Les requêtes/instructions/transactions de longue durée sont parfois inévitables dans un environnement MySQL. Dans certains cas, une requête de longue durée peut être le catalyseur d'un événement désastreux. Si vous vous souciez de votre base de données, l'optimisation des performances des requêtes et la détection des requêtes longues doivent être effectuées régulièrement. Les choses deviennent cependant plus difficiles lorsque plusieurs instances d'un groupe ou d'un cluster sont impliquées.
Lorsque vous traitez avec plusieurs nœuds, les tâches répétitives pour vérifier chaque nœud sont quelque chose que nous devons éviter. ClusterControl surveille plusieurs aspects de votre serveur de base de données, y compris les requêtes. ClusterControl regroupe toutes les informations relatives aux requêtes de tous les nœuds du groupe ou du cluster pour fournir une vue centralisée de la charge de travail. Il existe un excellent moyen de comprendre votre cluster dans son ensemble avec un minimum d'effort.
Dans cet article de blog, nous vous montrons comment détecter les requêtes MySQL de longue durée à l'aide de ClusterControl.
Pourquoi une requête prend plus de temps ?
Tout d'abord, nous devons connaître la nature de la requête, s'il s'agit d'une requête longue ou courte. Certaines opérations analytiques et par lots sont censées être des requêtes longues, nous pouvons donc les ignorer pour le moment. De plus, selon la taille de la table, la modification de la structure de la table avec la commande ALTER peut être une opération longue.
Pour une transaction de courte durée, elle doit être exécutée aussi rapidement que possible, généralement en moins d'une seconde. Le plus court sera le mieux. Cela s'accompagne d'un ensemble de règles de bonnes pratiques de requête que les utilisateurs doivent suivre, telles que l'utilisation d'une indexation appropriée dans l'instruction WHERE ou JOIN, l'utilisation du bon moteur de stockage, la sélection des types de données appropriés, la planification de l'opération par lots pendant les heures creuses, le déchargement analytique /signalement du trafic vers des réplicas dédiés, etc.
Il y a un certain nombre de choses qui peuvent faire en sorte qu'une requête prenne plus de temps à s'exécuter :
- Requête inefficace :utilisez des colonnes non indexées lors de la recherche ou de la jointure. MySQL prend donc plus de temps pour répondre à la condition.
- Verrou de table :la table est verrouillée, par un verrou global ou un verrou de table explicite lorsque la requête tente d'y accéder.
- Deadlock - Une requête attend pour accéder aux mêmes lignes qui sont verrouillées par une autre requête.
- L'ensemble de données ne tient pas dans la RAM :si les données de votre ensemble de travail tiennent dans ce cache, les requêtes SELECT seront généralement relativement rapides.
- Ressources matérielles sous-optimales :il peut s'agir de disques lents, d'une reconstruction RAID, d'un réseau saturé, etc.
- Opération de maintenance :l'exécution de mysqldump peut amener d'énormes quantités de données autrement inutilisées dans le pool de mémoire tampon, et en même temps, les données (potentiellement utiles) qui s'y trouvent déjà seront expulsées et vidées sur le disque.
La liste ci-dessus souligne que ce n'est pas seulement la requête elle-même qui cause toutes sortes de problèmes. Il existe de nombreuses raisons qui nécessitent d'examiner différents aspects d'un serveur MySQL. Dans le pire des cas, une requête de longue durée peut entraîner une interruption totale du service, telle qu'une panne de serveur, une panne de serveur et des connexions maximales. Si vous constatez qu'une requête prend plus de temps que d'habitude à s'exécuter, examinez-la.
Comment vérifier ?
LISTE DE PROCESSUS
MySQL fournit un certain nombre d'outils intégrés pour vérifier la transaction de longue durée. Tout d'abord, les commandes SHOW PROCESSLIST ou SHOW FULL PROCESSLIST peuvent exposer les requêtes en cours d'exécution en temps réel. Voici une capture d'écran de la fonctionnalité ClusterControl Running Queries, similaire à la commande SHOW FULL PROCESSLIST (mais ClusterControl regroupe tous les processus en une seule vue pour tous les nœuds du cluster) :
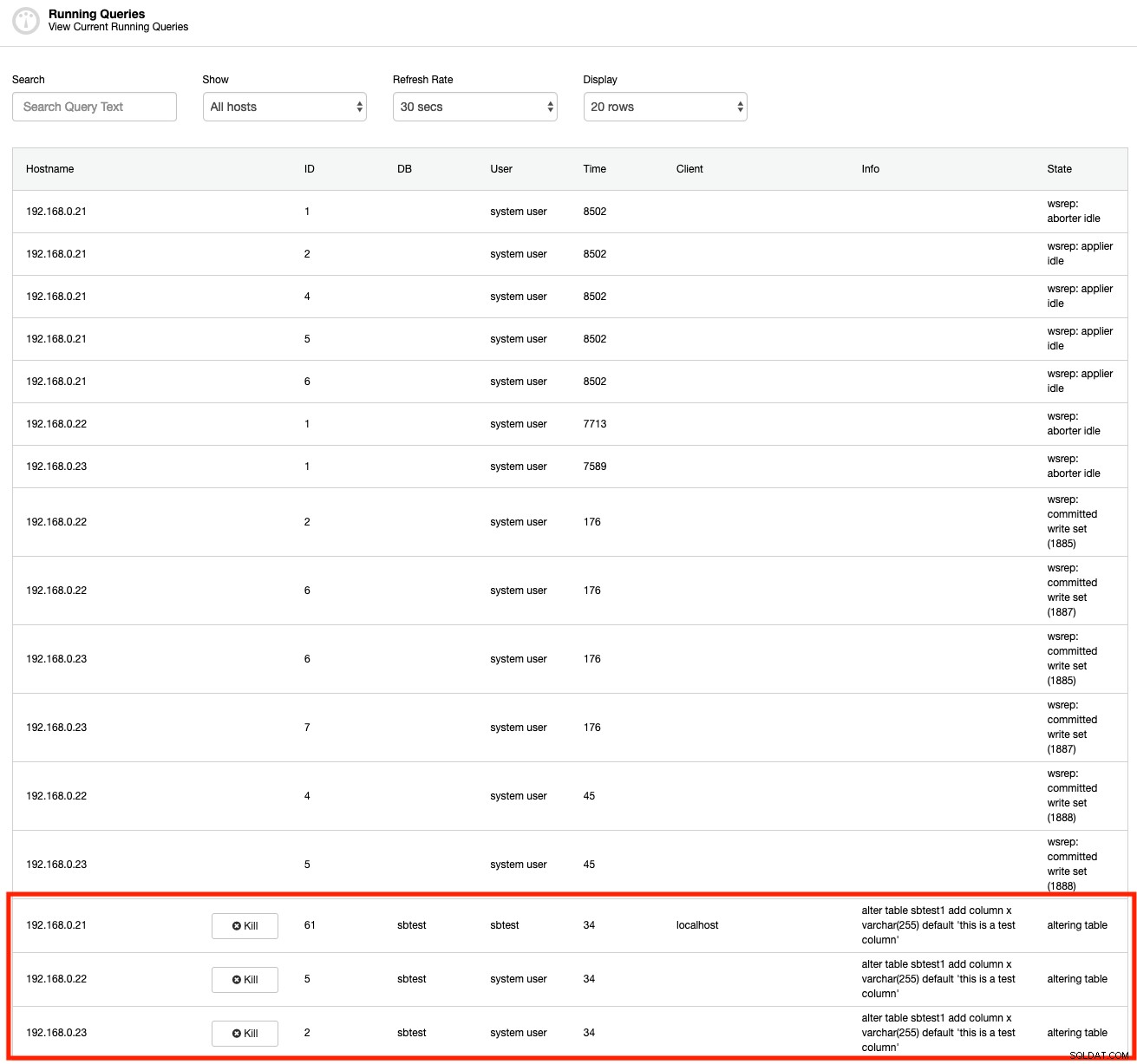
Comme vous pouvez le voir, nous pouvons immédiatement voir la requête offensante dès la sortie. Mais à quelle fréquence regardons-nous ces processus ? Ceci n'est utile que si vous êtes conscient de la longue durée de la transaction. Sinon, vous ne le sauriez pas jusqu'à ce que quelque chose se produise - comme les connexions s'accumulent ou le serveur devient plus lent que d'habitude.
Journal des requêtes lentes
Le journal des requêtes lentes capture les requêtes lentes (instructions SQL qui prennent plus de long_query_time secondes à exécuter), ou des requêtes qui n'utilisent pas d'index pour les recherches (log_queries_not_using_indexes ). Cette fonctionnalité n'est pas activée par défaut et pour l'activer, définissez simplement les lignes suivantes et redémarrez le serveur MySQL :
[mysqld]
slow_query_log=1
long_query_time=0.1
log_queries_not_using_indexes=1Le journal des requêtes lentes peut être utilisé pour rechercher des requêtes qui prennent beaucoup de temps à s'exécuter et qui sont donc candidates à l'optimisation. Cependant, l'examen d'un journal de requêtes long et lent peut être une tâche fastidieuse. Il existe des outils pour analyser les fichiers journaux des requêtes lentes de MySQL et résumer leur contenu comme mysqldumpslow, pt-query-digest ou ClusterControl Top Queries.
ClusterControl Top Queries résume la requête lente à l'aide de deux méthodes :le journal des requêtes lentes MySQL ou le schéma de performances :
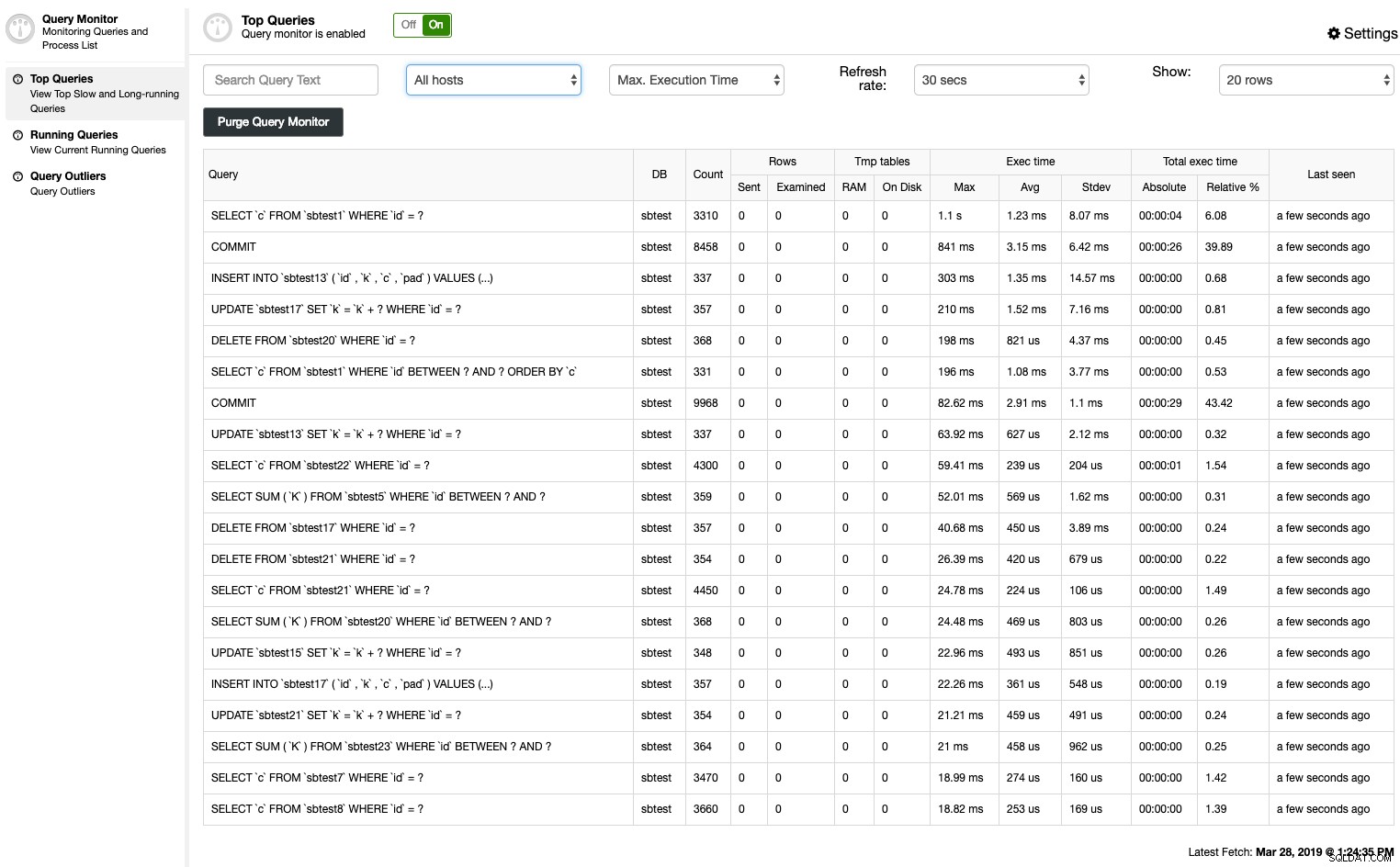
Vous pouvez facilement voir un résumé des résumés de relevés normalisés, triés en fonction d'un certain nombre de critères :
- Hébergeur
- Occurrences
- Durée totale d'exécution
- Durée d'exécution maximale
- Délai d'exécution moyen
- Temps d'écart type
Nous avons couvert cette fonctionnalité en détail dans cet article de blog, Comment utiliser le moniteur de requêtes ClusterControl pour MySQL, MariaDB et Percona Server.
Schéma de performances
Performance Schema est un excellent outil disponible pour surveiller les composants internes du serveur MySQL et les détails d'exécution à un niveau inférieur. Les tableaux suivants dans Performance Schema peuvent être utilisés pour rechercher des requêtes lentes :
- events_statements_current
- events_statements_history
- events_statements_history_long
- events_statements_summary_by_digest
- events_statements_summary_by_user_by_event_name
- events_statements_summary_by_host_by_event_name
MySQL 5.7.7 et supérieur inclut le schéma sys, un ensemble d'objets qui aide les DBA et les développeurs à interpréter les données collectées par le schéma de performances sous une forme plus facilement compréhensible. Les objets de schéma Sys peuvent être utilisés pour des cas d'utilisation typiques de réglage et de diagnostic.
ClusterControl fournit des conseillers, qui sont des mini-programmes que vous pouvez écrire à l'aide de ClusterControl DSL (similaire à JavaScript) pour étendre les capacités de surveillance de ClusterControl personnalisées selon vos besoins. Il existe un certain nombre de scripts inclus basés sur le schéma de performances que vous pouvez utiliser pour surveiller les performances des requêtes telles que l'attente d'E/S, le temps d'attente de verrouillage, etc. Par exemple sous Gérer -> Developer Studio , allez dans s9s -> mysql -> p_s -> top_tables_by_iowait.js et cliquez sur le bouton "Compiler et exécuter". Vous devriez voir la sortie sous l'onglet Messages pour les 10 premières tables triées par attente d'E/S par serveur :
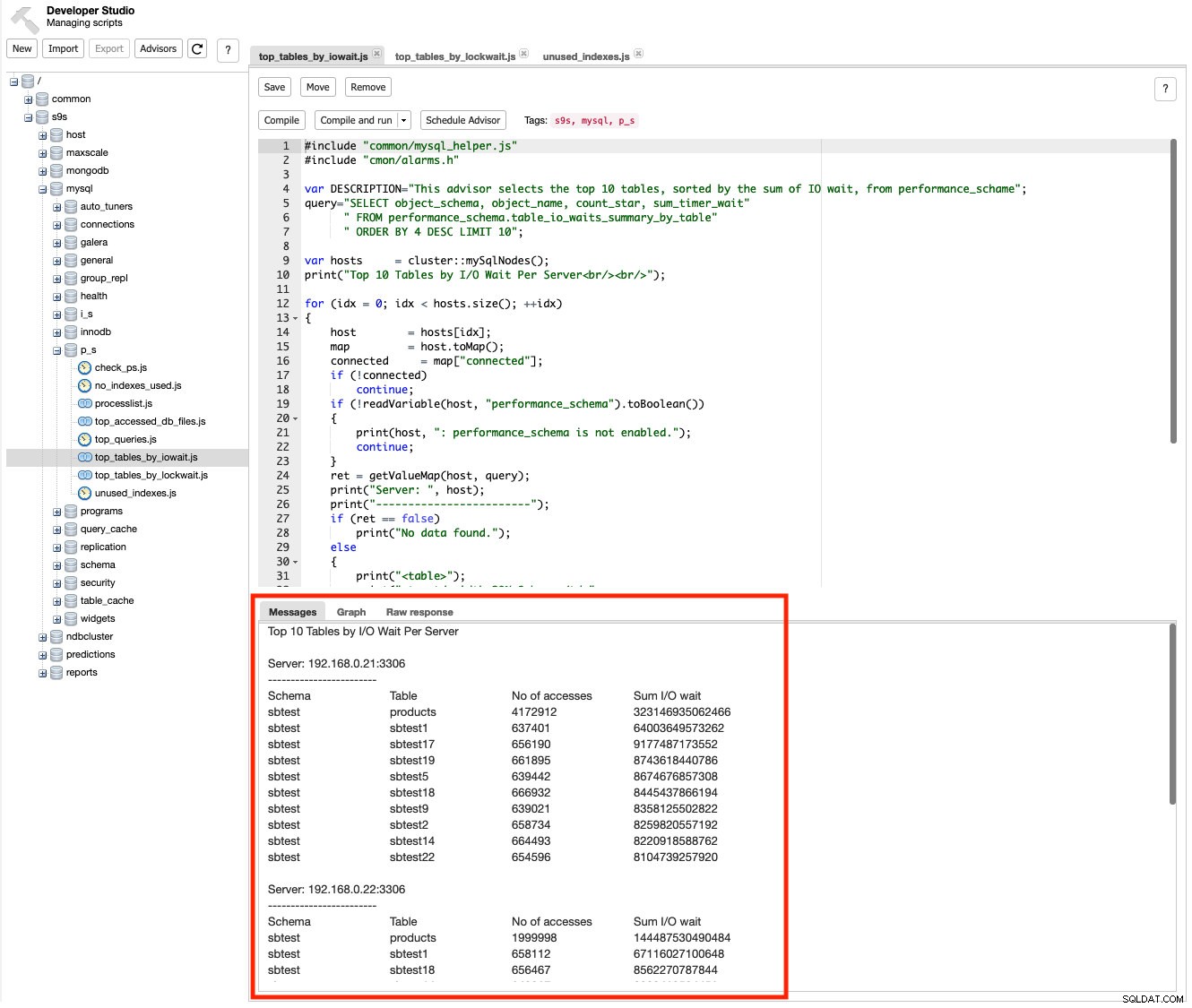
Il existe un certain nombre de scripts que vous pouvez utiliser pour comprendre les informations de bas niveau où et pourquoi la lenteur se produit, comme top_tables_by_lockwait.js , top_accessed_db_files.js et ainsi de suite.
ClusterControl - Détection et alerte en cas de requêtes longues
Avec ClusterControl, vous obtiendrez des fonctionnalités puissantes supplémentaires que vous ne trouverez pas dans l'installation standard de MySQL. ClusterControl peut être configuré pour surveiller de manière proactive les processus en cours d'exécution, déclencher une alarme et envoyer une notification à l'utilisateur si le seuil de requête longue est dépassé. Cela peut être configuré en utilisant la configuration d'exécution sous Paramètres :
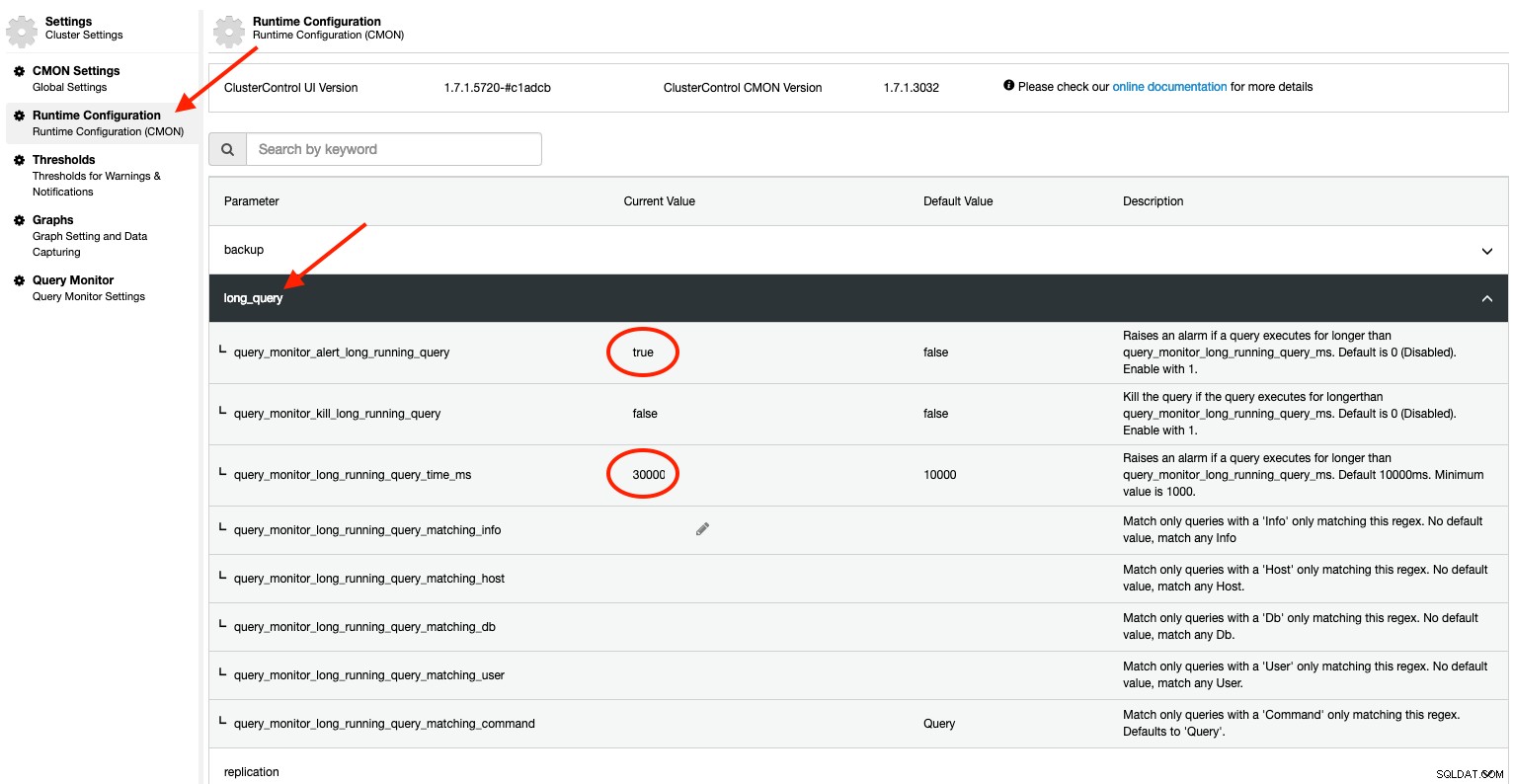
Pour pre1.7.1, la valeur par défaut pour query_monitor_alert_long_running_query c'est faux. Nous encourageons l'utilisateur à l'activer en le définissant sur 1 (vrai). Pour le rendre persistant, ajoutez la ligne suivante dans /etc/cmon.d/cmon_X.cnf :
query_monitor_alert_long_running_query=1
query_monitor_long_running_query_ms=30000Toute modification apportée à la configuration d'exécution est appliquée immédiatement et aucun redémarrage n'est nécessaire. Vous verrez quelque chose comme ceci dans la section Alarmes si une requête dépasse les seuils de 30 000 ms (30 secondes) :
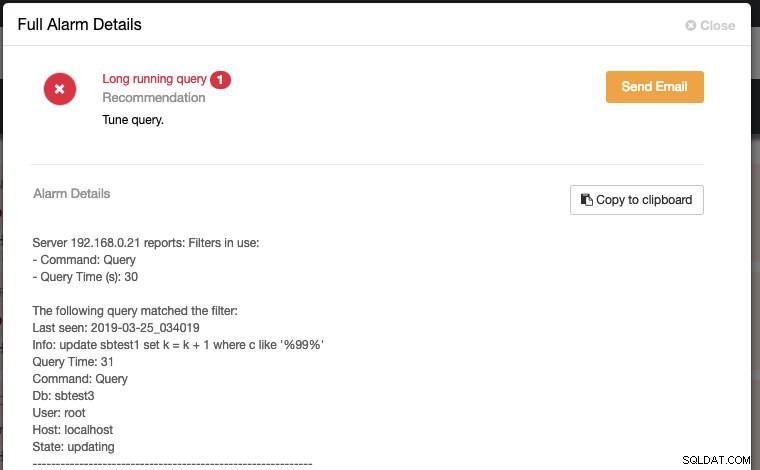
Si vous configurez les paramètres du destinataire du courrier sur "Deliver" pour la catégorie de gravité DbComponent plus CRITICAL (comme indiqué dans la capture d'écran suivante) :
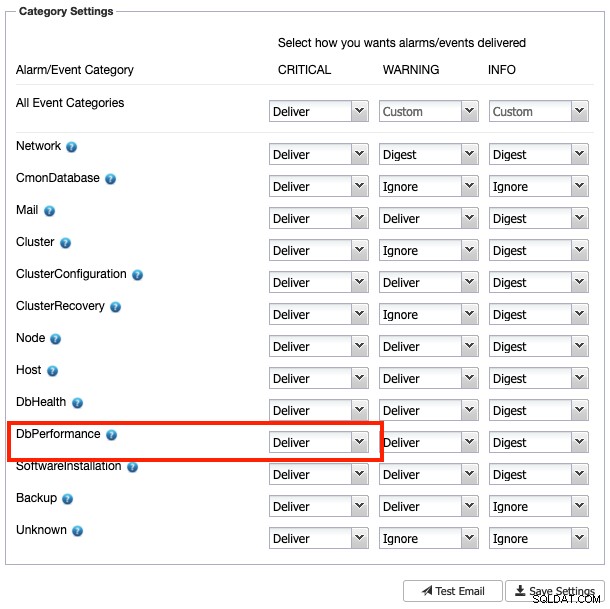
Vous devriez recevoir une copie de cette alarme dans votre e-mail. Sinon, il peut être transféré manuellement en cliquant sur le bouton "Envoyer un e-mail".
De plus, vous pouvez filtrer tout type de ressources de liste de processus correspondant à certains critères avec une expression régulière (regex). Par exemple, si vous souhaitez que ClusterControl détecte une requête de longue durée pour trois utilisateurs MySQL appelés "sbtest", "myshop" et "db_user1", procédez comme suit :
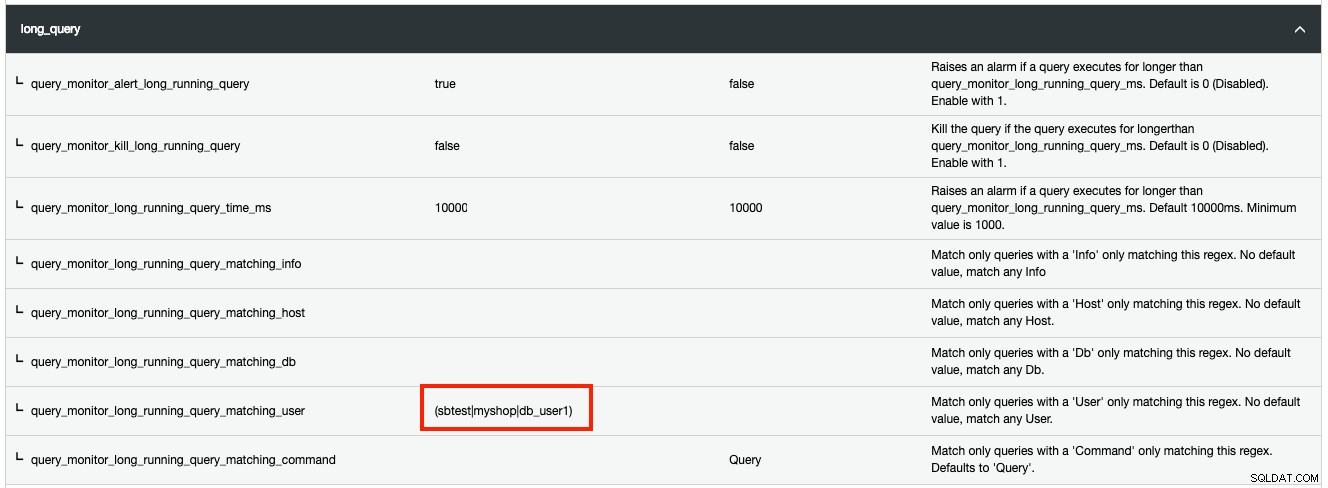
Toute modification apportée à la configuration d'exécution est appliquée immédiatement et aucun redémarrage n'est nécessaire.
De plus, ClusterControl répertoriera toutes les transactions de blocage avec le statut InnoDB lorsqu'il se produisait sous Performance -> Transaction Log :
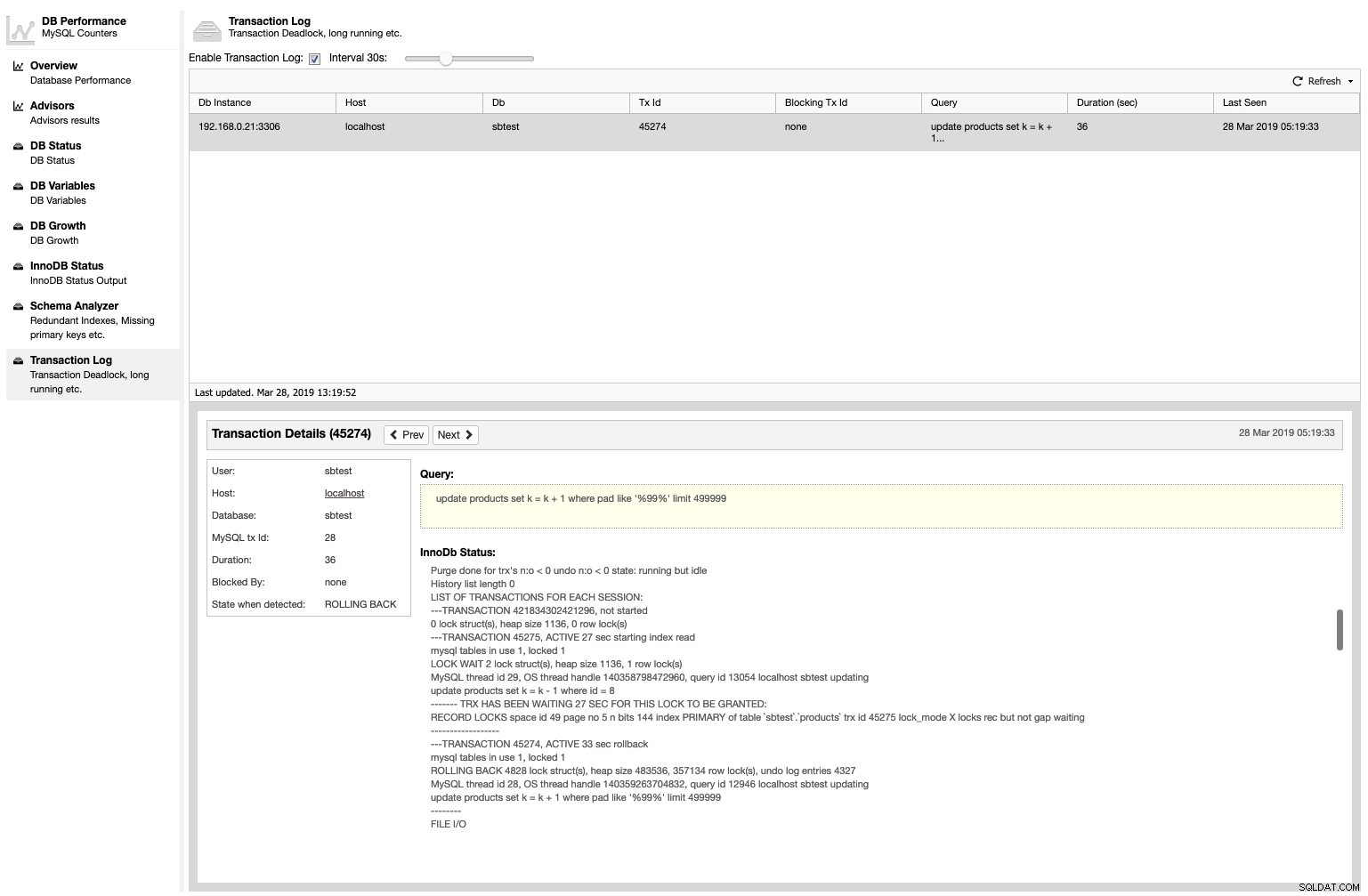
Cette fonctionnalité n'est pas activée par défaut, car la détection de blocage affectera l'utilisation du processeur sur les nœuds de la base de données. Pour l'activer, cochez simplement la case "Activer le journal des transactions" et spécifiez l'intervalle que vous souhaitez. Pour le rendre persistant, ajoutez une variable avec une valeur en secondes dans /etc/cmon.d/cmon_X.cnf :
db_deadlock_check_interval=30De même, si vous voulez vérifier le statut InnoDB, allez simplement dans Performance -> InnoDB Status , et choisissez le serveur MySQL dans la liste déroulante. Par exemple :
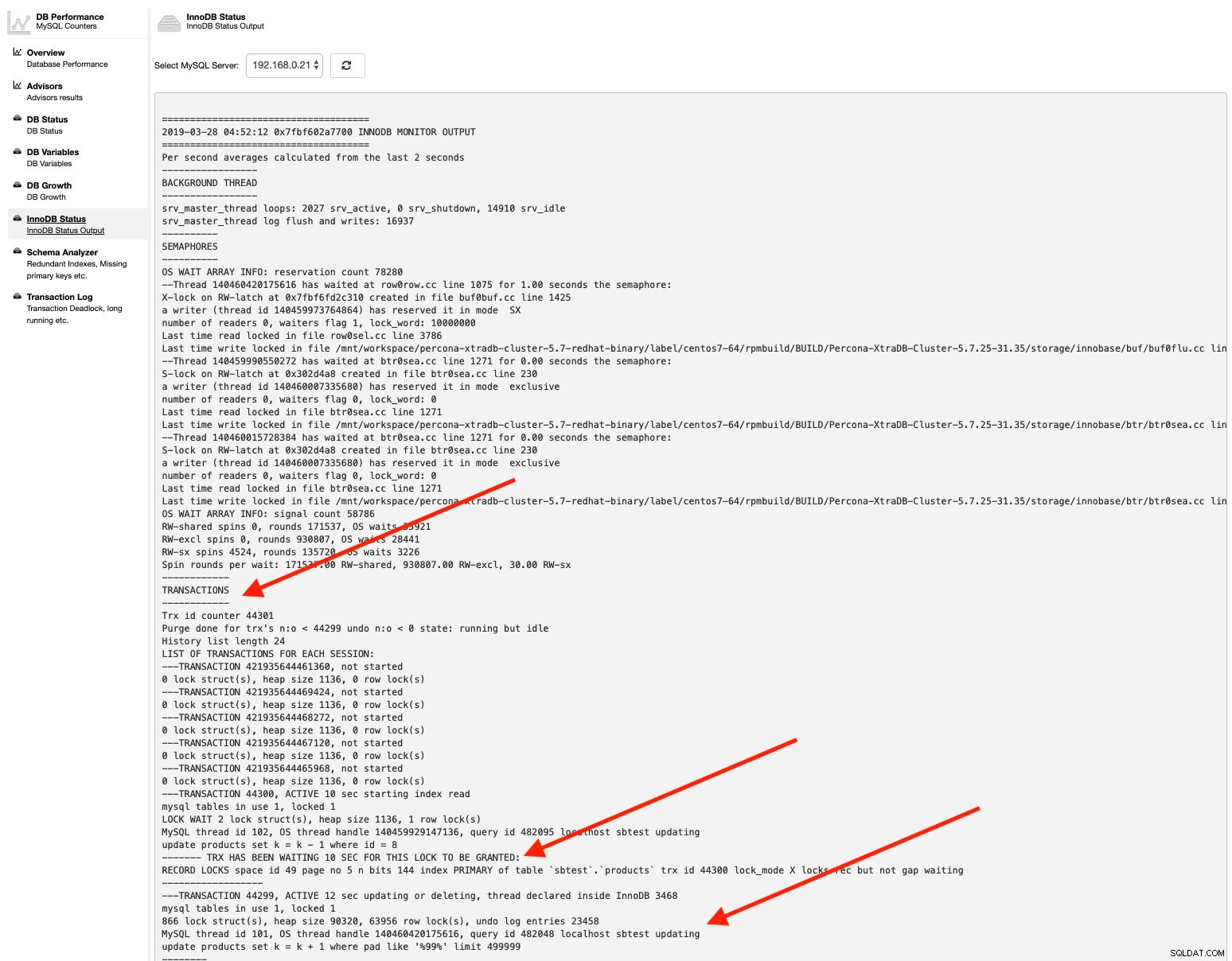
Et voilà, toutes les informations requises sont facilement récupérables en quelques clics.
Résumé
Les transactions de longue durée peuvent entraîner une dégradation des performances, une panne de serveur, des connexions maximisées et des blocages. Avec ClusterControl, vous pouvez détecter les requêtes longues directement à partir de l'interface utilisateur, sans avoir à examiner chaque nœud MySQL du cluster.