Presque tous les problèmes de performances liés aux colonnes calculées que j'ai rencontrés au fil des ans ont eu une (ou plusieurs) des causes profondes suivantes :
- Limites de mise en œuvre
- Manque de prise en charge du modèle de coût dans l'optimiseur de requêtes
- Extension de la définition de colonne calculée avant le début de l'optimisation
Un exemple de limite de mise en œuvre n'est pas en mesure de créer un index filtré sur une colonne calculée (même persistante). Nous ne pouvons pas faire grand-chose à propos de cette catégorie de problèmes; nous devons utiliser des solutions de contournement en attendant que les améliorations du produit arrivent.
L'absence de prise en charge du modèle de coût par l'optimiseur signifie que SQL Server affecte un faible coût fixe aux calculs scalaires, quelle que soit la complexité ou la mise en œuvre. Par conséquent, le serveur décide souvent de recalculer une valeur de colonne calculée stockée au lieu de lire directement la valeur persistante ou indexée. Cela est particulièrement pénible lorsque l'expression calculée est coûteuse, par exemple lorsqu'elle implique l'appel d'une fonction scalaire définie par l'utilisateur.
Les problèmes liés à l'élargissement de la définition sont un peu plus impliqués et ont des effets de grande envergure.
Les problèmes de l'expansion des colonnes calculées
SQL Server développe normalement les colonnes calculées dans leurs définitions sous-jacentes pendant la phase de liaison de la normalisation des requêtes. Il s'agit d'une phase très précoce du processus de compilation des requêtes, bien avant que toute décision de sélection de plan ne soit prise (y compris un plan trivial).
En théorie, effectuer une expansion précoce pourrait permettre des optimisations qui seraient autrement manquées. Par exemple, l'optimiseur peut être en mesure d'appliquer des simplifications en fonction d'autres informations dans la requête et les métadonnées (par exemple, des contraintes). C'est le même type de raisonnement qui conduit à développer les définitions de vue (à moins qu'un NOEXPAND indice est utilisé).
Plus tard dans le processus de compilation (mais avant même qu'un plan trivial n'ait été envisagé), l'optimiseur cherche à faire correspondre les expressions aux colonnes calculées persistantes ou indexées. Le problème est que les activités de l'optimiseur entre-temps ont peut-être modifié les expressions étendues de sorte que la correspondance n'est plus possible.
Lorsque cela se produit, le plan d'exécution final donne l'impression que l'optimiseur a raté une opportunité "évidente" d'utiliser une colonne calculée persistante ou indexée. Il y a peu de détails dans les plans d'exécution qui peuvent aider à déterminer la cause, ce qui en fait un problème potentiellement frustrant à déboguer et à corriger.
Mettre en correspondance des expressions avec des colonnes calculées
Il convient d'être particulièrement clair sur le fait qu'il existe ici deux processus distincts :
- Extension précoce des colonnes calculées ; et
- Tentatives ultérieures de correspondance des expressions avec les colonnes calculées.
En particulier, notez que toute expression de requête peut être associée ultérieurement à une colonne calculée appropriée, et pas seulement aux expressions résultant de l'expansion des colonnes calculées.
La correspondance d'expression de colonne calculée peut permettre d'améliorer le plan même lorsque le texte de la requête d'origine ne peut pas être modifié. Par exemple, la création d'une colonne calculée pour correspondre à une expression de requête connue permet à l'optimiseur d'utiliser les statistiques et les index associés à la colonne calculée. Cette fonctionnalité est conceptuellement similaire à la correspondance des vues indexées dans Enterprise Edition. La correspondance des colonnes calculées est fonctionnelle dans toutes les éditions.
D'un point de vue pratique, ma propre expérience a montré que la correspondance d'expressions de requête générales avec des colonnes calculées peut en effet améliorer les performances, l'efficacité et la stabilité du plan d'exécution. D'un autre côté, j'ai rarement (voire jamais) trouvé que l'expansion de colonne calculée en valait la peine. Cela ne semble jamais donner d'optimisations utiles.
Utilisations des colonnes calculées
Colonnes calculées qui ne sont aucune persisted ni indexed ont des utilisations valides. Par exemple, ils peuvent prendre en charge des statistiques automatiques si la colonne est déterministe et précise (pas d'éléments à virgule flottante). Ils peuvent également être utilisés pour économiser de l'espace de stockage (au prix d'une petite utilisation supplémentaire du processeur d'exécution). Comme dernier exemple, ils peuvent fournir un moyen astucieux de s'assurer qu'un calcul simple est toujours effectué correctement, plutôt que d'être explicitement écrit dans les requêtes à chaque fois.
Persistant des colonnes calculées ont été ajoutées au produit spécifiquement pour permettre la construction d'index sur des colonnes déterministes mais "imprécises" (virgule flottante). D'après mon expérience, cette utilisation prévue est relativement rare. C'est peut-être simplement parce que je ne rencontre pas beaucoup de données à virgule flottante.
Mis à part les index à virgule flottante, les colonnes persistantes sont assez courantes. Dans une certaine mesure, cela peut être dû au fait que les utilisateurs inexpérimentés supposent qu'une colonne calculée doit toujours être persistante avant de pouvoir être indexée. Les utilisateurs plus expérimentés peuvent utiliser des colonnes persistantes simplement parce qu'ils ont constaté que les performances ont tendance à être meilleures de cette façon.
Indexé les colonnes calculées (persistantes ou non) peuvent être utilisées pour fournir un ordre et une méthode d'accès efficace. Il peut être utile de stocker une valeur calculée dans un index sans la conserver également dans la table de base. De même, des colonnes calculées appropriées peuvent également être incluses dans des index plutôt que d'être des colonnes clés.
Performances médiocres
Une cause majeure de performances médiocres est un simple échec à utiliser une valeur de colonne calculée indexée ou persistante comme prévu. J'ai perdu le compte du nombre de questions que j'ai eues au fil des ans pour demander pourquoi l'optimiseur choisirait un plan d'exécution terrible alors qu'il existe un plan manifestement meilleur utilisant une colonne calculée indexée ou persistante.
La cause précise dans chaque cas varie, mais est presque toujours soit une mauvaise décision basée sur les coûts (car les scalaires se voient attribuer un faible coût fixe); ou un échec de correspondance d'une expression étendue avec une colonne ou un index calculé persistant.
Les échecs de match-back sont particulièrement intéressants pour moi, car ils impliquent souvent des interactions complexes avec des fonctionnalités orthogonales du moteur. Tout aussi souvent, l'échec de la "correspondance" laisse une expression (plutôt qu'une colonne) dans une position dans l'arborescence de requête interne qui empêche la correspondance d'une règle d'optimisation importante. Dans les deux cas, le résultat est le même :un plan d'exécution sous-optimal.
Maintenant, je pense qu'il est juste de dire que les gens indexent ou conservent généralement une colonne calculée avec la forte attente que la valeur stockée sera réellement utilisée. Il peut être assez choquant de voir SQL Server recalculer l'expression sous-jacente à chaque fois, tout en ignorant la valeur stockée délibérément fournie. Les gens ne sont pas toujours très intéressés par les interactions internes et les lacunes du modèle de coût qui ont conduit au résultat indésirable. Même lorsqu'il existe des solutions de contournement, celles-ci nécessitent du temps, des compétences et des efforts pour être découvertes et testées.
En bref :de nombreuses personnes préféreraient simplement que SQL Server utilise la valeur persistante ou indexée. Toujours.
Une nouvelle option
Historiquement, il n'y avait aucun moyen de forcer SQL Server à toujours utiliser la valeur stockée (pas d'équivalent au NOEXPAND indice pour les vues). Il existe certaines circonstances dans lesquelles un guide de plan fonctionnera, mais il n'est pas toujours possible de générer la forme de plan requise en premier lieu, et tous les éléments et positions du plan ne peuvent pas être forcés (filtres et calculs scalaires, par exemple).
Il n'existe toujours pas de solution soignée et entièrement documentée, mais une récente mise à jour de SQL Server 2016 a fourni une nouvelle approche intéressante. Il s'applique aux instances SQL Server 2016 corrigées avec au moins la mise à jour cumulative 2 pour SQL Server 2016 SP1 ou la mise à jour cumulative 4 pour SQL Server 2016 RTM.
La mise à jour pertinente est documentée dans :CORRECTIF :Impossible de reconstruire la partition en ligne pour une table contenant une colonne de partitionnement calculée dans SQL Server 2016
Comme souvent avec la documentation de support, cela ne dit pas exactement ce qui a été modifié dans le moteur pour résoudre le problème. Cela ne semble certainement pas très pertinent pour nos préoccupations actuelles, à en juger par le titre et la description. Néanmoins, ce correctif introduit un nouvel indicateur de trace pris en charge 176 , qui est vérifié dans une méthode de code appelée FDontExpandPersistedCC . Comme le nom de la méthode l'indique, cela empêche l'expansion d'une colonne calculée persistante.
Il y a trois mises en garde importantes à cela :
- La colonne calculée doit être persistante . Même si elle est indexée, la colonne doit également être persistante.
- La correspondance entre les expressions de requête générales et les colonnes calculées persistantes est désactivée .
- La documentation ne décrit pas la fonction de l'indicateur de trace et ne le prescrit pour aucune autre utilisation. Si vous choisissez d'utiliser l'indicateur de trace 176 pour empêcher l'expansion des colonnes calculées persistantes, ce sera donc à vos risques et périls.
Cet indicateur de trace est efficace en tant que démarrage –T option, à la fois au niveau global et de la session à l'aide de DBCC TRACEON , et par requête avec OPTION (QUERYTRACEON) .
Exemple
Il s'agit d'une version simplifiée d'une question (basée sur un problème réel) à laquelle j'ai répondu sur Database Administrators Stack Exchange il y a quelques années. La définition de table inclut une colonne calculée persistante :
CREATE TABLE dbo.T( ID entier IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D date NULL, Calculé comme A + '-' + B + '-' + C PERSISTED, CONTRAINTE PK_T_ID PRIMARY KEY CLUSTERED (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.number % 10, 2 ), B =STR(SV.number % 20, 2), C =STR(SV.number % 30, 2), D =DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P';
La requête ci-dessous renvoie toutes les lignes de la table dans un ordre particulier, tout en renvoyant également la valeur suivante de la colonne D dans le même ordre :
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER BY T2.D ASC )FROM dbo.T AS T1ORDER BY T1.Computed, T1.D ;
Un index de couverture évident pour prendre en charge le classement final et les recherches dans la sous-requête est :
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Computed, D, ID);
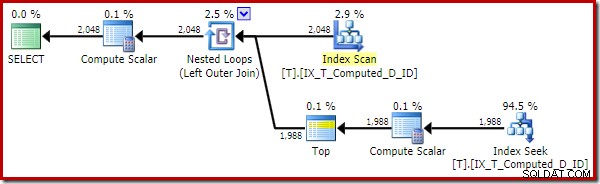
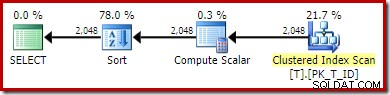
Le plan d'exécution délivré par l'optimiseur est surprenant et décevant :
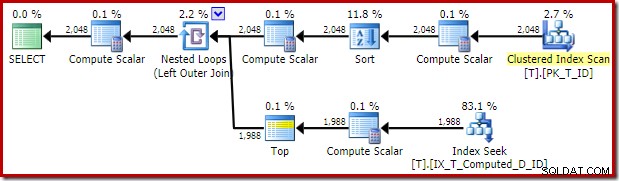
La recherche d'index sur le côté intérieur de la jointure de boucles imbriquées semble être bonne. Cependant, l'analyse et le tri de l'index clusterisé sur l'entrée externe sont inattendus. Nous aurions espéré voir une analyse ordonnée de notre index non clusterisé couvrant à la place.
Nous pouvons forcer l'optimiseur à utiliser l'index non-cluster avec un indicateur de table :
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER BY T2.D ASC )FROM dbo.T AS T1 WITH (INDEX(IX_T_Computed_D_ID)) -- Nouveau !ORDER BY T1.Computed, T1.D ;
Le plan d'exécution résultant est :
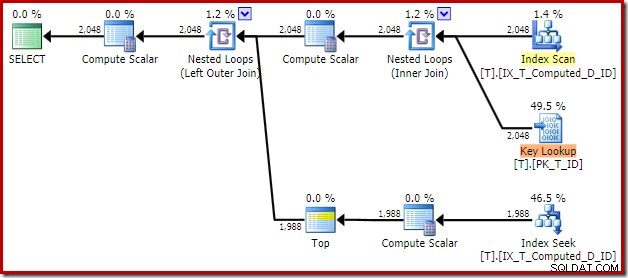
L'analyse de l'index non clusterisé supprime le tri, mais ajoute une recherche de clé ! Les recherches dans ce nouveau plan sont surprenantes, étant donné que notre index couvre définitivement toutes les colonnes nécessaires à la requête.
En regardant les propriétés de l'opérateur Key Lookup :
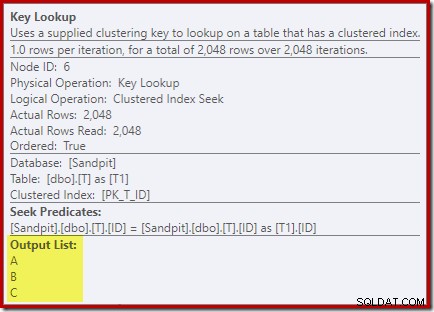
Pour une raison quelconque, l'optimiseur a décidé que trois colonnes non mentionnées dans la requête doivent être extraites de la table de base (puisqu'elles ne sont pas présentes dans notre index non clusterisé par conception).
En regardant autour du plan d'exécution, nous découvrons que les colonnes recherchées sont nécessaires au côté interne Index Seek :

La première partie de ce prédicat de recherche correspond à la corrélation T2.Computed = T1.Computed dans la requête d'origine. L'optimiseur a élargi les définitions des deux colonnes calculées, mais n'a réussi à faire correspondre qu'à la colonne calculée persistante et indexée pour l'alias côté interne T1 . Quitter le T2 référence étendue a entraîné le côté externe de la jointure devant fournir les colonnes de la table de base (A , B , et C ) nécessaire pour calculer cette expression pour chaque ligne.
Comme c'est parfois le cas, il est possible de réécrire cette requête afin que le problème disparaisse (une option est indiquée dans mon ancienne réponse à la question Stack Exchange). En utilisant SQL Server 2016, nous pouvons également essayer l'indicateur de trace 176 pour empêcher l'expansion des colonnes calculées :
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER PAR T2.D ASC ) DE dbo.T AS T1ORDER PAR T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Nouveau !
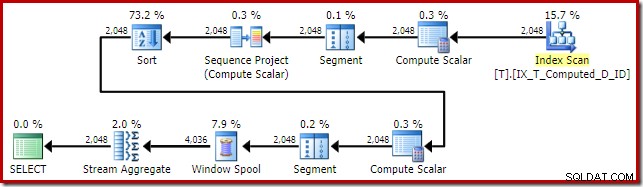
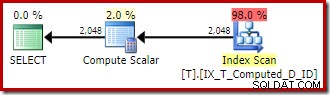
Le plan d'exécution est désormais bien amélioré :
Ce plan d'exécution contient uniquement des références aux colonnes calculées. Les scalaires de calcul ne font rien d'utile et seraient nettoyés si l'optimiseur était un peu plus ordonné dans la maison.
Le point important est que l'index optimal est maintenant utilisé correctement et que le tri et la recherche de clé ont été éliminés. Tout cela en empêchant SQL Server de faire quelque chose que nous ne nous serions jamais attendu à ce qu'il fasse en premier lieu (développer une colonne calculée persistante et indexée).
Utiliser LEAD
La question Stack Exchange d'origine était destinée à SQL Server 2008, où LEAD n'est pas disponible. Essayons d'exprimer l'exigence sur SQL Server 2016 en utilisant la nouvelle syntaxe :
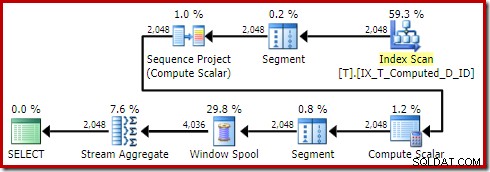
SELECT T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER (PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.Computed ;Le plan d'exécution de SQL Server 2016 est :
Cette forme de plan est tout à fait typique pour une simple fonction de fenêtre en mode ligne. Le seul élément inattendu est l'opérateur de tri au milieu. Si l'ensemble de données était volumineux, ce tri pourrait avoir un impact important sur les performances et l'utilisation de la mémoire.
Le problème, encore une fois, est l'expansion de colonne calculée. Dans ce cas, l'une des expressions étendues se trouve dans une position qui empêche la logique normale de l'optimiseur de simplifier le tri.
Essayer exactement la même requête avec l'indicateur de trace 176 :
SELECT T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER (PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );Produit le plan :
Le Sort a disparu comme il se doit. Notez également au passage que cette requête s'est qualifiée pour un plan trivial, évitant complètement l'optimisation basée sur les coûts.
Correspondance d'expression générale désactivée
L'une des mises en garde mentionnées précédemment était que l'indicateur de trace 176 désactive également la correspondance entre les expressions de la requête source et les colonnes calculées persistantes.
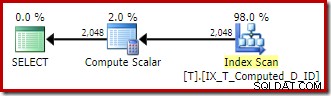
Pour illustrer, considérez la version suivante de l'exemple de requête. Le
LEADcalcul a été supprimé et les références à la colonne calculée dans leSELECTetORDER BYles clauses ont été remplacées par les expressions sous-jacentes. Exécutez-le d'abord sans l'indicateur de trace 176 :SELECT T1.ID, Calculé =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C ;Les expressions sont mises en correspondance avec la colonne calculée persistante et le plan d'exécution est une simple analyse ordonnée de l'index non cluster :
Le Compute Scalar n'est là encore qu'un reste de bric-à-brac architectural.
Essayez maintenant la même requête avec l'indicateur de trace 176 activé :
SELECT T1.ID, Calculé =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Nouveau !Le nouveau plan d'exécution est :
Le balayage d'index non clusterisé a été remplacé par un balayage d'index clusterisé. Le scalaire de calcul évalue l'expression et le tri trie en fonction du résultat. Privé de la possibilité de faire correspondre des expressions à des colonnes calculées persistantes, l'optimiseur ne peut pas utiliser la valeur persistante ou l'index non clusterisé.
Notez que la limitation de correspondance d'expression s'applique uniquement à persistant colonnes calculées lorsque l'indicateur de trace 176 est actif. Si nous rendons la colonne calculée indexée mais non persistante, la correspondance d'expression fonctionne correctement.
Afin de supprimer l'attribut persisted, nous devons d'abord supprimer l'index non clusterisé. Une fois le changement effectué on peut remettre l'index directement (car l'expression est déterministe et précise) :
DROP INDEX IX_T_Computed_D_ID ON dbo.T;GOALTER TABLE dbo.TALTER COLUMN ComputedDROP PERSISTED;GOCREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Calculé, D, ID);L'optimiseur n'a plus de problème pour faire correspondre l'expression de requête à la colonne calculée lorsque l'indicateur de trace 176 est actif :
-- La colonne calculée n'est plus persistante-- mais toujours indexée. TF 176 active.SELECT T1.ID, Calculé =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);Le plan d'exécution revient à l'analyse d'index non cluster optimale sans tri :
Pour résumer :l'indicateur de trace 176 empêche l'expansion persistante des colonnes calculées. En tant qu'effet secondaire, cela empêche également l'expression de la requête de correspondre uniquement aux colonnes calculées persistantes.
Les métadonnées du schéma ne sont chargées qu'une seule fois, lors de la phase de liaison. L'indicateur de trace 176 empêche l'expansion de sorte que la définition de colonne calculée n'est pas chargée à ce moment-là. La correspondance ultérieure entre expression et colonne ne peut pas fonctionner sans la définition de colonne calculée à comparer.
Le chargement initial des métadonnées apporte toutes les colonnes, pas seulement celles référencées dans la requête (cette optimisation est effectuée ultérieurement). Cela rend toutes les colonnes calculées disponibles pour la correspondance, ce qui est généralement une bonne chose. Malheureusement, si l'une des colonnes calculées chargées contient une fonction scalaire définie par l'utilisateur, sa présence désactive le parallélisme pour l'ensemble de la requête même lorsque la colonne problématique n'est pas utilisée. L'indicateur de trace 176 peut également aider à cela, si la colonne en question est persistante. En ne chargeant pas la définition, une fonction scalaire définie par l'utilisateur n'est jamais présente, donc le parallélisme n'est pas désactivé.
Réflexions finales
Il me semble que le monde SQL Server serait un meilleur endroit si l'optimiseur traitait les colonnes calculées persistantes ou indexées plus comme des colonnes régulières. Dans presque tous les cas, cela correspondrait mieux aux attentes des développeurs que l'arrangement actuel. Développer des colonnes calculées dans leurs expressions sous-jacentes et tenter plus tard de les faire correspondre n'est pas aussi efficace dans la pratique que la théorie pourrait le suggérer.
Jusqu'à ce que SQL Server fournisse une prise en charge spécifique pour empêcher l'expansion des colonnes calculées persistantes ou indexées, le nouvel indicateur de trace 176 est une option tentante pour les utilisateurs de SQL Server 2016, bien qu'imparfaite. Il est un peu regrettable qu'il désactive la correspondance d'expression générale comme effet secondaire. Il est également dommage que la colonne calculée doive être persistante lorsqu'elle est indexée. Il y a alors le risque d'utiliser un indicateur de trace pour autre chose que son objectif documenté à considérer.
Il est juste de dire que la majorité des problèmes liés aux requêtes de colonnes calculées peuvent finalement être résolus par d'autres moyens, avec suffisamment de temps, d'efforts et d'expertise. D'un autre côté, l'indicateur de trace 176 semble souvent fonctionner comme par magie. Le choix, comme on dit, vous appartient.
Pour finir, voici quelques problèmes de colonne calculés intéressants qui bénéficient de l'indicateur de trace 176 :
- Index de colonne calculé non utilisé
- Colonne calculée PERSISTED non utilisée dans le partitionnement de la fonction de fenêtrage
- Colonne calculée persistante provoquant l'analyse
- Index de colonne calculé non utilisé avec les types de données MAX
- Problème de performances grave avec des colonnes calculées persistantes et des jointures
- Pourquoi SQL Server "Compute Scalar" lorsque je SÉLECTIONNE une colonne calculée persistante ?
- Colonnes de base utilisées à la place de la colonne calculée persistante par moteur
- La colonne calculée avec UDF désactive le parallélisme pour les requêtes sur *d'autres* colonnes