Il existe plusieurs façons de contacter quelqu'un de nos jours, n'est-ce pas ?
Nous disposons de différents téléphones :mobile et fixe, personnel et professionnel. Nous avons différentes adresses – résidentielles, postales, de facturation, professionnelles, etc. – et probablement plusieurs adresses e-mail également. N'oubliez pas Skype et diverses applications de messagerie. Ajoutez maintenant LinkedIn et Facebook - qui, soit dit en passant, ont tous deux leurs propres éléments de messagerie.
Il n'y a pas si longtemps, beaucoup d'entre eux n'existaient pas. Vous pouvez donc à peu près garantir que dans quelques années, nous aurons une nouvelle façon de contacter les personnes et les organisations.
Pouvons-nous modéliser toutes ces informations de contact de manière à ne pas avoir à modifier la conception de notre base de données lorsque "la dernière chose" arrive ? Lisez la suite pour le savoir…
Le modèle de point de contact des parties
En un mot, oui. Les bases de données peuvent être conçues pour contenir des informations que nous n'avons même pas encore.
Je vais me lancer directement et vous montrer la solution, puis je décrirai comment les pièces fonctionnent ensemble. Je vais appeler les différentes manières de contacter les parties points de contact , même si j'ai vu des méthodes de contact et même lieux de contact utilisé.
Physiquement, tous ces points de contact seront stockés dans une seule colonne de table, contact_point.contact_value . Pensez à un numéro de téléphone, une adresse e-mail ou une adresse Web (URL) et vous comprendrez pourquoi nous pouvons tous les stocker ici ; ce ne sont que des chaînes (varchars) à ce niveau. La différenciation est dans les métadonnées. La seule exception à cette règle est l'adresse postale, qui sera décrite plus en détail ultérieurement.
Les tableaux jaunes à gauche contiennent des métadonnées et les tableaux bleus à droite contiennent des données commerciales.
Les principales catégories
Bien que nous ayons de nombreuses façons de contacter quelqu'un, ces moyens appartiennent en fait à un petit nombre de catégories ou de types. Vous comprendrez ce que je veux dire en regardant la liste ci-dessous :
| Type de point de contact |
|---|
| Numéro de téléphone (fixe) |
| Numéro de portable |
| Numéro de fax |
| Adresse e-mail |
| Adresse postale |
| Adresse Web |
| Téléavertisseur |
En un sens, ceux-ci sont physiquement distincts. Bien sûr, vous pouvez utiliser un téléphone mobile pour appeler un téléphone fixe ou un autre mobile. En ce qui concerne les appels vocaux entre fixes et mobiles, la distinction n'est pas si importante. Pourtant, nous sommes plus susceptibles d'envoyer un SMS (SMS) vers un mobile que vers un téléphone fixe.
Mais vous n'êtes pas susceptible d'appeler délibérément un numéro de fax. Après tout, qu'allez-vous lui dire quand vous l'entendrez, à part "Oups, mauvais numéro" ? Vous êtes naturellement beaucoup plus susceptible d'appeler avec un autre télécopieur, qu'il soit physique ou émulé. Vous n'enverriez pas non plus de lettre à un téléphone fixe, ni ne tenteriez de passer un appel vocal à une adresse postale.
Il est important que nous distinguions ces types, car nous interagissons différemment avec eux. Cela sera particulièrement vrai si votre application a une sorte d'intégration avec des services de communication. Il doit savoir avec quel type interagir.
Comment les parties utilisent les points de contact
C'est probablement un peu plus intuitif, un peu plus conforme à la façon dont nous pensons aux types de contacts. Voici une liste plus longue (mais non exhaustive !) qui vous aidera à vous faire une idée de ces types :
| Type de contact de la partie (type de point de contact) |
|---|
| Ligne de conférence (numéro de téléphone) |
| Adresse de facturation (adresse postale) |
| Adresse de livraison (Adresse Postale) |
| Ligne directe (numéro de téléphone) |
| Adresse de vacances/vacances (adresse postale) |
| Téléphone de vacances/vacances (numéro de téléphone) |
| Adresse du domicile (adresse postale) |
| Téléphone personnel (numéro de téléphone) |
| Téléphone/télécopieur personnel (numéro de téléphone) |
| Profil LinkedIn (Adresse Web) |
| Adresse principale (adresse postale) |
| E-mail principal (adresse e-mail) |
| Fax principal (numéro de fax) |
| Téléphone principal (numéro de téléphone) |
| Site Web principal (adresse Web) |
| E-mail personnel (Adresse e-mail) |
| Fax personnel (numéro de fax) |
| Portable personnel (numéro de portable) |
| Téléavertisseur personnel (Téléavertisseur) |
| Site Web personnel (adresse Web) |
| Adresse secondaire (adresse postale) |
| Téléphone secondaire (numéro de téléphone) |
| Profil de réseau social (adresse Web) |
| Adresse professionnelle (adresse postale) |
| E-mail professionnel (adresse e-mail) |
| Fax professionnel (numéro de fax) |
| Portable professionnel (numéro de portable) |
| Téléphone professionnel (numéro de téléphone) |
L'adresse postale – Un cas particulier
Tous ces types de points de contact sont stockés dans un seul champ, à l'exception d'une adresse postale. Cela nécessite normalement un certain nombre de lignes (ou champs).
Il y a un article de blog ici qui propose un moyen simple et indépendant de la langue de stocker les adresses postales. Si vos exigences sont plutôt basiques - par ex. pour imprimer les étiquettes d'adresse à peu près au fur et à mesure qu'elles sont entrées dans le système - cette approche suffira probablement. Si vos besoins sont plus sophistiqués, vous devrez probablement développer une solution différente.
Pour avoir une idée de la complexité de l'adressage, jetez un coup d'œil à ce schéma pour les types d'adresses de la norme britannique BS7666. La norme comprend un certain nombre de parties couvrant les index des rues, les index des terrains et des propriétés et les points de livraison. Il ne fait pas de distinction entre les propriétés commerciales ou résidentielles ; entre terrains occupés, bâtis ou vacants ; entre zones urbaines ou rurales; ou entre entités adressables par la poste et entités non adressables par la poste s tels que les mâts de communication (tours). Pour y parvenir, il introduit des termes que la plupart d'entre nous ne connaissent probablement pas, tels que Primary Addressable Object (PAO), qui est le nom donné à un objet adressable qui peut être adressé sans référence à un autre objet adressable. Des exemples familiers de PAO incluent un nom de bâtiment ou un numéro de rue. Un objet adressable secondaire (SAO) est donné à tout objet adressable qui est adressé par référence à un PAO. Il peut s'agir du premier étage d'un bâtiment nommé.
Pour nous donner une visualisation de cela, je l'ai rapidement rétro-conçu dans un outil de modélisation UML. Voici ce que nous obtenons :
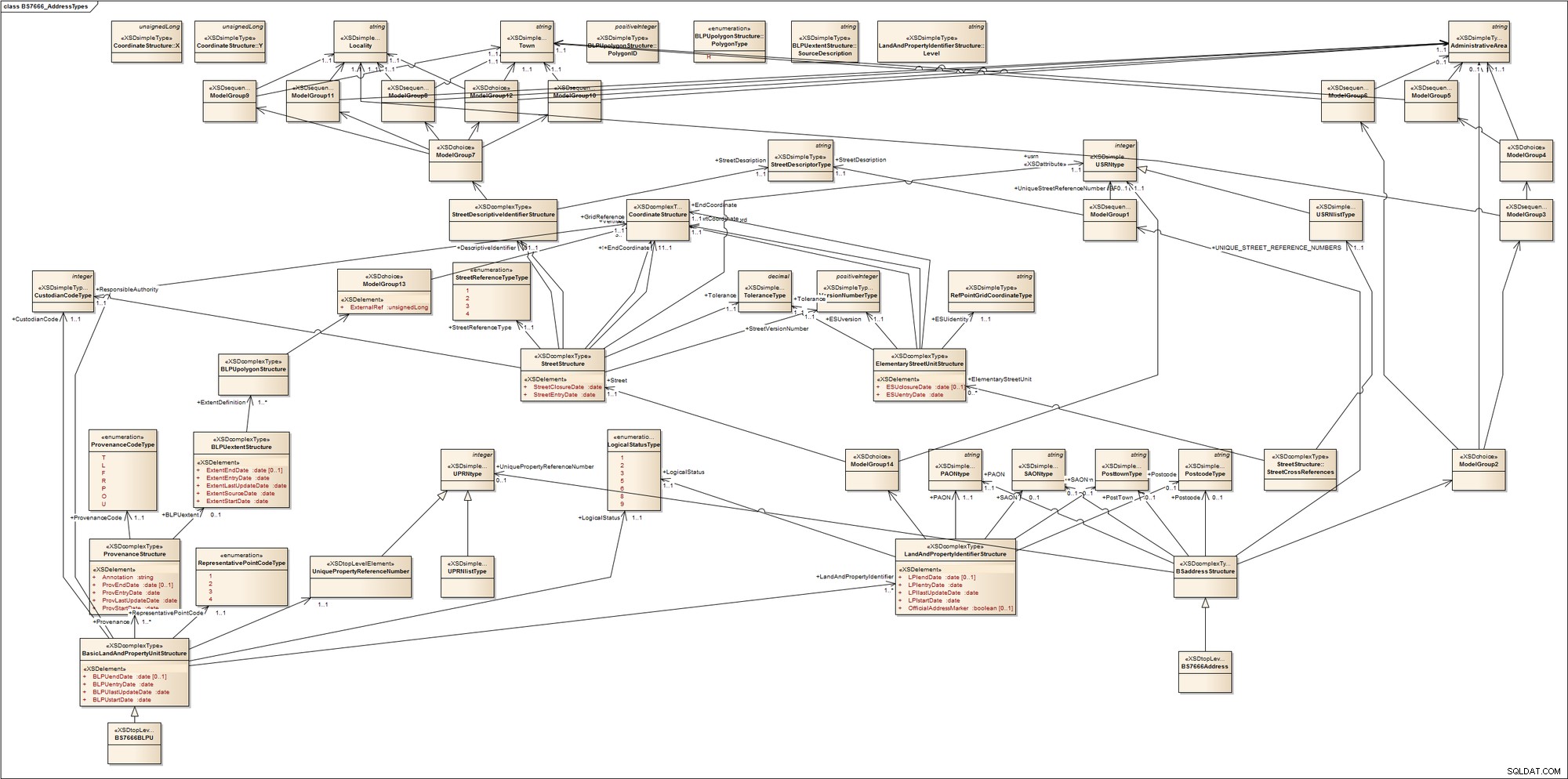
Ce que je veux dire, c'est que cela peut devenir assez compliqué et désordonné; l'adressage dans certains domaines peut être très complexe.
Si vous deviez aplatir cela dans une seule table relationnelle, vous obtiendriez quelque chose comme ceci :
Bien que cela capture les composants d'adresse BS7666, cela ne vous dit pas comment le modèle fonctionne. Toute la logique relationnelle du schéma XML est cachée dans la logique de l'application.
Ces deux diagrammes représentent deux extrêmes de modélisation de données . Mais existe-t-il une solution intermédiaire pour modéliser les adresses ?
Il est en effet possible d'avoir un modèle d'adressage relativement simple, flexible et paramétrable.
Composants d'adresse
Un composant d'adresse est généralement une ligne sur une étiquette d'adresse, ou plutôt un type de ligne sur une étiquette d'adresse. Les types de composants que nous utilisons généralement pour les adresses au Royaume-Uni sont répertoriés dans le tableau suivant :
| Type de composant d'adresse |
|---|
| Destinataire |
| Zone |
| Nom du bâtiment |
| Numéro de bâtiment |
| Pays |
| Comté |
| Nom du service |
| Localité dépendante |
| Nom de la voie dépendante |
| Localité à double dépendance |
| Code postal international |
| Niveau |
| Localité |
| SSC Mailsort |
| Nom de l'organisation |
| Numéro de fin PAO |
| Suffixe de fin PAO |
| Numéro de départ PAO |
| Suffixe de début PAO |
| Texte PAO |
| Boîte postale |
| Code postal |
| Ville postale |
| Code postal |
| Type de code postal |
| Numéro de fin SAO |
| Suffixe de fin SAO |
| Numéro de départ SAO |
| Suffixe de début SAO |
| Texte SAO |
| Rue |
| Description de la rue |
| Nom du sous-bâtiment |
| Nom de la voie |
| Ville |
Vous pouvez avoir trois ou quatre lignes d'adresse, plus la ville postale et le code postal. Cependant, la difficulté que vous rencontrerez est d'identifier ce que contiennent réellement ces lignes quand c'est important - par ex. lors du mappage des données entre les systèmes. Lorsque vous effectuez le profilage des données, vous constaterez que la ligne d'adresse 3 contient parfois une localité dépendante, mais à d'autres moments, elle contient un comté ou une localité. Vous êtes maintenant dans le traitement du langage naturel (NLP); vous devez reconnaître la différence entre localité et département. Et les permutations se multiplient au fur et à mesure que vous ajoutez des pays.
Nous devons donc définir tous les composants d'adresse pour tous les pays dans lesquels nous opérons.
Formats d'adresse
Les formats d'adresse sont composés de deux parties :un en-tête et son détail. L'en-tête est essentiellement le nom ou le titre que le format d'adresse est connu par. Les exemples pourraient inclure :
| Type de format d'adresse |
|---|
| 3 lignes génériques |
| 5 lignes génériques |
| Bureau de poste des forces britanniques (BFPO) |
| International |
| Adresse du bureau de poste (PAF) |
| États-Unis Adresse |
| Adresse française |
En prenant le format d'adresse postale complète (PAF) du Royaume-Uni à titre d'exemple, nous définissons ensuite les composants de format d'adresse suivants :
| Format | Composant | Séquence | Est-ce obligatoire ? |
|---|---|---|---|
| PAF | Destinataire | 1 | N |
| PAF | Nom de l'organisation | 2 | N |
| PAF | Nom du service | 3 | N |
| PAF | Boîte postale | 4 | N |
| PAF | Nom du bâtiment | 5 | N |
| PAF | Nom du sous-bâtiment | 6 | N |
| PAF | Numéro de bâtiment | 7 | N |
| PAF | Voie | 8 | N |
| PAF | Rue | 9 | N |
| PAF | Localité à double dépendance | 10 | N |
| PAF | Localité dépendante | 11 | N |
| PAF | Ville de poste | 12 | O |
| PAF | Code postal | 13 | O |
Notre application lit ces métadonnées et affiche les composants de l'adresse dans le bon ordre. Lorsque la capture d'adresse est requise, les métadonnées nous indiquent si le composant d'adresse est obligatoire ou non.
Le plus souvent, notre application demande le code postal à l'utilisateur final, recherche les valeurs correspondantes et remplit automatiquement les composants de l'adresse. Certaines applications permettent à l'utilisateur de modifier l'adresse ; les autres [ennuyeux] ne le font pas !
Il n'est pas affiché dans le PDM, mais si votre organisation opère à l'international, vous pouvez définir une relation plusieurs à plusieurs entre address_format_type et country afin que le format d'adresse correct (basé sur le pays de l'utilisateur) soit présenté à l'utilisateur final (party ).
Quand et seulement quand le contact_point est une adresse postale contact_point_type , il doit avoir une relation avec un address_format_type. Inversement, il s'ensuit que les types d'adresses non postales jamais avoir une relation avec un address_format_type . De plus, le format doit rester fixe pour la durée de vie du contact_point , sinon vous introduirez la possibilité de problèmes d'intégrité des données. (Pour que cela ne soit pas le cas , la cible address_format_components doit être un sous-ensemble de la source address_format_components ).
La colonne contact_value n'a aucune signification pour une adresse postale car les valeurs sont stockées dans un ddress_line.line_content . Inversement, contact_value est obligatoire pour tous les autres contact_point_types . En gros, contact_point.contact_value et address_line.line_content sont mutuellement exclusifs.
La relation plusieurs à plusieurs entre la partie et le point de contact
Vous pouvez penser à contact_point (plus address_line ) comme contenant les valeurs et party_contact comme définissant l'utilisation. Cela permet à un seul contact_point avoir des utilisations multiples . Notre adresse personnelle [postale] peut également être notre adresse de facturation et notre adresse de livraison, selon le contexte.
Jusqu'à présent, le récit a supposé qu'une partie possède un contact_point particulier . Mais le modèle de données n'impose pas cette règle de propriété ! Il ne fait aucune restriction de ce genre. Il existe une autre possibilité avec cette conception :plusieurs parties pour les mêmes points de contact.
Vous devez examiner attentivement les implications avant de vous aventurer dans cette voie.
Voici un exemple. Au Royaume-Uni, les organisations de certification (AO) emploient généralement des enseignants comme examinateurs. Un enseignant a deux relations :une avec l'école où il travaille et une autre avec l'AO en tant qu'examinateur. L'école disposera d'une banque de contact_points avec différents numéros de téléphone et éventuellement une ou plusieurs adresses postales. Ce seront des choses comme l'adresse principale de l'école (adresse postale), l'e-mail principal (adresse e-mail), le fax principal (numéro de fax) et le téléphone principal (numéro de téléphone).
Il est tout à fait possible que notre examinateur puisse utiliser les mêmes contact_points comme son école, mais il utilisera party_contact les définir comme liés au travail. Si le numéro de téléphone principal de l'école change, le numéro de travail de l'enseignant sera automatiquement mis à jour, ce qui est plutôt sympa.
Si vous suivez cette voie, vous devrez définir au niveau de l'application quelle partie ou quelles parties sont autorisées à mettre à jour les contact_points .
Un mot rapide sur les performances
Les tables de métadonnées jaunes vont être constamment utilisées par les requêtes. Par conséquent, ils sont susceptibles de rester en mémoire. Sur la plupart des SGBDR, vous pouvez épingler des tables en mémoire pour vous en assurer. Dans Oracle, je les créerais sous forme de tables organisées en index, qui sont petites et performantes. Faites l'équivalent pour votre SGBDR.
Vous voulez également vous assurer que party_contact les lignes sont co-localisées dans le même bloc (ou page) en utilisant un index clusterisé sur party_id . Faites de même avec address_line.contact_point_id . Cela réduit la quantité d'IO.
Une autre option existe si vous voulez une party être propriétaire exclusif d'un contact_point . Vous pouvez ensuite fusionner contact_point dans party_contact pour créer party_contact_point (toujours groupé sur party_id ). Cela simplifie le modèle et peut améliorer les performances.
Modifier les contacts ne signifie pas changer les bases de données
Nous vivons à une époque où l'on peut dire que le changement est la seule constante.
Cela ne signifie pas que chaque fois que quelque chose change, cela doit avoir un impact sur votre base de données. Avec un peu de réflexion, nous pouvons pérenniser nos conceptions - peut-être plus que nous ne l'avons fait jusqu'à présent. Cela nous aide à réagir rapidement au changement inévitable.
Si vous vous lancez dans un projet entièrement nouveau, je recommanderais d'utiliser le modèle Party (dont le point de contact fait partie) pour les organisations et les personnes. Pourquoi ne pas ouvrir le modèle et l'adapter à vos besoins ? N'hésitez pas à en prendre une copie et à la personnaliser.
Mais si votre ou vos bases de données sont déjà déterminées, le schéma que j'ai présenté ici peut toujours être utilisé, sous forme XML, pour définir votre charge utile lors de l'intégration de données entre systèmes.