La haute disponibilité correspond à un pourcentage élevé de temps pendant lequel le système fonctionne et répond en fonction des besoins de l'entreprise. Pour les systèmes de base de données de production, la priorité la plus élevée est généralement de la maintenir proche de 100 %. Nous construisons des clusters de bases de données pour éliminer tout point de défaillance unique. Si une instance devient indisponible, un autre nœud doit pouvoir prendre la charge de travail et continuer à partir de là. Dans un monde parfait, un cluster de bases de données résoudrait tous nos problèmes de disponibilité du système. Malheureusement, alors que tout peut sembler bon sur le papier, la réalité est souvent différente. Alors, où cela peut-il mal tourner ?
Les systèmes de bases de données transactionnelles sont livrés avec des moteurs de stockage sophistiqués. Le maintien de la cohérence des données sur plusieurs nœuds rend cette tâche beaucoup plus difficile. Le clustering introduit un certain nombre de nouvelles variables qui dépendent fortement du réseau et de l'infrastructure sous-jacente. Il n'est pas rare qu'une instance de base de données autonome qui fonctionnait correctement sur un seul nœud fonctionne soudainement mal dans un environnement de cluster.
Parmi le nombre de choses qui peuvent affecter la disponibilité du cluster, les problèmes de latence jouent un rôle crucial. Mais quelle est la latence ? Est-ce uniquement lié au réseau ?
Le terme "latence" désigne en fait plusieurs types de retards encourus dans le traitement des données. C'est le temps qu'il faut pour qu'une information passe d'une étape à une autre.
Dans cet article de blog, nous examinerons les deux principales solutions de haute disponibilité pour MySQL et MariaDB, et comment elles peuvent chacune être affectées par des problèmes de latence.
À la fin de l'article, nous examinons les équilibreurs de charge modernes et expliquons comment ils peuvent vous aider à résoudre certains types de problèmes de latence.
Dans un article précédent, mon collègue Krzysztof Książek a écrit sur "Traitement des réseaux non fiables lors de l'élaboration d'une solution HA pour MySQL ou MariaDB". Vous trouverez des conseils qui peuvent vous aider à concevoir votre architecture HA prête pour la production et à éviter certains des problèmes décrits ici.
Réplication maître-esclave pour une haute disponibilité.
La réplication maître-esclave MySQL est probablement le type de cluster de base de données le plus populaire sur la planète. L'une des principales choses que vous souhaitez surveiller lors de l'exécution de votre cluster de réplication maître-esclave est le décalage de l'esclave. En fonction des exigences de votre application et de la manière dont vous utilisez votre base de données, la latence de réplication (décalage esclave) peut déterminer si les données peuvent être lues à partir du nœud esclave ou non. Les données validées sur le maître mais pas encore disponibles sur un esclave asynchrone signifient que l'esclave a un état plus ancien. Lorsqu'il n'est pas acceptable de lire à partir d'un esclave, vous devez vous rendre sur le maître, ce qui peut affecter les performances de l'application. Dans le pire des cas, votre système ne pourra pas gérer toute la charge de travail sur un maître.
Lag esclave et données obsolètes
Pour vérifier l'état de la réplication maître-esclave, vous devez commencer par la commande ci-dessous :
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)À l'aide des informations ci-dessus, vous pouvez déterminer la qualité de la latence de réplication globale. Plus la valeur que vous voyez dans "Seconds_Behind_Master" est faible, meilleure est la vitesse de transfert des données pour la réplication.
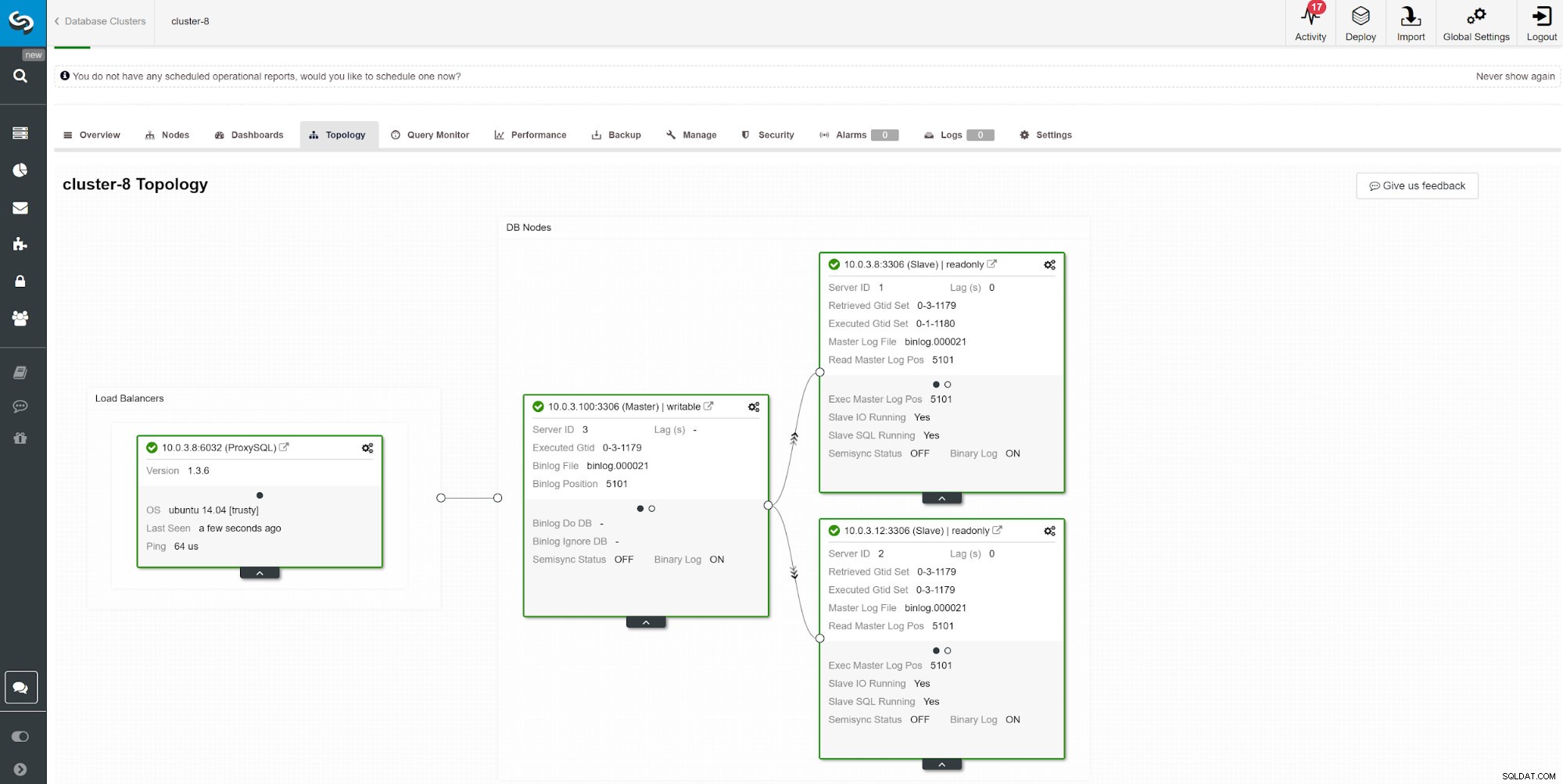 Une autre façon de surveiller le décalage de l'esclave consiste à utiliser la surveillance de la réplication ClusterControl. Dans cette capture d'écran, nous pouvons voir l'état de réplication du cluster asymchoronous Master-Slave (2x) avec ProxySQL.
Une autre façon de surveiller le décalage de l'esclave consiste à utiliser la surveillance de la réplication ClusterControl. Dans cette capture d'écran, nous pouvons voir l'état de réplication du cluster asymchoronous Master-Slave (2x) avec ProxySQL. Il y a un certain nombre de choses qui peuvent affecter le temps de réplication. Le plus évident est le débit du réseau et la quantité de données que vous pouvez transférer. MySQL est livré avec plusieurs options de configuration pour optimiser le processus de réplication. Les paramètres essentiels liés à la réplication sont :
- Application parallèle
- Algorithme d'horloge logique
- Compression
- Réplication maître-esclave sélective
- Mode de réplication
Application parallèle
Il n'est pas rare de commencer le réglage de la réplication en activant l'application du processus parallèle. La raison en est que, par défaut, MySQL utilise un journal binaire séquentiel, et un serveur de base de données typique est livré avec plusieurs processeurs à utiliser.
Pour contourner l'application de journal séquentiel, MariaDB et MySQL proposent une réplication parallèle. L'implémentation peut différer selon le fournisseur et la version. Par exemple. MySQL 5.6 offre une réplication parallèle tant qu'un schéma sépare les requêtes, tandis que MariaDB (à partir de la version 10.0) et MySQL 5.7 peuvent gérer la réplication parallèle entre les schémas. Différents fournisseurs et versions sont livrés avec leurs limitations et leurs fonctionnalités, alors vérifiez toujours la documentation.
L'exécution de requêtes via des threads esclaves parallèles peut accélérer votre flux de réplication si vous écrivez beaucoup. Cependant, si ce n'est pas le cas, il serait préférable de s'en tenir à la réplication traditionnelle à un seul thread. Pour activer le traitement parallèle, remplacez slave_parallel_workers par le nombre de threads CPU que vous souhaitez impliquer dans le processus. Il est recommandé de conserver la valeur inférieure du nombre de threads CPU disponibles.
La réplication parallèle fonctionne mieux avec les commits de groupe. Pour vérifier si vous avez des validations de groupe, exécutez la requête suivante.
show global status like 'binlog_%commits';Plus le rapport entre ces deux valeurs est grand, mieux c'est.
Horloge logique
Le slave_parallel_type=LOGICAL_CLOCK est une implémentation d'un algorithme d'horloge Lamport. Lors de l'utilisation d'un esclave multithread, cette variable spécifie la méthode utilisée pour décider quelles transactions sont autorisées à s'exécuter en parallèle sur l'esclave. La variable n'a aucun effet sur les esclaves pour lesquels le multithreading n'est pas activé, assurez-vous donc que slave_parallel_workers est supérieur à 0.
Les utilisateurs de MariaDB doivent également vérifier le mode optimiste introduit dans la version 10.1.3 car il peut également vous donner de meilleurs résultats.
GTID
MariaDB est livré avec sa propre implémentation de GTID. La séquence de MariaDB se compose d'un domaine, d'un serveur et d'une transaction. Les domaines permettent une réplication multisource avec un ID distinct. Différents ID de domaine peuvent être utilisés pour répliquer la partie des données dans le désordre (en parallèle). Tant que cela convient à votre application, cela peut réduire la latence de réplication.
La technique similaire s'applique à MySQL 5.7 qui peut également utiliser le maître multisource et les canaux de réplication indépendants.
Compression
La puissance du processeur devient moins chère au fil du temps, donc l'utiliser pour la compression binlog pourrait être une bonne option pour de nombreux environnements de base de données. Le paramètre slave_compressed_protocol indique à MySQL d'utiliser la compression si le maître et l'esclave la prennent en charge. Par défaut, ce paramètre est désactivé.
À partir de MariaDB 10.2.3, les événements sélectionnés dans le journal binaire peuvent éventuellement être compressés, pour enregistrer les transferts réseau.
Formats de réplication
MySQL propose plusieurs modes de réplication. Choisir le bon format de réplication permet de minimiser le temps de transmission des données entre les nœuds du cluster.
Réplication multimaître pour une haute disponibilité
Certaines applications ne peuvent pas se permettre de fonctionner sur des données obsolètes.
Dans de tels cas, vous souhaiterez peut-être appliquer la cohérence entre les nœuds avec la réplication synchrone. Garder les données synchrones nécessite un plugin supplémentaire, et pour certains, la meilleure solution sur le marché pour cela est Galera Cluster.
Le cluster Galera est livré avec l'API wsrep qui est responsable de la transmission des transactions à tous les nœuds et de leur exécution selon un ordre à l'échelle du cluster. Cela bloquera l'exécution des requêtes suivantes jusqu'à ce que le nœud ait appliqué tous les jeux d'écriture de sa file d'attente d'application. Bien que ce soit une bonne solution pour la cohérence, vous pouvez rencontrer certaines limitations architecturales. Les problèmes de latence courants peuvent être liés à :
- Le nœud le plus lent du cluster
- Mise à l'échelle horizontale et opérations d'écriture
- Clusters géolocalisés
- Ping élevé
- Taille de la transaction
Le nœud le plus lent du cluster
De par leur conception, les performances d'écriture du cluster ne peuvent pas être supérieures aux performances du nœud le plus lent du cluster. Commencez l'examen de votre cluster en vérifiant les ressources de la machine et vérifiez les fichiers de configuration pour vous assurer qu'ils s'exécutent tous avec les mêmes paramètres de performances.
Parallélisation
Les threads parallèles ne garantissent pas de meilleures performances, mais ils peuvent accélérer la synchronisation des nouveaux nœuds avec le cluster. Le statut wsrep_cert_deps_distance nous indique le degré de parallélisation possible. C'est la valeur de la distance moyenne entre les valeurs de seqno les plus hautes et les plus basses qui peuvent être éventuellement appliquées en parallèle. Vous pouvez utiliser la variable d'état wsrep_cert_deps_distance pour déterminer le nombre maximal de threads esclaves possibles.
Mise à l'échelle horizontale
En ajoutant plus de nœuds dans le cluster, nous avons moins de points susceptibles d'échouer ; cependant, les informations doivent traverser plusieurs instances jusqu'à ce qu'elles soient validées, ce qui multiplie les temps de réponse. Si vous avez besoin d'écritures évolutives, envisagez une architecture basée sur le sharding. Une bonne solution peut être un moteur de stockage Spider.
Dans certains cas, pour réduire le partage d'informations entre les nœuds du cluster, vous pouvez envisager d'avoir un enregistreur à la fois. Il est relativement facile à mettre en œuvre lors de l'utilisation d'un équilibreur de charge. Lorsque vous effectuez cette opération manuellement, assurez-vous d'avoir une procédure pour modifier la valeur DNS lorsque votre nœud d'écriture tombe en panne.
Clusters géolocalisés
Bien que Galera Cluster soit synchrone, il est possible de déployer un Galera Cluster dans des centres de données. La réplication synchrone comme MySQL Cluster (NDB) implémente une validation en deux phases, où les messages sont envoyés à tous les nœuds d'un cluster dans une phase de « préparation », et un autre ensemble de messages est envoyé dans une phase de « validation ». Cette approche n'est généralement pas adaptée aux nœuds géographiquement disparates, en raison des latences dans l'envoi des messages entre les nœuds.
Ping élevé
Galera Cluster avec les paramètres par défaut ne gère pas bien la latence réseau élevée. Si vous avez un réseau avec un nœud qui affiche un temps de ping élevé, envisagez de modifier les paramètres evs.send_window et evs.user_send_window. Ces variables définissent le nombre maximal de paquets de données en réplication à la fois. Pour les configurations WAN, la variable peut être définie sur une valeur considérablement plus élevée que la valeur par défaut de 2. Il est courant de la définir sur 512. Ces paramètres font partie de wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Taille des transactions
L'une des choses que vous devez prendre en compte lors de l'exécution de Galera Cluster est la taille de la transaction. Trouver l'équilibre entre la taille de la transaction, les performances et le processus de certification Galera est quelque chose que vous devez estimer dans votre application. Vous pouvez trouver plus d'informations à ce sujet dans l'article How to Improve Performance of Galera Cluster for MySQL or MariaDB by Ashraf Sharif.
Lectures de cohérence causale de l'équilibreur de charge
Même avec le risque minimisé de problèmes de latence des données, la réplication asynchrone MySQL standard ne peut pas garantir la cohérence. Il est toujours possible que les données ne soient pas encore répliquées sur l'esclave pendant que votre application les lit à partir de là. La réplication synchrone peut résoudre ce problème, mais elle présente des limites d'architecture et peut ne pas répondre aux exigences de votre application (par exemple, des écritures en bloc intensives). Alors, comment le surmonter ?
La première étape pour éviter la lecture de données obsolètes consiste à informer l'application du délai de réplication. Il est généralement programmé dans le code de l'application. Heureusement, il existe des équilibreurs de charge de base de données modernes prenant en charge le routage adaptatif des requêtes basé sur le suivi GTID. Les plus populaires sont ProxySQL et Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader permet à ProxySQL de savoir en temps réel quel GTID a été exécuté sur chaque serveur MySQL, les esclaves et le maître lui-même. Grâce à cela, lorsqu'un client exécute une lecture qui doit fournir des lectures de cohérence causale, ProxySQL sait immédiatement sur quel serveur la requête peut être exécutée. Si, pour une raison quelconque, les écritures n'ont pas encore été exécutées sur un esclave, ProxySQL saura que l'écrivain a été exécuté sur le maître et y enverra la lecture.
Échelle maximale 2.3
MariaDB a introduit les lectures occasionnelles dans Maxscale 2.3.0. La façon dont cela fonctionne est similaire à ProxySQL 2.0. Fondamentalement, lorsque causal_reads est activé, toutes les lectures ultérieures effectuées sur les serveurs esclaves seront effectuées de manière à empêcher le retard de réplication d'affecter les résultats. Si l'esclave n'a pas rattrapé le maître dans le temps configuré, la requête sera réessayée sur le maître.