J'ai récemment reçu une question par e-mail d'un membre de la communauté concernant le CLR_MANUAL_EVENT type d'attente ; plus précisément, comment résoudre les problèmes liés à cette attente qui devient soudainement courante pour une charge de travail existante qui reposait fortement sur des types de données spatiales et des requêtes à l'aide des méthodes spatiales dans SQL Server.
En tant que consultant, ma première question est presque toujours :« Qu'est-ce qui a changé ? Mais dans ce cas, comme dans tant de cas, on m'a assuré que rien n'avait changé avec le code de l'application ou les modèles de charge de travail. Donc, mon premier arrêt a été de récupérer le CLR_MANUAL_EVENT attendez dans la bibliothèque de types d'attente SQLskills.com pour voir quelles autres informations nous avions déjà collectées sur ce type d'attente, car ce n'est généralement pas une attente avec laquelle je vois des problèmes dans SQL Server. Ce que j'ai trouvé vraiment intéressant, c'est le graphique/carte thermique des occurrences pour ce type d'attente fourni par SentryOne en haut de la page :
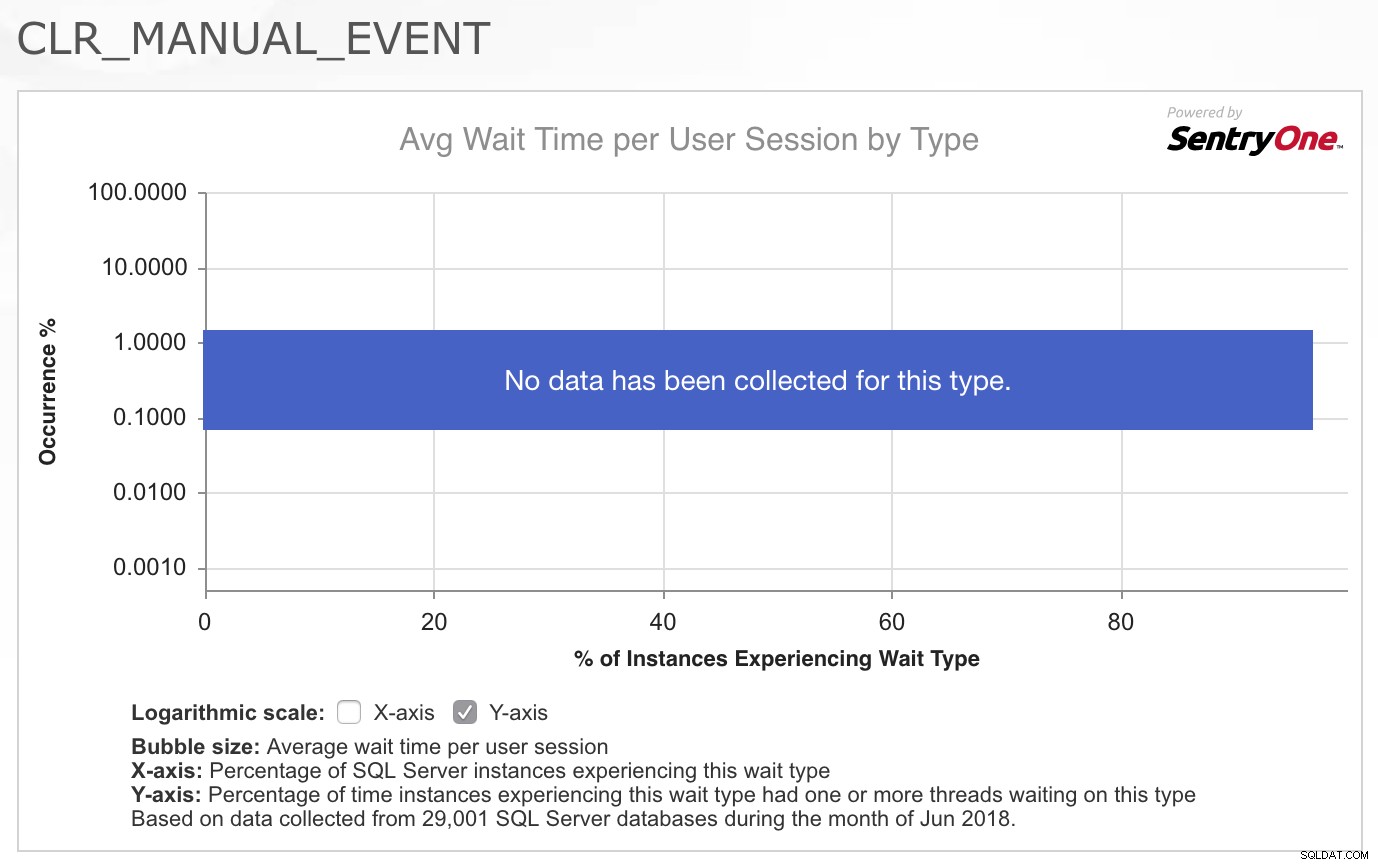
Le fait qu'aucune donnée n'ait été collectée pour ce type auprès d'un bon échantillon représentatif de leurs clients m'a vraiment confirmé que ce n'est pas quelque chose qui est généralement un problème, j'ai donc été intrigué par le fait que cette charge de travail spécifique présentait maintenant problèmes avec cette attente. Je ne savais pas trop où aller pour approfondir le problème, j'ai donc répondu à l'e-mail en disant que j'étais désolé de ne pas pouvoir aider davantage car je n'avais aucune idée de ce qui causerait littéralement des dizaines de threads effectuant des requêtes spatiales à tout d'un coup, il faut attendre 2 à 4 secondes à la fois sur ce type d'attente.
Un jour plus tard, j'ai reçu un aimable e-mail de suivi de la personne qui a posé la question qui m'a informé qu'ils avaient résolu le problème. En effet, rien dans la charge de travail réelle de l'application n'avait changé, mais une modification de l'environnement s'est produite. Un progiciel tiers a été installé sur tous les serveurs de leur infrastructure par leur équipe de sécurité, et ce logiciel collectait des données à des intervalles de cinq minutes et faisait en sorte que le traitement de la récupération de place .NET s'exécutait de manière incroyablement agressive et "devenait fou" comme ils ont dit. Armé de ces informations et d'une partie de mes connaissances passées sur le développement .NET, j'ai décidé de jouer avec cela et de voir si je pouvais reproduire le comportement et comment nous pouvions résoudre davantage les causes.
Informations générales
Au fil des ans, j'ai toujours suivi le blog PSSQL sur MSDN, et c'est généralement l'un de mes sites de référence lorsque je me souviens que j'ai lu un article sur un problème lié à SQL Server à un moment donné dans le passé, mais je peux ' Je ne me souviens pas de tous les détails.
Il existe un article de blog intitulé Attentes élevées sur CLR_MANUAL_EVENT et CLR_AUTO_EVENT par Jack Li de 2008 qui explique pourquoi ces attentes peuvent être ignorées en toute sécurité dans l'agrégat sys.dm_os_wait_stats DMV puisque les attentes se produisent dans des conditions normales, mais il ne précise pas quoi faire si les temps d'attente sont excessivement longs, ou ce qui pourrait les faire apparaître sur plusieurs threads dans sys.dm_os_waiting_tasks activement.
Il existe un autre article de blog de Jack Li de 2013 intitulé Un problème de performances impliquant la récupération de place CLR et le paramètre d'affinité CPU SQL auquel je fais référence dans notre classe de réglage des performances IEPTO2 lorsque je parle de considérations d'instances multiples et de la manière dont le Garbage Collector (GC) .NET déclenché par une instance peut avoir un impact sur les autres instances sur le même serveur.
Le GC dans .NET existe pour réduire l'utilisation de la mémoire des applications utilisant CLR en permettant à la mémoire allouée aux objets d'être nettoyée automatiquement, éliminant ainsi le besoin pour les développeurs d'avoir à gérer manuellement l'allocation et la désallocation de mémoire dans la mesure requise par le code non managé. . La fonctionnalité GC est documentée dans la documentation en ligne si vous souhaitez en savoir plus sur son fonctionnement, mais les détails au-delà du fait que les collections peuvent bloquer ne sont pas importants pour le dépannage des attentes actives sur CLR_MANUAL_EVENT dans SQL Server plus loin.
Aller à la racine du problème
Sachant que la récupération de place par .NET était à l'origine du problème, j'ai décidé de faire des expériences en utilisant une seule requête spatiale sur AdventureWorks2016 et un script PowerShell très simple pour invoquer le ramasse-miettes manuellement dans une boucle pour suivre ce qui se passe dans sys.dm_os_waiting_tasks à l'intérieur de SQL Server pour la requête :
USE AdventureWorks2016; GO SELECT a.SpatialLocation.ToString(), a.City, b.SpatialLocation.ToString(), b.City FROM Person.Address AS a INNER JOIN Person.Address AS b ON a.SpatialLocation.STDistance(b.SpatialLocation) <= 100 ORDER BY a.SpatialLocation.STDistance(b.SpatialLocation);
Cette requête compare toutes les adresses dans Person.Address table les unes par rapport aux autres pour trouver toute adresse située à moins de 100 mètres de toute autre adresse de la table. Cela crée une tâche parallèle de longue durée à l'intérieur de SQL Server qui produit également un grand résultat cartésien. Si vous décidez de reproduire ce comportement par vous-même, ne vous attendez pas à ce que cela se termine ou renvoie des résultats. Avec la requête en cours d'exécution, le thread parent de la tâche commence à attendre CXPACKET attend et la requête poursuit son traitement pendant plusieurs minutes. Cependant, ce qui m'intéressait, c'était ce qui se passait lorsque la récupération de place se produisait dans le runtime CLR ou si le GC était invoqué. J'ai donc utilisé un simple script PowerShell qui bouclerait et forcerait manuellement le GC à s'exécuter.
REMARQUE :CECI N'EST PAS UNE PRATIQUE RECOMMANDÉE DANS LE CODE DE PRODUCTION POUR DE NOMBREUSES RAISONS !
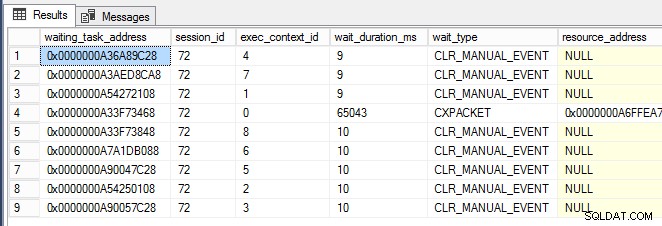
while (1 -eq 1) {[System.GC]::Collect() } Une fois la fenêtre PowerShell en cours d'exécution, j'ai presque immédiatement commencé à voir CLR_MANUAL_EVENT les attentes se produisant sur les threads de sous-tâches parallèles (illustrés ci-dessous, où exec_context_id est supérieur à zéro) dans sys.dm_os_waiting_tasks :
Maintenant que je pouvais déclencher ce comportement et qu'il commençait à devenir clair que SQL Server n'est pas nécessairement le problème ici et peut simplement être victime d'une autre activité, je voulais savoir comment creuser plus profondément et identifier la cause première du problème . C'est là que PerfMon s'est avéré utile pour suivre le groupe de compteurs de mémoire .NET CLR pour toutes les tâches sur le serveur.
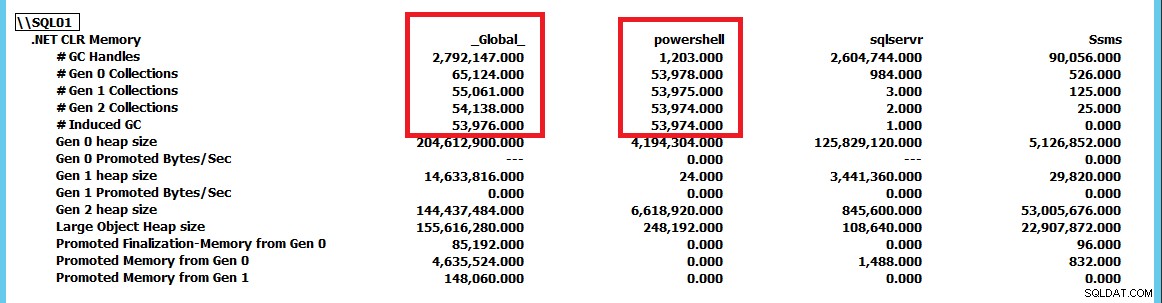
Cette capture d'écran a été réduite pour montrer les collections pour sqlservr et powershell en tant qu'applications par rapport au _Global_ collections par le runtime .NET. En forçant GC.Collect() pour fonctionner constamment, nous pouvons voir que le powershell instance pilote les collections GC sur le serveur. À l'aide de ce groupe de compteurs PerfMon, nous pouvons suivre les applications qui effectuent le plus de collectes et, à partir de là, poursuivre l'étude du problème. Dans ce cas, le simple fait d'arrêter le script PowerShell élimine le CLR_MANUAL_EVENT attend à l'intérieur de SQL Server et la requête continue de se traiter jusqu'à ce que nous l'arrêtions ou lui permettions de renvoyer le milliard de lignes de résultats qu'elle produirait.
Conclusion
Si vous avez des attentes actives pour CLR_MANUAL_EVENT causant des ralentissements d'application, ne supposez pas automatiquement que le problème existe à l'intérieur de SQL Server. SQL Server utilise la récupération de place au niveau du serveur (au moins avant SQL Server 2017 CU4 où les petits serveurs avec moins de 2 Go de RAM peuvent utiliser la récupération de place au niveau du client pour réduire l'utilisation des ressources). Si vous constatez que ce problème se produit dans SQL Server, utilisez le groupe de compteurs de mémoire .NET CLR dans PerfMon et vérifiez si une autre application pilote la récupération de place dans CLR et bloque les tâches CLR en interne dans SQL Server.



