MISE À JOUR :2 septembre 2021 (Publié à l'origine le 26 juillet 2012.)
Beaucoup de choses changent au cours de quelques versions majeures de notre plate-forme de base de données préférée. SQL Server 2016 nous a apporté STRING_SPLIT, une fonction native qui élimine le besoin de nombreuses solutions personnalisées dont nous avions besoin auparavant. C'est rapide aussi, mais ce n'est pas parfait. Par exemple, il ne prend en charge qu'un délimiteur à un seul caractère et ne renvoie rien pour indiquer l'ordre des éléments d'entrée. J'ai écrit plusieurs articles sur cette fonction (et STRING_AGG, qui est arrivé dans SQL Server 2017) depuis la rédaction de cet article :
- Surprises et hypothèses de performances :STRING_SPLIT()
- STRING_SPLIT() dans SQL Server 2016 : Suivi #1
- STRING_SPLIT() dans SQL Server 2016 :suivi 2
- Code de remplacement de chaîne fractionnée SQL Server avec STRING_SPLIT
- Comparaison des méthodes de fractionnement/concaténation de chaînes
- Résolvez les anciens problèmes avec les nouvelles fonctions STRING_AGG et STRING_SPLIT de SQL Server
- Traitement du délimiteur à caractère unique dans la fonction STRING_SPLIT de SQL Server
- Veuillez nous aider à améliorer STRING_SPLIT
- Un moyen d'améliorer STRING_SPLIT dans SQL Server – et vous pouvez nous aider
Je vais laisser le contenu ci-dessous ici pour la postérité et la pertinence historique, et aussi parce qu'une partie de la méthodologie de test est pertinente pour d'autres problèmes en dehors du fractionnement des chaînes, mais veuillez consulter certaines des références ci-dessus pour plus d'informations sur la façon dont vous devriez vous diviser chaînes dans les versions modernes et prises en charge de SQL Server - ainsi que cet article, qui explique pourquoi le fractionnement des chaînes n'est peut-être pas un problème que vous souhaitez que la base de données résolve en premier lieu, nouvelle fonction ou non.
- Fractionner les chaînes :désormais avec moins de T-SQL
Je sais que beaucoup de gens s'ennuient du problème des "chaînes divisées", mais il semble toujours apparaître presque quotidiennement sur les forums et les sites de questions-réponses comme Stack Overflow. C'est le problème où les gens veulent passer une chaîne comme celle-ci :
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
À l'intérieur de la procédure, ils veulent faire quelque chose comme ceci :
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Cela ne fonctionne pas car @FavoriteTeams est une chaîne unique, et ce qui précède se traduit par :
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server va donc essayer de trouver une équipe nommée Patriots,Red Sox,Bruins , et je suppose qu'il n'y a pas une telle équipe. Ce qu'ils veulent vraiment ici, c'est l'équivalent de :
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Mais comme il n'y a pas de type de tableau dans SQL Server, ce n'est pas du tout la façon dont la variable est interprétée - c'est toujours une chaîne simple et unique qui contient des virgules. Mis à part la conception de schéma discutable, dans ce cas, la liste séparée par des virgules doit être "divisée" en valeurs individuelles - et c'est la question qui suscite souvent de nombreux "nouveaux" débats et commentaires sur la meilleure solution pour y parvenir. /P>
La réponse semble être, presque invariablement, que vous devriez utiliser CLR. Si vous ne pouvez pas utiliser CLR - et je sais que beaucoup d'entre vous ne le peuvent pas, en raison de la politique de l'entreprise, du patron aux cheveux pointus ou de l'entêtement - alors vous utilisez l'une des nombreuses solutions de contournement qui existent. Et de nombreuses solutions de contournement existent.
Mais lequel devez-vous utiliser ?
Je vais comparer les performances de quelques solutions – et me concentrer sur la question que tout le monde se pose toujours :« Laquelle est la plus rapide ? Je ne vais pas insister sur la discussion autour de * toutes * les méthodes potentielles, car plusieurs ont déjà été éliminées en raison du fait qu'elles ne s'adaptent tout simplement pas. Et je pourrais revoir cela à l'avenir pour examiner l'impact sur d'autres mesures, mais pour l'instant je vais me concentrer uniquement sur la durée. Voici les concurrents que je vais comparer (en utilisant SQL Server 2012, 11.00.2316, sur une machine virtuelle Windows 7 avec 4 processeurs et 8 Go de RAM) :
CLR
Si vous souhaitez utiliser CLR, vous devez absolument emprunter le code de votre collègue MVP Adam Machanic avant de penser à écrire le vôtre (j'ai déjà blogué sur la réinvention de la roue, et cela s'applique également aux extraits de code gratuits comme celui-ci). Il a passé beaucoup de temps à affiner cette fonction CLR pour analyser efficacement une chaîne. Si vous utilisez actuellement une fonction CLR et que ce n'est pas celle-ci, je vous recommande fortement de la déployer et de la comparer - je l'ai testée par rapport à une routine CLR basée sur VB beaucoup plus simple qui était fonctionnellement équivalente, mais l'approche VB a fonctionné environ trois fois moins bien que celle d'Adam.
J'ai donc pris la fonction d'Adam, compilé le code dans une DLL (à l'aide de csc) et déployé uniquement ce fichier sur le serveur. Ensuite, j'ai ajouté l'assemblage et la fonction suivants à ma base de données :
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
C'est la fonction typique que j'utilise pour des scénarios ponctuels où je sais que l'entrée est "sûre", mais ce n'est pas celle que je recommande pour les environnements de production (plus de détails ci-dessous).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Une très forte mise en garde doit accompagner l'approche XML :elle ne peut être utilisée que si vous pouvez garantir que votre chaîne d'entrée ne contient aucun caractère XML illégal. Un nom avec <,> ou &et la fonction explosera. Ainsi, quelles que soient les performances, si vous envisagez d'utiliser cette approche, soyez conscient des limites - elle ne doit pas être considérée comme une option viable pour un séparateur de chaînes générique. Je l'inclus dans ce tour d'horizon parce que vous avez peut-être un cas où vous pouvez faites confiance à l'entrée - par exemple, il est possible de l'utiliser pour des listes d'entiers ou de GUID séparés par des virgules.
Tableau des nombres
Cette solution utilise une table Numbers, que vous devez créer et remplir vous-même. (Nous demandons une version intégrée depuis des lustres.) La table Numbers doit contenir suffisamment de lignes pour dépasser la longueur de la chaîne la plus longue que vous diviserez. Dans ce cas, nous utiliserons 1 000 000 lignes :
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (L'utilisation de la compression des données réduira considérablement le nombre de pages requises, mais vous ne devez évidemment utiliser cette option que si vous utilisez Enterprise Edition. Dans ce cas, les données compressées nécessitent 1 360 pages, contre 2 102 pages sans compression, soit une économie d'environ 35 %. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Expression de table commune
Cette solution utilise un CTE récursif pour extraire chaque partie de la chaîne du "reste" de la partie précédente. En tant que CTE récursif avec des variables locales, vous remarquerez qu'il devait s'agir d'une fonction table multi-instructions, contrairement aux autres qui sont toutes en ligne.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Le séparateur de Jeff Moden Une fonction basée sur le séparateur de Jeff Moden avec des modifications mineures pour prendre en charge des chaînes plus longues
Sur SQLServerCentral, Jeff Moden a présenté une fonction de fractionnement qui rivalisait avec les performances de CLR, j'ai donc pensé qu'il était juste d'inclure une variante utilisant une approche similaire dans ce tour d'horizon. J'ai dû apporter quelques modifications mineures à sa fonction afin de gérer notre chaîne la plus longue (500 000 caractères), et j'ai également rendu les conventions de dénomination similaires :
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; En passant, pour ceux qui utilisent la solution de Jeff Moden, vous pouvez envisager d'utiliser un tableau de nombres comme ci-dessus et d'expérimenter une légère variation de la fonction de Jeff :
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Cela échangera des lectures légèrement plus élevées pour un CPU légèrement inférieur, donc peut être mieux selon que votre système est déjà lié au CPU ou aux E/S.)
Vérification de l'intégrité
Juste pour être sûr que nous sommes sur la bonne voie, nous pouvons vérifier que les cinq fonctions renvoient les résultats attendus :
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Et en fait, ce sont les résultats que nous voyons dans les cinq cas…

Les données de test
Maintenant que nous savons que les fonctions se comportent comme prévu, nous pouvons passer à la partie amusante :tester les performances par rapport à différents nombres de chaînes dont la longueur varie. Mais d'abord, nous avons besoin d'une table. J'ai créé l'objet simple suivant :
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
J'ai rempli ce tableau avec un ensemble de chaînes de longueurs variables, en m'assurant qu'à peu près le même ensemble de données serait utilisé pour chaque test - 10 000 premières lignes où la chaîne fait 50 caractères, puis 1 000 lignes où la chaîne fait 500 caractères , 100 lignes où la chaîne est longue de 5 000 caractères, 10 lignes où la chaîne est longue de 50 000 caractères, et ainsi de suite jusqu'à 1 ligne de 500 000 caractères. Je l'ai fait à la fois pour comparer la même quantité de données globales traitées par les fonctions, ainsi que pour essayer de garder mes temps de test quelque peu prévisibles.
J'utilise une table #temp pour pouvoir simplement utiliser GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
La création et le remplissage de cette table ont pris environ 20 secondes sur ma machine, et la table représente environ 6 Mo de données (environ 500 000 caractères fois 2 octets, ou 1 Mo par string_type, plus la surcharge de ligne et d'index). Ce n'est pas un tableau énorme, mais il doit être suffisamment grand pour mettre en évidence les différences de performances entre les fonctions.
Les épreuves
Avec les fonctions en place et le tableau correctement rempli de grosses chaînes à mâcher, nous pouvons enfin exécuter des tests réels pour voir comment les différentes fonctions fonctionnent par rapport à des données réelles. Afin de mesurer les performances sans prendre en compte la surcharge du réseau, j'ai utilisé SQL Sentry Plan Explorer, en exécutant chaque ensemble de tests 10 fois, en collectant les métriques de durée et en faisant la moyenne.
Le premier test a simplement extrait les éléments de chaque chaîne comme un ensemble :
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
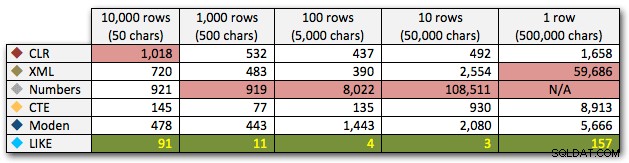
Les résultats montrent qu'à mesure que les cordes deviennent plus grandes, l'avantage du CLR brille vraiment. À l'extrémité inférieure, les résultats étaient mitigés, mais encore une fois, la méthode XML devrait être accompagnée d'un astérisque, car son utilisation dépend de l'utilisation d'une entrée XML sécurisée. Pour ce cas d'utilisation spécifique, la table Numbers a toujours donné les pires résultats :
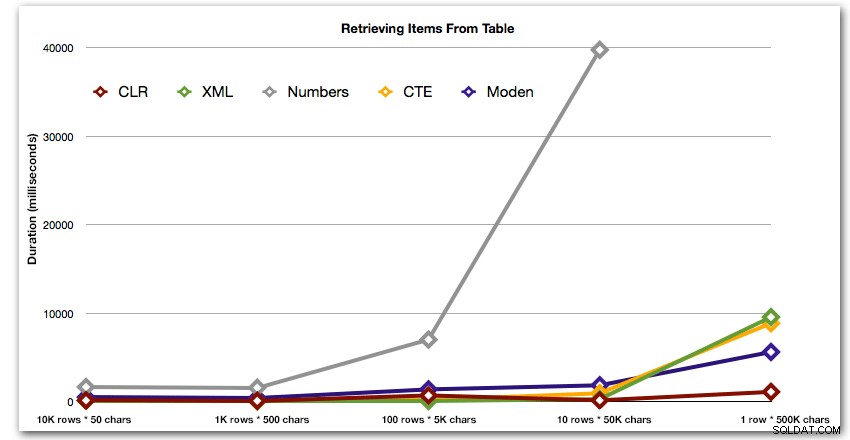
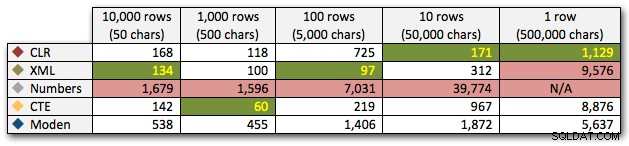
Durée, en millisecondes
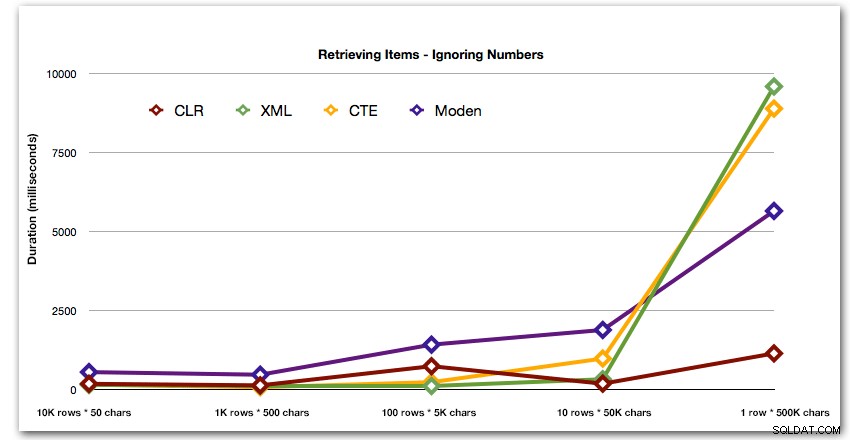
Après la performance hyperbolique de 40 secondes pour le tableau des nombres contre 10 lignes de 50 000 caractères, je l'ai retiré de la course pour le dernier test. Pour mieux montrer les performances relatives des quatre meilleures méthodes de ce test, j'ai complètement supprimé les résultats des nombres du graphique :
Ensuite, comparons le moment où nous effectuons une recherche avec la valeur séparée par des virgules (par exemple, renvoyons les lignes où l'une des chaînes est 'foo'). Encore une fois, nous utiliserons les cinq fonctions ci-dessus, mais nous comparerons également le résultat à une recherche effectuée au moment de l'exécution en utilisant LIKE au lieu de s'embêter avec le fractionnement.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Ces résultats montrent que, pour les petites chaînes, CLR était en fait le plus lent et que la meilleure solution consiste à effectuer une analyse à l'aide de LIKE, sans se soucier de diviser les données. Encore une fois, j'ai abandonné la solution de table Numbers de la 5ème approche, lorsqu'il était clair que sa durée augmenterait de façon exponentielle à mesure que la taille de la chaîne augmentait :
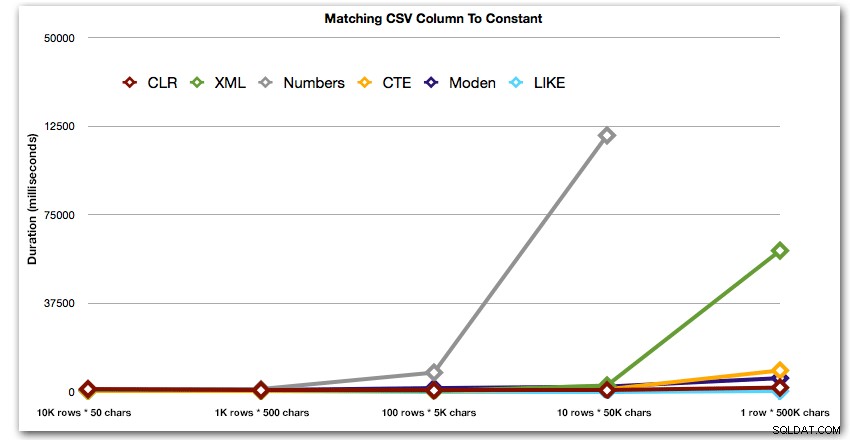
Durée, en millisecondes
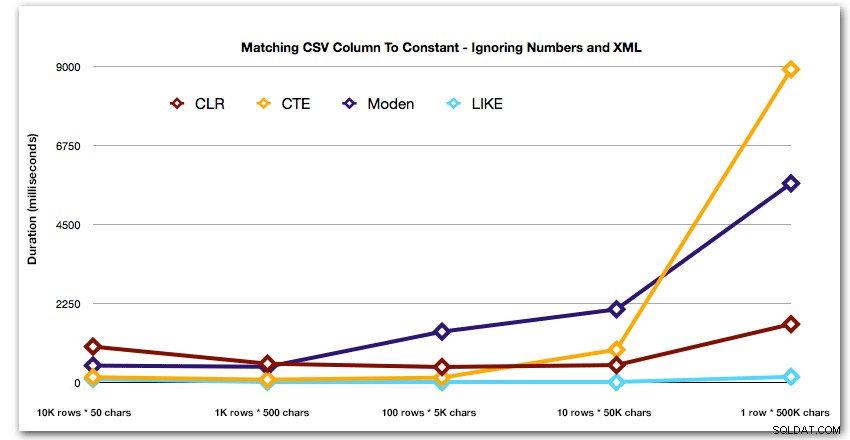
Et pour mieux illustrer les modèles des 4 premiers résultats, j'ai éliminé les solutions Numbers et XML du graphique :
Ensuite, examinons la réplication du cas d'utilisation depuis le début de cet article, où nous essayons de trouver toutes les lignes d'une table qui existent dans la liste transmise. Comme pour les données de la table que nous avons créée ci-dessus, nous 'vont créer des chaînes dont la longueur varie de 50 à 500 000 caractères, les stocker dans une variable, puis vérifier si une vue de catalogue commune existe dans la liste.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
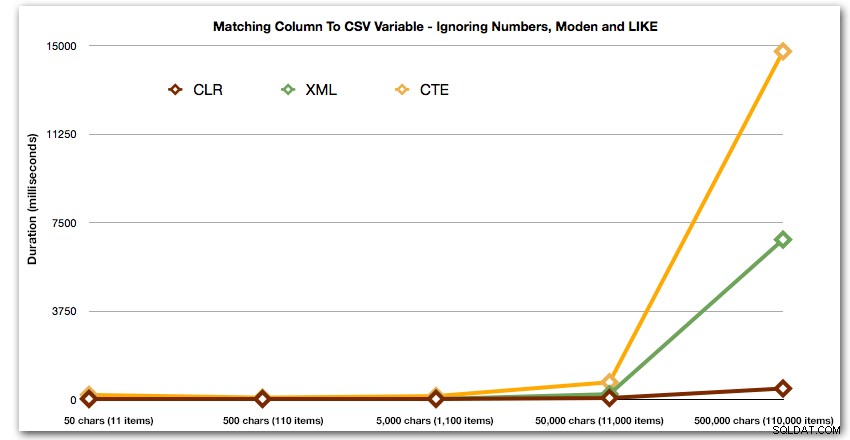
ORDER BY [object_id]; Ces résultats montrent que, pour ce motif, plusieurs méthodes voient leur durée augmenter de manière exponentielle à mesure que la taille de la chaîne augmente. À l'extrémité inférieure, XML suit le rythme du CLR, mais cela se détériore également rapidement. CLR est toujours le grand gagnant ici :
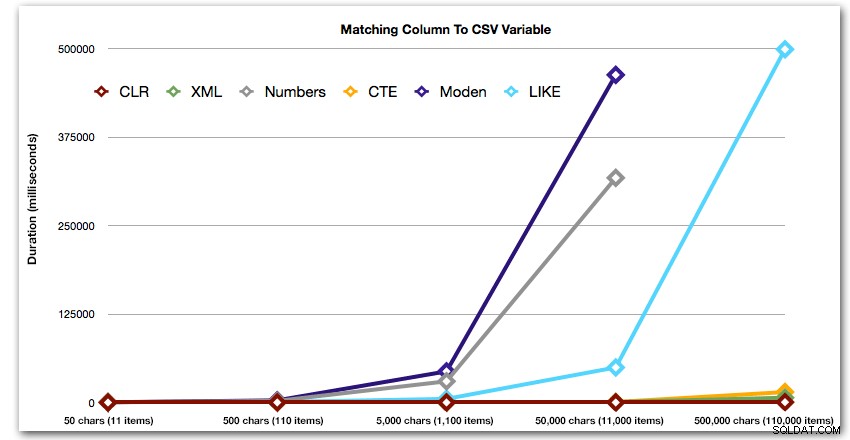
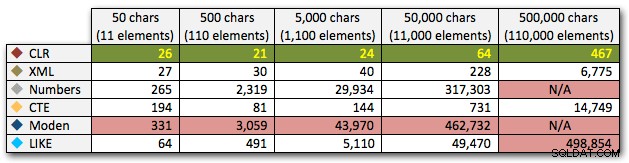
Durée, en millisecondes
Et encore sans les méthodes qui explosent à la hausse en terme de durée :
Enfin, comparons le coût de récupération des données d'une seule variable de longueur variable, en ignorant le coût de lecture des données d'une table. Encore une fois, nous allons générer des chaînes de longueur variable, de 50 à 500 000 caractères, puis renvoyer simplement les valeurs sous forme d'ensemble :
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Ces résultats montrent également que le CLR est assez stable en termes de durée, jusqu'à 110 000 éléments dans l'ensemble, tandis que les autres méthodes conservent un rythme décent jusqu'à un certain temps après 11 000 éléments :
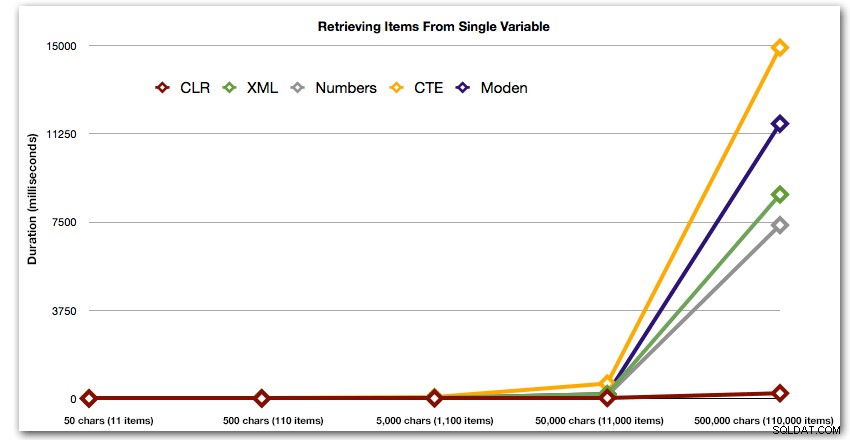
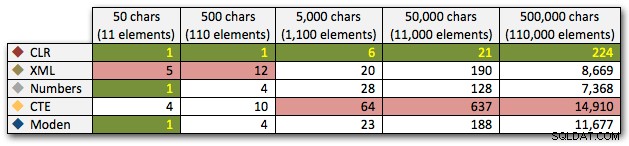
Durée, en millisecondes
Conclusion
Dans presque tous les cas, la solution CLR surpasse clairement les autres approches - dans certains cas, c'est une victoire écrasante, d'autant plus que la taille des cordes augmente; dans quelques autres, c'est une photo-finish qui pourrait tomber dans les deux sens. Dans le premier test, nous avons vu que XML et CTE surpassaient CLR au bas de l'échelle, donc s'il s'agit d'un cas d'utilisation typique * et * vous êtes sûr que vos chaînes sont dans la plage de 1 à 10 000 caractères, l'une de ces approches pourrait être une meilleure option. Si vos tailles de cordes sont moins prévisibles que cela, CLR est probablement toujours votre meilleur pari global - vous perdez quelques millisecondes à l'extrémité inférieure, mais vous gagnez beaucoup à l'extrémité supérieure. Voici les choix que je ferais, en fonction de la tâche, avec la deuxième place mise en évidence pour les cas où le CLR n'est pas une option. Notez que XML est ma méthode préférée uniquement si je sais que l'entrée est XML-safe; ce ne sont pas nécessairement vos meilleures alternatives si vous avez moins confiance en votre contribution.
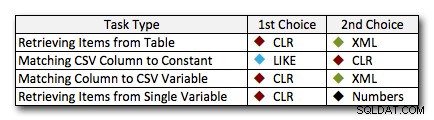
La seule véritable exception où CLR n'est pas mon choix à tous les niveaux est le cas où vous stockez en fait des listes séparées par des virgules dans une table, puis recherchez des lignes où une entité définie se trouve dans cette liste. Dans ce cas précis, je recommanderais probablement d'abord de reconcevoir et de normaliser correctement le schéma, afin que ces valeurs soient stockées séparément, plutôt que de l'utiliser comme excuse pour ne pas utiliser CLR pour le fractionnement.
Si vous ne pouvez pas utiliser CLR pour d'autres raisons, il n'y a pas de "deuxième place" claire révélée par ces tests; mes réponses ci-dessus étaient basées sur l'échelle globale et non sur une taille de chaîne spécifique. Chaque solution ici a été finaliste dans au moins un scénario - donc bien que CLR soit clairement le choix quand vous pouvez l'utiliser, ce que vous devriez utiliser quand vous ne pouvez pas est plus une réponse "ça dépend" - vous devrez juger en fonction de votre ou vos cas d'utilisation et les tests ci-dessus (ou en construisant vos propres tests) quelle alternative est la meilleure pour vous.
Addendum :Une alternative au fractionnement en premier lieu
Les approches ci-dessus ne nécessitent aucune modification de vos applications existantes, en supposant qu'elles assemblent déjà une chaîne séparée par des virgules et la lancent dans la base de données pour la traiter. Une option à considérer, si le CLR n'est pas une option et/ou si vous pouvez modifier la ou les applications, consiste à utiliser des paramètres de table (TVP). Voici un exemple rapide de la façon d'utiliser un TVP dans le contexte ci-dessus. Commencez par créer un type de table avec une seule colonne de chaîne :
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Ensuite, la procédure stockée peut prendre ce TVP en entrée et se joindre au contenu (ou l'utiliser d'autres manières - ce n'est qu'un exemple) :
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Maintenant, dans votre code C#, par exemple, au lieu de créer une chaîne séparée par des virgules, remplissez un DataTable (ou utilisez n'importe quelle collection compatible pouvant déjà contenir votre ensemble de valeurs) :
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Vous pourriez considérer cela comme une préquelle d'un post de suivi.
Bien sûr, cela ne fonctionne pas bien avec JSON et d'autres API - c'est souvent la raison pour laquelle une chaîne séparée par des virgules est transmise à SQL Server en premier lieu.