Comme tout langage de programmation, T-SQL a sa part de bogues et de pièges courants, dont certains provoquent des résultats incorrects et d'autres des problèmes de performances. Dans bon nombre de ces cas, il existe des pratiques exemplaires qui peuvent vous aider à éviter les ennuis. J'ai interrogé d'autres MVP de Microsoft Data Platform sur les bogues et les pièges qu'ils voient souvent ou qu'ils trouvent simplement particulièrement intéressants, et sur les meilleures pratiques qu'ils emploient pour les éviter. J'ai eu beaucoup de cas intéressants.
Un grand merci à Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser et Chan Ming Man pour avoir partagé vos connaissances et votre expérience !
Cet article est le premier d'une série sur le sujet. Chaque article se concentre sur un certain thème. Ce mois-ci, je me concentre sur les bogues, les pièges et les meilleures pratiques liés au déterminisme. Un calcul déterministe est un calcul qui est garanti pour produire des résultats reproductibles avec les mêmes entrées. De nombreux bugs et pièges résultent de l'utilisation de calculs non déterministes. Dans cet article, je couvre les implications de l'utilisation d'un ordre non déterministe, de fonctions non déterministes, de références multiples à des expressions de table avec des calculs non déterministes, et de l'utilisation d'expressions CASE et de la fonction NULLIF avec des calculs non déterministes.
J'utilise l'exemple de base de données TSQLV5 dans de nombreux exemples de cette série.
Ordre non déterministe
Une source courante de bogues dans T-SQL est l'utilisation d'un ordre non déterministe. Autrement dit, lorsque votre ordre par liste n'identifie pas de manière unique une ligne. Il peut s'agir d'un ordre de présentation, d'un ordre TOP/OFFSET-FETCH ou d'un ordre de fenêtre.
Prenons par exemple un scénario de pagination classique utilisant le filtre OFFSET-FETCH. Vous devez interroger la table Sales.Orders renvoyant une page de 10 lignes à la fois, triée par date de commande, décroissante (la plus récente en premier). J'utiliserai des constantes pour les éléments offset et fetch pour plus de simplicité, mais ce sont généralement des expressions basées sur des paramètres d'entrée.
La requête suivante (appelez-la Requête 1) renvoie la première page des 10 commandes les plus récentes :
UTILISER TSQLV5 ; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY ;
Le plan pour la requête 1 est illustré à la figure 1.
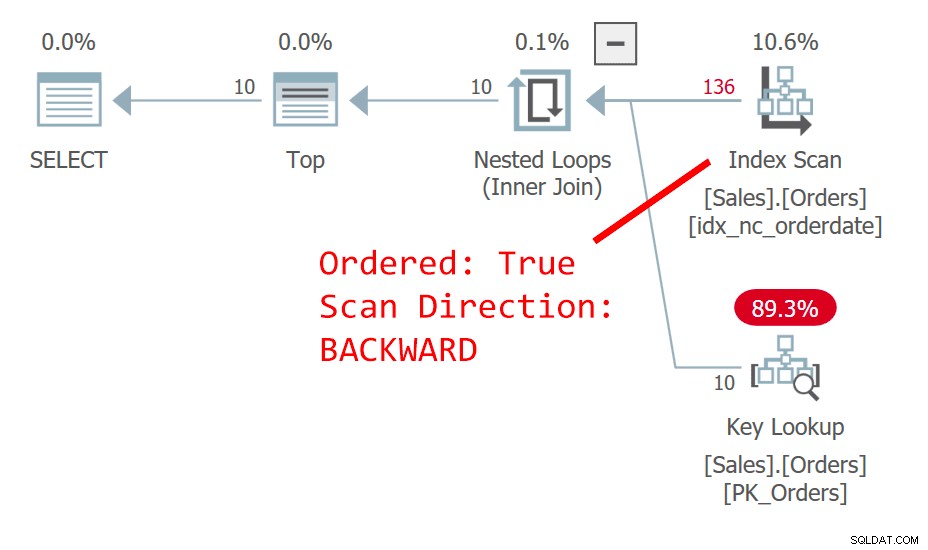 Figure 1 :Plan pour la requête 1
Figure 1 :Plan pour la requête 1
La requête classe les lignes par date de commande, en ordre décroissant. La colonne orderdate n'identifie pas une ligne de manière unique. Cet ordre non déterministe signifie que conceptuellement, il n'y a pas de préférence entre les lignes avec la même date. En cas d'égalité, ce qui détermine la ligne que SQL Server préférera, ce sont des éléments tels que les choix de plan et la disposition physique des données, et non quelque chose sur lequel vous pouvez compter comme étant reproductible. Le plan de la figure 1 analyse l'index à la date de commande dans l'ordre inverse. Il se trouve que cette table a un index clusterisé sur orderid et, dans une table clusterisée, la clé d'index clusterisée est utilisée comme localisateur de ligne dans les index non clusterisés. Il est en fait implicitement positionné comme dernier élément clé dans tous les index non clusterisés, même si théoriquement SQL Server aurait pu le placer dans l'index en tant que colonne incluse. Ainsi, implicitement, l'index non clusterisé sur orderdate est en fait défini sur (orderdate, orderid). Par conséquent, dans notre analyse arrière ordonnée de l'index, entre les lignes liées en fonction de la date de commande, une ligne avec une valeur orderid plus élevée est accessible avant une ligne avec une valeur orderid inférieure. Cette requête génère la sortie suivante :
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 06-05-2019 68 11074 06-05-2019 73 11073 05-05-2019 58 11072 05-05-2019 20 11071 05-05-2019 46 11070 05-05-2019 49 2019-05-04 60 1019 80 *** 11068 2019-05-04 62
Ensuite, utilisez la requête suivante (appelez-la Requête 2) pour obtenir la deuxième page de 10 lignes :
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY ;
Le plan pour Query est illustré à la figure 2.
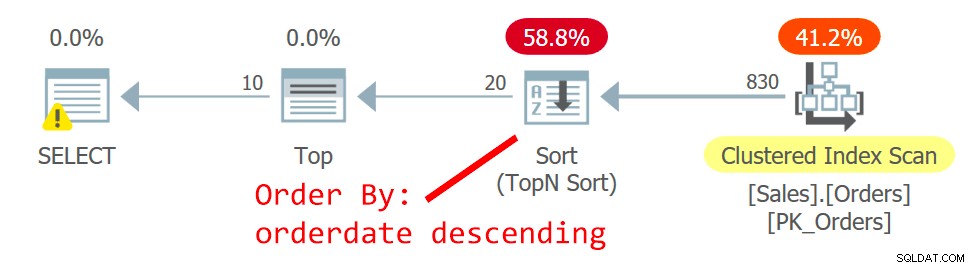
Figure 2 :Plan pour la requête 2
L'optimiseur choisit un plan différent, celui qui analyse l'index clusterisé de manière non ordonnée et utilise un tri TopN pour prendre en charge la demande de l'opérateur Top de gérer le filtre d'extraction de décalage. La raison de la modification est que le plan de la figure 1 utilise un index non couvrant non clusterisé, et plus la page que vous recherchez est éloignée, plus les recherches sont nécessaires. Avec la deuxième demande de page, vous avez franchi le point de basculement qui justifie l'utilisation de l'index non couvrant.
Même si l'analyse de l'index clusterisé, qui est défini avec orderid comme clé, n'est pas ordonnée, le moteur de stockage utilise une analyse d'ordre d'index en interne. Cela a à voir avec la taille de l'index. Jusqu'à 64 pages, le moteur de stockage préfère généralement les analyses d'ordre d'index aux analyses d'ordre d'allocation. Même si l'index était plus grand, sous le niveau d'isolement de lecture validée et les données qui ne sont pas marquées comme en lecture seule, le moteur de stockage utilise une analyse de l'ordre de l'index pour éviter la double lecture et le saut de lignes à la suite de fractionnements de page qui se produisent pendant le analyse. Dans les conditions données, en pratique, entre des lignes avec la même date, ce plan accède à une ligne avec un orderid inférieur avant une avec un orderid supérieur.
Cette requête génère la sortie suivante :
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 30 04-29 53 11058 2019-04-29 6
Observez que même si les données sous-jacentes n'ont pas changé, vous vous êtes retrouvé avec la même commande (avec l'ID de commande 11069) renvoyée dans les première et deuxième pages !
Espérons que la meilleure pratique ici est claire. Ajoutez un bris d'égalité à votre commande par liste pour obtenir une commande déterministe. Par exemple, trier par date de commande décroissante, numéro de commande décroissant.
Essayez à nouveau de demander la première page, cette fois avec un ordre déterministe :
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY ;
Vous obtenez le résultat suivant, garanti :
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 06-05-2019 68 11074 06-05-2019 73 11073 05-05-2019 58 11072 05-05-2019 20 11071 05-05-2019 46 11070 05-05-2019 49 2019-05-04 60 1019 80 11068 2019-05-04 62
Demandez la deuxième page :
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY ;
Vous obtenez le résultat suivant, garanti :
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 01-05-2019 46 11064 01-05-2019 71 11063 30-04-2019 37 11062 30-04-2019 66 11061 30-04-2019 32 11060 30-04-2019 27 27 11060 30-04-2019 27 67 11058 2019-04-29 6
Tant qu'il n'y a pas eu de changement dans les données sous-jacentes, vous êtes assuré d'obtenir des pages consécutives sans répétition ni saut de lignes entre les pages.
De la même manière, en utilisant des fonctions de fenêtre telles que ROW_NUMBER avec un ordre non déterministe, vous pouvez obtenir des résultats différents pour la même requête en fonction de la forme du plan et de l'ordre d'accès réel entre les liens. Considérez la requête suivante (appelez-la Requête 3), implémentant la première requête de page à l'aide de numéros de ligne (forçant l'utilisation de l'index sur la date de commande à des fins d'illustration) :
WITH C AS ( SELECT id_commande, date_commande, client, ROW_NUMBER() OVER(ORDER BY date_commande DESC) AS n FROM Ventes.Commandes WITH (INDEX(idx_nc_date_commande)) ) SELECT id_commande, date_commande, client FROM C WHERE n BETWEEN 1 ET 10 ;
Le plan de cette requête est illustré à la figure 3 :
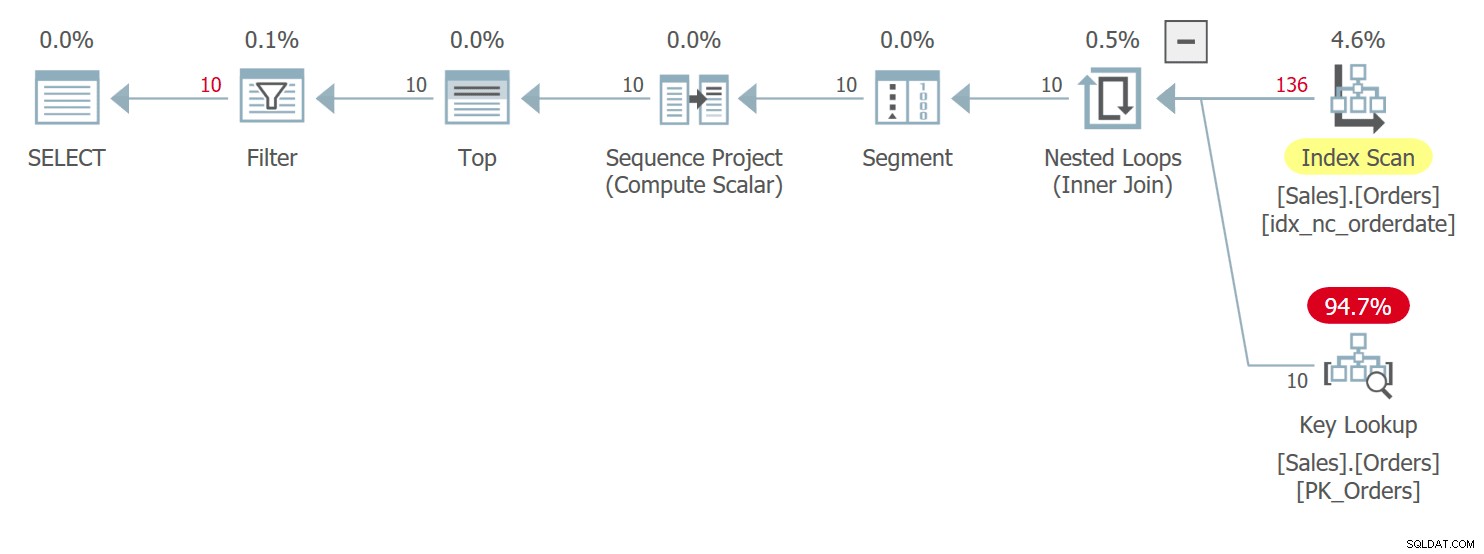
Figure 3 :Plan pour la requête 3
Vous avez ici des conditions très similaires à celles que j'ai décrites précédemment pour la requête 1 avec son plan qui a été montré plus tôt dans la figure 1. Entre les lignes avec des liens dans les valeurs de date de commande, ce plan accède à une ligne avec une valeur orderid plus élevée avant une avec une valeur inférieure valeur d'ID de commande. Cette requête génère la sortie suivante :
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 06-05-2019 68 11074 06-05-2019 73 11073 05-05-2019 58 11072 05-05-2019 20 11071 05-05-2019 46 11070 05-05-2019 49 2019-05-04 60 1019 80 *** 11068 2019-05-04 62
Ensuite, exécutez à nouveau la requête (appelez-la Requête 4), en demandant la première page, mais cette fois forcez l'utilisation de l'index clusterisé PK_Orders :
WITH C AS ( SELECT ID commande, date commande, client, ROW_NUMBER() OVER(ORDER BY date commande DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT ID commande, date commande, client FROM C WHERE n BETWEEN 1 ET 10 ;
Le plan de cette requête est illustré à la figure 4.

Figure 4 :Plan pour la requête 4
Cette fois, vous avez des conditions très similaires à celles que j'ai décrites précédemment pour la requête 2 avec son plan qui a été montré plus tôt dans la figure 2. Entre les lignes avec des liens dans les valeurs de date de commande, ce plan accède à une ligne avec une valeur orderid inférieure avant une avec un valeur d'ID de commande plus élevée. Cette requête génère la sortie suivante :
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 60 1019-05-05 58 2019-05-05 58 17 *** 11068 2019-05-04 62
Observez que les deux exécutions ont produit des résultats différents même si rien n'a changé dans les données sous-jacentes.
Encore une fois, la meilleure pratique ici est simple :utilisez l'ordre déterministe en ajoutant un critère de départage, comme ceci :
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 AND 10;Cette requête génère la sortie suivante :
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 06-05-2019 68 11074 06-05-2019 73 11073 05-05-2019 58 11072 05-05-2019 20 11071 05-05-2019 46 11070 05-05-2019 49 2019-05-04 60 1019 80 11068 2019-05-04 62L'ensemble renvoyé est garanti reproductible quelle que soit la forme du plan.
Il est probablement utile de mentionner que puisque cette requête n'a pas d'ordre de présentation par clause dans la requête externe, il n'y a pas d'ordre de présentation garanti ici. Si vous avez besoin d'une telle garantie, vous devez ajouter un ordre de présentation par clause, comme ceci :
WITH C AS ( SELECT id_commande, date_commande, custid, ROW_NUMBER() OVER(ORDER BY date_commande DESC, id_commande DESC) AS n FROM Sales.Orders ) SELECT id_commande, date_commande, custid FROM C WHERE n BETWEEN 1 AND 10 ORDER BY n;Fonctions non déterministes
Une fonction non déterministe est une fonction qui, étant donné les mêmes entrées, peut renvoyer des résultats différents dans différentes exécutions de la fonction. Les exemples classiques sont SYSDATETIME, NEWID et RAND (lorsqu'ils sont invoqués sans graine d'entrée). Le comportement des fonctions non déterministes dans T-SQL peut surprendre certains et peut entraîner des bogues et des pièges dans certains cas.
De nombreuses personnes supposent que lorsque vous appelez une fonction non déterministe dans le cadre d'une requête, la fonction est évaluée séparément par ligne. En pratique, la plupart des fonctions non déterministes sont évaluées une fois par référence dans la requête. Considérez la requête suivante comme exemple :
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders ;Puisqu'il n'y a qu'une seule référence à chacune des fonctions non déterministes SYSDATETIME et RAND dans la requête, chacune de ces fonctions n'est évaluée qu'une seule fois et son résultat est répété sur toutes les lignes de résultat. J'ai obtenu le résultat suivant lors de l'exécution de cette requête :
orderid dt rnd ----------- --------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 :17:02 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...Comme exemple où ne pas comprendre ce comportement peut entraîner un bogue, supposons que vous ayez besoin d'écrire une requête qui renvoie trois commandes aléatoires à partir de la table Sales.Orders. Une première tentative courante consiste à utiliser une requête TOP avec un ordre basé sur la fonction RAND, en pensant que la fonction serait évaluée séparément par ligne, comme ceci :
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();En pratique, la fonction n'est évaluée qu'une seule fois pour toute la requête ; par conséquent, toutes les lignes obtiennent le même résultat et l'ordre n'est absolument pas affecté. En fait, si vous vérifiez le plan pour cette requête, vous ne verrez aucun opérateur de tri. Lorsque j'ai exécuté cette requête plusieurs fois, j'ai continué à obtenir le même résultat :
id de commande ----------- 11008 11019 11039La requête est en fait équivalente à une requête sans clause ORDER BY, où l'ordre de présentation n'est pas garanti. Donc, techniquement, l'ordre est non déterministe et, théoriquement, des exécutions différentes pourraient entraîner un ordre différent, et donc une sélection différente des 3 premières lignes. Cependant, la probabilité que cela se produise est faible et vous ne pouvez pas considérer cette solution comme produisant trois lignes aléatoires à chaque exécution.
Une exception à la règle selon laquelle une fonction non déterministe est appelée une fois par référence dans la requête est la fonction NEWID, qui renvoie un identificateur global unique (GUID). Lorsqu'elle est utilisée dans une requête, cette fonction est invoqué séparément par ligne. La requête suivante le démontre :
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders ;Cette requête a généré le résultat suivant :
orderid monnouvelid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...La valeur de NEWID elle-même est assez aléatoire. Si vous appliquez la fonction CHECKSUM dessus, vous obtenez un résultat entier avec une distribution aléatoire encore meilleure. Donc, une façon d'obtenir trois commandes aléatoires est d'utiliser une requête TOP avec une commande basée sur CHECKSUM(NEWID()), comme ceci :
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());Exécutez cette requête à plusieurs reprises et notez que vous obtenez à chaque fois un ensemble différent de trois commandes aléatoires. J'ai obtenu la sortie suivante en une seule exécution :
id de commande ----------- 11031 10330 10962Et la sortie suivante dans une autre exécution :
id de commande ----------- 10308 10885 10444En dehors de NEWID, que se passe-t-il si vous devez utiliser une fonction non déterministe telle que SYSDATETIME dans une requête et que vous avez besoin qu'elle soit évaluée séparément par ligne ? Une façon d'y parvenir est d'utiliser une fonction définie par l'utilisateur (UDF) qui invoque la fonction non déterministe, comme ceci :
CRÉER OU MODIFIER LA FONCTION dbo.MySysDateTime() RETOURNE DATETIME2 AS BEGIN RETURN SYSDATETIME(); FINIR; ALLERVous invoquez ensuite l'UDF dans la requête comme suit (appelez-le Requête 5) :
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders ;L'UDF est exécuté par ligne cette fois. Vous devez être conscient, cependant, qu'il y a une pénalité de performance assez forte associée à l'exécution par ligne de l'UDF. De plus, l'invocation d'une UDF T-SQL scalaire est un inhibiteur de parallélisme.
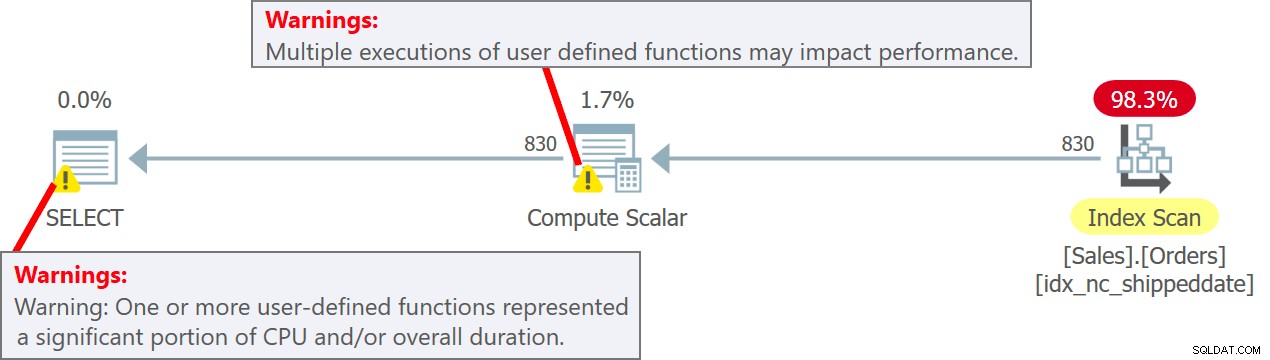
Le plan de cette requête est illustré à la figure 5.
Figure 5 :Plan pour la requête 5Notez dans le plan qu'en effet l'UDF est appelée par ligne source dans l'opérateur Compute Scalar. Notez également que SentryOne Plan Explorer vous avertit de la baisse potentielle des performances associée à l'utilisation de l'UDF à la fois dans l'opérateur Compute Scalar et dans le nœud racine du plan.
J'ai obtenu le résultat suivant de l'exécution de cette requête :
orderid mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 .Observez que les lignes de sortie ont plusieurs valeurs de date et d'heure différentes dans la colonne mydt.
Vous avez peut-être entendu dire que SQL Server 2019 résout le problème de performances courant causé par les UDF scalaires T-SQL en incorporant de telles fonctions. Cependant, l'UDF doit répondre à une liste d'exigences afin d'être inlineable. L'une des exigences est que l'UDF n'invoque aucune fonction intrinsèque non déterministe telle que SYSDATETIME. Le raisonnement de cette exigence est que vous avez peut-être créé la FDU exactement pour obtenir une exécution par ligne. Si l'UDF était en ligne, la fonction non déterministe sous-jacente ne serait exécutée qu'une seule fois pour toute la requête. En fait, le plan de la figure 5 a été généré dans SQL Server 2019, et vous pouvez clairement voir que l'UDF n'a pas été intégré. Cela est dû à l'utilisation de la fonction non déterministe SYSDATETIME. Vous pouvez vérifier si une UDF est inlineable dans SQL Server 2019 en interrogeant l'attribut is_inlineable dans la vue sys.sql_modules, comme ceci :
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Ce code génère la sortie suivante vous indiquant que l'UDF MySysDateTime n'est pas inlineable :
is_inlineable ------------- 0Pour illustrer une UDF inlineable, voici la définition d'une UDF appelée EndOfyear qui accepte une date d'entrée et renvoie la date de fin d'année correspondante :
CRÉER OU MODIFIER LA FONCTION dbo.EndOfYear(@dt AS DATE) RENVOIE LA DATE AS BEGIN RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231'); FINIR; ALLERIl n'y a pas d'utilisation de fonctions non déterministes ici, et le code répond également aux autres exigences de l'inlining. Vous pouvez vérifier que l'UDF est inlineable en utilisant le code suivant :
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Ce code génère la sortie suivante :
is_inlineable ------------- 1La requête suivante (appelez-la Requête 6) utilise l'UDF EndOfYear pour filtrer les commandes qui ont été passées à une date de fin d'année :
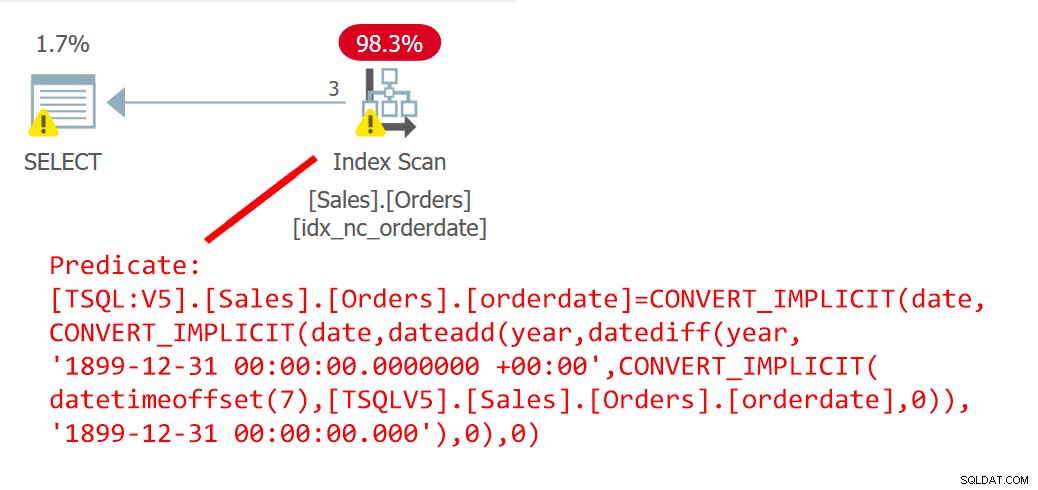
SELECT orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Le plan de cette requête est illustré à la figure 6.
Figure 6 :Plan pour la requête 6Le plan montre clairement que l'UDF s'est alignée.
Expressions de table, non-déterminisme et références multiples
Comme mentionné, les fonctions non déterministes telles que SYSDATETIME sont invoquées une fois par référence dans une requête. Mais que se passe-t-il si vous référencez une telle fonction une fois dans une requête dans une expression de table telle qu'un CTE, puis que vous avez une requête externe avec plusieurs références au CTE ? Beaucoup de gens ne réalisent pas que chaque référence à l'expression de table est développée séparément et que le code en ligne entraîne plusieurs références à la fonction non déterministe sous-jacente. Avec une fonction comme SYSDATETIME, selon le moment exact de chacune des exécutions, vous pourriez finir par obtenir un résultat différent pour chacune. Certaines personnes trouvent ce comportement surprenant.
Ceci peut être illustré avec le code suivant :
DECLARE @i AS INT =1, @rc AS INT =NULL ; TANT QUE 1 =1 COMMENCE ; AVEC C1 AS ( SELECT SYSDATETIME() AS dt ), C2 AS ( SELECT dt FROM C1 UNION SELECT dt FROM C1 ) SELECT @rc =COUNT(*) FROM C2; SI @rc> 1 RUPTURE ; SET @i +=1 ; FINIR; SELECT @rc AS valeurs distinctes, @i AS itérations ;Si les deux références à C1 dans la requête en C2 représentaient la même chose, ce code aurait entraîné une boucle infinie. Cependant, étant donné que les deux références sont développées séparément, lorsque la synchronisation est telle que chaque invocation a lieu dans un intervalle différent de 100 nanosecondes (la précision de la valeur du résultat), l'union aboutit à deux lignes et le code doit rompre avec le boucle. Exécutez ce code et voyez par vous-même. En effet, après quelques itérations il casse. J'ai obtenu le résultat suivant dans l'une des exécutions :
itérations distinctvalues -------------- ----------- 2 448La meilleure pratique consiste à éviter d'utiliser des expressions de table telles que des CTE et des vues, lorsque la requête interne utilise des calculs non déterministes et que la requête externe fait référence à l'expression de table plusieurs fois. C'est bien sûr à moins que vous ne compreniez les implications et que vous soyez d'accord avec elles. Des options alternatives pourraient être de conserver le résultat de la requête interne, par exemple dans une table temporaire, puis d'interroger la table temporaire autant de fois que nécessaire.
Pour illustrer des exemples où le non-respect de la meilleure pratique peut vous causer des problèmes, supposons que vous deviez écrire une requête qui associe les employés de la table HR.Employees de manière aléatoire. Vous proposez la requête suivante (appelez-la requête 7) pour gérer la tâche :
WITH C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. nom AS nom1, C2.empid AS empid2, C2.prénom AS prénom2, C2.nom AS nom2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1;Le plan de cette requête est illustré à la figure 7.
Figure 7 :Plan pour la requête 7Observez que les deux références à C sont développées séparément et que les numéros de ligne sont calculés indépendamment pour chaque référence ordonnée par des invocations indépendantes de l'expression CHECKSUM(NEWID()). Cela signifie que le même employé n'est pas assuré d'obtenir le même numéro de ligne dans les deux références étendues. Si un employé obtient le numéro de ligne x en C1 et le numéro de ligne x - 1 en C2, la requête associera l'employé à lui-même. Par exemple, j'ai obtenu le résultat suivant dans l'une des exécutions :
empid1 prenom1 nom1 empid2 prenom2 nom2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russel King ***Remarquez qu'il y a ici trois cas d'auto-paires. Ceci est plus facile à voir en ajoutant un filtre à la requête externe qui recherche spécifiquement les auto-paires, comme ceci :
WITH C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. nom AS nom1, C2.empid AS empid2, C2.prénom AS prénom2, C2.nom AS nom2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.empid =C2.empid;Vous devrez peut-être exécuter cette requête plusieurs fois pour voir le problème. Voici un exemple du résultat que j'ai obtenu dans l'une des exécutions :
empid1 prenom1 nom1 empid2 prenom2 nom2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkConformément à la meilleure pratique, une façon de résoudre ce problème consiste à conserver le résultat de la requête interne dans une table temporaire, puis à interroger plusieurs instances de la table temporaire selon les besoins.
Un autre exemple illustre les bogues qui peuvent résulter de l'utilisation d'un ordre non déterministe et de plusieurs références à une expression de table. Supposons que vous deviez interroger la table Sales.Orders et que, pour effectuer une analyse des tendances, vous souhaitiez associer chaque commande à la suivante en fonction de la commande par date de commande. Votre solution doit être compatible avec les systèmes pré-SQL Server 2012, ce qui signifie que vous ne pouvez pas utiliser les fonctions évidentes LAG/LEAD. Vous décidez d'utiliser un CTE qui calcule les numéros de ligne pour positionner les lignes en fonction de l'ordre de la date de commande, puis joignez deux instances du CTE, en associant les commandes en fonction d'un décalage de 1 entre les numéros de ligne, comme ceci (appelez cette requête 8):
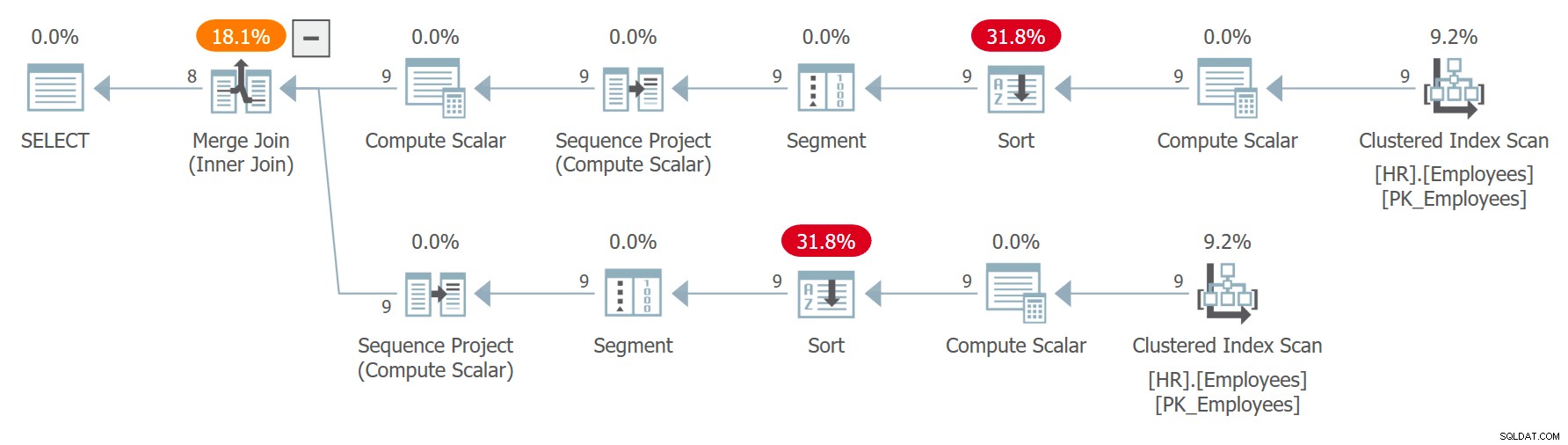
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FROM C AS C1 LEFT OUTER JOIN C AS C2 ON C1.n =C2.n + 1;Le plan de cette requête est illustré à la figure 8.
Figure 8 :Plan pour la requête 8
L'ordre des numéros de ligne n'est pas déterministe puisque la date de commande n'est pas unique. Observez que les deux références au CTE sont développées séparément. Curieusement, puisque la requête recherche un sous-ensemble différent de colonnes de chacune des instances, l'optimiseur décide d'utiliser un index différent dans chaque cas. Dans un cas, il utilise une analyse arrière ordonnée de l'index à la date de commande, analysant efficacement les lignes avec la même date en fonction de l'ordre décroissant de l'ID de commande. Dans l'autre cas, il analyse l'index clusterisé, classé faux puis trie, mais effectivement parmi les lignes avec la même date, il accède aux lignes dans l'ordre croissant de orderid. Cela est dû à un raisonnement similaire que j'ai fourni dans la section sur l'ordre non déterministe plus tôt. Cela peut avoir pour résultat que la même ligne obtienne le numéro de ligne x dans une instance et le numéro de ligne x - 1 dans l'autre instance. Dans un tel cas, la jointure finira par faire correspondre une commande avec elle-même plutôt qu'avec la suivante comme il se doit.
J'ai obtenu le résultat suivant lors de l'exécution de cette requête :
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 201 05 *** ...Observez les auto-correspondances dans le résultat. Encore une fois, le problème peut être identifié plus facilement en ajoutant un filtre recherchant des auto-correspondances, comme ceci :
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FROM C AS C1 LEFT OUTER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.orderid =C2.orderid;J'ai obtenu le résultat suivant de cette requête :
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...La meilleure pratique ici consiste à s'assurer que vous utilisez un ordre unique pour garantir le déterminisme en ajoutant un critère de départage comme orderid à la clause d'ordre de la fenêtre. Ainsi, même si vous avez plusieurs références au même CTE, les numéros de ligne seront les mêmes dans les deux. Si vous souhaitez éviter la répétition des calculs, vous pouvez également envisager de conserver le résultat de la requête interne, mais vous devez alors tenir compte du coût supplémentaire d'un tel travail.
CASE/NULLIF et fonctions non déterministes
Lorsque vous avez plusieurs références à une fonction non déterministe dans une requête, chaque référence est évaluée séparément. Ce qui pourrait être surprenant et même entraîner des bogues, c'est que parfois vous écrivez une référence, mais implicitement, elle est convertie en plusieurs références. Telle est la situation avec certaines utilisations de l'expression CASE et de la fonction IIF.
Prenons l'exemple suivant :
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END ;Ici, le résultat de l'expression testée est une valeur entière non négative, il doit donc clairement être pair ou impair. Il ne peut être ni pair ni impair. Cependant, si vous exécutez ce code suffisamment de fois, vous obtiendrez parfois un NULL indiquant que la clause implicite ELSE NULL de l'expression CASE a été activée. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusion
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!