HAProxy et ProxySQL sont tous deux des équilibreurs de charge très populaires dans le monde MySQL, mais il existe une différence significative entre ces deux proxys. Nous n'entrerons pas dans les détails ici, vous pouvez en savoir plus sur HAProxy dans le didacticiel HAProxy et ProxySQL dans le didacticiel ProxySQL. La différence la plus importante est que ProxySQL est un proxy compatible SQL, il analyse le trafic et comprend le protocole MySQL et, en tant que tel, il peut être utilisé pour la mise en forme avancée du trafic - vous pouvez bloquer les requêtes, les réécrire, les diriger vers des hôtes particuliers, mettre en cache eux et bien d'autres. HAProxy, d'autre part, est un proxy de couche 4 très simple mais efficace et tout ce qu'il fait est d'envoyer des paquets au backend. ProxySQL peut être utilisé pour effectuer une séparation en lecture-écriture - il comprend le SQL et il peut être configuré pour détecter si une requête est SELECT ou non et les acheminer en conséquence :les SELECT vers tous les nœuds, les autres requêtes vers le maître uniquement. Cette fonctionnalité n'est pas disponible dans HAProxy, qui doit utiliser deux ports distincts et deux backends distincts pour le maître et les esclaves ; la séparation lecture-écriture doit être effectuée du côté de l'application.
Pourquoi migrer vers ProxySQL ?
Sur la base des différences que nous avons expliquées ci-dessus, nous dirions que la principale raison pour laquelle vous pourriez vouloir passer de HAProxy à ProxySQL est l'absence de séparation lecture-écriture dans HAProxy. Si vous utilisez un cluster de bases de données MySQL, et peu importe qu'il s'agisse d'une réplication asynchrone ou d'un cluster Galera, vous souhaitez probablement pouvoir séparer les lectures des écritures. Pour la réplication MySQL, évidemment, ce serait le seul moyen d'utiliser votre cluster de base de données car les écritures doivent toujours être envoyées au maître. Par conséquent, si vous ne pouvez pas effectuer la séparation lecture-écriture, vous ne pouvez envoyer des requêtes qu'au maître uniquement. Pour Galera, la séparation en lecture-écriture n'est pas un must, mais certainement un bon à avoir. Bien sûr, vous pouvez configurer tous les nœuds Galera en tant que backend dans HAProxy et envoyer du trafic à chacun d'eux de manière circulaire, mais cela peut entraîner des écritures de plusieurs nœuds en conflit les uns avec les autres, entraînant des blocages et une baisse des performances. Nous avons également constaté des problèmes et des bogues dans le cluster Galera, pour lesquels, jusqu'à ce qu'ils soient corrigés, la solution de contournement consistait à diriger toutes les écritures vers un seul nœud. Ainsi, la meilleure pratique consiste à envoyer toutes les écritures à un nœud Galera, car cela conduit à un comportement plus stable et à de meilleures performances.
Une autre très bonne raison de migrer vers ProxySQL est le besoin de mieux contrôler le trafic. Avec HAProxy, vous ne pouvez rien faire - il envoie simplement le trafic à ses backends. Avec ProxySQL, vous pouvez façonner votre trafic à l'aide de règles de requête (faire correspondre le trafic à l'aide d'expressions régulières, d'utilisateur, de schéma, d'hôte source et bien d'autres). Vous pouvez rediriger les SELECT OLAP vers l'esclave d'analyse (c'est vrai pour la réplication et Galera). Vous pouvez décharger votre maître en redirigeant certains des SELECT hors de celui-ci. Vous pouvez implémenter un pare-feu SQL. Vous pouvez ajouter un délai à certaines requêtes, vous pouvez tuer des requêtes si elles prennent plus d'un temps prédéfini. Vous pouvez réécrire les requêtes pour ajouter des conseils d'optimisation. Tout cela n'est pas possible avec HAProxy.
Comment migrer de HAProxy vers ProxySQL ?
Considérons d'abord la topologie suivante...
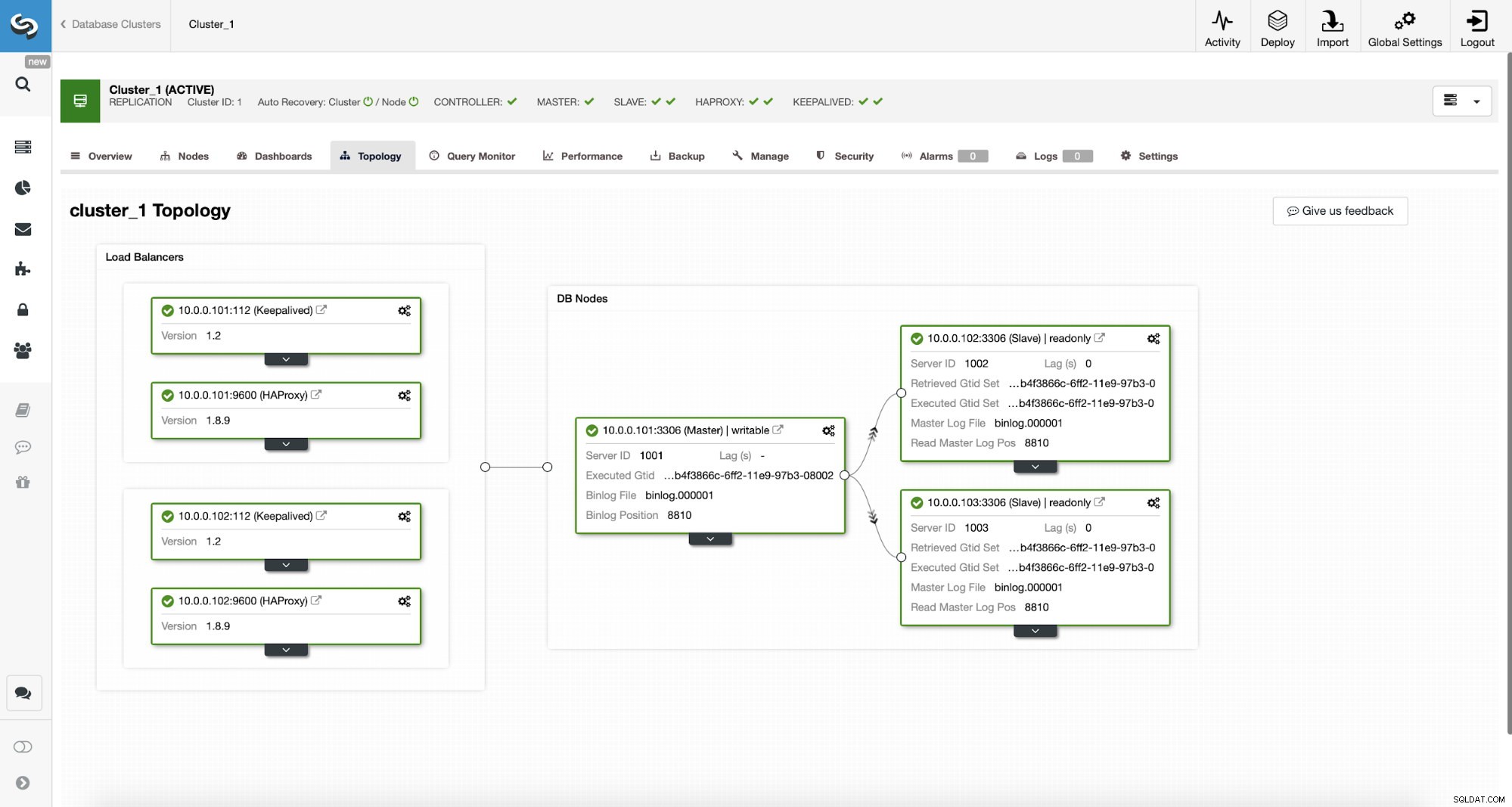 Topologie MySQL ClusterControl
Topologie MySQL ClusterControl 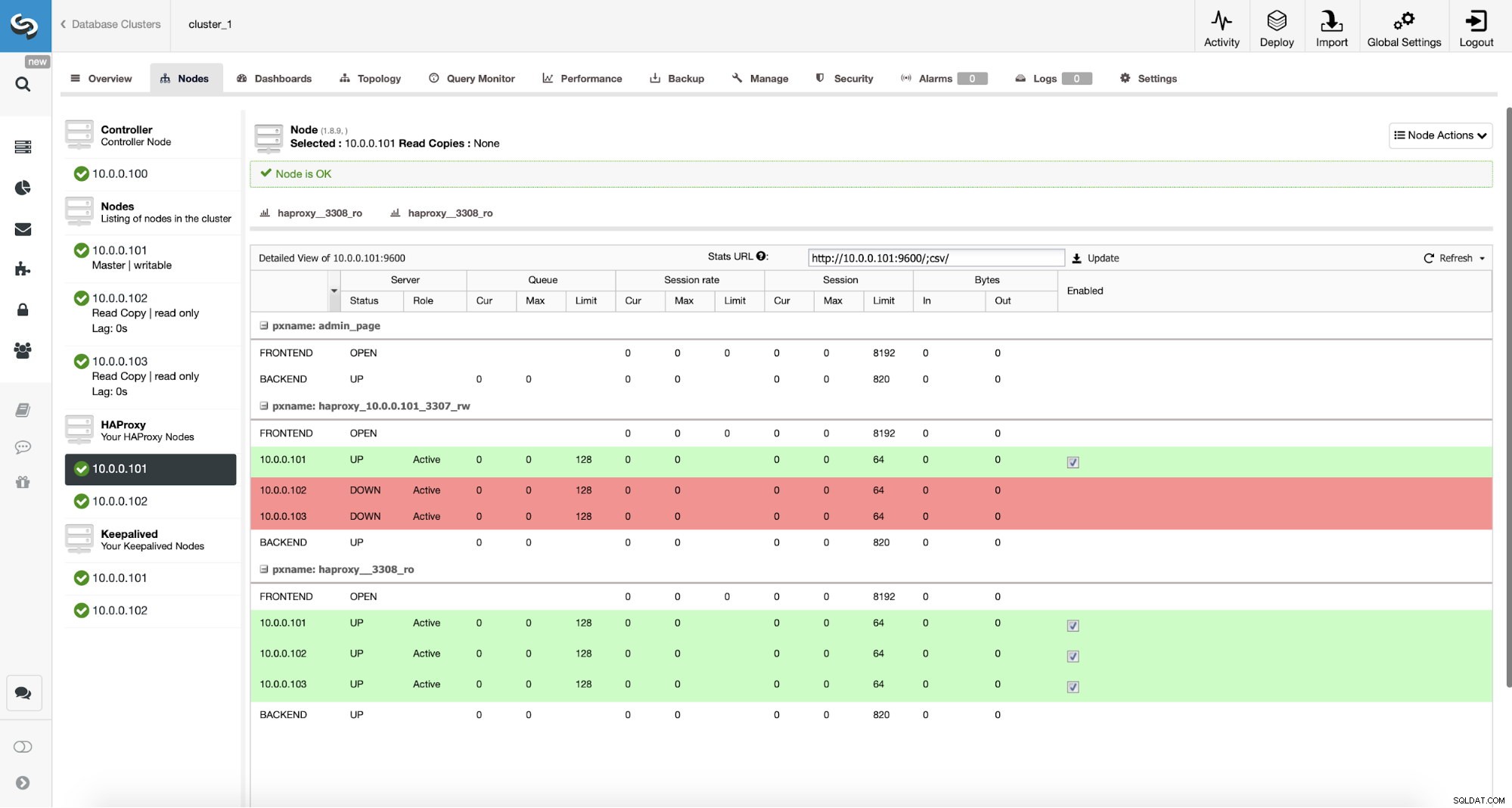 Cluster de réplication MySQL dans ClusterControl
Cluster de réplication MySQL dans ClusterControl Nous avons ici un cluster de réplication composé d'un maître et de deux esclaves. Nous avons deux nœuds HAProxy déployés, chacun utilisant deux backends - sur le port 3307 pour le maître (écritures) et 3308 pour tous les nœuds (lectures). Keepalived est utilisé pour fournir une adresse IP virtuelle sur ces deux instances HAProxy - si l'une d'entre elles échoue, une autre sera utilisée. Notre application se connecte directement au VIP, via celui-ci à l'une des instances HAProxy. Supposons que notre application (nous utiliserons Sysbench) ne peut pas faire la séparation lecture-écriture, nous devons donc nous connecter au backend "writer". Par conséquent, la majorité de la charge se trouve sur notre maître (10.0.0.101).
Quelles seraient les étapes pour migrer vers ProxySQL ? Réfléchissons-y un instant. Tout d'abord, nous devons déployer et configurer ProxySQL. Nous devrons ajouter des serveurs à ProxySQL, créer les utilisateurs de surveillance requis et créer des règles de requête appropriées. Enfin, nous devrons déployer Keepalived au-dessus de ProxySQL, créer une autre adresse IP virtuelle, puis assurer un basculement aussi transparent que possible pour notre application de HAProxy à ProxySQL.
Voyons comment nous pouvons y parvenir...
Comment installer ProxySQL
On peut installer ProxySQL de plusieurs façons. Vous pouvez utiliser le référentiel, soit à partir de ProxySQL lui-même (https://repo.proxysql.com) ou si vous utilisez Percona XtraDB Cluster, vous pouvez également installer ProxySQL à partir du référentiel Percona bien qu'il puisse nécessiter une configuration supplémentaire car il repose sur CLI outils d'administration créés pour PXC. Étant donné que nous parlons de réplication, leur utilisation peut simplement rendre les choses plus complexes. Enfin, vous pouvez également installer les binaires ProxySQL après les avoir téléchargés depuis ProxySQL GitHub. Il existe actuellement deux versions stables, 1.4.x et 2.0.x. Il existe des différences entre ProxySQL 1.4 et ProxySQL 2.0 en termes de fonctionnalités, pour ce blog nous nous en tiendrons à la branche 1.4.x, car elle est mieux testée et l'ensemble de fonctionnalités nous suffit.
Nous utiliserons le référentiel ProxySQL et nous déploierons ProxySQL sur deux nœuds supplémentaires :10.0.0.103 et 10.0.0.104.
Tout d'abord, nous allons installer ProxySQL en utilisant le référentiel officiel. Nous nous assurerons également que le client MySQL est installé (nous l'utiliserons pour configurer ProxySQL). Veuillez garder à l'esprit que le processus que nous suivons n'est pas de qualité production. Pour la production, vous souhaiterez au moins modifier les informations d'identification par défaut de l'utilisateur administratif. Vous voudrez également revoir la configuration et vous assurer qu'elle est conforme à vos attentes et à vos exigences.
apt-get install -y lsb-release
wget -O - 'https://repo.proxysql.com/ProxySQL/repo_pub_key' | apt-key add -
echo deb https://repo.proxysql.com/ProxySQL/proxysql-1.4.x/$(lsb_release -sc)/ ./ | tee /etc/apt/sources.list.d/proxysql.list
apt-get -y update
apt-get -y install proxysql
service proxysql startMaintenant que ProxySQL a été démarré, nous allons utiliser la CLI pour configurer ProxySQL.
mysql -uadmin -padmin -P6032 -h127.0.0.1Tout d'abord, nous allons définir les serveurs backend et les groupes d'hôtes de réplication :
mysql> INSERT INTO mysql_servers (hostgroup_id, hostname) VALUES (10, '10.0.0.101'), (20, '10.0.0.102'), (20, '10.0.0.103');
Query OK, 3 rows affected (0.91 sec)mysql> INSERT INTO mysql_replication_hostgroups (writer_hostgroup, reader_hostgroup) VALUES (10, 20);
Query OK, 1 row affected (0.00 sec)Nous avons trois serveurs, nous avons également défini que ProxySQL doit utiliser le groupe d'hôtes 10 pour le maître (nœud avec read_only=0) et le groupe d'hôtes 20 pour les esclaves (read_only=1).
Comme prochaine étape, nous devons ajouter un utilisateur de surveillance sur les nœuds MySQL afin que ProxySQL puisse les surveiller. Nous allons utiliser les valeurs par défaut, idéalement vous modifierez les informations d'identification dans ProxySQL.
mysql> SHOW VARIABLES LIKE 'mysql-monitor_username';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_username | monitor |
+------------------------+---------+
1 row in set (0.00 sec)mysql> SHOW VARIABLES LIKE 'mysql-monitor_password';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_password | monitor |
+------------------------+---------+
1 row in set (0.00 sec)Nous devons donc créer l'utilisateur "monitor" avec le mot de passe "monitor". Pour ce faire, nous devrons exécuter la subvention suivante sur le serveur MySQL maître :
mysql> create user example@sqldat.com'%' identified by 'monitor';
Query OK, 0 rows affected (0.56 sec)Revenons à ProxySQL - nous devons configurer les utilisateurs que notre application utilisera pour accéder à MySQL et aux règles de requête, qui sont destinées à nous donner une séparation lecture-écriture.
mysql> INSERT INTO mysql_users (username, password, default_hostgroup) VALUES ('sbtest', 'sbtest', 10);
Query OK, 1 row affected (0.34 sec)mysql> INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (100, 1, '^SELECT.*FOR UPDATE$',10,1), (200,1,'^SELECT',20,1), (300,1,'.*',10,1);
Query OK, 3 rows affected (0.01 sec)Veuillez noter que nous avons utilisé le mot de passe en texte brut et nous comptons sur ProxySQL pour le hacher. Pour des raisons de sécurité, vous devez explicitement transmettre ici le hachage du mot de passe MySQL.
Enfin, nous devons appliquer toutes les modifications.
mysql> LOAD MYSQL SERVERS TO RUNTIME;
Query OK, 0 rows affected (0.02 sec)mysql> LOAD MYSQL USERS TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> SAVE MYSQL SERVERS TO DISK;
Query OK, 0 rows affected (0.07 sec)mysql> SAVE MYSQL QUERY RULES TO DISK;
Query OK, 0 rows affected (0.02 sec)Nous souhaitons également charger les mots de passe hachés depuis l'exécution :les mots de passe en texte brut sont hachés lorsqu'ils sont chargés dans la configuration d'exécution. Pour les conserver hachés sur le disque, nous devons les charger depuis l'exécution, puis les stocker sur le disque :
mysql> SAVE MYSQL USERS FROM RUNTIME;
Query OK, 0 rows affected (0.00 sec)mysql> SAVE MYSQL USERS TO DISK;
Query OK, 0 rows affected (0.02 sec)C'est tout quand il s'agit de ProxySQL. Avant d'aller plus loin, vous devez vérifier si vous pouvez vous connecter à des proxys à partir de vos serveurs d'application.
example@sqldat.com:~# mysql -h 10.0.0.103 -usbtest -psbtest -P6033 -e "SELECT * FROM sbtest.sbtest4 LIMIT 1\G"
mysql: [Warning] Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
id: 1
k: 50147
c: 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441
pad: 22195207048-70116052123-74140395089-76317954521-98694025897Dans notre cas, tout semble bon. Il est maintenant temps d'installer Keepalived.
Installation continue
L'installation est assez simple (du moins sur Ubuntu 16.04, que nous avons utilisé) :
apt install keepalivedEnsuite, vous devez créer des fichiers de configuration pour les deux serveurs :
Nœud keepalive maître :
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 101
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.sh
}Nœud keepalive de sauvegarde :
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.shÇa y est, vous pouvez démarrer keepalived sur les deux nœuds :
service keepalived startVous devriez voir des informations dans les journaux indiquant que l'un des nœuds est entré dans l'état MASTER et que le VIP a été mis en place sur ce nœud.
May 7 09:52:11 vagrant systemd[1]: Starting Keepalive Daemon (LVS and VRRP)...
May 7 09:52:11 vagrant Keepalived[26686]: Starting Keepalived v1.2.24 (08/06,2018)
May 7 09:52:11 vagrant Keepalived[26686]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived[26696]: Starting Healthcheck child process, pid=26697
May 7 09:52:11 vagrant Keepalived[26696]: Starting VRRP child process, pid=26698
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Initializing ipvs
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering gratuitous ARP shared channel
May 7 09:52:11 vagrant systemd[1]: Started Keepalive Daemon (LVS and VRRP).
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to load ipset library
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to initialise ipsets
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: pid 26701 exited with status 256
May 7 09:52:12 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Transition to MASTER STATE
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: pid 26763 exited with status 256
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Entering MASTER STATE
May 7 09:52:15 vagrant Keepalived_vrrp[26698]: pid 26806 exited with status 256example@sqldat.com:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:ee:87:c4 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feee:87c4/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:fc:ac:21 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.103/24 brd 10.0.0.255 scope global eth1
valid_lft forever preferred_lft forever
inet 10.0.0.112/32 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fefc:ac21/64 scope link
valid_lft forever preferred_lft foreverComme vous pouvez le voir, sur le nœud 10.0.0.103, un VIP (10.0.0.112) a été créé. Nous pouvons maintenant conclure en déplaçant le trafic de l'ancienne configuration vers la nouvelle.
Basculer le trafic vers une configuration ProxySQL
Il existe de nombreuses méthodes pour le faire, cela dépend principalement de votre environnement particulier. S'il vous arrive d'utiliser DNS pour maintenir un domaine pointant vers votre VIP HAProxy, vous pouvez simplement y apporter une modification et, progressivement, au fil du temps, toutes les connexions redirigeront vers le nouveau VIP. Vous pouvez également apporter une modification à votre application, en particulier si les détails de connexion sont codés en dur - une fois que vous avez déployé la modification, les nœuds commenceront à se connecter à la nouvelle configuration. Peu importe comment vous le faites, il serait bon de tester la nouvelle configuration avant de faire un changement global. Vous l'avez certainement testé sur votre environnement de staging, mais ce n'est pas une mauvaise idée de choisir une poignée de serveurs d'applications et de les rediriger vers le nouveau proxy, en surveillant leur apparence en termes de performances. Vous trouverez ci-dessous un exemple simple utilisant iptables, qui peut être utile pour les tests.
Sur les hôtes ProxySQL, redirigez le trafic de l'hôte 10.0.0.11 et du port 3307 vers l'hôte 10.0.0.112 et le port 6033 :
iptables -t nat -A OUTPUT -p tcp -d 10.0.0.111 --dport 3307 -j DNAT --to-destination 10.0.0.112:6033Selon votre application, vous devrez peut-être redémarrer le serveur Web ou d'autres services (si votre application crée un pool constant de connexions à la base de données) ou simplement attendre que de nouvelles connexions soient ouvertes avec ProxySQL. Vous pouvez vérifier que ProxySQL reçoit le trafic :
mysql> show processlist;
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| SessionID | user | db | hostgroup | command | time_ms | info |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| 12 | sbtest | sbtest | 20 | Sleep | 0 | |
| 13 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest23 WHERE id=49957 |
| 14 | sbtest | sbtest | 10 | Query | 59 | DELETE FROM sbtest11 WHERE id=50185 |
| 15 | sbtest | sbtest | 20 | Query | 59 | SELECT c FROM sbtest8 WHERE id=46054 |
| 16 | sbtest | sbtest | 20 | Query | 0 | SELECT DISTINCT c FROM sbtest27 WHERE id BETWEEN 50115 AND 50214 ORDER BY c |
| 17 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest32 WHERE id=50084 |
| 18 | sbtest | sbtest | 10 | Query | 26 | DELETE FROM sbtest28 WHERE id=34611 |
| 19 | sbtest | sbtest | 10 | Query | 16 | DELETE FROM sbtest4 WHERE id=50151 |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+C'était tout, nous avons déplacé le trafic de HAProxy vers la configuration de ProxySQL. Il a fallu quelques étapes, mais c'est tout à fait faisable avec une très petite interruption du service.
Comment migrer de HAProxy vers ProxySQL à l'aide de ClusterControl ?
Dans la section précédente, nous avons expliqué comment déployer manuellement la configuration de ProxySQL, puis y migrer. Dans cette section, nous aimerions expliquer comment atteindre le même objectif en utilisant ClusterControl. La configuration initiale est exactement la même, nous devons donc procéder au déploiement de ProxySQL.
Déployer ProxySQL à l'aide de ClusterControl
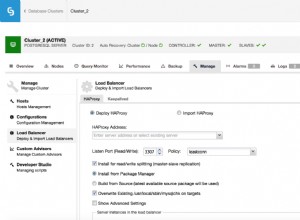
Le déploiement de ProxySQL dans ClusterControl n'est qu'une question de quelques clics.
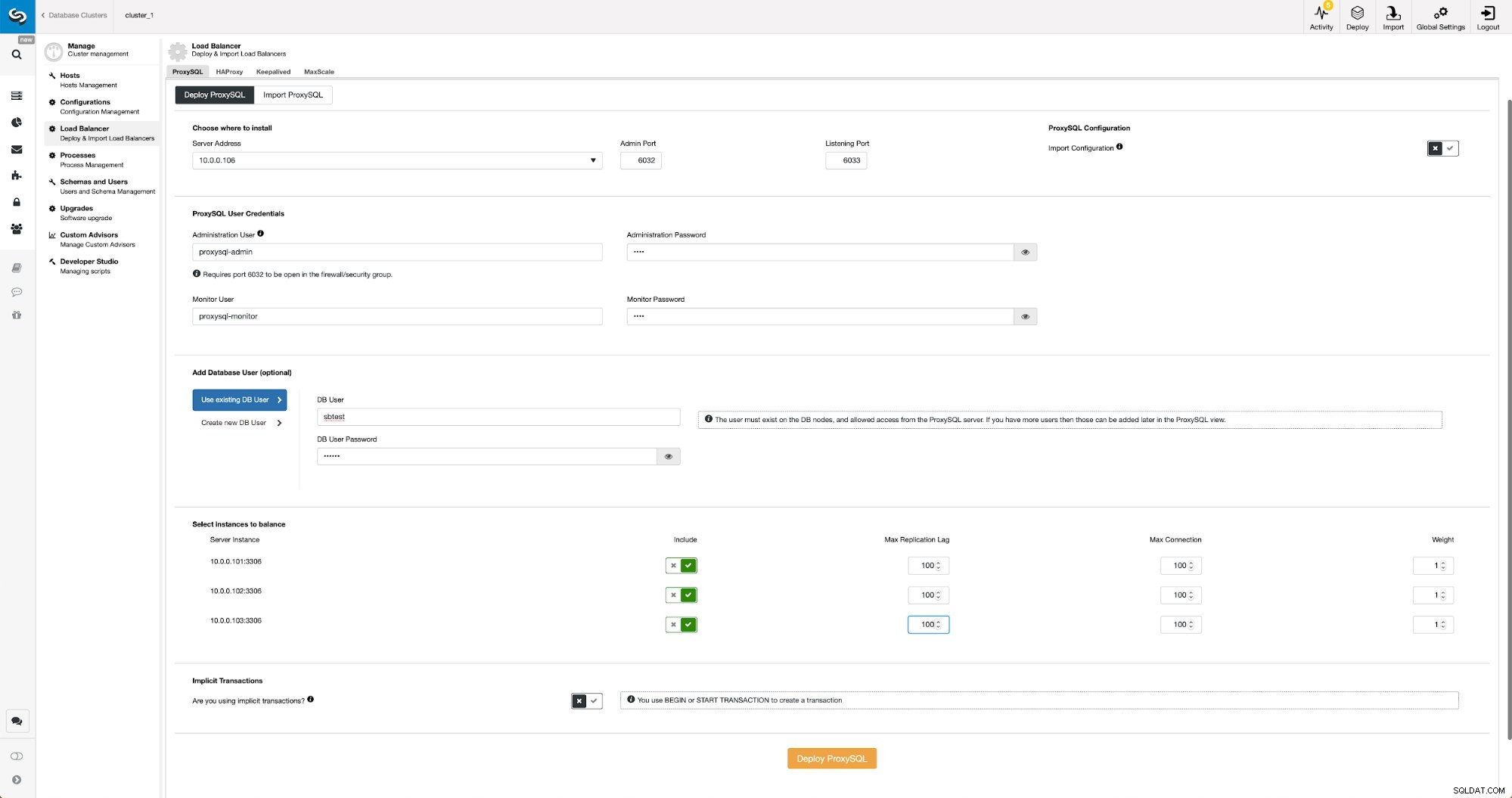 Déployer ProxySQL dans ClusterControl
Déployer ProxySQL dans ClusterControl Nous avons dû choisir l'adresse IP ou le nom d'hôte d'un nœud, transmettre les informations d'identification pour l'utilisateur administratif CLI et l'utilisateur de surveillance MySQL. Nous avons décidé d'utiliser MySQL existant et nous avons transmis les détails d'accès pour l'utilisateur 'sbtest'@'%' que nous utilisons dans l'application. Nous avons choisi les nœuds que nous voulons utiliser dans l'équilibreur de charge, nous avons également augmenté le délai de réplication maximum (si ce seuil est franchi, ProxySQL n'enverra pas le trafic à cet esclave) de 10 secondes par défaut à 100 car nous souffrons déjà de la réplication décalage. Après un court instant, les nœuds ProxySQL seront ajoutés au cluster.
Déployer Keepalived pour ProxySQL à l'aide de ClusterControl
Lorsque les nœuds ProxySQL ont été ajoutés, il est temps de déployer Keepalived.
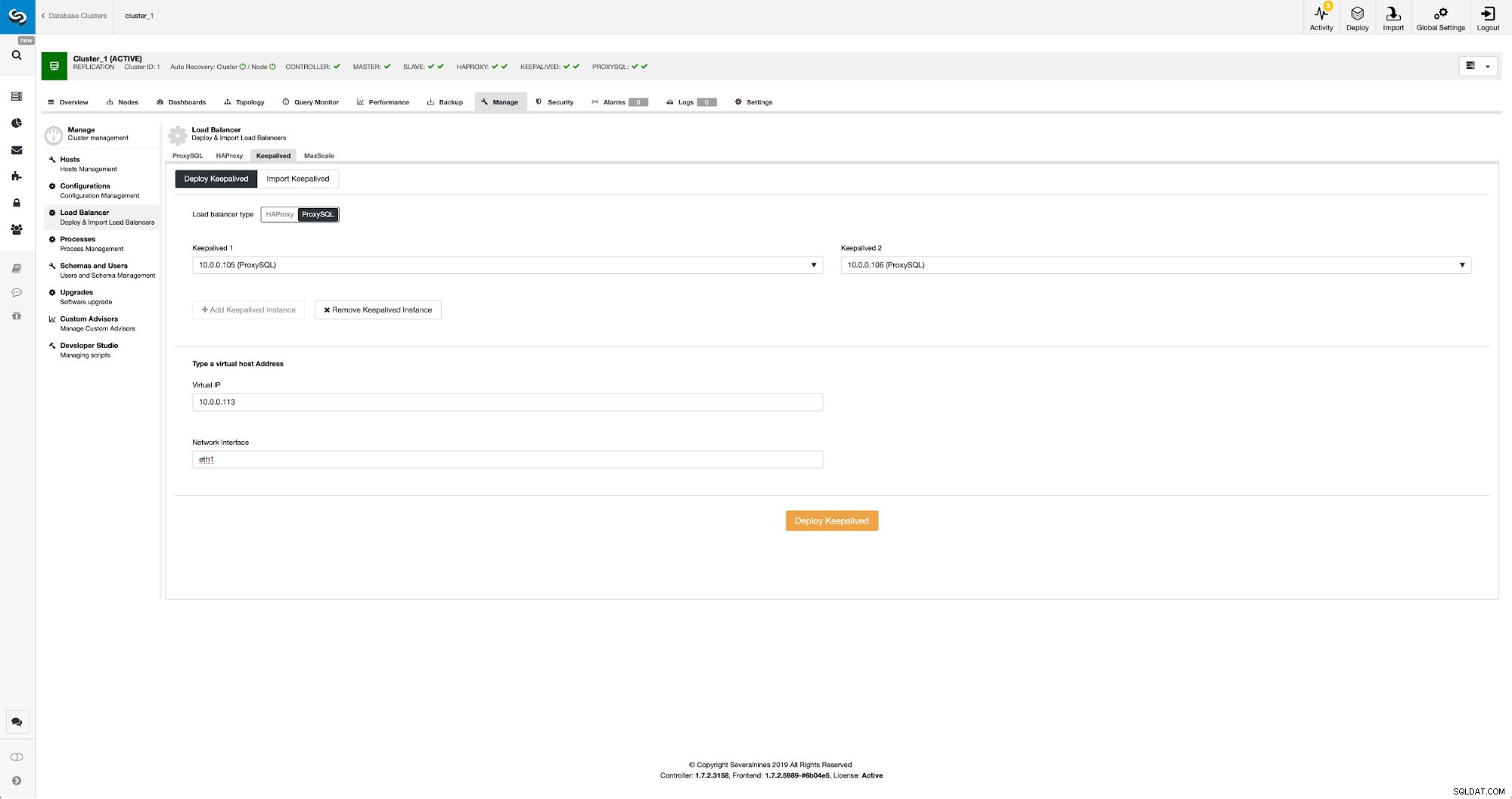 Keepalived avec ProxySQL dans ClusterControl
Keepalived avec ProxySQL dans ClusterControl Tout ce que nous avions à faire était de choisir sur quels nœuds ProxySQL nous voulons que Keepalived se déploie, l'adresse IP virtuelle et l'interface à laquelle le VIP sera lié. Une fois le déploiement terminé, nous basculerons le trafic vers la nouvelle configuration en utilisant l'une des méthodes mentionnées dans la section "Basculer le trafic vers la configuration ProxySQL" ci-dessus.
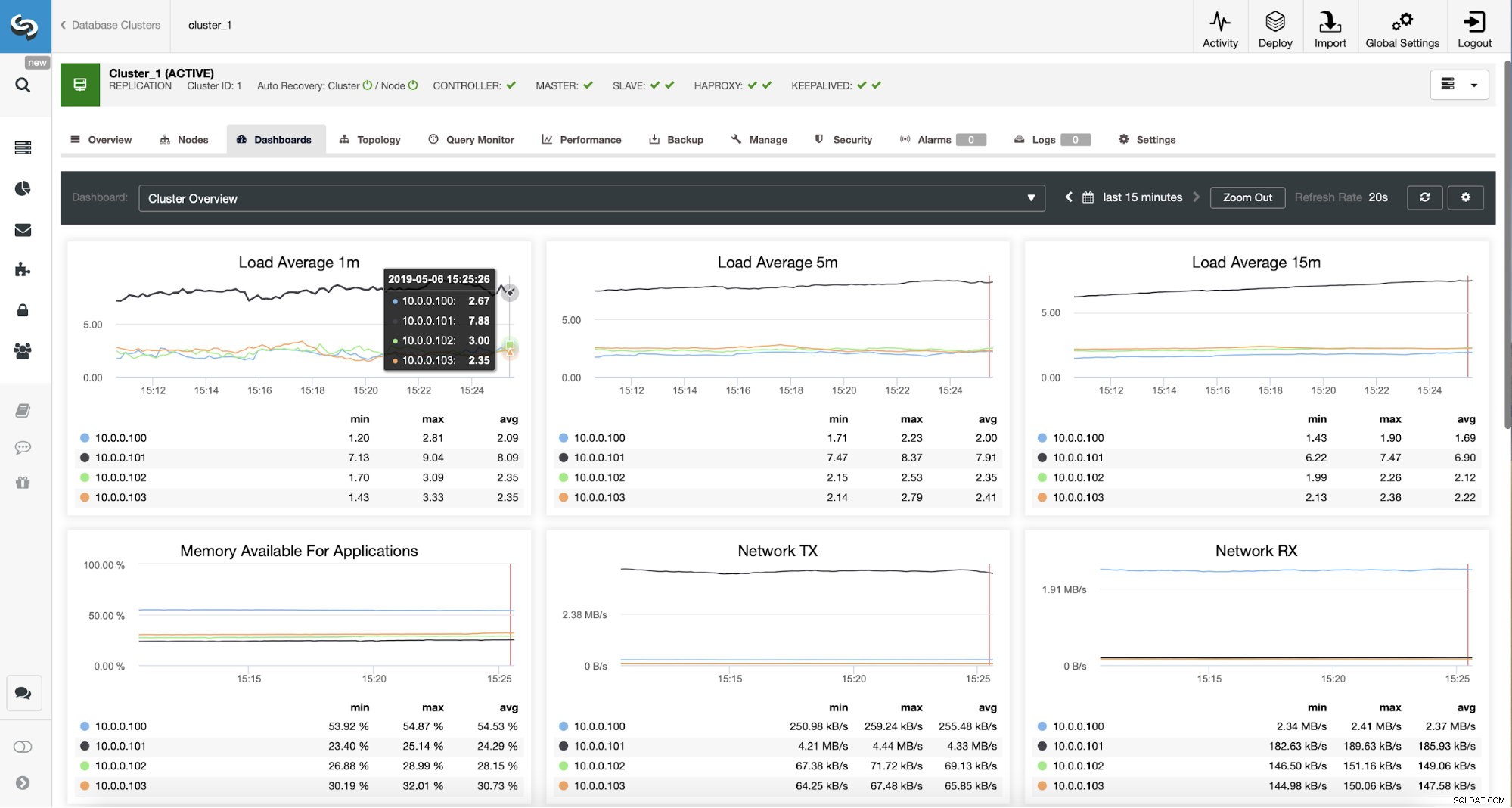
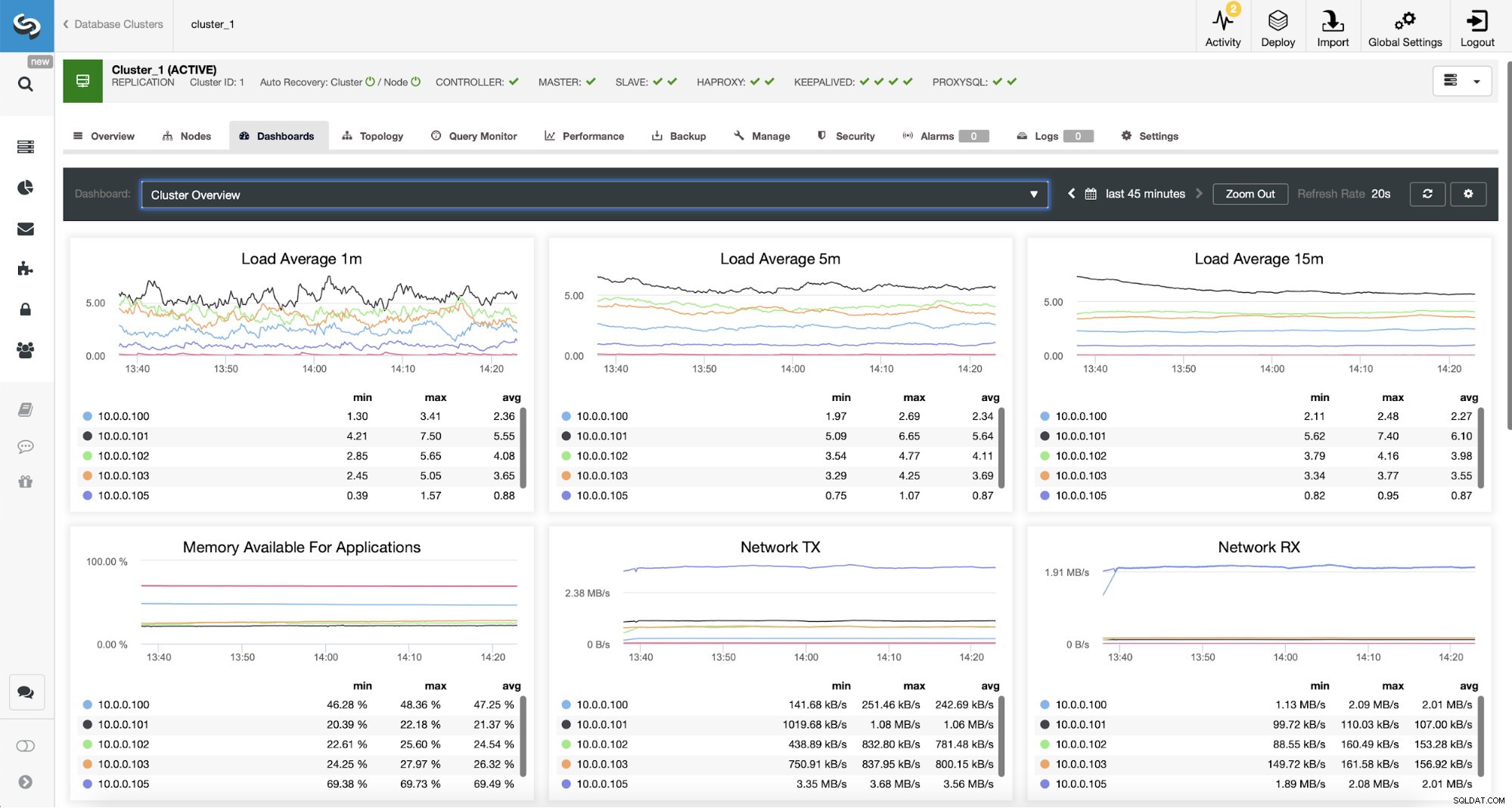 Surveillance du trafic ProxySQL dans ClusterControl
Surveillance du trafic ProxySQL dans ClusterControl Nous pouvons vérifier que le trafic est passé à ProxySQL en regardant le graphique de charge - comme vous pouvez le voir, la charge est beaucoup plus répartie sur les nœuds du cluster. Vous pouvez également le voir sur le graphique ci-dessous, qui montre la distribution des requêtes dans le cluster.
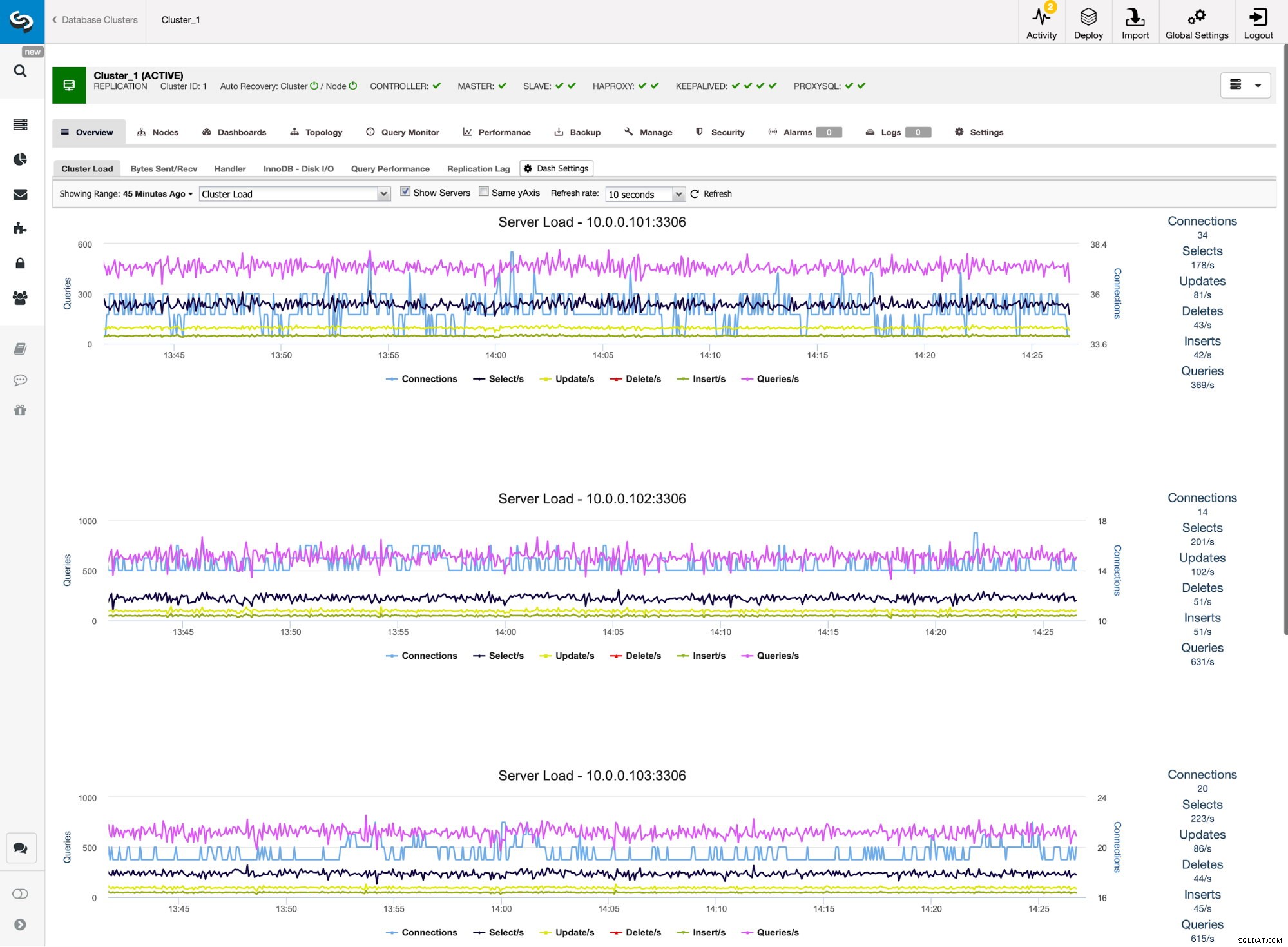 Tableau de bord ProxySQL dans ClusterControl
Tableau de bord ProxySQL dans ClusterControl Enfin, le tableau de bord ProxySQL montre également que le trafic est réparti sur tous les nœuds du cluster :
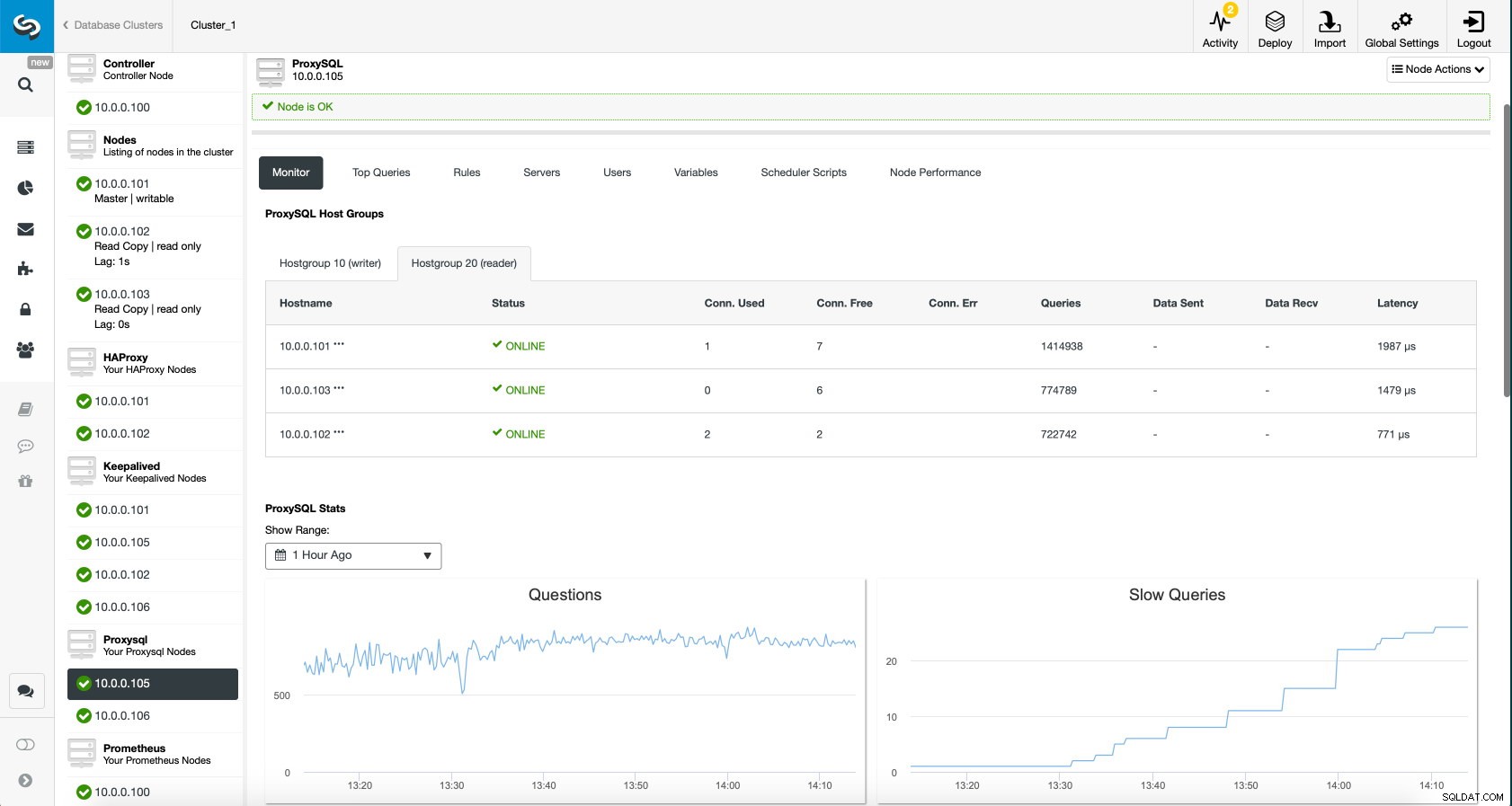 Tableau de bord ProxySQL dans ClusterControl
Tableau de bord ProxySQL dans ClusterControl Nous espérons que vous tirerez profit de cet article de blog, comme vous pouvez le constater, avec ClusterControl, le déploiement de la nouvelle architecture ne prend qu'un instant et ne nécessite que quelques clics pour que tout fonctionne. Faites-nous part de votre expérience dans ces migrations.