La haute disponibilité est incontournable de nos jours, car la plupart des organisations ne peuvent pas se permettre de perdre leurs données. Cependant, la haute disponibilité a toujours un prix (qui peut varier considérablement.) Toute configuration nécessitant une action presque immédiate nécessite généralement un environnement coûteux qui reflète précisément la configuration de production. Mais, il existe d'autres options qui peuvent être moins chères. Ceux-ci peuvent ne pas permettre un passage immédiat à un cluster de reprise après sinistre, mais ils permettront toujours la continuité des activités (et n'épuiseront pas le budget.)
Un exemple de ce type de configuration est un environnement DR "cold-standby". Cela vous permet de réduire vos dépenses tout en étant en mesure de créer un nouvel environnement dans un lieu externe en cas de catastrophe. Dans cet article de blog, nous allons montrer comment créer une telle configuration.
La configuration initiale
Supposons que nous ayons une configuration de réplication MySQL maître/esclave assez standard dans notre propre centre de données. Il s'agit d'une configuration hautement disponible avec ProxySQL et Keepalived pour la gestion des adresses IP virtuelles. Le principal risque est que le datacenter devienne indisponible. C'est un petit DC, peut-être qu'il n'y a qu'un seul FAI sans BGP en place. Et dans cette situation, nous supposerons que s'il fallait des heures pour ramener la base de données, ce n'est pas grave tant qu'il est possible de la ramener.
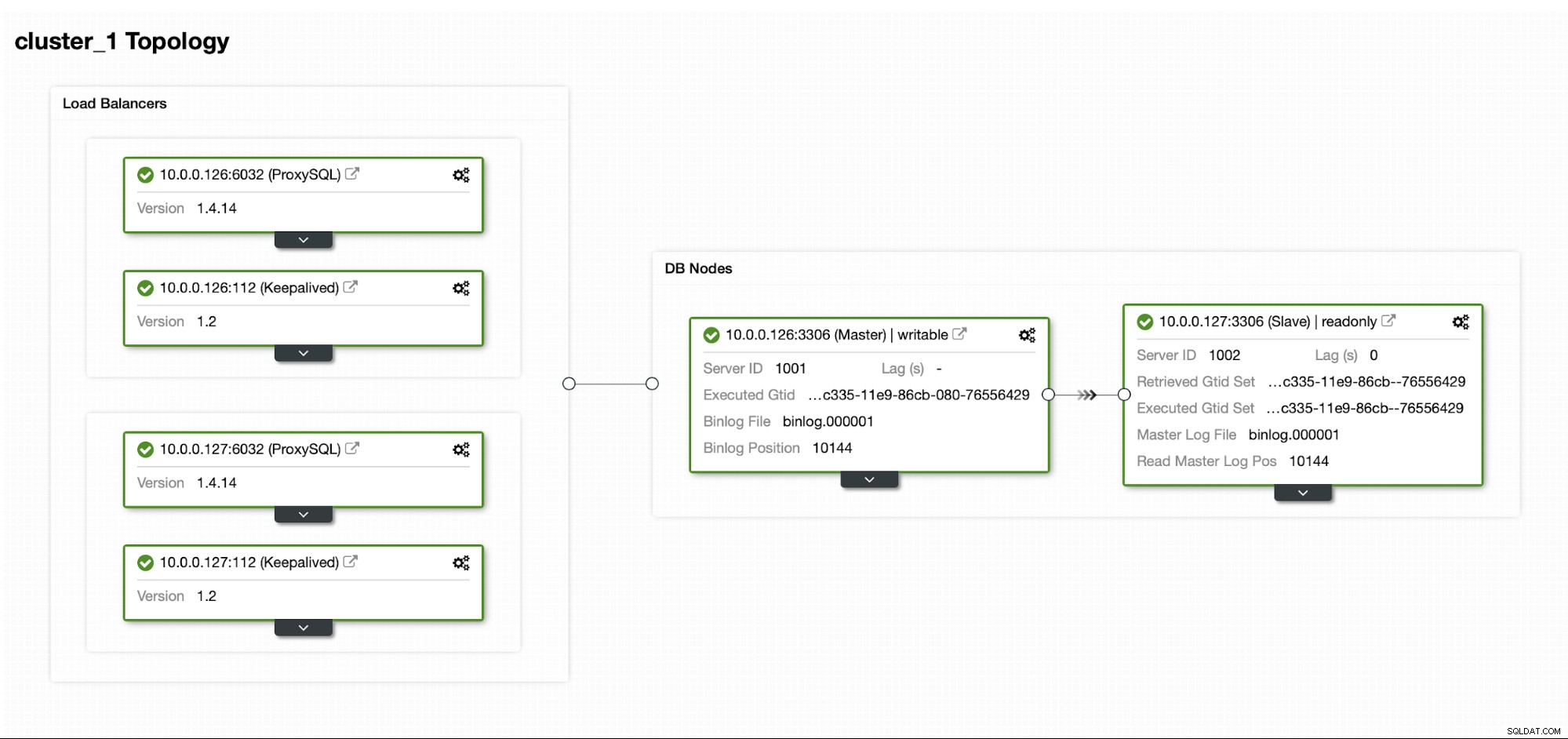
Pour déployer ce cluster, nous avons utilisé ClusterControl, que vous pouvez télécharger gratuitement. Pour notre environnement DR, nous utiliserons EC2 (mais il pourrait également s'agir de n'importe quel autre fournisseur de cloud.)
Le défi
Le principal problème auquel nous devons faire face est de savoir comment nous assurer que nous disposons de données fraîches pour restaurer notre base de données dans l'environnement de reprise après sinistre ? Bien sûr, idéalement, nous aurions un esclave de réplication opérationnel dans EC2... mais nous devons ensuite payer pour cela. Si nous sommes serrés sur le budget, nous pourrions essayer de contourner cela avec des sauvegardes. Ce n'est pas la solution parfaite car, dans le pire des cas, nous ne pourrons jamais récupérer toutes les données.
Par "le pire scénario", nous entendons une situation dans laquelle nous n'aurons pas accès aux serveurs de base de données d'origine. Si nous parvenons à les joindre, les données n'auront pas été perdues.
La solution
Nous allons utiliser ClusterControl pour configurer un calendrier de sauvegarde afin de réduire le risque de perte des données. Nous utiliserons également la fonctionnalité ClusterControl pour télécharger des sauvegardes sur le cloud. Si le datacenter ne sera pas disponible, nous pouvons espérer que le fournisseur de cloud que nous avons choisi sera joignable.
Configuration de la planification de sauvegarde dans ClusterControl
Tout d'abord, nous devrons configurer ClusterControl avec nos identifiants cloud.
Nous pouvons le faire en utilisant "Intégrations" dans le menu de gauche.
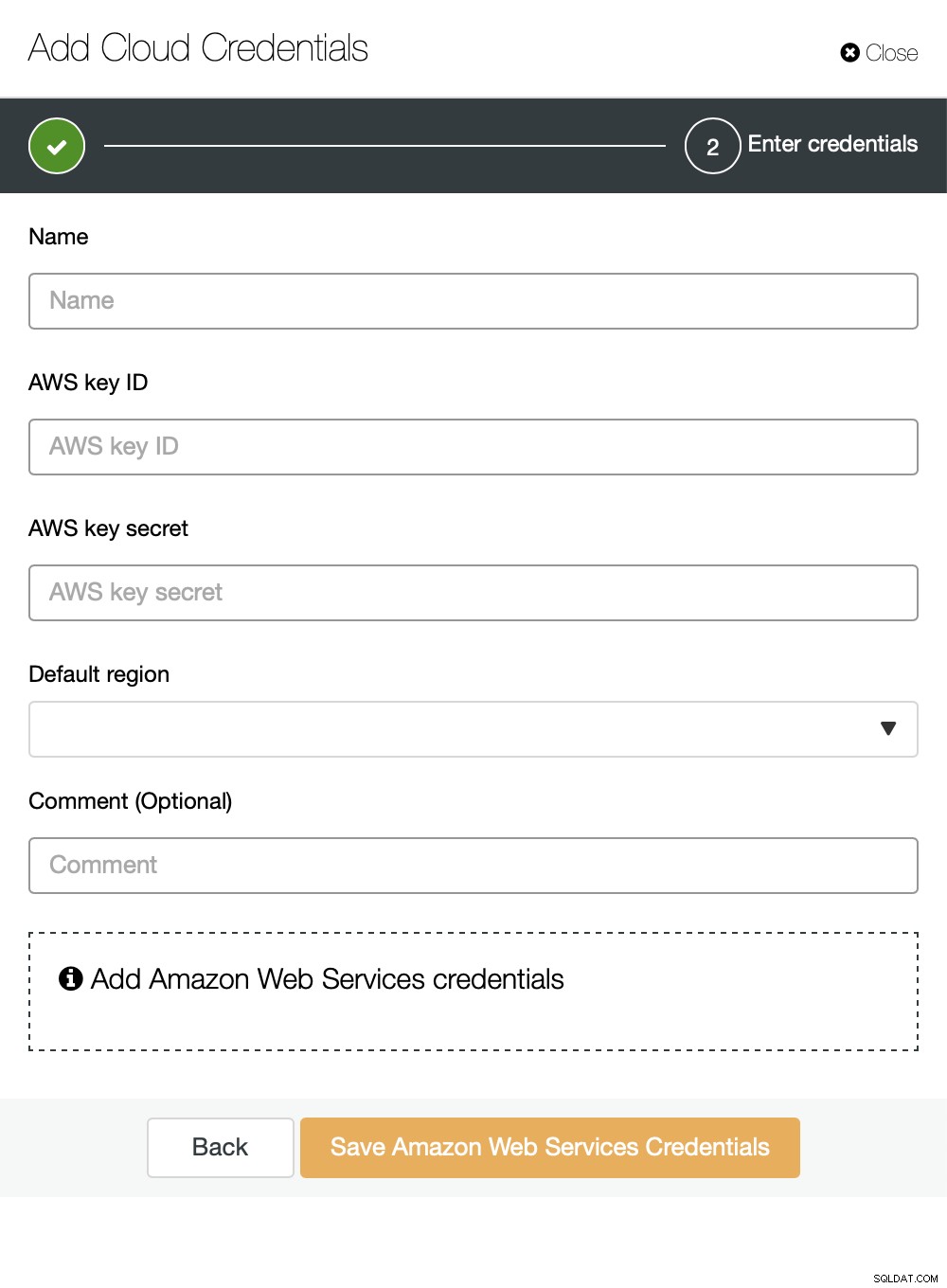
Vous pouvez choisir Amazon Web Services, Google Cloud ou Microsoft Azure comme cloud vous voulez que ClusterControl télécharge les sauvegardes. Nous continuerons avec AWS où ClusterControl utilisera S3 pour stocker les sauvegardes.
Nous devons ensuite transmettre l'ID de clé et la clé secrète, choisir la région par défaut et choisissez un nom pour cet ensemble d'informations d'identification.
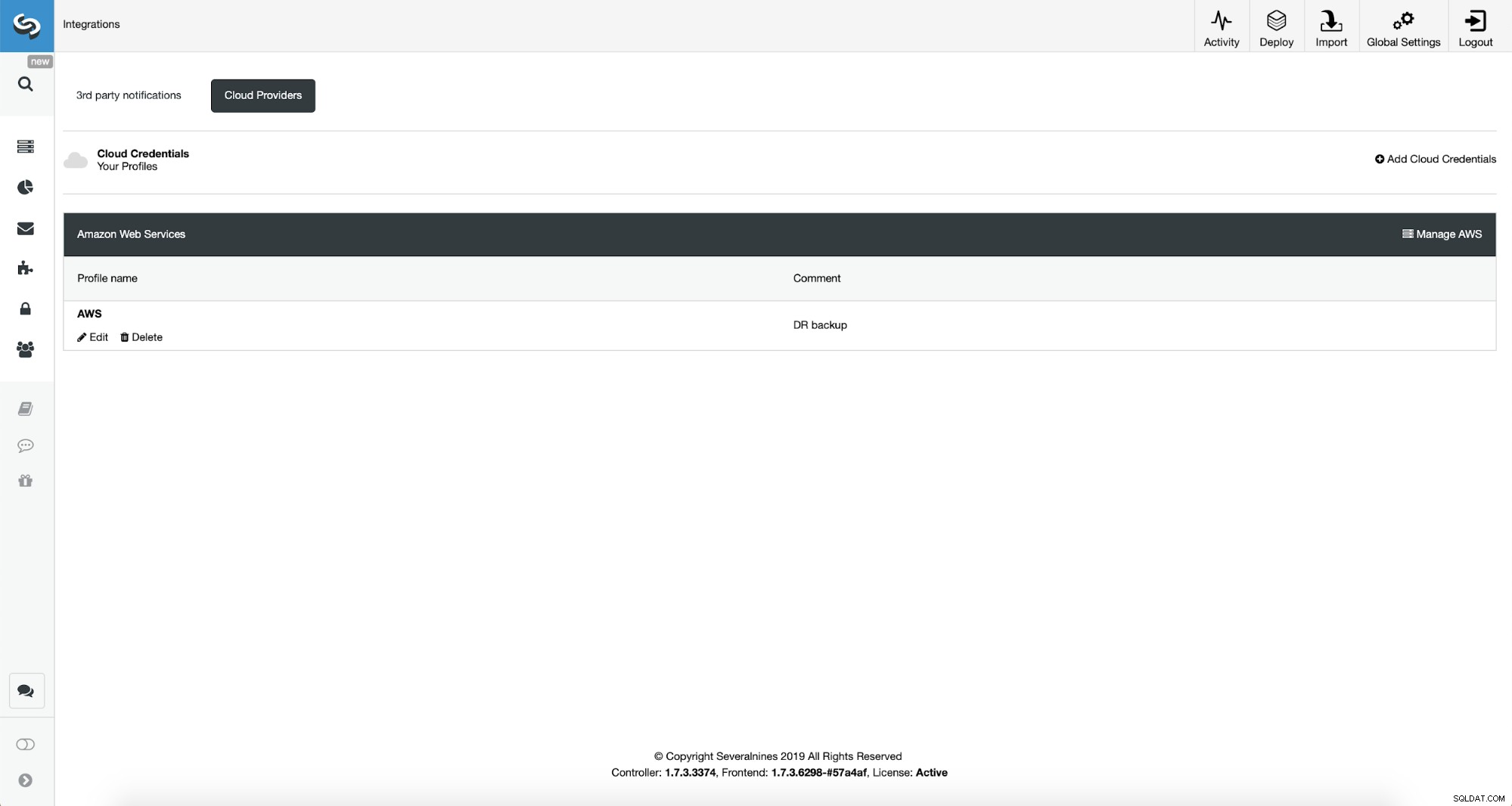
Une fois cela fait, nous pouvons voir les informations d'identification que nous venons d'ajouter répertoriées dans ClusterControl.
Maintenant, nous allons procéder à la configuration du calendrier de sauvegarde.
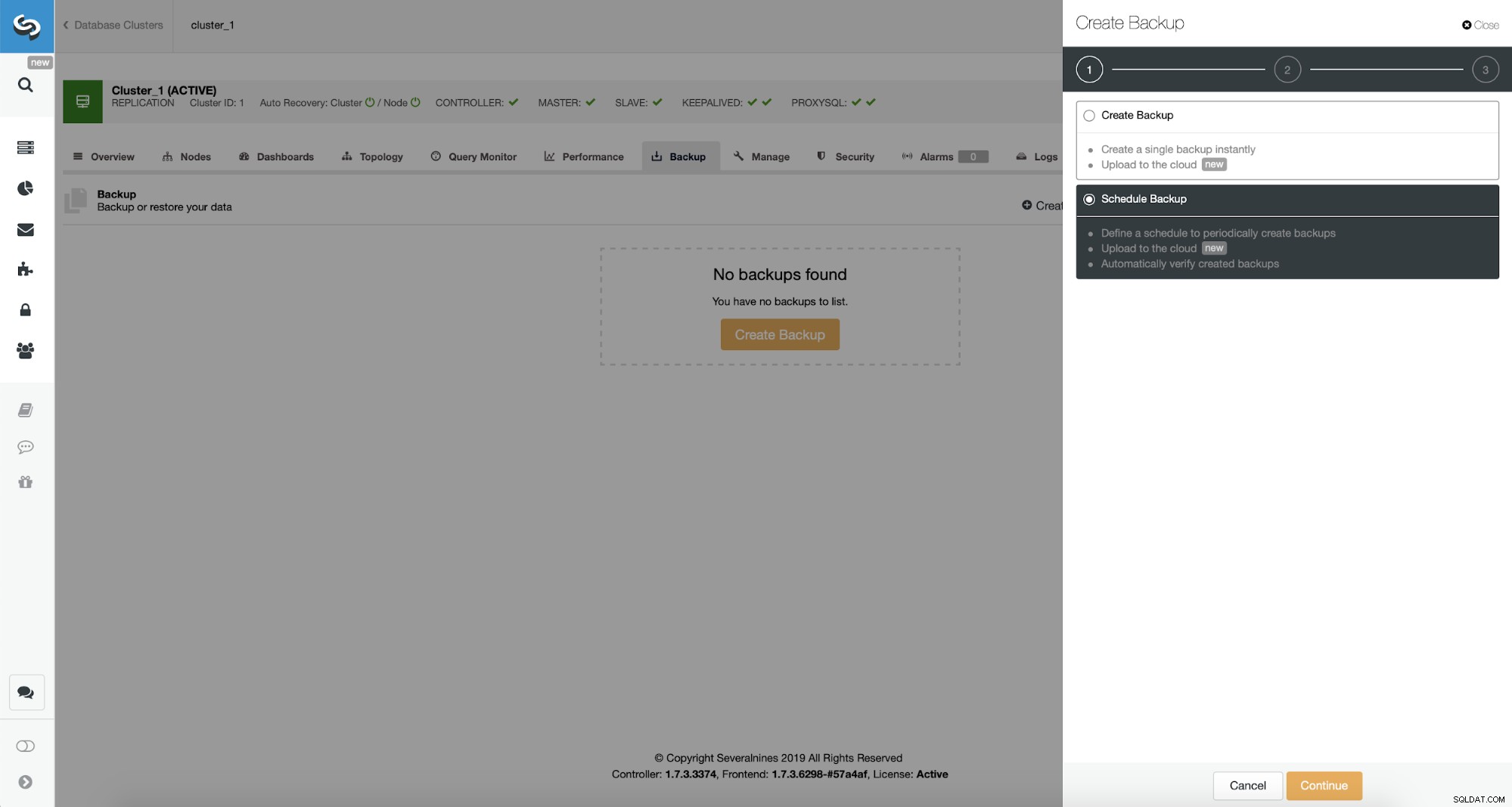
ClusterControl vous permet de créer une sauvegarde immédiatement ou de la planifier. Nous allons choisir la deuxième option. Ce que nous voulons, c'est créer un calendrier suivant :
- Sauvegarde complète créée une fois par jour
- Sauvegardes incrémentielles créées toutes les 10 minutes.
L'idée ici est la suivante. Dans le pire des cas, nous ne perdrons que 10 minutes de trafic. Si le centre de données devenait indisponible de l'extérieur mais qu'il fonctionnerait en interne, nous pourrions essayer d'éviter toute perte de données en attendant 10 minutes, en copiant la dernière sauvegarde incrémentielle sur un ordinateur portable, puis nous pouvons l'envoyer manuellement vers notre base de données DR en utilisant même la connexion téléphonique. et une connexion cellulaire pour contourner la panne du FAI. Si nous ne pourrons pas extraire les données de l'ancien centre de données pendant un certain temps, cela vise à minimiser le nombre de transactions que nous devrons fusionner manuellement dans la base de données DR.
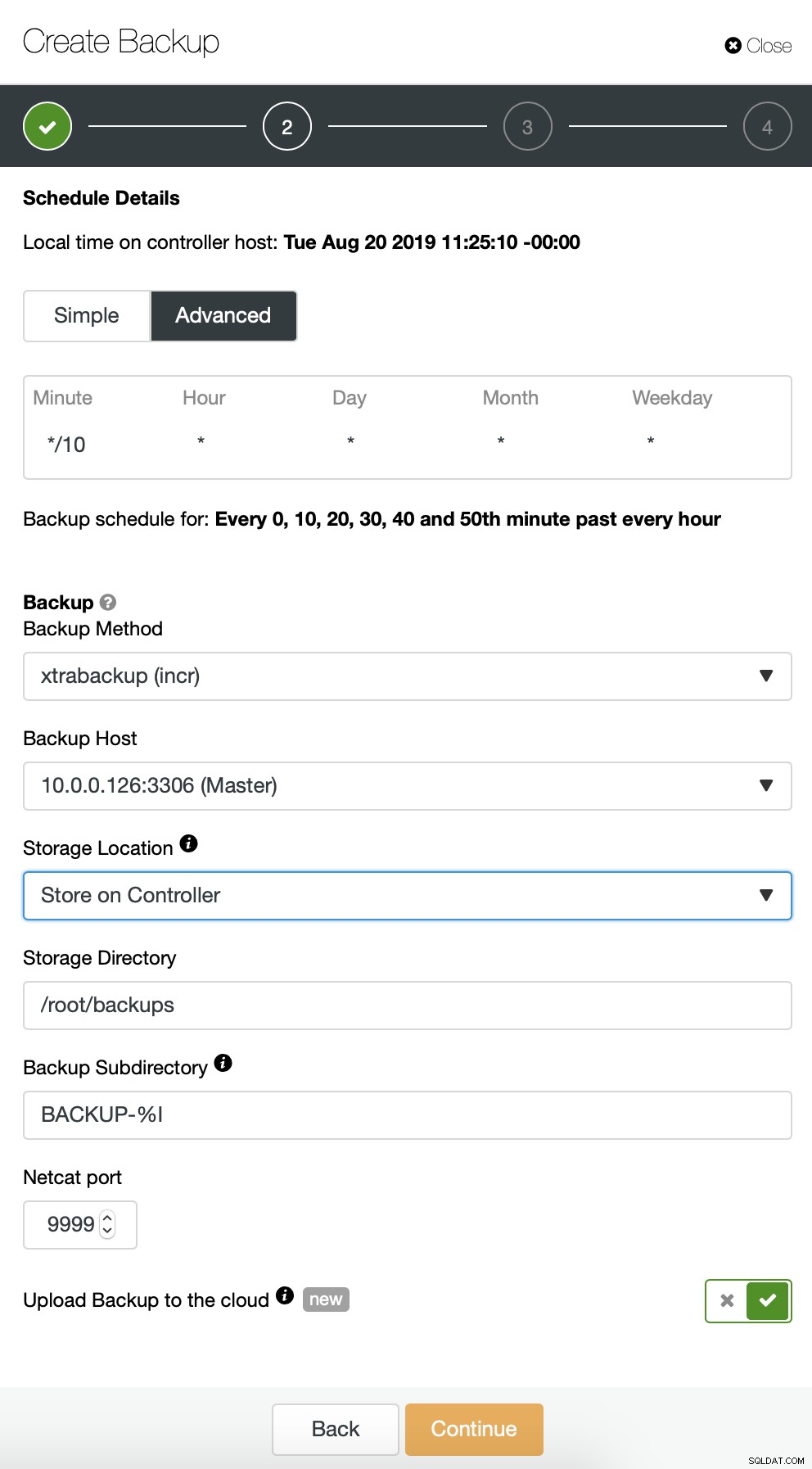
Nous commençons par une sauvegarde complète qui aura lieu tous les jours à 2 h 00. Nous utiliserons le maître pour effectuer la sauvegarde, nous la stockerons sur le contrôleur sous le répertoire /root/backups/. Nous activerons également l'option "Télécharger la sauvegarde sur le cloud".
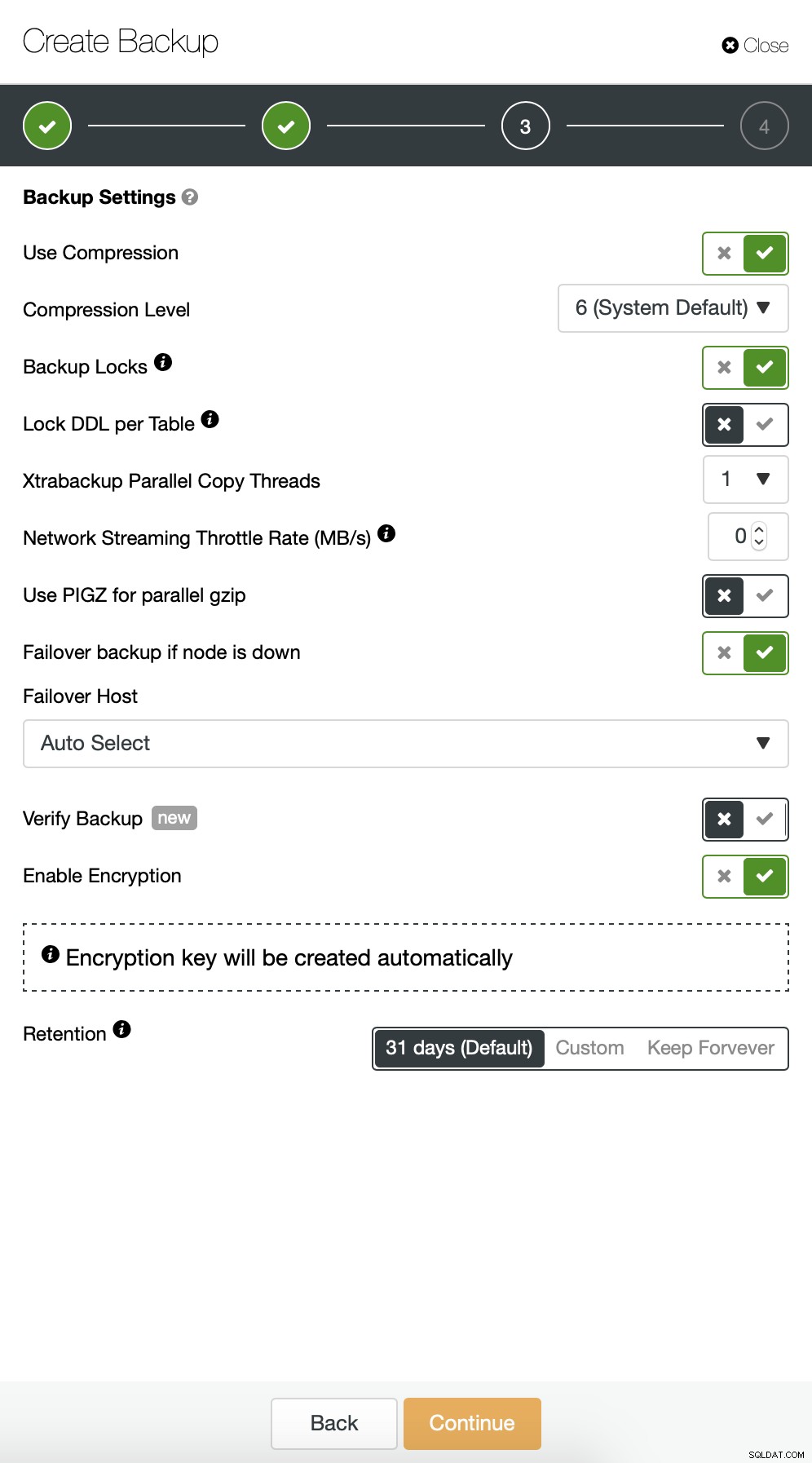
Ensuite, nous souhaitons apporter quelques modifications à la configuration par défaut. Nous avons décidé d'utiliser un hôte de basculement automatiquement sélectionné (au cas où notre maître serait indisponible, ClusterControl utilisera tout autre nœud disponible). Nous voulions également activer le cryptage car nous enverrons nos sauvegardes sur le réseau.
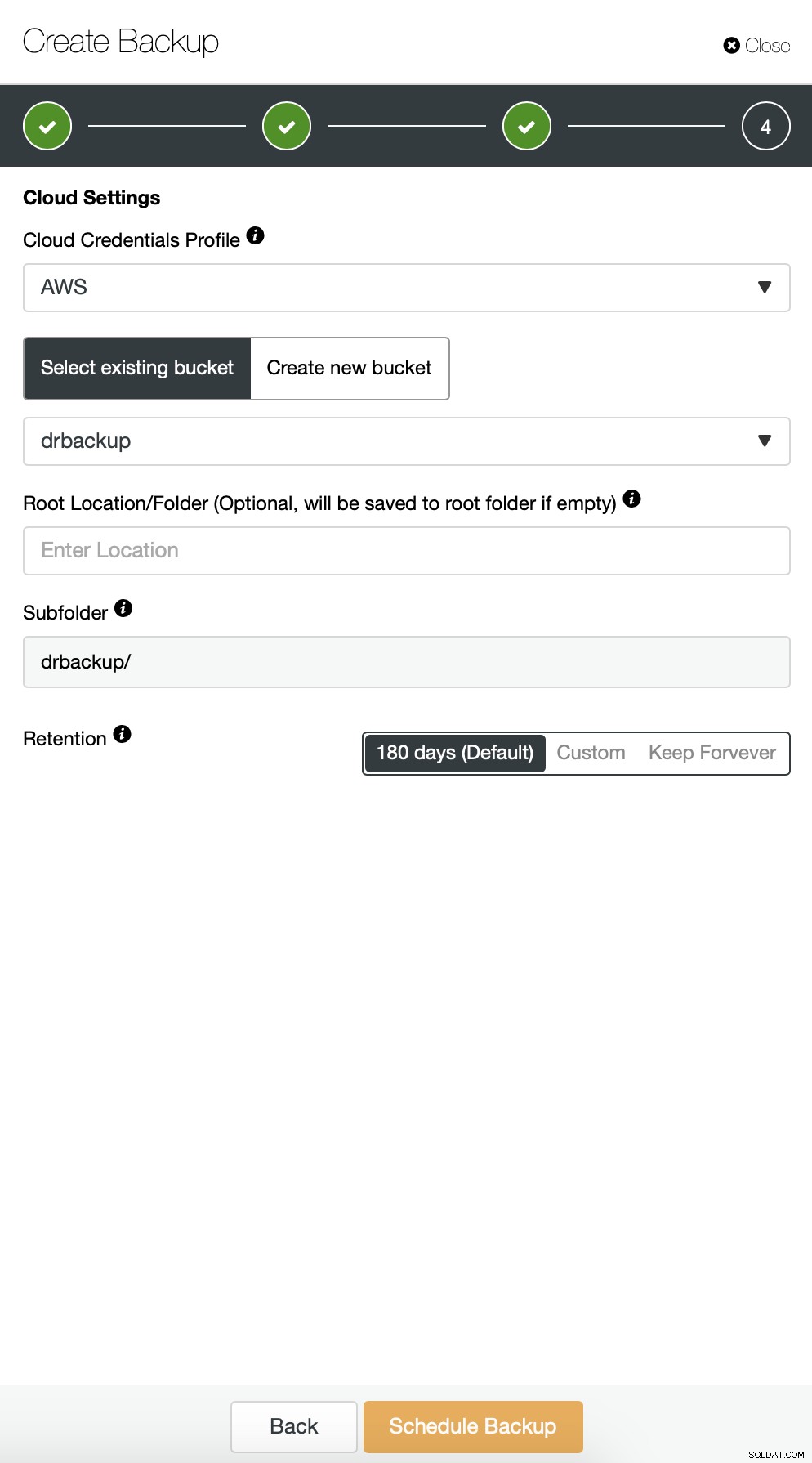
Ensuite, nous devons choisir les informations d'identification, sélectionner le compartiment S3 existant ou créer un un nouveau si nécessaire.
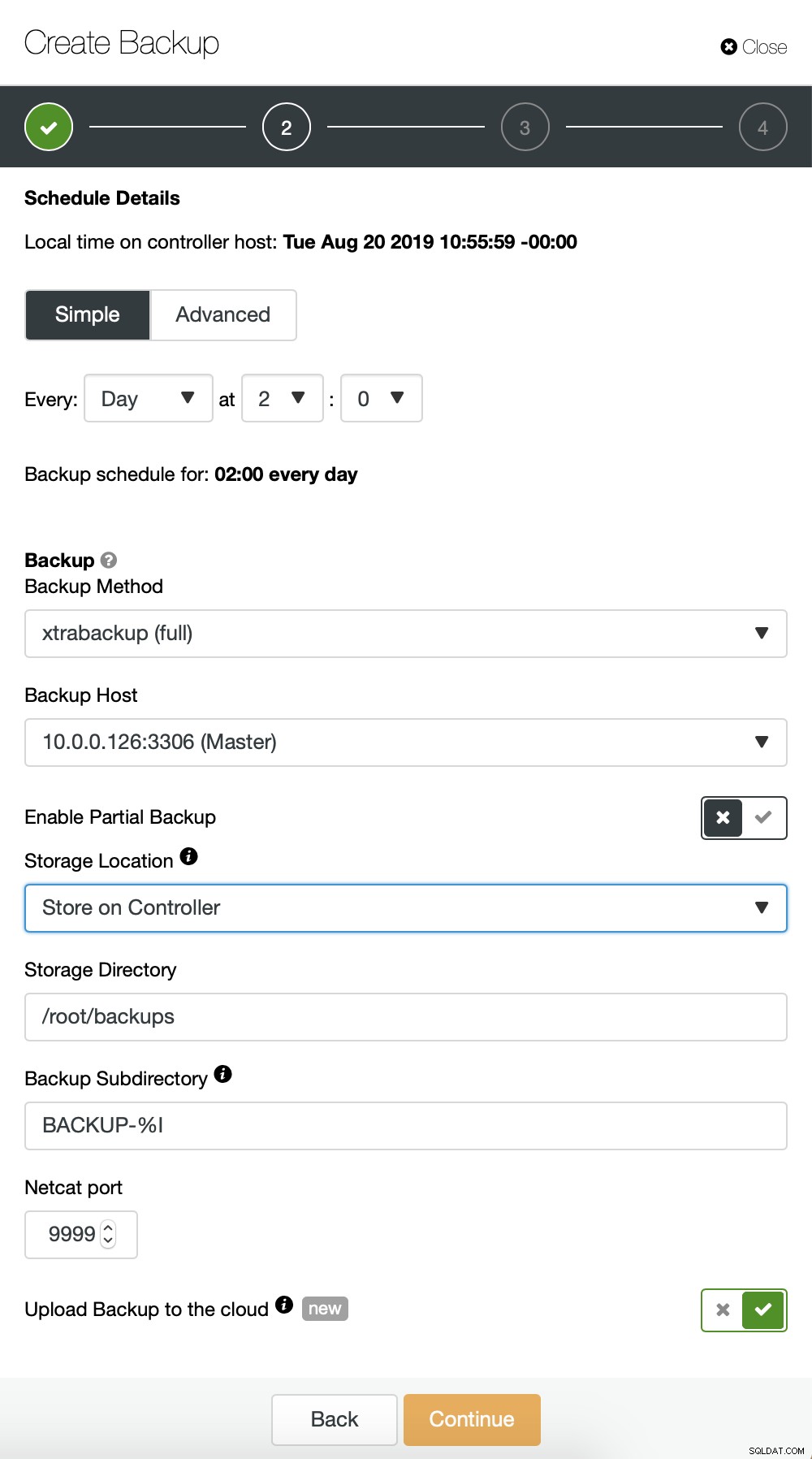
Nous répétons essentiellement le processus pour la sauvegarde incrémentielle, cette fois nous avons utilisé la boîte de dialogue "Avancé" pour exécuter les sauvegardes toutes les 10 minutes.
Le reste des paramètres est similaire, nous pouvons également réutiliser le compartiment S3.
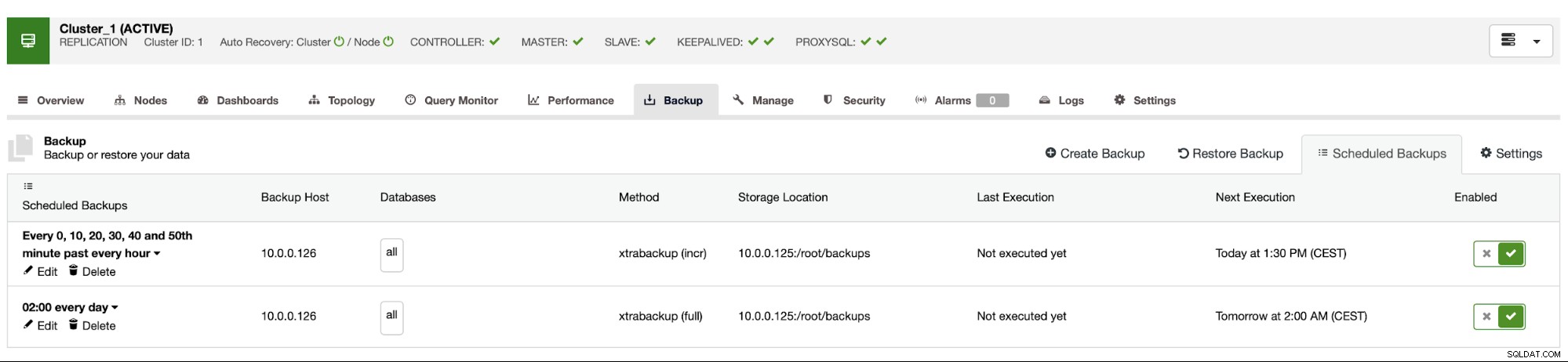
Le programme de sauvegarde ressemble à ci-dessus. Nous n'avons pas besoin de démarrer la sauvegarde complète manuellement, ClusterControl exécutera une sauvegarde incrémentielle comme prévu et s'il détecte qu'il n'y a pas de sauvegarde complète disponible, il exécutera une sauvegarde complète au lieu de l'incrémentale.
Avec une telle configuration, nous pouvons être sûrs de pouvoir récupérer les données sur n'importe quel système externe avec une granularité de 10 minutes.
Restauration de sauvegarde manuelle
S'il arrive que vous ayez besoin de restaurer la sauvegarde sur l'instance de reprise après sinistre, vous devez suivre quelques étapes. Nous vous recommandons fortement de tester ce processus de temps en temps, en vous assurant qu'il fonctionne correctement et que vous maîtrisez son exécution.
Tout d'abord, nous devons installer l'outil de ligne de commande AWS sur notre serveur cible :
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userEnsuite, nous devons le configurer avec les informations d'identification appropriées :
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonNous pouvons maintenant tester si nous avons accès aux données de notre compartiment S3 :
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Maintenant, nous devons télécharger les données. Nous allons créer un répertoire pour les sauvegardes - rappelez-vous, nous devons télécharger le jeu de sauvegarde complet - en partant d'une sauvegarde complète jusqu'à la dernière sauvegarde incrémentielle que nous voulons appliquer.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Maintenant, il y a deux options. Nous pouvons soit télécharger les sauvegardes une par une :
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Nous pouvons également, surtout si vous avez un calendrier de rotation serré, synchroniser tout le contenu du bucket avec ce que nous avons localement sur le serveur :
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Comme vous vous en souvenez, les sauvegardes sont cryptées. Nous devons avoir une clé de cryptage qui est stockée dans ClusterControl. Assurez-vous que sa copie est stockée dans un endroit sûr, en dehors du centre de données principal. Si vous ne pouvez pas l'atteindre, vous ne pourrez pas décrypter les sauvegardes. La clé se trouve dans la configuration de ClusterControl :
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Il est encodé en base64, nous devons donc d'abord le décoder et le stocker dans le fichier avant de pouvoir commencer à déchiffrer la sauvegarde :
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> passer
Maintenant, nous pouvons réutiliser ce fichier pour déchiffrer les sauvegardes. Pour l'instant, disons que nous ferons une sauvegarde complète et deux sauvegardes incrémentielles.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Nous avons les données déchiffrées, nous devons maintenant procéder à la configuration de notre serveur MySQL. Idéalement, il devrait s'agir exactement de la même version que sur les systèmes de production. Nous utiliserons Percona Server pour MySQL :
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Rien de complexe, juste une installation régulière. Une fois qu'il est prêt, nous devons l'arrêter et supprimer le contenu de son répertoire de données.
service mysql stop
rm -rf /var/lib/mysql/*Pour restaurer la sauvegarde, nous aurons besoin de Xtrabackup - un outil utilisé par CC pour la créer (au moins pour Perona et Oracle MySQL, MariaDB utilise MariaBackup). Il est important que cet outil soit installé dans la même version que sur les serveurs de production :
apt install percona-xtrabackup-24C'est tout ce que nous avons à préparer. Nous pouvons maintenant commencer à restaurer la sauvegarde. Avec les sauvegardes incrémentielles, il est important de garder à l'esprit que vous devez les préparer et les appliquer en plus de la sauvegarde de base. La sauvegarde de base doit également être préparée. Il est crucial d'exécuter la préparation avec l'option "--apply-log-only" pour empêcher xtrabackup d'exécuter la phase de restauration. Sinon, vous ne pourrez pas appliquer la prochaine sauvegarde incrémentielle.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/Dans la dernière commande, nous avons autorisé xtrabackup à exécuter la restauration des transactions non terminées - nous n'appliquerons plus de sauvegardes incrémentielles par la suite. Il est maintenant temps de remplir le répertoire de données avec la sauvegarde, de démarrer MySQL et de voir si tout fonctionne comme prévu :
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Comme vous pouvez le voir, tout va bien. MySQL a démarré correctement et nous avons pu y accéder (et les données sont là !) Nous avons réussi à remettre notre base de données en service dans un endroit séparé. Le temps total requis dépend strictement de la taille des données - nous avons dû télécharger les données de S3, les décrypter et les décompresser et enfin préparer la sauvegarde. Néanmoins, il s'agit d'une option très bon marché (vous ne devez payer que pour les données S3) qui vous offre une option de continuité des activités en cas de catastrophe.