La durabilité retardée est une fonctionnalité de dernière minute mais intéressante dans SQL Server 2014; le pitch d'ascenseur de haut niveau de la fonctionnalité est, tout simplement :
- "Échangez durabilité contre performance."
Un peu de contexte d'abord. Par défaut, SQL Server utilise un journal à écriture anticipée (WAL), ce qui signifie que les modifications sont écrites dans le journal avant d'être autorisées à être validées. Dans les systèmes où les écritures dans le journal des transactions deviennent le goulot d'étranglement et où il existe une tolérance modérée à la perte de données , vous avez désormais la possibilité de suspendre temporairement l'obligation d'attendre le vidage du journal et l'accusé de réception. Il se trouve que cela supprime littéralement le D d'ACID, au moins pour une petite partie des données (nous en reparlerons plus tard).
Vous faites en quelque sorte déjà ce sacrifice maintenant. En mode de récupération complète, il existe toujours un risque de perte de données, il est simplement mesuré en termes de temps plutôt qu'en taille. Par exemple, si vous sauvegardez le journal des transactions toutes les cinq minutes, vous risquez de perdre jusqu'à un peu moins de 5 minutes de données en cas de catastrophe. Je ne parle pas ici d'un simple basculement, mais disons que le serveur prend littéralement feu ou que quelqu'un trébuche sur le cordon d'alimentation - la base de données peut très bien être irrécupérable et vous devrez peut-être revenir au moment de la dernière sauvegarde du journal . Et cela en supposant que vous testiez même vos sauvegardes en les restaurant quelque part - en cas de panne critique, vous ne disposerez peut-être pas du point de récupération que vous pensez avoir. Nous avons tendance à ne pas penser à ce scénario, bien sûr, car nous ne nous attendons jamais à de mauvaises choses™ arriver.
Comment ça marche
La durabilité différée permet aux transactions d'écriture de continuer à s'exécuter comme si le journal avait été vidé sur le disque; en réalité, les écritures sur disque ont été regroupées et différées, pour être gérées en arrière-plan. La transaction est optimiste; il suppose que le vidage du journal sera arriver. Le système utilise un bloc de 60 Ko de tampon de journal et tente de vider le journal sur le disque lorsque ce bloc de 60 Ko est plein (au plus tard - cela peut arriver et arrivera souvent avant cela). Vous pouvez définir cette option au niveau de la base de données, au niveau de la transaction individuelle ou, dans le cas de procédures compilées en mode natif dans OLTP en mémoire, au niveau de la procédure. Le paramétrage de la base de données l'emporte en cas de conflit; par exemple, si la base de données est désactivée, toute tentative de validation d'une transaction à l'aide de l'option retardée sera simplement ignorée, sans message d'erreur. En outre, certaines transactions sont toujours entièrement durables, quels que soient les paramètres de la base de données ou les paramètres de validation ; par exemple, les transactions système, les transactions entre bases de données et les opérations impliquant FileTable, le suivi des modifications, la capture des données modifiées et la réplication.
Au niveau de la base de données, vous pouvez utiliser :
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Si vous le définissez sur ALLOWED , cela signifie que toute transaction individuelle peut utiliser la durabilité différée ; FORCED signifie que toutes les transactions qui peuvent utiliser la durabilité différée le seront (les exceptions ci-dessus sont toujours pertinentes dans ce cas). Vous voudrez probablement utiliser ALLOWED plutôt que FORCED - mais ce dernier peut être utile dans le cas d'une application existante où vous souhaitez utiliser cette option partout et également minimiser la quantité de code à toucher. Une chose importante à noter à propos de ALLOWED est que les transactions entièrement durables peuvent devoir attendre plus longtemps, car elles forceront d'abord le vidage de toutes les transactions durables retardées.
Au niveau de la transaction, vous pouvez dire :
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Et dans une procédure OLTP en mémoire compilée nativement, vous pouvez ajouter l'option suivante au BEGIN ATOMIC bloquer :
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Une question courante concerne ce qui se passe avec la sémantique de verrouillage et d'isolement. Rien ne change, vraiment. Le verrouillage et le blocage se produisent toujours, et les transactions sont validées de la même manière et avec les mêmes règles. La seule différence est qu'en autorisant la validation sans attendre que le journal soit vidé sur le disque, tous les verrous associés sont libérés beaucoup plus tôt.
Quand devriez-vous l'utiliser
En plus de l'avantage que vous obtenez en permettant aux transactions de se poursuivre sans attendre que l'écriture du journal se produise, vous obtenez également moins d'écritures de journal de plus grande taille. Cela peut très bien fonctionner si votre système a une forte proportion de transactions qui sont en fait inférieures à 60 Ko, et en particulier lorsque le disque de journal est lent (bien que j'ai trouvé des avantages similaires sur les SSD et les disques durs traditionnels). Cela ne fonctionne pas si bien si vos transactions sont, pour la plupart, supérieures à 60 Ko, si elles durent généralement longtemps ou si vous avez un débit élevé et une simultanéité élevée. Ce qui peut arriver ici, c'est que vous pouvez remplir tout le tampon du journal avant la fin du vidage, ce qui signifie simplement transférer vos attentes vers une autre ressource et, en fin de compte, ne pas améliorer les performances perçues par les utilisateurs de l'application.
En d'autres termes, si votre journal des transactions n'est pas actuellement un goulot d'étranglement, n'activez pas cette fonctionnalité. Comment savoir si votre journal des transactions est actuellement un goulot d'étranglement ? Le premier indicateur serait haut WRITELOG attend, en particulier lorsqu'il est couplé avec PAGEIOLATCH_** . Paul Randal (@PaulRandal) propose une excellente série en quatre parties sur l'identification des problèmes de journaux de transactions, ainsi que sur la configuration pour des performances optimales :
- Réduire la graisse du journal des transactions
- Réduire davantage de graisse du journal des transactions
- Problèmes de configuration du journal des transactions
- Surveillance du journal des transactions
Consultez également ce billet de blog de Kimberly Tripp (@KimberlyLTripp), 8 étapes pour améliorer le débit du journal des transactions, et le billet de blog de l'équipe SQL CAT, Diagnostiquer les problèmes de performances du journal des transactions et les limites du gestionnaire de journaux.
Cette enquête peut vous amener à la conclusion que la durabilité retardée vaut la peine d'être examinée ; ce n'est peut-être pas le cas. Tester votre charge de travail sera le moyen le plus fiable de savoir avec certitude. Comme beaucoup d'autres ajouts dans les versions récentes de SQL Server (*tousse* Hekaton ), cette fonctionnalité n'est PAS conçue pour améliorer chaque charge de travail et, comme indiqué ci-dessus, elle peut en fait aggraver certaines charges de travail. Consultez cet article de blog de Simon Harvey pour d'autres questions que vous devriez vous poser sur votre charge de travail afin de déterminer s'il est possible de sacrifier une certaine durabilité pour obtenir de meilleures performances.
Possibilité de perte de données
Je vais mentionner cela plusieurs fois, et mettre l'accent à chaque fois :Vous devez être tolérant à la perte de données . Avec un disque performant, le maximum que vous devriez vous attendre à perdre en cas de catastrophe - ou même un arrêt planifié et gracieux - est jusqu'à un bloc complet (60 Ko). Cependant, dans le cas où votre sous-système d'E/S ne peut pas suivre, il est possible que vous perdiez jusqu'à l'intégralité de la mémoire tampon du journal (~ 7 Mo).
Pour clarifier, à partir de la documentation (c'est moi qui souligne):
Pour une durabilité retardée, il n'y a aucune différence entre un arrêt inattendu et un arrêt/redémarrage attendu de SQL Server . Comme pour les événements catastrophiques, vous devez prévoir la perte de données . Lors d'un arrêt/redémarrage planifié, certaines transactions qui n'ont pas été écrites sur le disque peuvent d'abord être enregistrées sur le disque, mais vous ne devez pas planifier cela. Planifiez comme si un arrêt/redémarrage, planifié ou non, perdait les données de la même manière qu'un événement catastrophique.Il est donc très important que vous pesiez votre risque de perte de données avec votre besoin d'atténuer les problèmes de performances du journal des transactions. Si vous dirigez une banque ou quoi que ce soit qui traite de l'argent, il peut être beaucoup plus sûr et plus approprié pour vous de déplacer votre journal vers un disque plus rapide que de lancer les dés à l'aide de cette fonctionnalité. Si vous essayez d'améliorer le temps de réponse dans votre application Web Gamerz Chat Room, le risque est peut-être moins grave.
Vous pouvez contrôler ce comportement dans une certaine mesure afin de minimiser votre risque de perte de données. Vous pouvez forcer le vidage sur disque de toutes les transactions durables retardées de l'une des deux manières suivantes :
- Engagez toute transaction entièrement durable.
- Appelez
sys.sp_flush_logmanuellement.
Cela vous permet de revenir au contrôle de la perte de données en termes de temps plutôt que de taille; vous pouvez programmer le rinçage toutes les 5 secondes, par exemple. Mais vous voudrez trouver votre sweet spot ici; rincer trop souvent peut compenser l'avantage de durabilité retardée en premier lieu. Dans tous les cas, vous devrez toujours être tolérant à la perte de données , même si cela ne vaut que
On pourrait penser que CHECKPOINT peut aider ici, mais cette opération ne garantit pas techniquement que le journal sera vidé sur le disque.
Interaction avec HA/DR
Vous vous demandez peut-être comment Delayed Durablity fonctionne avec les fonctionnalités HA/DR telles que l'envoi de journaux, la réplication et les groupes de disponibilité. Avec la plupart d'entre eux, cela fonctionne sans changement. L'envoi et la réplication des journaux reliront les enregistrements de journal qui ont été renforcés, de sorte que le même potentiel de perte de données existe là-bas. Avec les AG en mode asynchrone, nous n'attendons pas l'accusé de réception secondaire de toute façon, il se comportera donc de la même manière qu'aujourd'hui. Avec synchrone, cependant, nous ne pouvons pas valider sur le primaire tant que la transaction n'est pas validée et renforcée dans le journal distant. Même dans ce scénario, nous pouvons avoir certains avantages localement en n'ayant pas à attendre que le journal local écrive, nous devons toujours attendre l'activité à distance. Donc, dans ce scénario, il y a moins d'avantages, et potentiellement aucun ; sauf peut-être dans le cas rare où le disque de journalisation du primaire est très lent et le disque de journalisation du secondaire est très rapide. Je soupçonne que les mêmes conditions s'appliquent à la mise en miroir synchronisée/asynchrone, mais vous n'obtiendrez aucun engagement officiel de ma part sur le fonctionnement d'une nouvelle fonctionnalité brillante avec une fonctionnalité obsolète. :-)
Observation des performances
Ce ne serait pas vraiment un article ici si je ne montrais pas des observations de performances réelles. J'ai configuré 8 bases de données pour tester les effets de deux modèles de charge de travail différents avec les attributs suivants :
- Modèle de récupération :simple ou complet
- Emplacement du journal :SSD ou HDD
- Durabilité :retardée ou entièrement durable
Je suis vraiment, vraiment, vraiment paresseux efficace sur ce genre de choses. Comme je veux éviter de répéter les mêmes opérations dans chaque base de données, j'ai créé temporairement la table suivante dans model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Ensuite, j'ai créé un ensemble de commandes SQL dynamiques pour créer ces 8 bases de données, plutôt que de créer les bases de données individuellement, puis de jouer avec les paramètres :
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
N'hésitez pas à exécuter ce code vous-même (avec le EXEC toujours commenté) pour voir que cela créerait 4 bases de données avec la durabilité différée désactivée (deux en récupération COMPLÈTE, deux en SIMPLE, une de chaque avec connexion sur disque lent et une de chacune avec connexion sur SSD). Répétez ce modèle pour 4 bases de données avec une durabilité retardée FORCÉE - je l'ai fait pour simplifier le code dans le test, plutôt que pour refléter ce que je ferais dans la vraie vie (où je voudrais probablement traiter certaines transactions comme critiques, et d'autres comme, enfin, moins que critique).
Pour vérifier l'intégrité, j'ai exécuté la requête suivante pour m'assurer que les bases de données avaient la bonne matrice d'attributs :
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Résultats :
| nom | modèle_récupération | delayed_durability | log_disk |
|---|---|---|---|
| jj1 | COMPLET | FORCÉ | SSD |
| dd2 | SIMPLE | FORCÉ | SSD |
| dd3 | COMPLET | FORCÉ | Disque dur |
| dd4 | SIMPLE | FORCÉ | Disque dur |
| dd5 | COMPLET | DÉSACTIVÉ | SSD |
| dd6 | SIMPLE | DÉSACTIVÉ | SSD |
| dd7 | COMPLET | DÉSACTIVÉ | Disque dur |
| dd8 | SIMPLE | DÉSACTIVÉ | Disque dur |
Configuration pertinente des 8 bases de test
J'ai également exécuté le test proprement plusieurs fois pour m'assurer qu'un fichier de données de 1 Go et un fichier journal de 1 Go seraient suffisants pour exécuter l'ensemble des charges de travail sans introduire d'événements de croissance automatique dans l'équation. En tant que meilleure pratique, je fais régulièrement tout mon possible pour m'assurer que les systèmes des clients disposent de suffisamment d'espace alloué (et d'alertes appropriées intégrées) de sorte qu'aucun événement de croissance ne se produise à un moment inattendu. Dans le monde réel, je sais que cela n'arrive pas toujours, mais c'est l'idéal.
J'ai configuré le système pour qu'il soit surveillé avec SQL Sentry - cela me permettrait d'afficher facilement la plupart des mesures de performances que je voulais mettre en évidence. Mais j'ai également créé une table temporaire pour stocker les métriques de lot, y compris la durée et la sortie très spécifique de sys.dm_io_virtual_file_stats :
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Cela me permettrait d'enregistrer l'heure de début et de fin de chaque lot individuel et de mesurer les deltas dans le DMV entre l'heure de début et l'heure de fin (uniquement fiable dans ce cas car je sais que je suis le seul utilisateur du système).
Beaucoup de petites transactions
Le premier test que je voulais effectuer était un grand nombre de petites transactions. Pour chaque base de données, je voulais aboutir à 500 000 lots distincts d'un seul insert chacun :
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Rappelez-vous, j'essaie d'être paresseux efficace sur ce genre de choses. Donc, pour générer le code pour les 8 bases de données, j'ai exécuté ceci :
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
J'ai exécuté ce test, puis j'ai regardé les #Metrics table avec la requête suivante :
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Cela a donné les résultats suivants (et j'ai confirmé par plusieurs tests que les résultats étaient cohérents) :
| base de données | écrit | octets | octets/écriture | io_stall_ms | heure_début | heure_de_fin | durée (secondes) |
|---|---|---|---|---|---|---|---|
| dd1 | 8 068 | 261 894 656 | 32 460,91 | 6 232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8 072 | 261 682 688 | 32 418,56 | 2 740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8 246 | 262 254 592 | 31 803,85 | 3 996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8 055 | 261 688 320 | 32 487,68 | 4 231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500 012 | 526 448 640 | 1 052,87 | 35 593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500 014 | 525 870 080 | 1 051,71 | 35 435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500 015 | 526 120 448 | 1 052,20 | 50 857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500 017 | 525 886 976 | 1 051,73 | 49 680 | 133 |
Petites transactions :durée et résultats de sys.dm_io_virtual_file_stats
Certainement quelques observations intéressantes ici :
- Le nombre d'opérations d'écriture individuelles était très faible pour les bases de données à durabilité différée (~ 60 X pour les bases de données traditionnelles).
- Le nombre total d'octets écrits a été réduit de moitié grâce à la durabilité différée (je suppose parce que toutes les écritures dans le cas traditionnel contenaient beaucoup d'espace perdu).
- Le nombre d'octets par écriture était beaucoup plus élevé pour la durabilité différée. Ce n'était pas trop surprenant, puisque le but de la fonctionnalité est de regrouper les écritures en lots plus importants.
- La durée totale des blocages d'E/S était volatile, mais d'environ un ordre de grandeur inférieur pour la durabilité retardée. Les blocages dans le cadre de transactions entièrement durables étaient beaucoup plus sensibles au type de disque.
- Si quelque chose ne vous a pas convaincu jusqu'à présent, la colonne de la durée est très révélatrice. Les lots entièrement durables qui prennent deux minutes ou plus sont presque réduits de moitié.
Les colonnes d'heure de début/fin m'ont permis de me concentrer sur le tableau de bord Performance Advisor pour la période précise où ces transactions se produisaient, où nous pouvons tirer de nombreux indicateurs visuels supplémentaires :
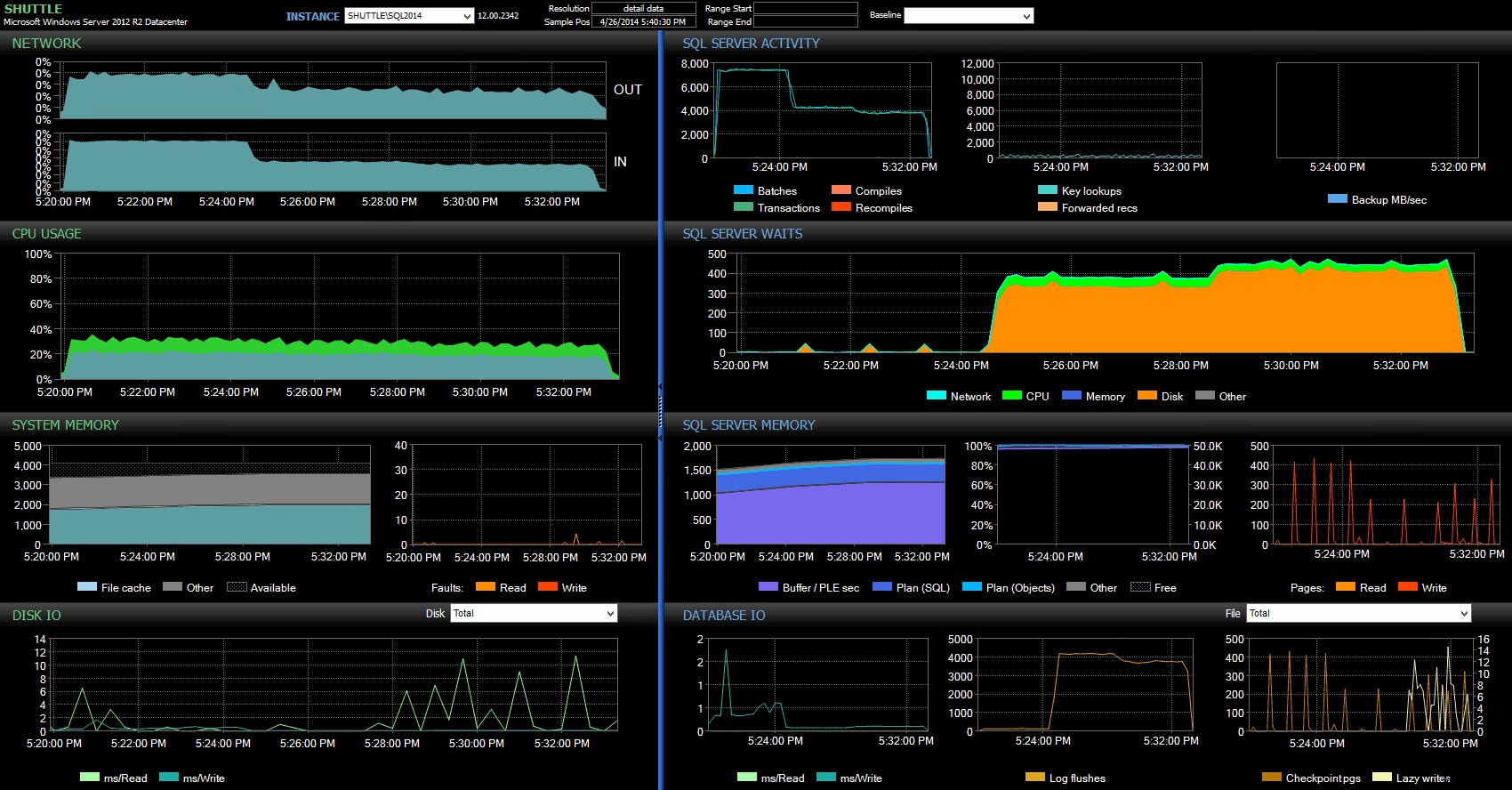
Tableau de bord SQL Sentry – cliquez pour agrandir
D'autres observations ici :
- Sur plusieurs graphiques, vous pouvez clairement voir exactement quand la partie de durabilité non retardée du lot a pris le relais (~17:24:32).
- Il n'y a aucun impact observable sur le processeur ou la mémoire lors de l'utilisation de la durabilité différée.
- Vous pouvez constater un impact considérable sur les lots/transactions par seconde dans le premier graphique sous Activité SQL Server.
- Les attentes de SQL Server explosent lorsque les transactions entièrement durables démarrent. Ceux-ci étaient composés presque exclusivement de
WRITELOGattend, avec un petit nombre dePAGEIOLOATCH_EXetPAGEIOLATCH_UPattend la bonne mesure. - Le nombre total de vidages de journaux tout au long des opérations de durabilité différée était assez faible (faible 100 s/s), alors qu'il est passé à plus de 4 000 s/s pour le comportement traditionnel (et légèrement inférieur pour la durée du test sur le disque dur).
Moins de transactions plus importantes
Pour le prochain test, je voulais voir ce qui se passerait si nous effectuions moins d'opérations, mais je me suis assuré que chaque instruction affectait une plus grande quantité de données. Je voulais que ce lot s'exécute sur chaque base de données :
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); J'ai donc encore une fois utilisé la méthode paresseuse pour produire 8 copies de ce script, une par base de données :
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
J'ai exécuté ce lot, puis modifié la requête par rapport à #Metrics ci-dessus pour regarder le deuxième test au lieu du premier. Les résultats :
| base de données | écrit | octets | octets/écriture | io_stall_ms | heure_début | heure_de_fin | durée (secondes) |
|---|---|---|---|---|---|---|---|
| dd1 | 20 970 | 1 271 911 936 | 60 653,88 | 12 577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20 997 | 1 272 145 408 | 60 587,00 | 14 698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20 973 | 1 272 982 016 | 60 696,22 | 12 085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20 958 | 1 272 064 512 | 60 695,89 | 11 795 | 143 | ||
| dd5 | 30 138 | 1 282 231 808 | 42 545,35 | 7 402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30 138 | 1 282 260 992 | 42 546,31 | 7 806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30 129 | 1 281 575 424 | 42 536,27 | 9 888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30 130 | 1 281 449 472 | 42 530,68 | 11 452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Transactions plus importantes :durée et résultats de sys.dm_io_virtual_file_stats
Cette fois, l'impact de la durabilité retardée est beaucoup moins perceptible. Nous voyons un nombre légèrement inférieur d'opérations d'écriture, à un nombre légèrement supérieur d'octets par écriture, avec le nombre total d'octets écrits presque identique. Dans ce cas, nous voyons en fait que les blocages d'E/S sont plus élevés pour la durabilité retardée, et cela explique probablement le fait que les durées étaient également presque identiques.
D'après le tableau de bord Performance Advisor, nous avons quelques similitudes avec le test précédent, ainsi que quelques différences importantes :
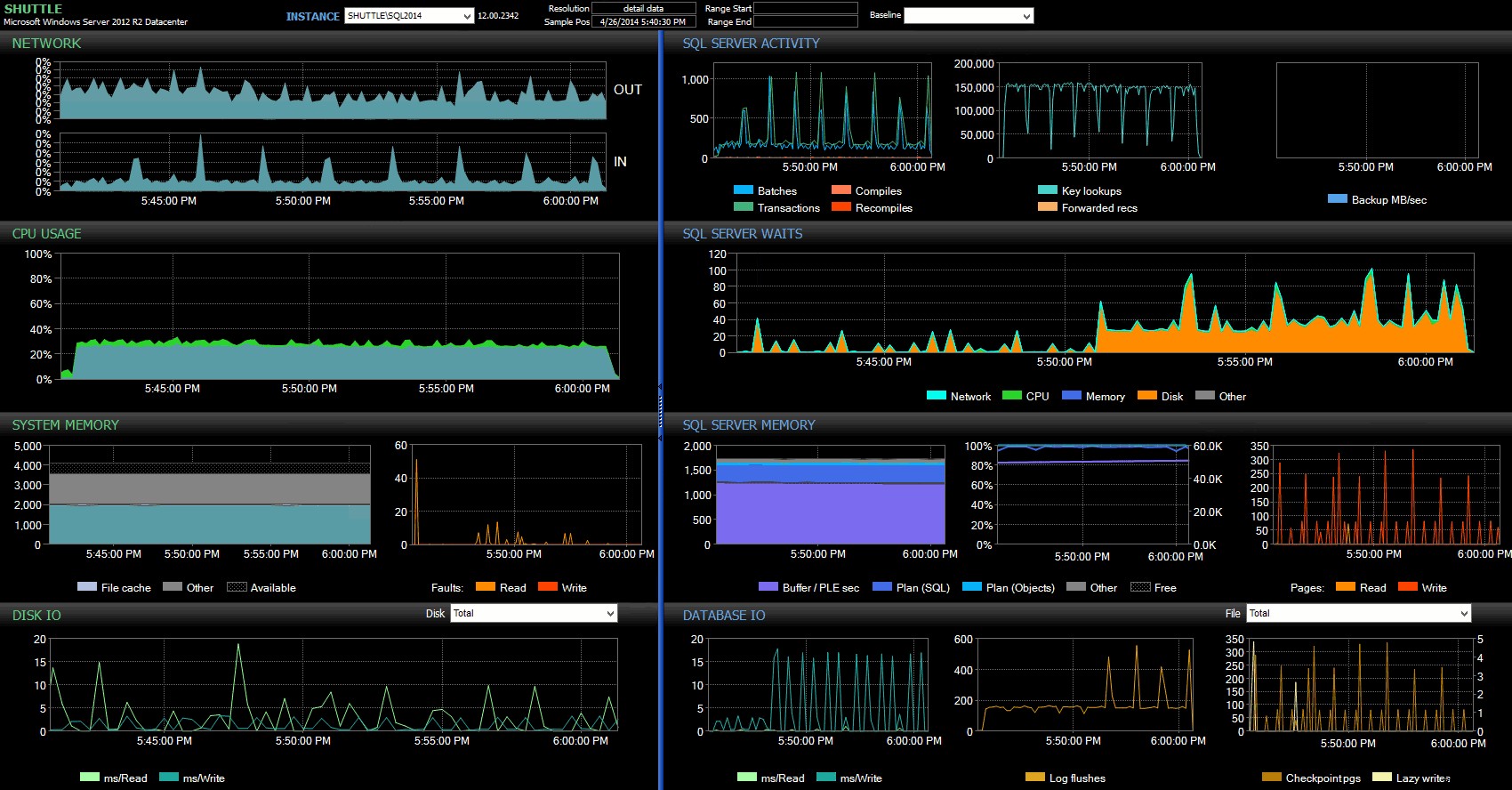
Tableau de bord SQL Sentry – cliquez pour agrandir
L'une des grandes différences à souligner ici est que le delta des statistiques d'attente n'est pas aussi prononcé qu'avec le test précédent - il y a toujours une fréquence beaucoup plus élevée de WRITELOG attend les lots entièrement durables, mais loin des niveaux observés avec les transactions plus petites. Une autre chose que vous pouvez remarquer immédiatement est que l'impact précédemment observé sur les lots et les transactions par seconde n'est plus présent. Et enfin, bien qu'il y ait plus de vidages de journaux avec des transactions entièrement durables que lorsqu'elles sont retardées, cette disparité est beaucoup moins prononcée qu'avec les transactions plus petites.
Conclusion
Il devrait être clair que certains types de charges de travail peuvent grandement bénéficier de la durabilité différée - à condition, bien sûr, que vous ayez une tolérance à la perte de données . Cette fonctionnalité n'est pas limitée à l'OLTP en mémoire, est disponible sur toutes les éditions de SQL Server 2014 et peut être implémentée avec peu ou pas de modifications de code. Cela peut certainement être une technique puissante si votre charge de travail peut le supporter. Mais encore une fois, vous devrez tester votre charge de travail pour vous assurer qu'elle bénéficiera de cette fonctionnalité, et également déterminer si cela augmente votre exposition au risque de perte de données.
Soit dit en passant, cela peut sembler être une nouvelle idée pour la foule de SQL Server, mais en vérité, Oracle l'a présenté sous le nom de "Commit asynchrone" en 2006 (voir COMMIT WRITE ... NOWAIT comme documenté ici et blogué en 2007). Et l'idée elle-même existe depuis près de 3 décennies; voir la brève chronique de Hal Berenson sur son histoire.
La prochaine fois
Une idée que j'ai lancée est d'essayer d'améliorer les performances de tempdb en y forçant la durabilité retardée. Une propriété spéciale de tempdb ce qui en fait un candidat si tentant est qu'il est transitoire par nature - n'importe quoi dans tempdb est conçu, explicitement, pour être lancé à la suite d'une grande variété d'événements système. Je dis cela maintenant sans avoir la moindre idée s'il existe une forme de charge de travail où cela fonctionnera bien ; mais je prévois de l'essayer, et si je trouve quelque chose d'intéressant, vous pouvez être sûr que je le posterai ici.