La pagination est un cas d'utilisation courant dans les applications client et Web partout. Google vous affiche 10 résultats à la fois, votre banque en ligne peut afficher 20 factures par page, et les logiciels de suivi des bogues et de contrôle des sources peuvent afficher 50 éléments à l'écran.
Je voulais examiner l'approche de pagination commune sur SQL Server 2012 - OFFSET / FETCH (un équivalent standard de la clause LIMIT privée de MySQL) - et suggérer une variation qui conduira à des performances de pagination plus linéaires sur l'ensemble de l'ensemble, au lieu d'être seulement optimal au début. Ce qui, malheureusement, est tout ce que beaucoup de magasins vont tester.
Qu'est-ce que la pagination dans SQL Server ?
En fonction de l'indexation de la table, des colonnes nécessaires et de la méthode de tri choisie, la pagination peut être relativement simple. Si vous recherchez les 20 "premiers" clients et que l'index clusterisé prend en charge ce tri (par exemple, un index clusterisé sur une colonne IDENTITY ou une colonne DateCreated), la requête sera relativement efficace. Si vous avez besoin de prendre en charge un tri qui nécessite des index non clusterisés, et surtout si vous avez des colonnes nécessaires pour la sortie qui ne sont pas couvertes par l'index (peu importe s'il n'y a pas d'index de support), les requêtes peuvent devenir plus coûteuses. Et même la même requête (avec un paramètre @PageNumber différent) peut coûter beaucoup plus cher à mesure que le @PageNumber augmente, car davantage de lectures peuvent être nécessaires pour accéder à cette "tranche" de données.
Certains diront que progresser vers la fin de l'ensemble est quelque chose que vous pouvez résoudre en consacrant plus de mémoire au problème (ainsi vous éliminez toute E/S physique) et/ou en utilisant la mise en cache au niveau de l'application (ainsi vous n'allez pas la base de données du tout). Supposons, pour les besoins de cet article, que plus de mémoire n'est pas toujours possible, car tous les clients ne peuvent pas ajouter de RAM à un serveur qui n'a plus d'emplacements de mémoire ou qu'ils ne contrôlent pas, ou simplement claquer des doigts et avoir des serveurs plus récents et plus gros prêts aller. D'autant plus que certains clients sont sur l'édition Standard, donc plafonnés à 64 Go (SQL Server 2012) ou 128 Go (SQL Server 2014), ou utilisent des éditions encore plus limitées telles qu'Express (1 Go) ou l'une des nombreuses offres cloud.
J'ai donc voulu examiner l'approche de pagination commune sur SQL Server 2012 - OFFSET / FETCH - et suggérer une variation qui conduira à des performances de pagination plus linéaires sur l'ensemble de l'ensemble, au lieu d'être optimales uniquement au début. Ce qui, malheureusement, est tout ce que beaucoup de magasins vont tester.
Configuration des données de pagination / Exemple
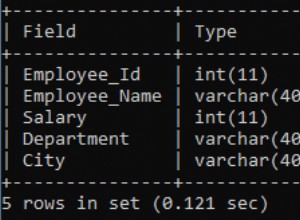
Je vais emprunter un autre article, Mauvaises habitudes :Se concentrer uniquement sur l'espace disque lors du choix des clés, où j'ai rempli le tableau suivant avec 1 000 000 lignes de données client aléatoires (mais pas tout à fait réalistes) :
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Comme je savais que je testerais les E/S ici et que je testerais à la fois à partir d'un cache chaud et froid, j'ai rendu le test au moins un peu plus juste en reconstruisant tous les index pour minimiser la fragmentation (comme cela se ferait moins de manière perturbatrice, mais régulière, sur la plupart des systèmes occupés qui effectuent tout type de maintenance d'index) :
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Après la reconstruction, la fragmentation arrive maintenant à 0,05 % - 0,17 % pour tous les index (niveau d'index =0), les pages sont remplies à plus de 99 % et le nombre de lignes/pages pour les index est le suivant :
| Index | Nombre de pages | Nombre de lignes |
|---|---|---|
| C_PK_Customers_I (index clusterisé) | 19 210 | 1 000 000 |
| C_Email_Customers_I | 7 344 | 1 000 000 |
| C_Active_Customers_I (index filtré) | 13 648 | 815 235 |
| C_Name_Customers_I | 16 824 | 1 000 000 |
Index, nombre de pages, nombre de lignes
Ce n'est évidemment pas une table super large, et j'ai laissé la compression hors de l'image cette fois. J'explorerai peut-être plus de configurations lors d'un prochain test.
Comment paginer efficacement une requête SQL
Le concept de pagination - ne montrant à l'utilisateur que des lignes à la fois - est plus facile à visualiser qu'à expliquer. Pensez à l'index d'un livre physique, qui peut avoir plusieurs pages de références à des points dans le livre, mais organisé par ordre alphabétique. Pour simplifier, supposons que dix éléments tiennent sur chaque page de l'index. Cela pourrait ressembler à ceci :
Maintenant, si j'ai déjà lu les pages 1 et 2 de l'index, je sais que pour arriver à la page 3, je dois sauter 2 pages. Mais puisque je sais qu'il y a 10 éléments sur chaque page, je peux aussi penser que cela revient à sauter 2 x 10 éléments et à commencer par le 21e élément. Ou, pour le dire autrement, je dois ignorer les premiers (10 * (3-1)) éléments. Pour rendre cela plus générique, je peux dire que pour commencer à la page n, je dois ignorer les premiers (10 * (n-1)) éléments. Pour arriver à la première page, je saute 10*(1-1) items, pour terminer à l'item 1. Pour arriver à la deuxième page, je saute 10*(2-1) items, pour finir à l'item 11. Et ainsi sur.
Avec ces informations, les utilisateurs formuleront une requête de pagination comme celle-ci, étant donné que les clauses OFFSET / FETCH ajoutées dans SQL Server 2012 ont été spécifiquement conçues pour ignorer autant de lignes :
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Comme je l'ai mentionné ci-dessus, cela fonctionne très bien s'il existe un index qui prend en charge ORDER BY et qui couvre toutes les colonnes de la clause SELECT (et, pour les requêtes plus complexes, les clauses WHERE et JOIN). Cependant, les coûts de tri peuvent être écrasants sans index de support, et si les colonnes de sortie ne sont pas couvertes, vous vous retrouverez avec tout un tas de recherches de clés, ou vous pouvez même obtenir une analyse de table dans certains scénarios.
Bonnes pratiques de tri de la pagination SQL
Compte tenu de la table et des index ci-dessus, je voulais tester ces scénarios, où nous voulons afficher 100 lignes par page et afficher toutes les colonnes de la table :
- Par défaut –
ORDER BY CustomerID(index clusterisé). C'est l'ordre le plus pratique pour les gens de la base de données, car il ne nécessite aucun tri supplémentaire et toutes les données de cette table qui pourraient éventuellement être nécessaires pour l'affichage sont incluses. D'un autre côté, ce n'est peut-être pas l'index le plus efficace à utiliser si vous affichez un sous-ensemble de la table. La commande peut également ne pas avoir de sens pour les utilisateurs finaux, en particulier si CustomerID est un identifiant de substitution sans signification externe. - Répertoire téléphonique –
ORDER BY LastName, FirstName(prise en charge des index non clusterisés). Il s'agit du classement le plus intuitif pour les utilisateurs, mais il nécessiterait un index non clusterisé pour prendre en charge à la fois le tri et la couverture. Sans index de prise en charge, la table entière devrait être analysée. - Défini par l'utilisateur –
ORDER BY FirstName DESC, EMail(pas d'index à l'appui). Cela représente la possibilité pour l'utilisateur de choisir l'ordre de tri qu'il souhaite, un modèle contre lequel Michael J. Swart met en garde dans "UI Design Patterns That Don't Scale".
Je voulais tester ces méthodes et comparer les plans et les métriques lorsque, dans des scénarios de cache chaud et de cache froid, je regardais la page 1, la page 500, la page 5 000 et la page 9 999. J'ai créé ces procédures (ne différant que par la clause ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail En réalité, vous n'aurez probablement qu'une seule procédure qui utilise du SQL dynamique (comme dans mon exemple "évier de cuisine") ou une expression CASE pour dicter l'ordre.
Dans les deux cas, vous pouvez obtenir de meilleurs résultats en utilisant OPTION (RECOMPILE) sur la requête pour éviter la réutilisation des plans qui sont optimaux pour une option de tri mais pas pour toutes. J'ai créé des procédures séparées ici pour supprimer ces variables; J'ai ajouté OPTION (RECOMPILE) pour ces tests afin d'éviter le reniflage de paramètres et d'autres problèmes d'optimisation sans vider l'intégralité du cache du plan à plusieurs reprises.
Une autre approche de la pagination SQL Server pour de meilleures performances
Une approche légèrement différente, que je ne vois pas très souvent mise en œuvre, consiste à localiser la "page" sur laquelle nous nous trouvons en utilisant uniquement la clé de clustering, puis à la joindre :
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
C'est du code plus verbeux, bien sûr, mais j'espère que ce que SQL Server peut être contraint de faire est clair :éviter une analyse, ou au moins différer les recherches jusqu'à ce qu'un ensemble de résultats beaucoup plus petit soit réduit. Paul White (@SQL_Kiwi) a étudié une approche similaire en 2010, avant que OFFSET/FETCH ne soit introduit dans les premières versions bêta de SQL Server 2012 (j'ai d'abord blogué à ce sujet plus tard cette année-là).
Compte tenu des scénarios ci-dessus, j'ai créé trois procédures supplémentaires, avec la seule différence entre la ou les colonnes spécifiées dans les clauses ORDER BY (nous en avons maintenant besoin de deux, une pour la page elle-même et une pour ordonner le résultat):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Remarque :Cela peut ne pas fonctionner aussi bien si votre clé primaire n'est pas en cluster - une partie de l'astuce qui améliore ce fonctionnement, lorsqu'un index de support peut être utilisé, est que la clé de clustering est déjà dans l'index, donc un la recherche est souvent évitée.
Tester le tri des clés de clustering
J'ai d'abord testé le cas où je ne m'attendais pas à beaucoup de variance entre les deux méthodes - tri par clé de regroupement. J'ai exécuté ces instructions dans un lot dans SQL Sentry Plan Explorer et j'ai observé la durée, les lectures et les plans graphiques, en m'assurant que chaque requête partait d'un cache complètement froid :
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
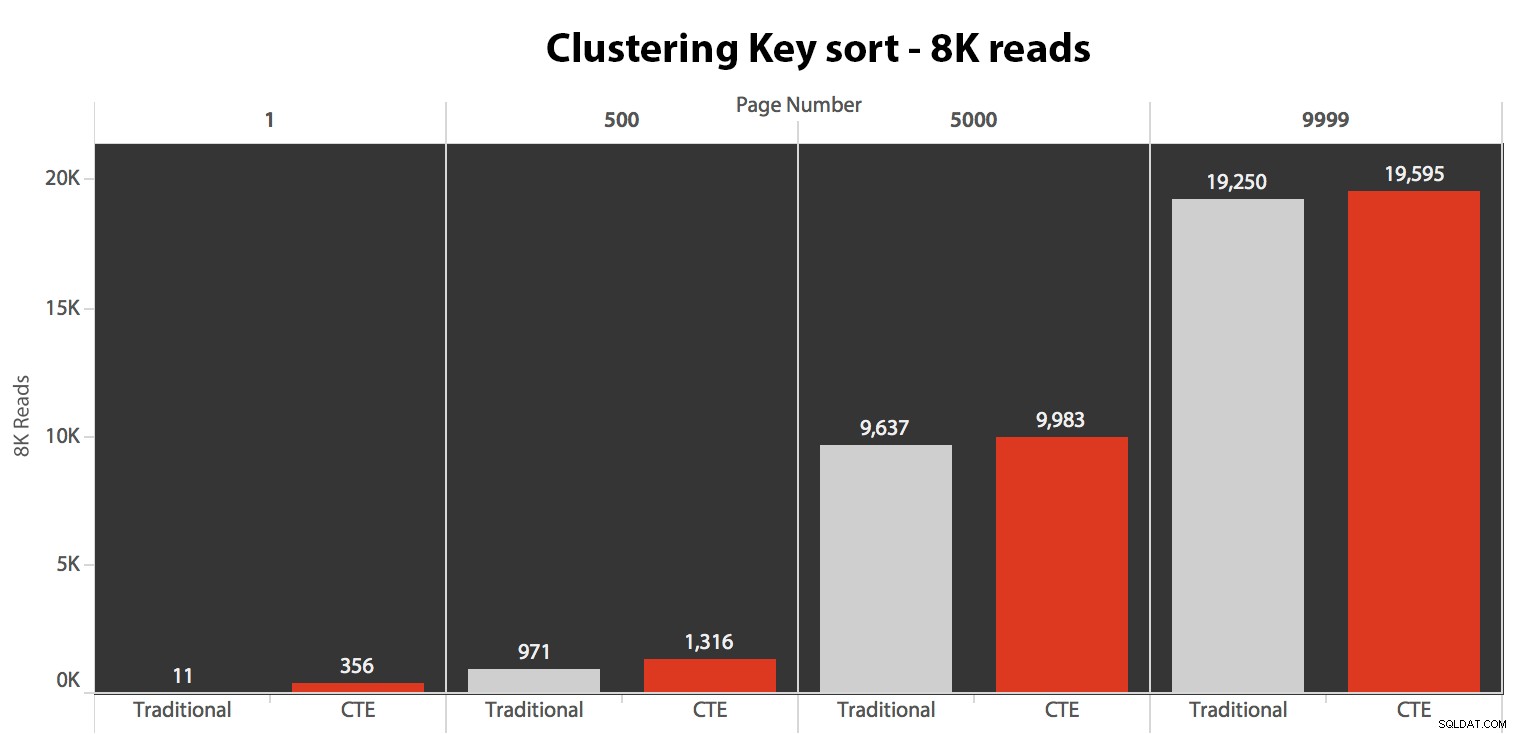
Les résultats ici n'étaient pas étonnants. Sur 5 exécutions, le nombre moyen de lectures est affiché ici, montrant des différences négligeables entre les deux requêtes, sur tous les numéros de page, lors du tri par clé de regroupement :
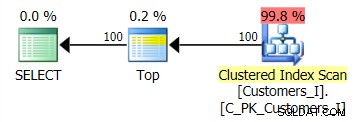
Le plan pour la méthode par défaut (comme indiqué dans Plan Explorer) dans tous les cas était le suivant :
Alors que le plan pour la méthode basée sur le CTE ressemblait à ceci :
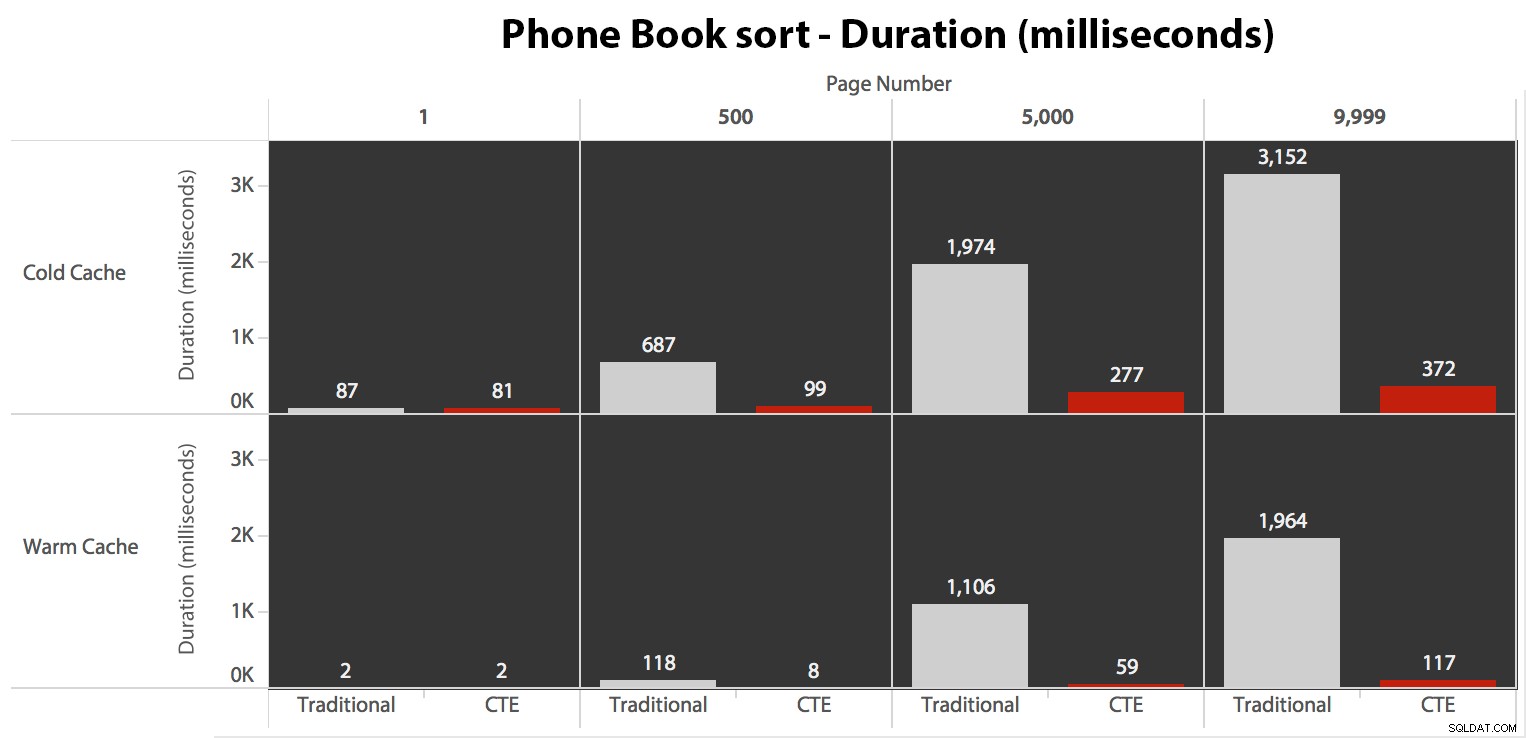
Maintenant, alors que les E/S étaient les mêmes indépendamment de la mise en cache (juste beaucoup plus de lectures anticipées dans le scénario de cache froid), j'ai mesuré la durée avec un cache froid et aussi avec un cache chaud (où j'ai commenté les commandes DROPCLEANBUFFERS et exécuté les requêtes plusieurs fois avant de mesurer). Ces durées ressemblaient à ceci :
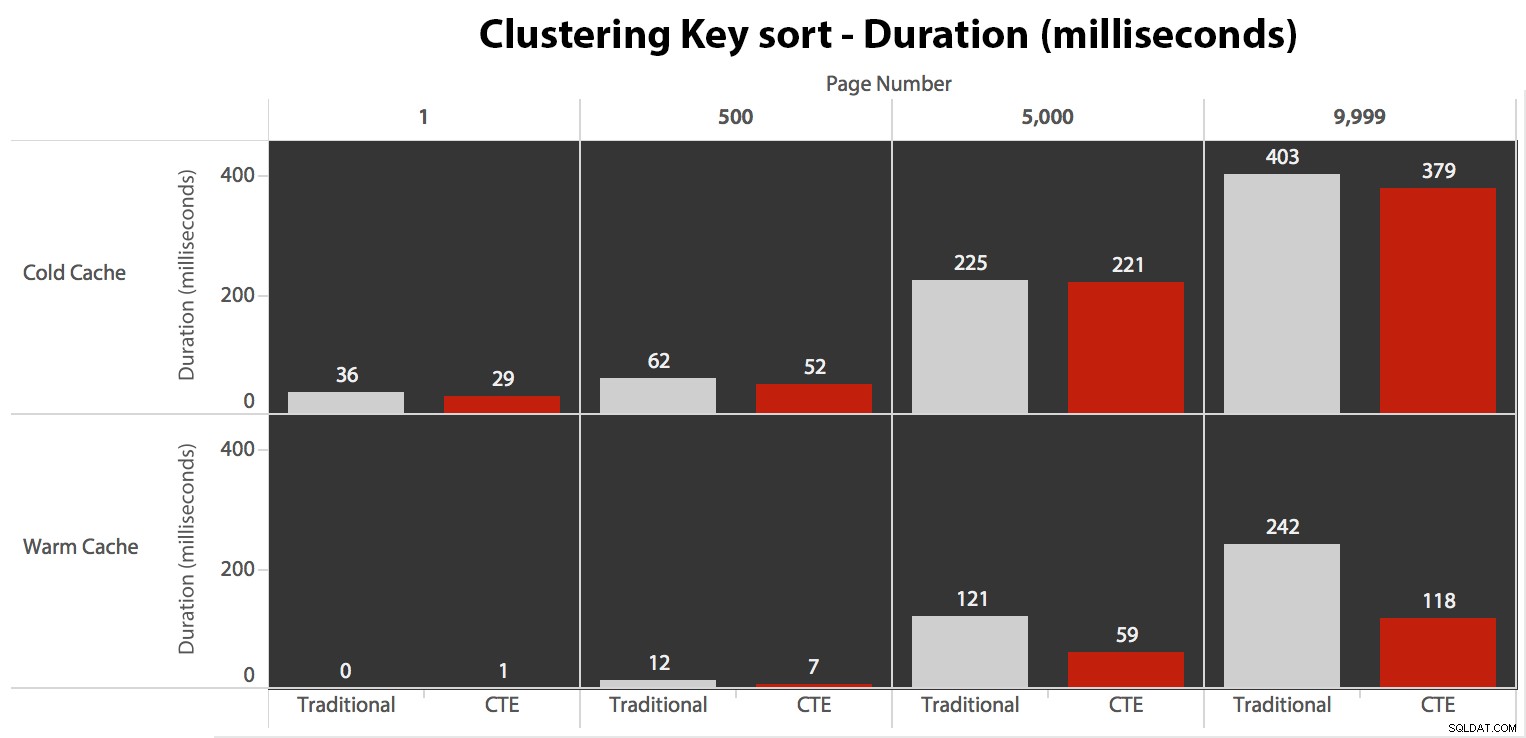
Bien que vous puissiez voir un modèle qui montre que la durée augmente à mesure que le numéro de page augmente, gardez à l'esprit l'échelle :pour atteindre les lignes 999 801 -> 999 900, nous parlons d'une demi-seconde dans le pire des cas et de 118 millisecondes dans le meilleur des cas. L'approche CTE gagne, mais pas de beaucoup.
Test du tri du répertoire téléphonique
Ensuite, j'ai testé le deuxième cas, où le tri était pris en charge par un index non couvrant sur LastName, FirstName. La requête ci-dessus vient de modifier toutes les instances de Test_1 à Test_2 . Voici les lectures utilisant un cache froid :
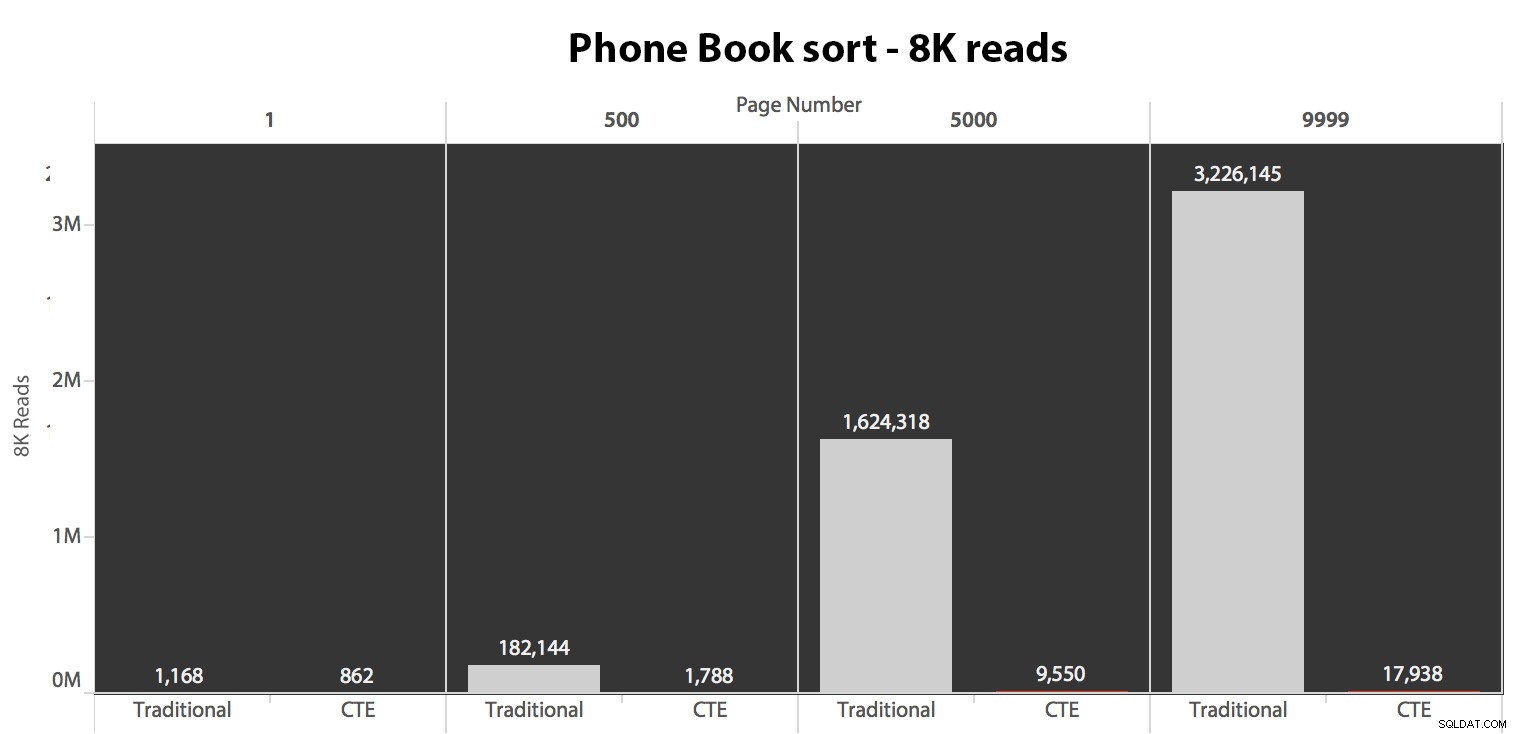
(Les lectures sous un cache tiède ont suivi le même schéma :les chiffres réels différaient légèrement, mais pas suffisamment pour justifier un graphique séparé.)
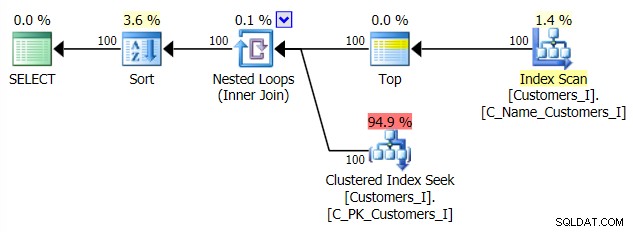
Lorsque nous n'utilisons pas l'index clusterisé pour trier, il est clair que les coûts d'E/S impliqués avec la méthode traditionnelle de OFFSET/FETCH sont bien pires que lors de l'identification des clés en premier dans un CTE et de l'extraction du reste des colonnes juste pour ce sous-ensemble.
Voici le plan de l'approche de requête traditionnelle :
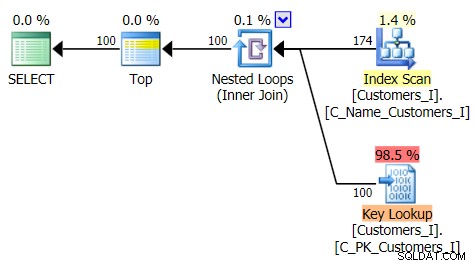
Et le plan de mon approche alternative, CTE :
Enfin, les durées :
L'approche traditionnelle montre une augmentation très évidente de la durée à mesure que vous avancez vers la fin de la pagination. L'approche CTE montre également un modèle non linéaire, mais il est beaucoup moins prononcé et donne un meilleur timing à chaque numéro de page. Nous voyons 117 millisecondes pour l'avant-dernière page, alors que l'approche traditionnelle prend presque deux secondes.
Tester le tri défini par l'utilisateur
Enfin, j'ai changé la requête pour utiliser le Test_3 procédures stockées, en testant le cas où le tri était défini par l'utilisateur et n'avait pas d'index de support. Les E/S étaient cohérentes dans chaque ensemble de tests ; le graphique est tellement inintéressant, je vais juste y faire un lien. Pour faire court :il y a eu un peu plus de 19 000 lectures dans tous les tests. La raison en est que chaque variation devait effectuer une analyse complète en raison de l'absence d'index pour prendre en charge la commande. Voici le plan de l'approche traditionnelle :
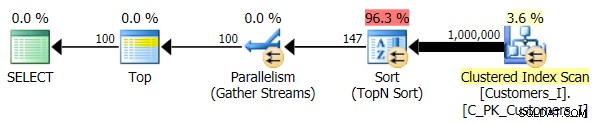
Et tandis que le plan pour la version CTE de la requête semble alarmant plus complexe…
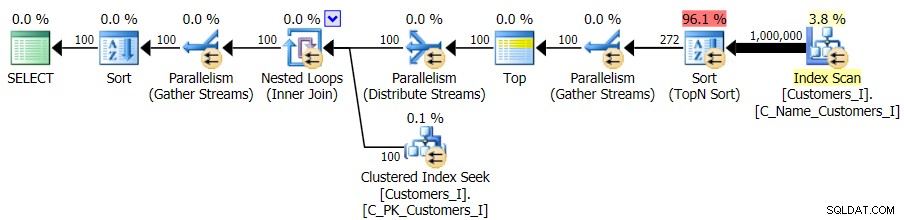
… cela conduit à des durées inférieures dans tous les cas sauf un. Voici les durées :
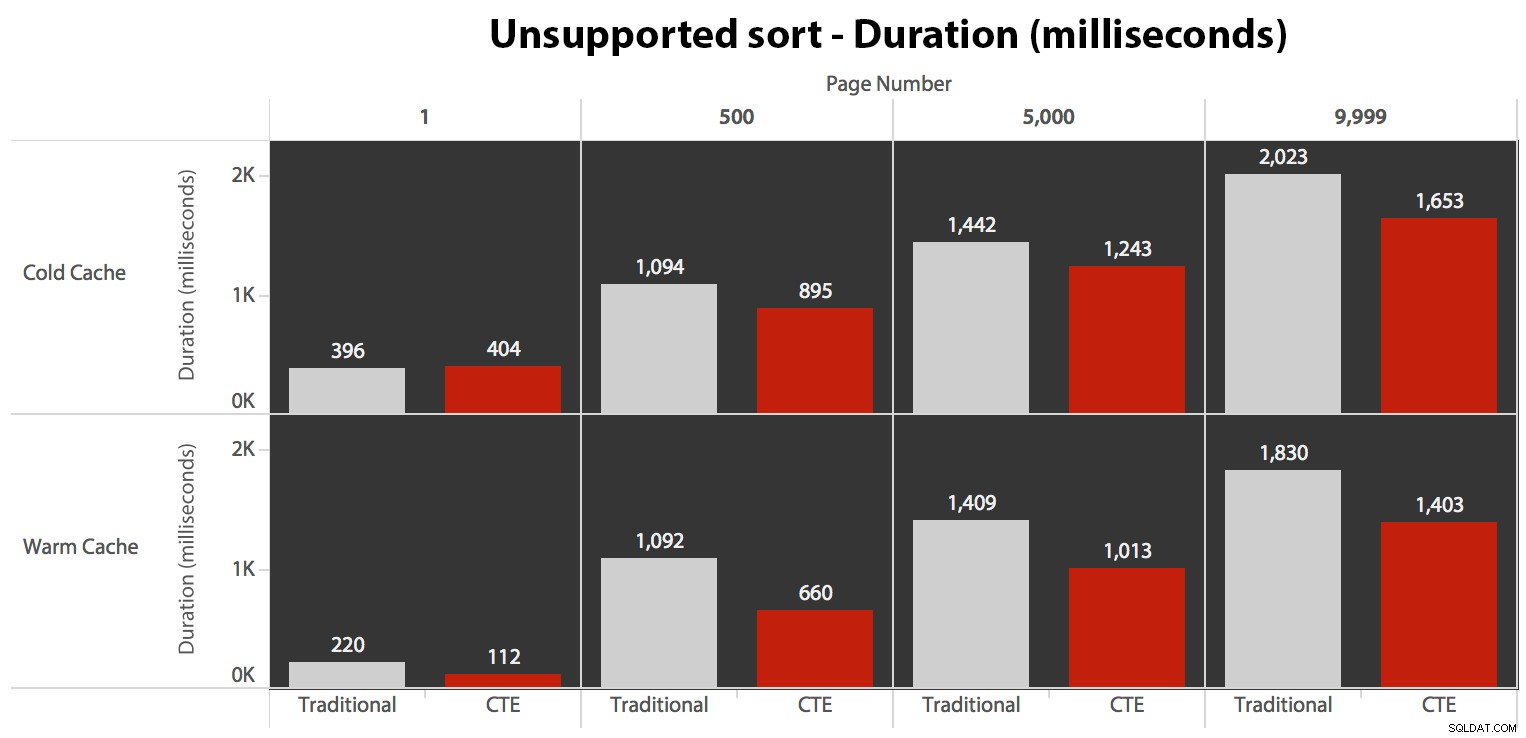
Vous pouvez voir que nous ne pouvons pas obtenir de performances linéaires ici en utilisant l'une ou l'autre méthode, mais le CTE arrive en tête avec une bonne marge (de 16 % à 65 % de mieux) dans tous les cas, sauf la requête de cache à froid contre le premier page (où il a perdu par un énorme 8 millisecondes). Il est également intéressant de noter que la méthode traditionnelle n'est pas du tout aidée par un cache chaud au "milieu" (pages 500 et 5000); ce n'est que vers la fin de l'ensemble que l'efficacité mérite d'être mentionnée.
Volume plus élevé
Après avoir testé individuellement quelques exécutions et pris des moyennes, j'ai pensé qu'il serait également judicieux de tester un volume élevé de transactions qui simuleraient en quelque sorte le trafic réel sur un système occupé. J'ai donc créé un travail avec 6 étapes, une pour chaque combinaison de méthode de requête (pagination traditionnelle contre CTE) et de type de tri (clé de clustering, annuaire téléphonique et non pris en charge), avec une séquence de 100 étapes pour frapper les quatre numéros de page ci-dessus , 10 fois chacun, et 60 autres numéros de page choisis au hasard (mais les mêmes pour chaque étape). Voici comment j'ai généré le script de création de tâche :
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Voici la liste d'étapes de travail résultante et l'une des propriétés de l'étape :
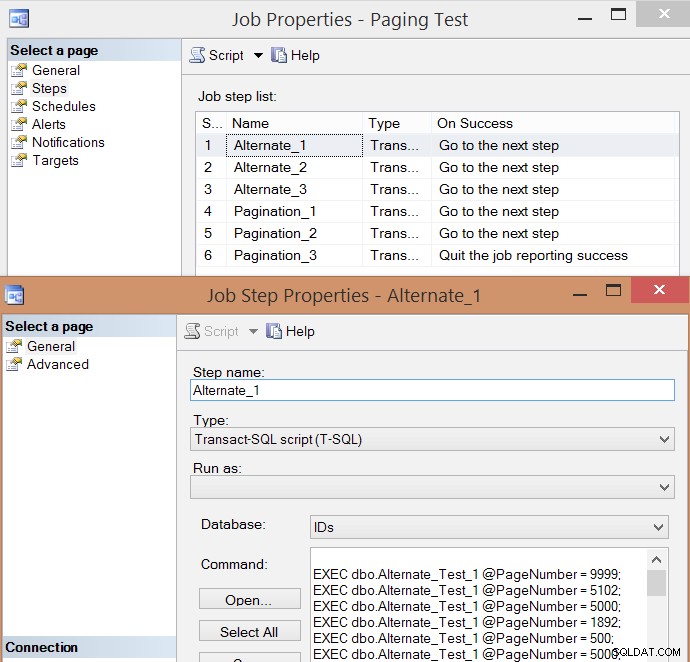
J'ai exécuté la tâche cinq fois, puis j'ai examiné l'historique des tâches, et voici les durées d'exécution moyennes de chaque étape :
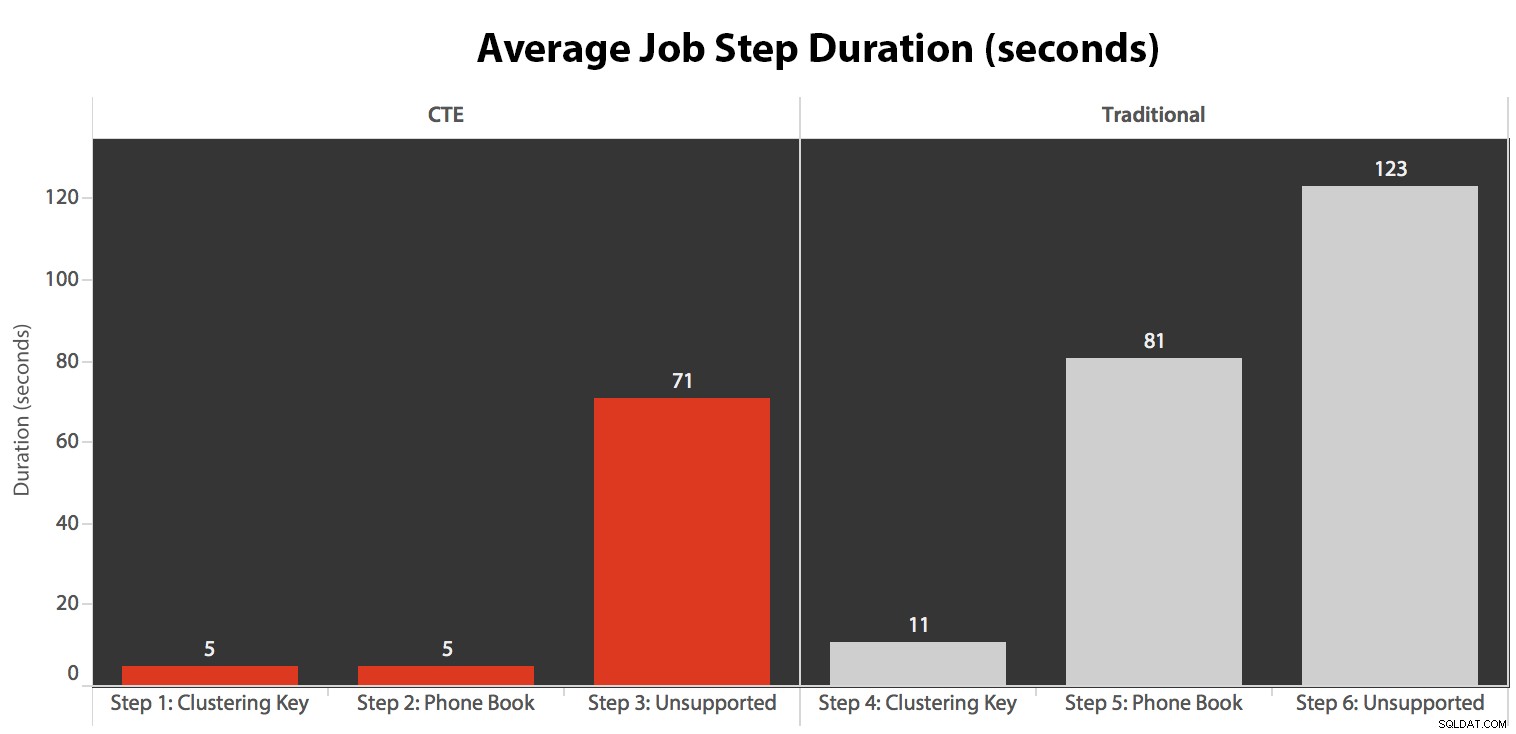
J'ai également corrélé une des exécutions sur le calendrier SQL Sentry Event Manager…
… avec le tableau de bord SQL Sentry, et marqué manuellement à peu près où chacune des six étapes s'est déroulée. Voici le graphique d'utilisation du processeur du côté Windows du tableau de bord :
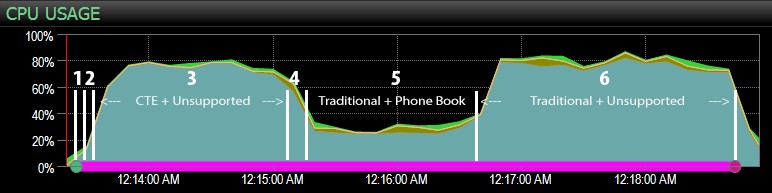
Et du côté SQL Server du tableau de bord, les métriques intéressantes se trouvaient dans les graphiques Key Lookups et Waits :
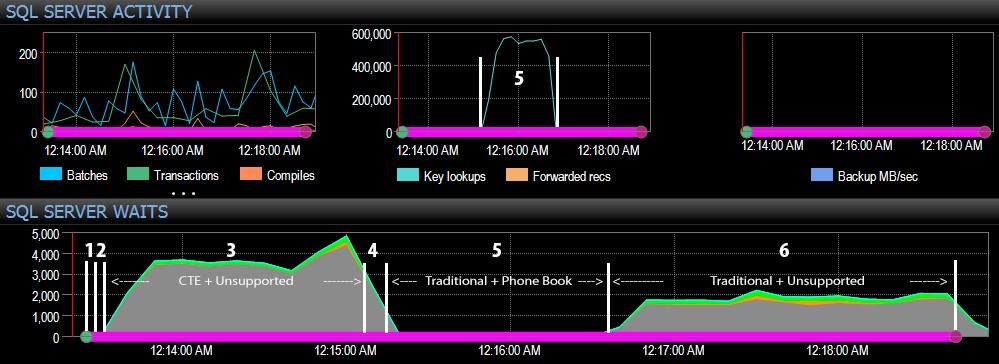
Les observations les plus intéressantes d'un point de vue purement visuel :
- Le processeur est assez chaud, à environ 80 %, lors de l'étape 3 (CTE + aucun index de support) et de l'étape 6 (traditionnel + aucun index de support) ;
- Les attentes CXPACKET sont relativement élevées lors de l'étape 3 et dans une moindre mesure lors de l'étape 6 ;
- vous pouvez voir l'énorme augmentation du nombre de recherches clés, à près de 600 000, en l'espace d'une minute environ (en corrélation avec l'étape 5 :l'approche traditionnelle avec un index de type annuaire téléphonique).
Dans un futur test - comme avec mon post précédent sur les GUID - j'aimerais tester cela sur un système où les données ne rentrent pas dans la mémoire (facile à simuler) et où les disques sont lents (pas si facile à simuler) , puisque certains de ces résultats bénéficient probablement de choses que tous les systèmes de production n'ont pas - des disques rapides et suffisamment de RAM. Je devrais également étendre les tests pour inclure plus de variations (en utilisant des colonnes maigres et larges, des index maigres et larges, un index d'annuaire téléphonique qui couvre en fait toutes les colonnes de sortie et un tri dans les deux sens). La dérive de la portée a définitivement limité l'étendue de mes tests pour cette première série de tests.
Comment améliorer la pagination de SQL Server
La pagination ne doit pas toujours être douloureuse; SQL Server 2012 facilite certainement la syntaxe, mais si vous branchez simplement la syntaxe native, vous ne verrez peut-être pas toujours un grand avantage. Ici, j'ai montré qu'une syntaxe légèrement plus détaillée utilisant un CTE peut conduire à de bien meilleures performances dans le meilleur des cas, et sans doute à des différences de performances négligeables dans le pire des cas. En séparant la localisation des données de la récupération des données en deux étapes différentes, nous pouvons voir un énorme avantage dans certains scénarios, en dehors des attentes CXPACKET plus élevées dans un cas (et même dans ce cas, les requêtes parallèles se sont terminées plus rapidement que les autres requêtes affichant peu ou pas d'attente, il était donc peu probable qu'ils soient les "mauvais" CXPACKET dont tout le monde vous avertit).
Pourtant, même la méthode la plus rapide est lente lorsqu'il n'y a pas d'index de support. Bien que vous puissiez être tenté d'implémenter un index pour chaque algorithme de tri possible qu'un utilisateur pourrait choisir, vous voudrez peut-être envisager de fournir moins d'options (puisque nous savons tous que les index ne sont pas gratuits). Par exemple, votre application doit-elle absolument prendre en charge le tri par LastName croissant *et* LastName décroissant ? S'ils veulent accéder directement aux clients dont le nom de famille commence par Z, ne peuvent-ils pas accéder à la *dernière* page et revenir en arrière ? C'est une décision commerciale et d'utilisation plus qu'une décision technique, gardez-la simplement en option avant de gifler les index sur chaque colonne de tri, dans les deux sens, afin d'obtenir les meilleures performances même pour les options de tri les plus obscures.