Dans notre précédent blog sur les tableaux de bord SCUMM, nous avons examiné le tableau de bord de présentation de MySQL. La nouvelle version de ClusterControl (ver. 1.7) propose un certain nombre de graphiques haute résolution de métriques utiles, et nous avons expliqué la signification de chacune des métriques et comment elles vous aident à dépanner votre base de données. Dans ce blog, nous examinerons le tableau de bord MySQL Replication. Continuons sur les détails de ce tableau de bord sur ce qui a à offrir.
Tableau de bord de réplication MySQL
Le tableau de bord de réplication MySQL propose des ensembles de graphiques très simples qui facilitent la surveillance de votre maître MySQL et de vos répliques. En partant du haut, il affiche les variables et informations les plus importantes pour déterminer l'état de santé des répliques ou même du maître. Ce tableau de bord offre une partie très utile lors de l'inspection de la santé des esclaves ou d'un maître dans la configuration maître-maître. On peut également vérifier sur ce tableau de bord la création du journal binaire du maître et déterminer la dimension globale, en termes de taille générée, à une période de temps donnée.
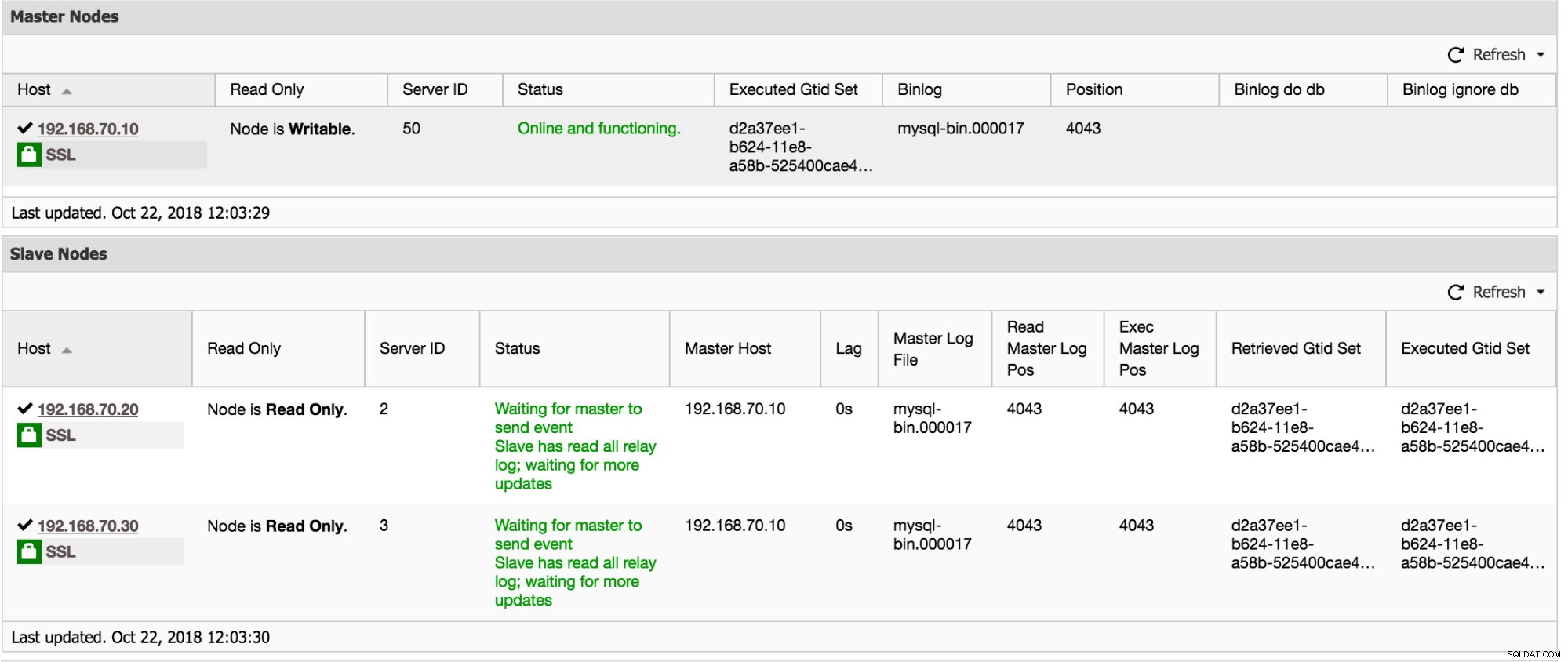
Première chose dans ce tableau de bord, il vous présente les informations les plus importantes dont vous pourriez avoir besoin concernant la santé de votre réplique. Voir le graphique ci-dessous :

Fondamentalement, il vous montrera l'IO_Thread, le SQL_Thread, l'erreur de réplication du thread esclave et si la variable read_only est activée. À partir de l'exemple de capture d'écran ci-dessus, toutes les informations montrent que mon esclave 192.168.70.20 est sain et fonctionne normalement.
De plus, ClusterControl a également des informations à collecter si vous accédez à Cluster -> Présentation. Faites défiler vers le bas et vous pouvez voir le graphique ci-dessous :
Un autre endroit pour afficher la configuration de la réplication est la vue topologique de la configuration de la réplication, accessible dans Cluster -> Topologie. Il donne, en un coup d'œil rapide, une vue des différents nœuds de la configuration, leurs rôles, le décalage de réplication, le GTID récupéré et plus encore. Voir le graphique ci-dessous :
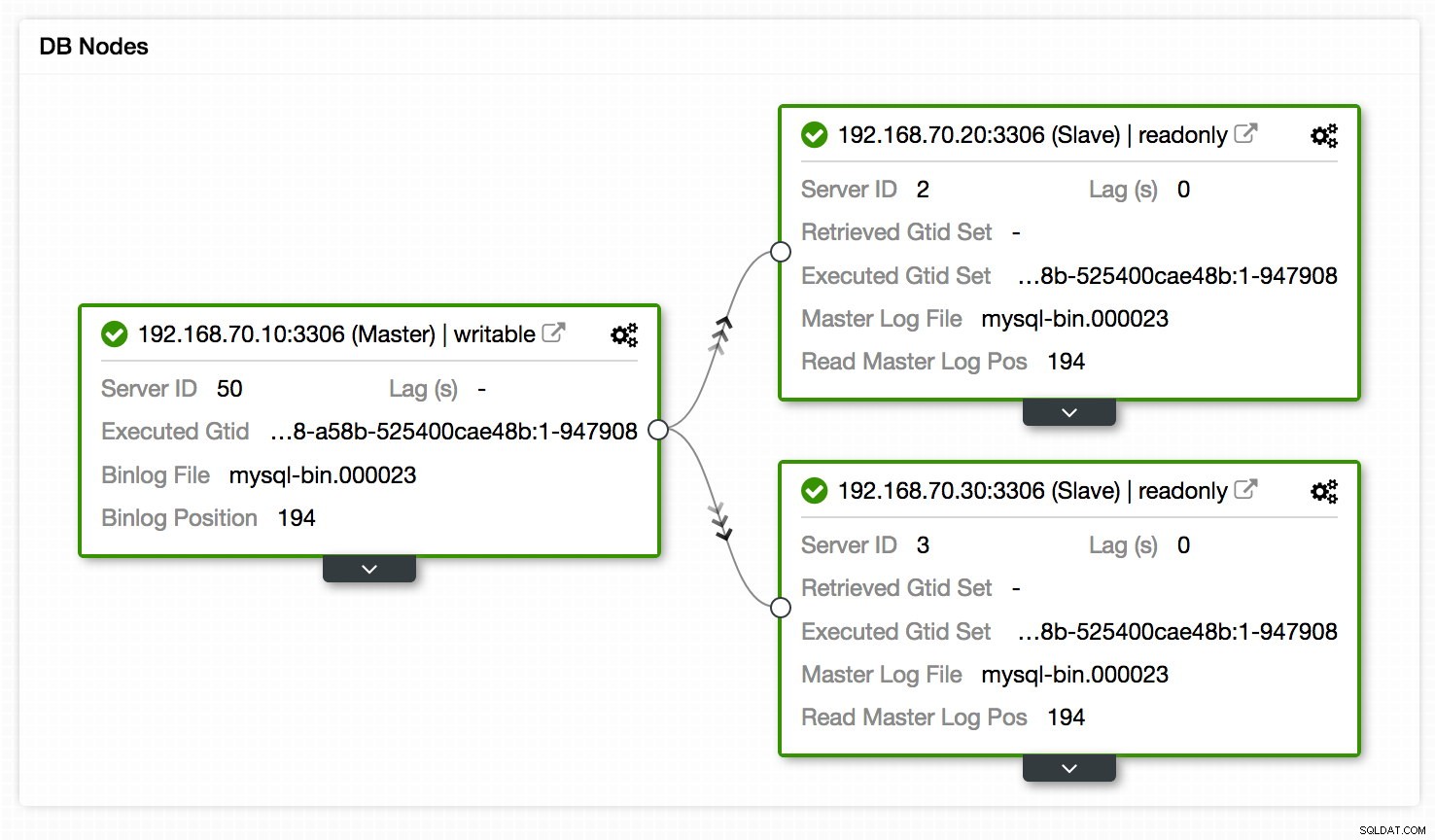
En plus de cela, la vue topologique affiche également tous les différents nœuds qui font partie de votre cluster de base de données, qu'il s'agisse des nœuds de base de données, des équilibreurs de charge (ProxySQL/MaxScale/HaProxy) ou des arbitres (garbd), ainsi que les connexions entre eux. Les nœuds, les connexions et leurs états sont découverts par ClusterControl. Étant donné que ClusterControl surveille en permanence les nœuds et conserve les informations d'état, toute modification de la topologie est reflétée dans l'interface Web. En cas de défaillance des nœuds signalés, vous pouvez utiliser cette vue avec les tableaux de bord SCUMM et voir quel impact cela pourrait avoir.
La vue topologique présente certaines similitudes avec Orchestrator dans laquelle vous pouvez gérer les nœuds, modifier les maîtres en faisant glisser et déposer l'objet sur le maître souhaité, redémarrer les nœuds et synchroniser les données. Pour en savoir plus sur notre Topology View, nous vous suggérons de lire notre blog précédent - "Visualiser la topologie de votre cluster dans ClusterControl".
Passons maintenant aux graphiques.
-
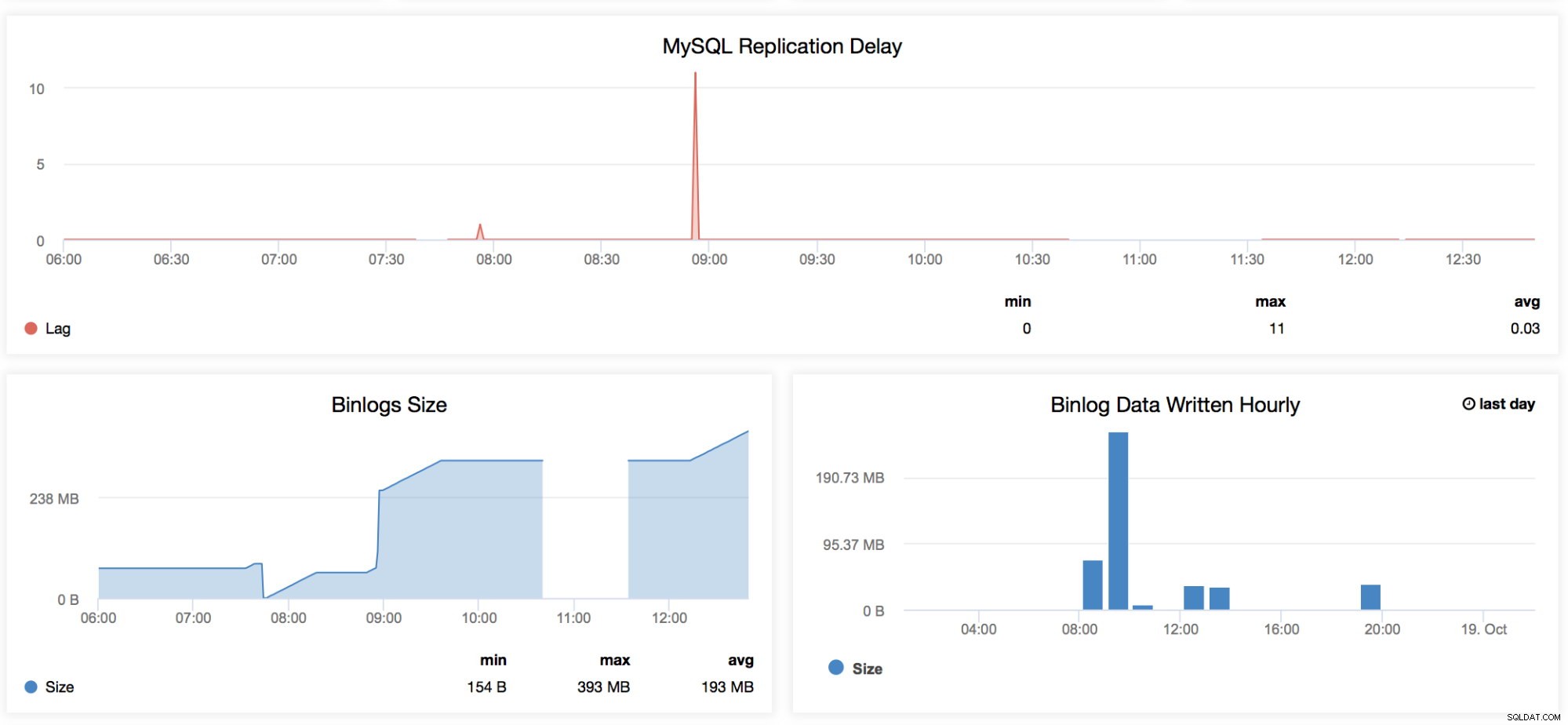
Délai de réplication MySQL
Ce graphique est très familier à quiconque gère MySQL, en particulier à ceux qui travaillent quotidiennement sur leur configuration maître-esclave. Ce graphique présente les tendances de tous les retards enregistrés pour une plage de temps spécifique spécifiée dans ce tableau de bord. Chaque fois que nous voulons vérifier le temps de chute périodique de notre réplique, ce graphique est bon à regarder. Il y a certaines occasions où une réplique peut être retardée pour des raisons étranges, comme votre RAID a un BBU dégradé et a besoin d'un remplacement, une table n'a pas de clé unique mais pas sur le maître, une analyse complète de la table indésirable ou une analyse complète de l'index, ou une mauvaise requête a été laissé en cours d'exécution par un développeur. C'est également un bon indicateur pour déterminer si le décalage de l'esclave est un problème clé, alors vous voudrez peut-être tirer parti de la réplication parallèle. -
Taille du binlog
Ces graphiques sont liés les uns aux autres. Le graphique Binlog Size vous montre comment votre nœud génère le journal binaire et aide à déterminer sa dimension en fonction de la période de temps que vous analysez. -
Données Binlog écrites par heure
Les données Binlog écrites par heure sont un graphique basé sur le jour actuel et le jour précédent enregistré. Cela peut être utile chaque fois que vous souhaitez identifier la taille de votre nœud qui accepte les écritures, que vous pourrez ensuite utiliser pour la planification de la capacité.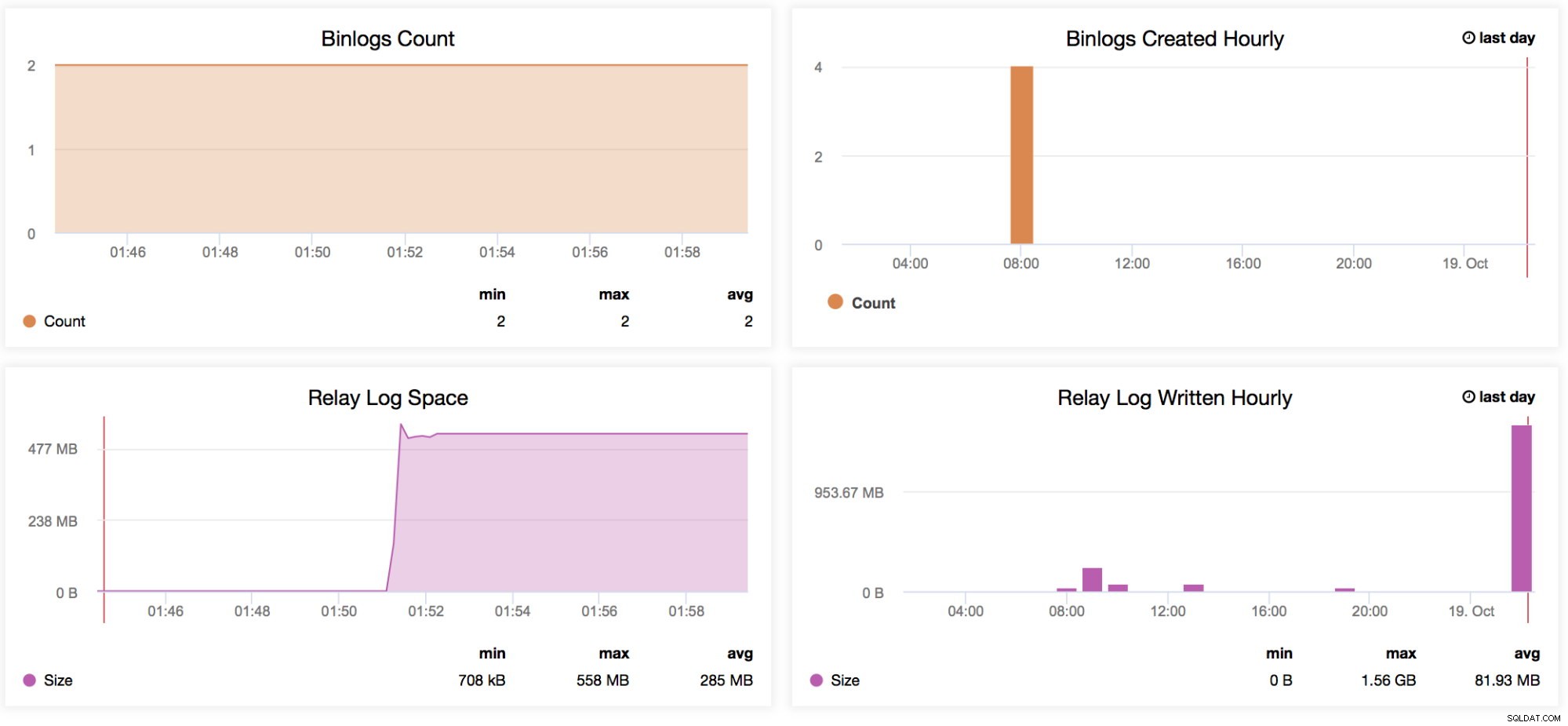
-
Binlogs Count
Supposons que vous vous attendiez à un trafic élevé pour une semaine donnée. Vous souhaitez comparer la taille des écritures passant par votre maître et vos esclaves avec la semaine précédente. Ce graphique est très utile pour ce genre de situation - Pour déterminer la hauteur des logs binaires générés sur le maître lui-même ou même sur les esclaves si la variable log_slave_updates est activée. Vous pouvez également utiliser cet indicateur pour déterminer vos données de journal binaire maître vs esclaves générées, en particulier si vous filtrez certaines tables ou schémas (replicate_ignore_db, replica_ignore_table, replica_wild_do_table) sur vos esclaves qui ont été générés alors que log_slave_updates est activé. -
Binlogs créés toutes les heures
Ce graphique est un aperçu rapide pour comparer la création de vos binlogs toutes les heures entre hier et la date d'aujourd'hui. -
Espace de journal de relais
Ce graphique sert de base aux journaux de relais générés à partir de votre réplica. Lorsqu'il est utilisé avec le graphique MySQL Replication Delay, il permet de déterminer le nombre de journaux de relais générés, ce que l'administrateur doit prendre en compte en termes de disponibilité du disque du réplica actuel. Cela peut causer des problèmes lorsque votre esclave est rigoureusement en retard et génère un grand nombre de journaux de relais. Cela peut consommer votre espace disque rapidement. Dans certaines situations, en raison d'un nombre élevé d'écritures du maître, l'esclave/la réplique accusera un retard considérable. Ainsi, la génération d'une grande quantité de journaux peut entraîner de graves problèmes sur cette réplique. Cela peut aider l'équipe des opérations lorsqu'elle discute avec sa direction de la planification des capacités. -
Journal de relais écrit toutes les heures
Identique à l'espace de journal de relais mais ajoute un aperçu rapide pour comparer vos journaux de relais écrits depuis hier et la date d'aujourd'hui.
Conclusion
Vous avez appris que l'utilisation de SCUMM pour surveiller votre réplication MySQL ajoute plus de productivité et d'efficacité à l'équipe des opérations. Utiliser les fonctionnalités que nous avons des versions précédentes combinées avec les graphiques fournis avec SCUMM, c'est comme aller au gymnase et voir des améliorations massives de votre productivité. C'est ce que SCUMM peut vous proposer :du monitoring sous stéroïdes ! (maintenant, nous ne préconisons pas que vous deviez prendre des stéroïdes lorsque vous allez à la salle de sport !)
Dans la partie 3 de ce blog, je discuterai des tableaux de bord InnoDB Metrics et MySQL Performance Schema.