Pourquoi choisir la réplication MySQL ?
Quelques notions de base sur la technologie de réplication. La réplication MySQL n'est pas compliquée ! Il est facile à mettre en œuvre, à surveiller et à régler car il existe diverses ressources que vous pouvez exploiter, Google en étant une. MySQL Replication ne contient pas beaucoup de variables de configuration à régler. Les erreurs logiques de SQL_THREAD et IO_THREAD ne sont pas si difficiles à comprendre et à corriger. La réplication MySQL est très populaire de nos jours et offre un moyen simple de mettre en œuvre la haute disponibilité des bases de données. Des fonctionnalités puissantes telles que GTID (Global Transaction Identifier) au lieu de la position de journal binaire à l'ancienne, ou la réplication semi-synchrone sans perte le rendent plus robuste.
Comme nous l'avons vu dans un article précédent, la latence du réseau est un défi de taille lors du choix d'une solution à haute disponibilité. L'utilisation de MySQL Replication offre l'avantage de ne pas être aussi sensible à la latence. Il n'implémente aucune réplication basée sur la certification, contrairement à Galera Cluster qui utilise des techniques de communication de groupe et de commande de transactions pour réaliser une réplication synchrone. Ainsi, il n'est pas nécessaire que tous les nœuds certifient un ensemble d'écritures, et il n'est pas nécessaire d'attendre avant une validation sur l'autre esclave ou réplique.
Le choix de la réplication MySQL traditionnelle avec une approche primaire-secondaire asynchrone vous permet d'accélérer la gestion des transactions depuis votre maître ; il n'a pas besoin d'attendre que les esclaves se synchronisent ou valident les transactions. La configuration comporte généralement un primaire (maître) et un ou plusieurs secondaires (esclaves). Par conséquent, il s'agit d'un système sans partage, où tous les serveurs ont une copie complète des données par défaut. Bien sûr, il y a des inconvénients. L'intégrité des données peut être un problème si vos esclaves ne se sont pas répliqués en raison d'erreurs SQL et de thread d'E/S, ou de plantages. Alternativement, pour résoudre les problèmes d'intégrité des données, vous pouvez choisir d'implémenter la réplication MySQL semi-synchrone (ou appelée réplication semi-synchrone sans perte dans MySQL 5.7). Comment cela fonctionne est que le maître doit attendre qu'une réplique reconnaisse tous les événements de la transaction. Cela signifie qu'il doit terminer ses écritures dans un journal de relais et le vider sur le disque avant de renvoyer au maître une réponse ACK. Lorsque la réplication semi-synchrone est activée, les threads ou les sessions du maître doivent attendre l'accusé de réception d'une réplique. Une fois qu'il reçoit une réponse ACK de la réplique, il peut alors valider la transaction. L'illustration ci-dessous montre comment MySQL gère la réplication semi-synchrone.
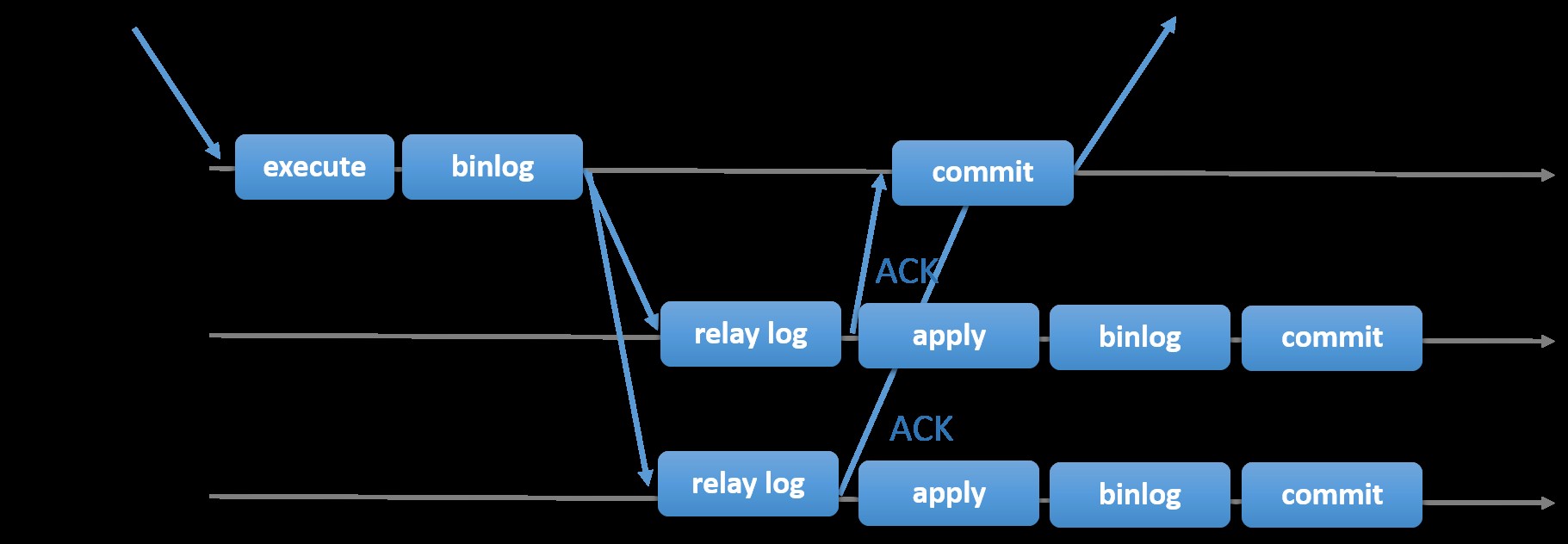 Image reproduite avec l'aimable autorisation de la documentation MySQL
Image reproduite avec l'aimable autorisation de la documentation MySQL Avec cette implémentation, toutes les transactions validées sont déjà répliquées sur au moins un esclave en cas de panne du maître. Bien que semi-synchrone ne représente pas en soi une solution à haute disponibilité, c'est un composant de votre solution. Il est préférable que vous connaissiez vos besoins et que vous ajustiez votre implémentation de semi-synchronisation en conséquence. Par conséquent, si une certaine perte de données est acceptable, vous pouvez utiliser à la place la réplication asynchrone traditionnelle.
La réplication basée sur GTID est utile au DBA car elle simplifie la tâche d'effectuer un basculement, en particulier lorsqu'un esclave est pointé vers un autre maître ou un nouveau maître. Cela signifie qu'avec un simple MASTER_AUTO_POSITION=1 après avoir défini les informations d'identification d'hôte et de réplication correctes, il commencera à répliquer à partir du maître sans avoir besoin de trouver et de spécifier les positions x et y correctes du journal binaire. L'ajout de la prise en charge de la réplication parallèle augmente également les threads de réplication car il accélère le traitement des événements à partir du journal de relais.
Ainsi, MySQL Replication est un excellent composant de choix par rapport aux autres solutions HA s'il répond à vos besoins.
Topologies pour la réplication MySQL
Le déploiement de MySQL Replication dans un environnement multicloud avec GCP (Google Cloud Platform) et AWS reste la même approche si vous devez répliquer sur site.
Il existe différentes topologies que vous pouvez configurer et mettre en œuvre.
Réplication maître avec esclave (réplication unique)
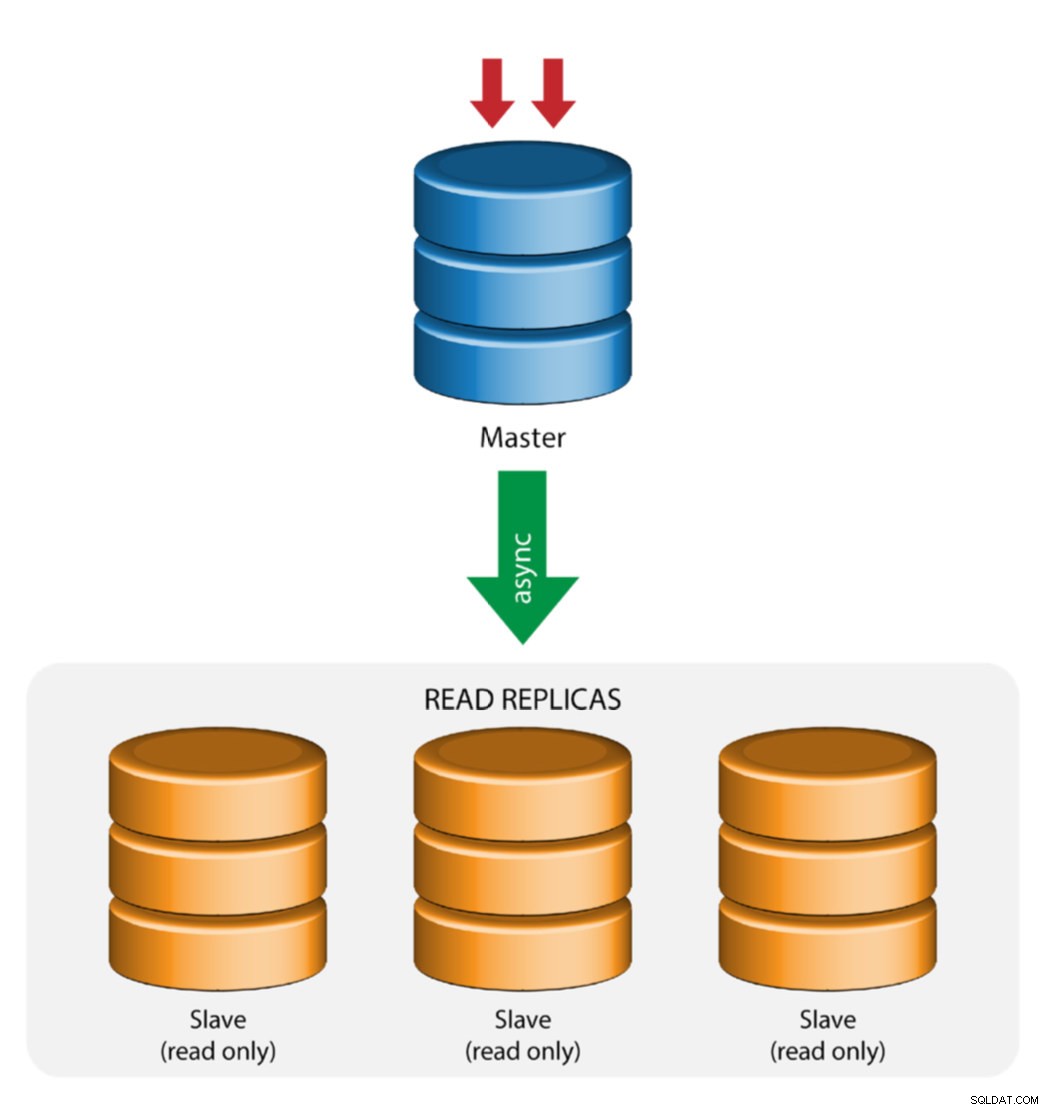
Il s'agit de la topologie de réplication MySQL la plus simple. Un maître reçoit les écritures, un ou plusieurs esclaves répliquent à partir du même maître via une réplication asynchrone ou semi-synchrone. Si le maître désigné tombe en panne, l'esclave le plus récent doit être promu en tant que nouveau maître. Les esclaves restants reprennent la réplication à partir du nouveau maître.
Maître avec relais esclaves (réplication en chaîne)
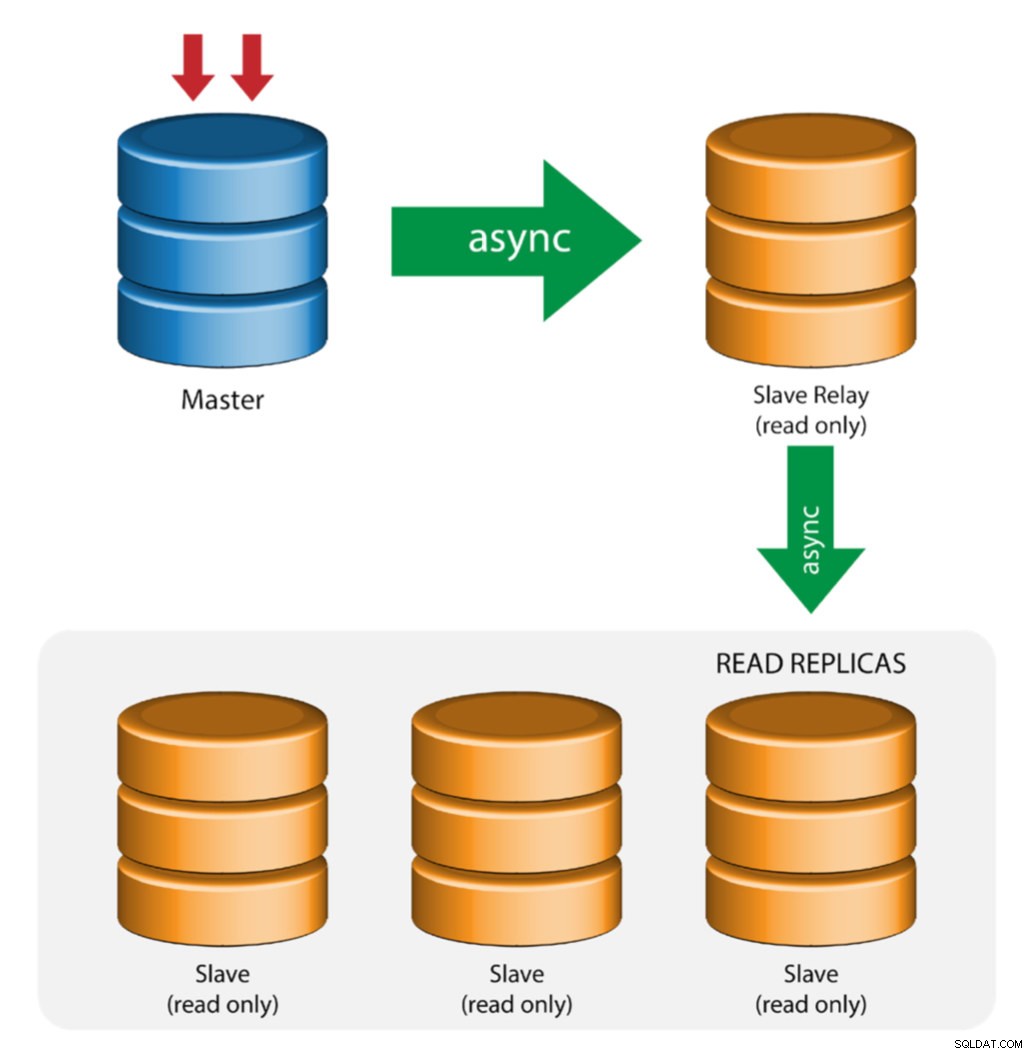
Cette configuration utilise un maître intermédiaire pour servir de relais aux autres esclaves de la chaîne de réplication. Lorsque de nombreux esclaves sont connectés à un maître, l'interface réseau du maître peut être surchargée. Cette topologie permet aux réplicas en lecture d'extraire le flux de réplication du serveur relais pour décharger le serveur maître. Sur le serveur relais esclave, la journalisation binaire et log_slave_updates doivent être activés, de sorte que les mises à jour reçues par le serveur esclave depuis le serveur maître sont enregistrées dans le propre journal binaire de l'esclave.
L'utilisation du relais esclave a ses problèmes :
- log_slave_updates a une baisse de performance.
- Le retard de réplication sur le serveur relais esclave générera un retard sur tous ses esclaves.
- Les transactions frauduleuses sur le serveur relais esclave infecteront tous ses esclaves.
- Si un serveur relais esclave tombe en panne et que vous n'utilisez pas GTID, tous ses esclaves arrêtent de se répliquer et doivent être réinitialisés.
Maître avec maître actif (réplication circulaire)
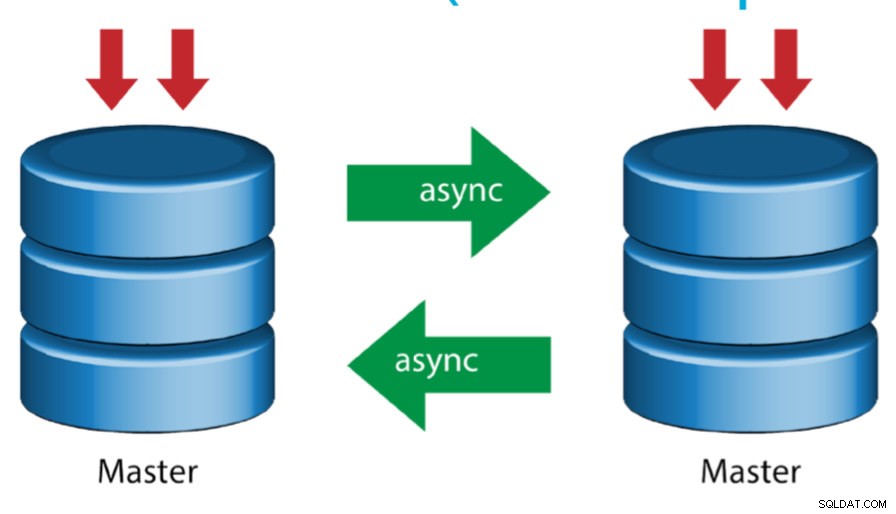
Également connue sous le nom de topologie en anneau, cette configuration nécessite deux serveurs MySQL ou plus qui agissent en tant que maîtres. Tous les maîtres reçoivent des écritures et génèrent des binlogs avec quelques mises en garde :
- Vous devez définir un décalage d'auto-incrémentation sur chaque serveur pour éviter les collisions de clés primaires.
- Il n'y a pas de résolution de conflit.
- MySQL Replication ne prend actuellement en charge aucun protocole de verrouillage entre le maître et l'esclave pour garantir l'atomicité d'une mise à jour distribuée sur deux serveurs différents.
- La pratique courante consiste à n'écrire que sur un maître et l'autre maître agit comme un nœud de secours à chaud. Néanmoins, si vous avez des esclaves en dessous de ce niveau, vous devez basculer manuellement vers le nouveau maître si le maître désigné tombe en panne.
- ClusterControl prend en charge cette topologie (nous ne recommandons pas plusieurs enregistreurs dans une configuration de réplication). Consultez ce blog précédent pour savoir comment déployer avec ClusterControl.
Maître avec maître de sauvegarde (réplication multiple)
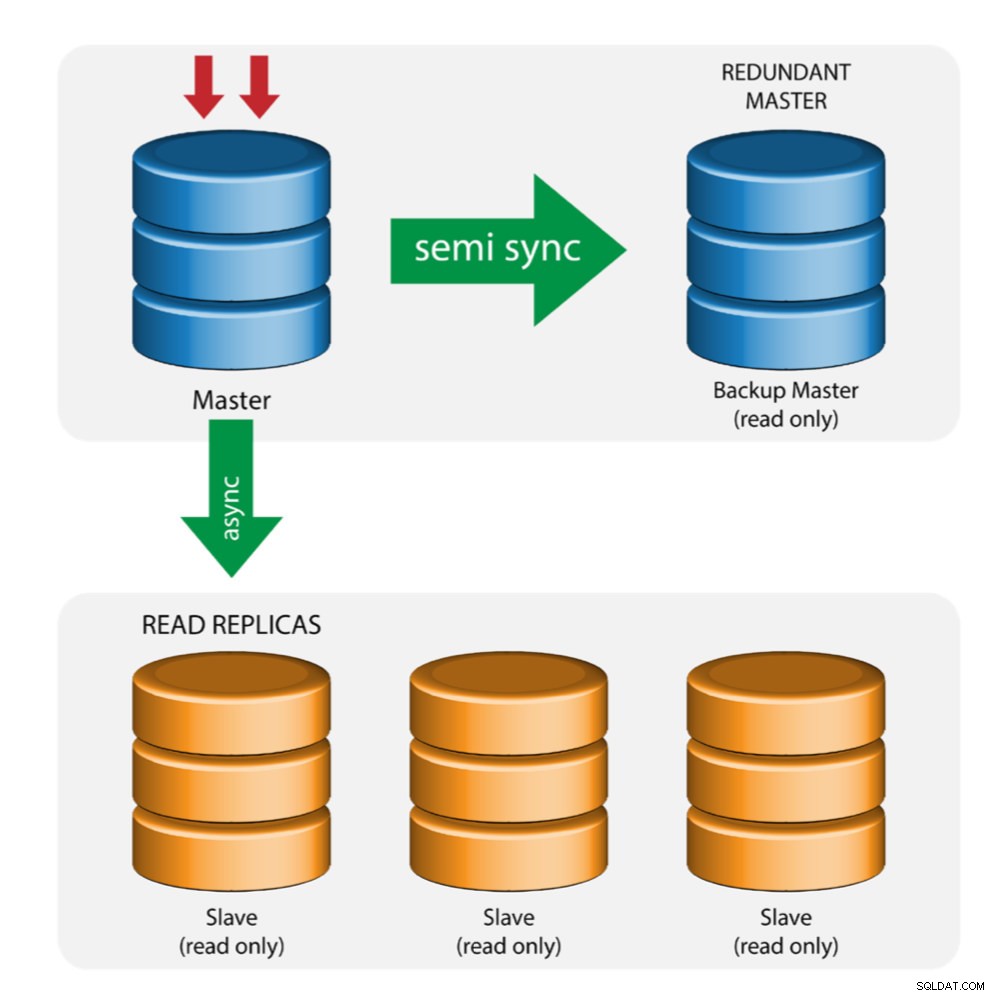
Le maître transmet les modifications à un maître de secours et à un ou plusieurs esclaves. La réplication semi-synchrone est utilisée entre le maître et le maître de secours. Le maître envoie la mise à jour au maître de secours et attend la validation de la transaction. Le maître de sauvegarde reçoit les mises à jour, écrit dans son journal de relais et vide sur le disque. Le maître de sauvegarde accuse ensuite réception de la transaction au maître et procède à la validation de la transaction. La réplication semi-synchronisée a un impact sur les performances, mais le risque de perte de données est minimisé.
Cette topologie fonctionne bien lors de l'exécution d'un basculement de maître au cas où le maître tomberait en panne. Le maître de sauvegarde agit comme un serveur de secours car il a la plus grande probabilité d'avoir des données à jour par rapport aux autres esclaves.
Plusieurs maîtres vers un seul esclave (réplication multi-sources)
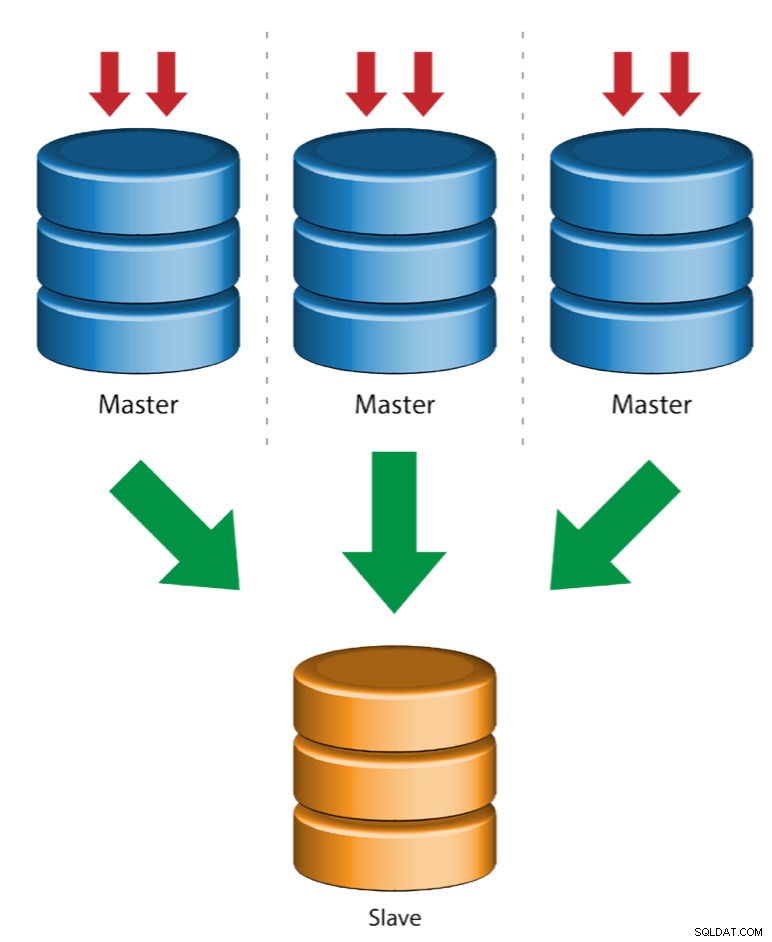
La réplication multi-sources permet à un esclave de réplication de recevoir simultanément des transactions provenant de plusieurs sources. La réplication multisource peut être utilisée pour sauvegarder plusieurs serveurs sur un seul serveur, pour fusionner des fragments de table et consolider les données de plusieurs serveurs sur un seul serveur.
MySQL et MariaDB ont différentes implémentations de réplication multi-sources, où MariaDB doit avoir un GTID avec gtid-domain-id configuré pour distinguer les transactions d'origine tandis que MySQL utilise un canal de réplication distinct pour chaque maître à partir duquel l'esclave se réplique. Dans MySQL, les maîtres d'une topologie de réplication multisource peuvent être configurés pour utiliser soit la réplication basée sur l'identifiant de transaction global (GTID), soit la réplication basée sur la position du journal binaire.
Vous trouverez plus d'informations sur la réplication multi-source MariaDB dans cet article de blog. Pour MySQL, veuillez vous référer à la documentation MySQL.
Galera avec esclave de réplication (réplication hybride)
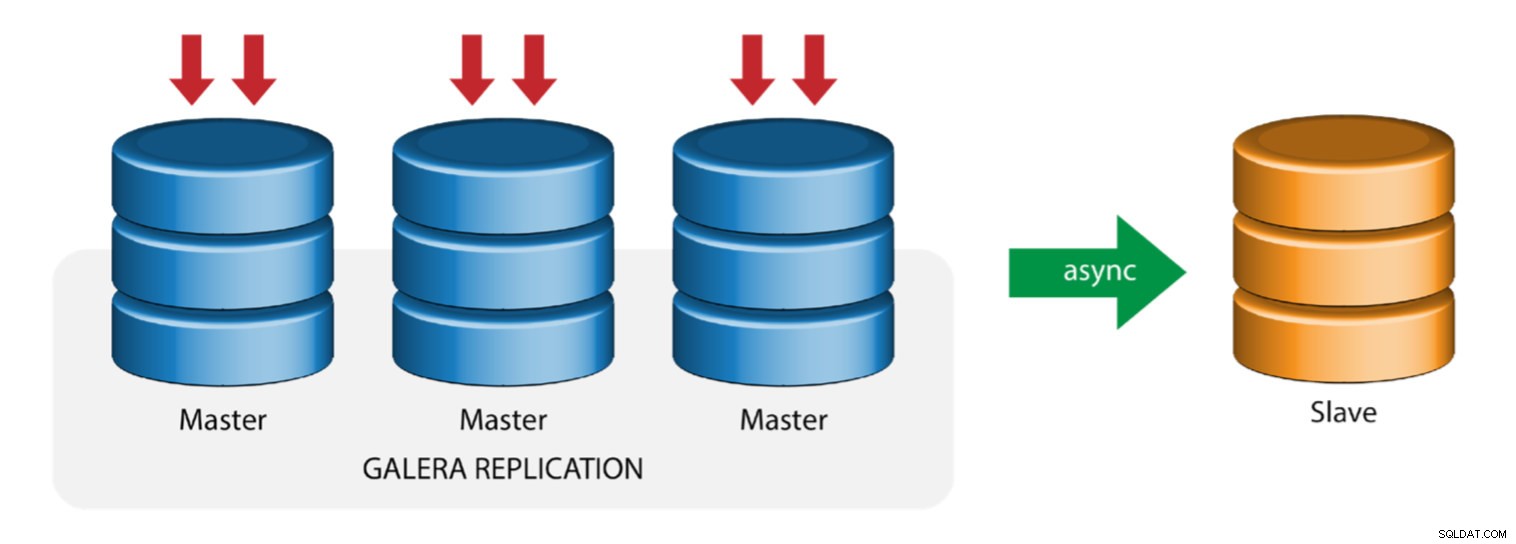
La réplication hybride est une combinaison de la réplication asynchrone MySQL et de la réplication virtuellement synchrone fournie par Galera. Le déploiement est maintenant simplifié avec la mise en œuvre de GTID dans la réplication MySQL, où la configuration et l'exécution du basculement maître sont devenues un processus simple du côté esclave.
Les performances du cluster Galera sont aussi rapides que le nœud le plus lent. Avoir un esclave de réplication asynchrone peut minimiser l'impact sur le cluster si vous envoyez des requêtes de type reporting/OLAP de longue durée à l'esclave, ou si vous effectuez des tâches lourdes qui nécessitent des verrous comme mysqldump. L'esclave peut également servir de sauvegarde en direct pour la reprise après sinistre sur site et hors site.
La réplication hybride est prise en charge par ClusterControl et vous pouvez la déployer directement à partir de l'interface utilisateur de ClusterControl. Pour plus d'informations sur la façon de procéder, veuillez lire les articles de blog - Réplication hybride avec MySQL 5.6 et Réplication hybride avec MariaDB 10.x.
Préparation des plates-formes GCP et AWS
Le problème du "monde réel"
Dans ce blog, nous allons démontrer et utiliser la topologie "Multiple Replication" dans laquelle les instances sur deux plates-formes de cloud public différentes communiqueront à l'aide de la réplication MySQL sur différentes régions et sur différentes zones de disponibilité. Ce scénario est basé sur un problème réel où une organisation souhaite structurer son infrastructure sur plusieurs plates-formes cloud pour l'évolutivité, la redondance, la résilience/la tolérance aux pannes. Des concepts similaires s'appliqueraient à MongoDB ou PostgreSQL.
Considérons une organisation américaine, avec une succursale à l'étranger en Asie du Sud-Est. Notre trafic est élevé dans la région basée en Asie. La latence doit être faible lors de la prise en charge des écritures et des lectures, mais en même temps, la région basée aux États-Unis peut également extraire des enregistrements provenant du trafic basé en Asie.
Le flux de l'architecture cloud
Dans cette section, je vais discuter de la conception architecturale. Tout d'abord, nous voulons offrir une couche hautement sécurisée pour laquelle nos nœuds Google Compute et AWS EC2 peuvent communiquer, mettre à jour ou installer des packages depuis Internet, sécurisés, hautement disponibles en cas de panne d'une AZ (zone de disponibilité), peuvent répliquer et communiquer avec une autre plate-forme cloud via une couche sécurisée. Voir l'image ci-dessous pour illustration :

Sur la base de l'illustration ci-dessus, sous la plate-forme AWS, tous les nœuds s'exécutent sur différentes zones de disponibilité. Il possède un sous-réseau privé et public pour lequel tous les nœuds de calcul se trouvent sur un sous-réseau privé. Par conséquent, il peut sortir d'Internet pour extraire et mettre à jour ses packages système en cas de besoin. Il dispose d'une passerelle VPN pour laquelle il doit interagir avec GCP dans ce canal, en contournant Internet mais via un canal sécurisé et privé. Comme pour GCP, tous les nœuds de calcul se trouvent sur différentes zones de disponibilité, utilisez la passerelle NAT pour mettre à jour les packages système en cas de besoin et utilisez la connexion VPN pour interagir avec les nœuds AWS hébergés dans une autre région, c'est-à-dire l'Asie-Pacifique (Singapour). D'autre part, la région basée aux États-Unis est hébergée sous us-east1. Afin d'accéder aux nœuds, un nœud de l'architecture sert de nœud bastion pour lequel nous l'utiliserons comme hôte de saut et installerons ClusterControl. Cela sera abordé plus tard dans ce blog.
Configuration des environnements GCP et AWS
Lors de l'enregistrement de votre premier compte GCP, Google fournit un compte VPC (Virtual Private Cloud) par défaut. Par conséquent, il est préférable de créer un VPC distinct de celui par défaut et de le personnaliser en fonction de vos besoins.
Notre objectif ici est de placer les nœuds de calcul dans des sous-réseaux privés ou les nœuds ne seront pas configurés avec l'IPv4 public. Par conséquent, les deux clouds publics doivent pouvoir communiquer entre eux. Les nœuds de calcul AWS et GCP fonctionnent avec différents CIDR, comme mentionné précédemment. Par conséquent, voici les CIDR suivants :
Nœuds de calcul AWS : 172.21.0.0/16
Nœuds de calcul GCP : 10.142.0.0/20
Dans cette configuration AWS, nous avons alloué trois sous-réseaux qui n'ont pas de passerelle Internet mais une passerelle NAT ; et un sous-réseau doté d'une passerelle Internet. Chacun de ces sous-réseaux est hébergé individuellement dans différentes zones de disponibilité (AZ).
ap-southeast-1a =172.21.1.0/24
ap-sud-est-1b =172.21.8.0/24
ap-sud-est-1c =172.21.24.0/24
Dans GCP, le sous-réseau par défaut créé dans un VPC sous us-east1, à savoir 10.142.0.0/20 CIDR, est utilisé. Voici donc les étapes que vous pouvez suivre pour configurer votre plate-forme cloud multi-public.
-
Pour cet exercice, j'ai créé un VPC dans la région us-east1 avec le sous-réseau suivant de 10.142.0.0/20. Voir ci-dessous :

-
Réservez une adresse IP statique. Il s'agit de l'adresse IP que nous allons configurer en tant que passerelle client dans AWS
-
Étant donné que nous avons des sous-réseaux en place (provisionnés en tant que subnet-us-east1 ), accédez à GCP -> Réseau VPC -> Réseaux VPC et sélectionnez le VPC que vous avez créé et accédez aux règles de pare-feu . Dans cette section, ajoutez les règles en spécifiant votre entrée et votre sortie. Fondamentalement, ce sont les règles entrantes/sortantes dans AWS ou votre pare-feu pour les connexions entrantes et sortantes. Dans cette configuration, j'ai ouvert tous les protocoles TCP de la gamme CIDR définie dans mon AWS et GCP VPC pour le rendre plus simple aux fins de ce blog. Par conséquent, ce n'est pas le moyen optimal pour la sécurité. Voir l'image ci-dessous :
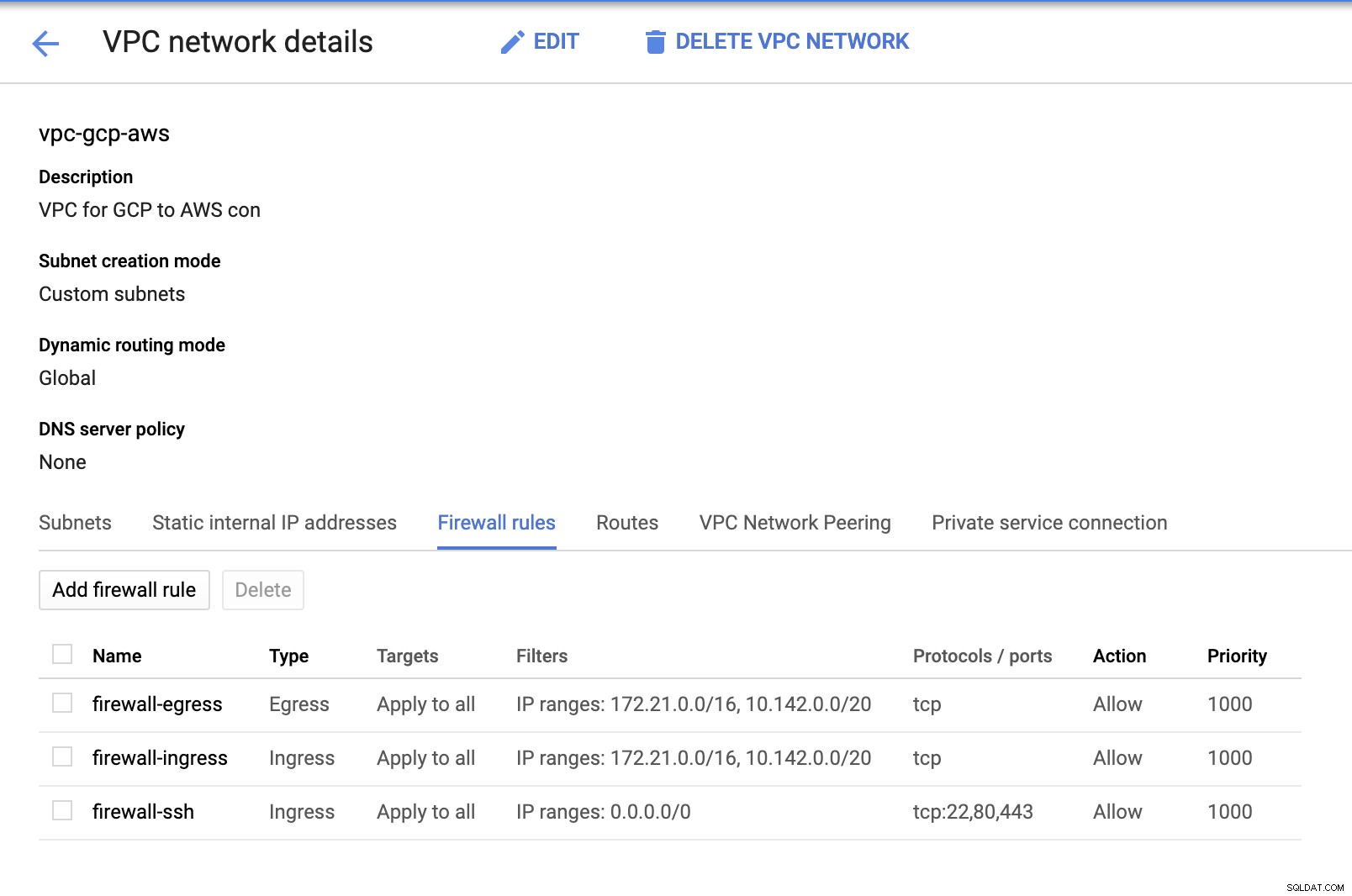
Le pare-feu-ssh ici sera utilisé pour autoriser les connexions entrantes ssh, HTTP et HTTPS.
-
Passez maintenant à AWS et créez un VPC. Pour ce blog, j'ai utilisé CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Créez les sous-réseaux pour lesquels vous devez les affecter dans chaque AZ (zone de disponibilité) ; et réservez au moins un sous-réseau pour un sous-réseau public qui gérera la passerelle NAT, et les autres sont pour les nœuds EC2.

-
Ensuite, créez votre table de routage et assurez-vous que la "Destination" et les "Cibles" sont correctement définies. Pour ce blog, j'ai créé 2 tables de routage. Celui qui gérera les 3 AZ auxquels mes nœuds de calcul seront attribués individuellement et sera attribué sans passerelle Internet car il n'aura pas d'adresse IP publique. Ensuite, l'autre gérera la passerelle NAT et aura une passerelle Internet qui sera dans le sous-réseau public. Voir l'image ci-dessous :

et comme mentionné, mon exemple de destination pour une route privée qui gère 3 sous-réseaux montre qu'il a une cible de passerelle NAT plus une cible de passerelle virtuelle que je mentionnerai plus tard dans les étapes entrantes.

-
Ensuite, créez une "passerelle Internet" et attribuez-la au VPC qui a été précédemment créé dans la section AWS VPC. Cette passerelle Internet ne doit être définie que comme destination du sous-réseau public car ce sera le service qui doit se connecter à Internet. De toute évidence, le nom signifie un service de passerelle Internet.
-
Créez ensuite une "passerelle NAT". Lors de la création d'une "passerelle NAT", assurez-vous que vous avez attribué votre NAT à un sous-réseau public. La passerelle NAT est votre canal pour accéder à Internet à partir de votre sous-réseau privé ou de nœuds EC2 auxquels aucune adresse IPv4 publique n'a été attribuée. Ensuite, créez ou attribuez une EIP (Elastic IP) car, dans AWS, seuls les nœuds de calcul auxquels une IPv4 publique est attribuée peuvent se connecter directement à Internet.
-
Maintenant, sous VPC -> Sécurité -> Groupes de sécurité (SG) , votre VPC créé aura un SG par défaut. Pour cette configuration, j'ai créé des "règles entrantes" avec des sources attribuées pour chaque CIDR, c'est-à-dire 10.142.0.0/20 dans GCP et 172.21.0.0/16 dans AWS. Voir ci-dessous :

Pour les "règles sortantes", vous pouvez laisser cela tel quel puisque l'attribution de règles aux "règles entrantes" est bilatérale, ce qui signifie qu'elle s'ouvrira également pour les "règles sortantes". Notez que ce n'est pas la meilleure façon de configurer votre groupe de sécurité ; mais pour faciliter cette configuration, j'ai également élargi la portée de la plage de ports et de la source. De plus, le protocole est spécifique aux connexions TCP uniquement puisque nous ne traiterons pas d'UDP pour ce blog.
De plus, vous pouvez laisser votre VPC -> Sécurité -> ACL réseau intact tant qu'il ne REFUSE aucune connexion tcp du CIDR indiqué dans votre source. -
Ensuite, nous allons configurer la configuration VPN qui sera hébergée sous la plate-forme AWS. Sous le VPC > Passerelles client , créez la passerelle à l'aide de l'adresse IP statique créée précédemment à l'étape précédente. Jetez un oeil à l'image ci-dessous :
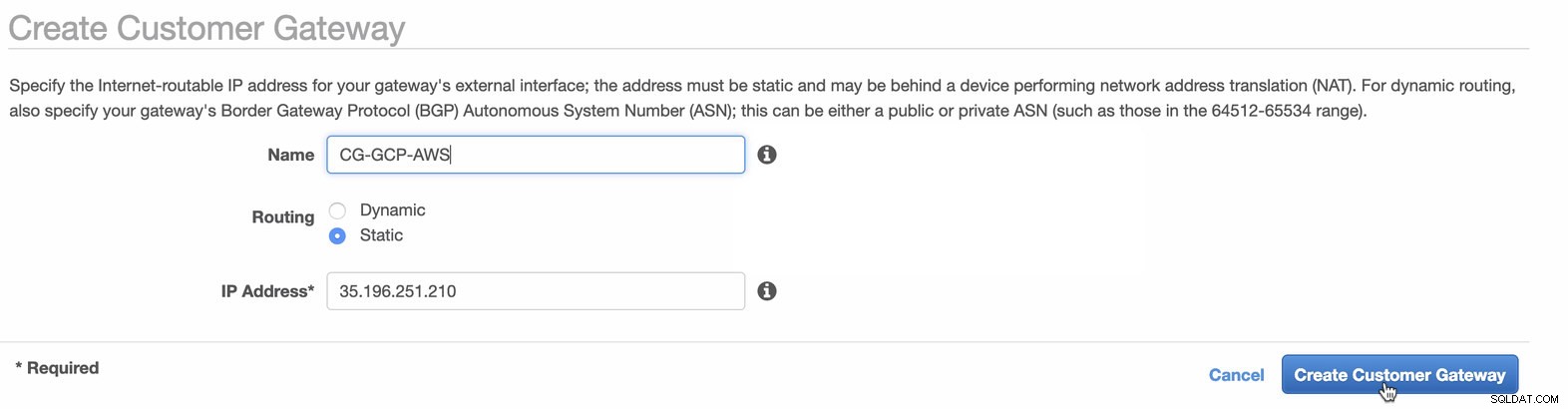
-
Ensuite, créez une passerelle privée virtuelle et attachez-la au VPC actuel que nous avons créé précédemment à l'étape précédente. Voir l'image ci-dessous :

-
Maintenant, créez une connexion VPN qui sera utilisée pour la connexion de site à site entre AWS et GCP. Lors de la création d'une connexion VPN, assurez-vous que vous avez sélectionné la passerelle réseau privé virtuel et la passerelle client correctes que nous avons créées aux étapes précédentes. Voir l'image ci-dessous :
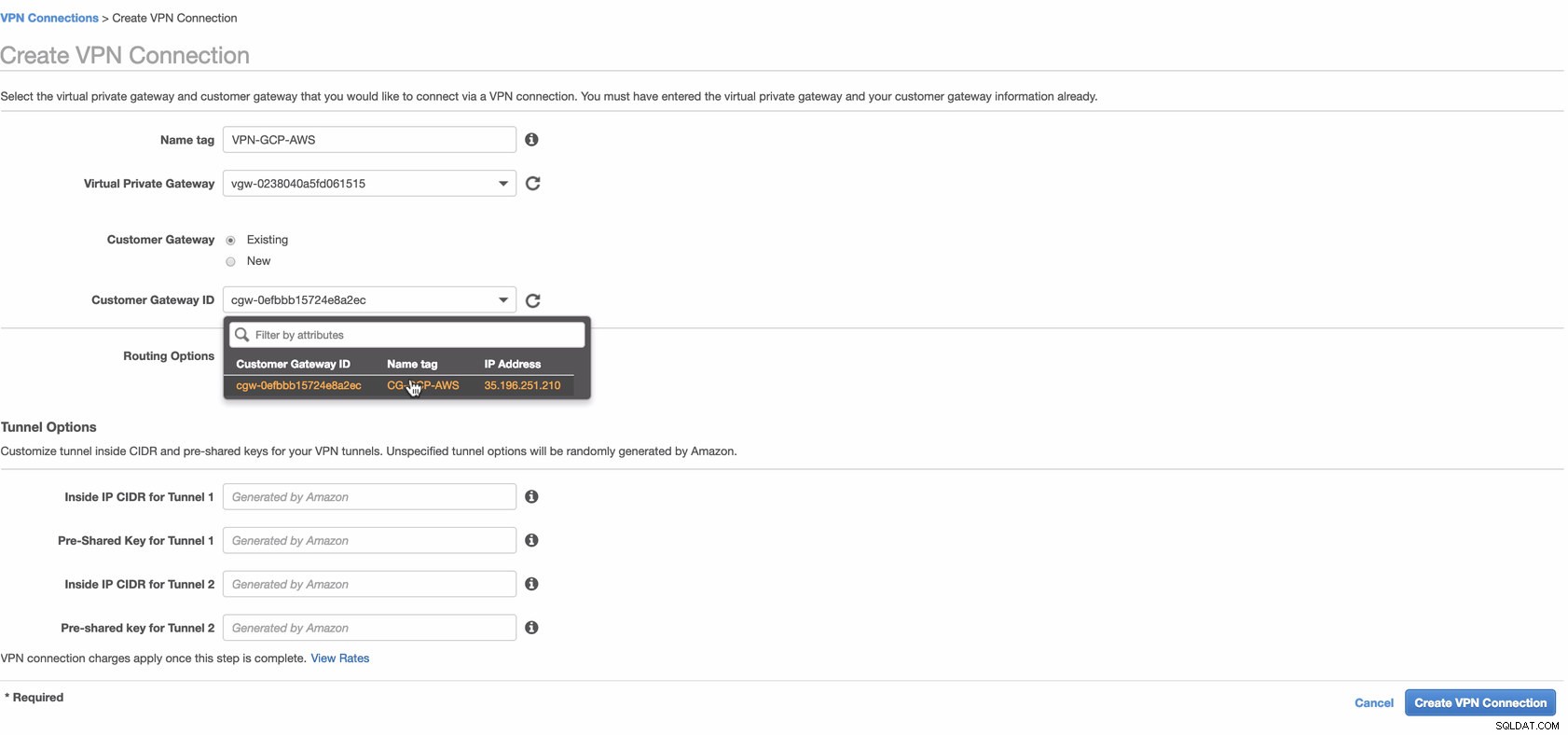
Cela peut prendre un certain temps pendant qu'AWS crée votre connexion VPN. Lorsque votre connexion VPN est alors provisionnée, vous vous demandez peut-être pourquoi sous l'onglet Tunnel (après avoir sélectionné votre connexion VPN), il apparaîtra que l'Adresse IP extérieure est éteint. Ceci est normal car aucune connexion n'a encore été établie à partir du client. Jetez un œil à l'exemple d'image ci-dessous :

Une fois la connexion VPN prête, sélectionnez votre connexion VPN créée et téléchargez la configuration. Il contient vos informations d'identification nécessaires aux étapes suivantes pour créer une connexion VPN de site à site avec le client.
Remarque : Dans le cas où vous avez configuré votre VPN où IPSEC EST UP mais Statut est DOWN tout comme l'image ci-dessous

cela est probablement dû à des valeurs incorrectes définies pour les paramètres spécifiques lors de la configuration de votre session BGP ou de votre routeur cloud. Consultez-le ici pour dépanner votre VPN.
-
Puisque nous avons une connexion VPN prête à être hébergée dans AWS, créons une connexion VPN dans GCP. Revenons maintenant à GCP et y configurons la connexion client. Dans GCP, accédez à GCP -> Connectivité hybride -> VPN . Assurez-vous que vous choisissez la bonne région, qui se trouve sur ce blog, nous utilisons us-east1 . Sélectionnez ensuite l'adresse IP statique créée aux étapes précédentes. Voir l'image ci-dessous :
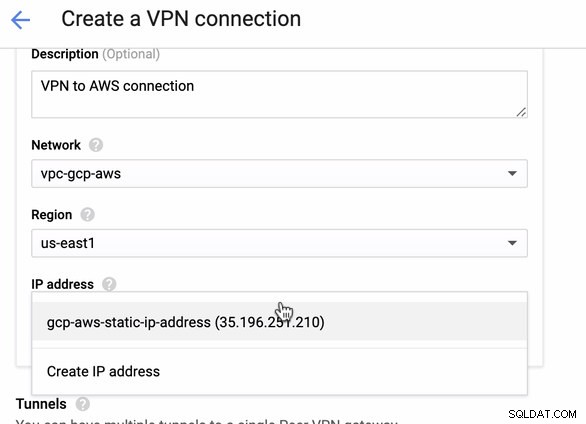
Puis dans les Tunnels , c'est ici que vous devrez configurer en fonction des informations d'identification téléchargées à partir de la connexion VPN AWS que vous avez créée précédemment. Je suggère de consulter ce guide utile de Google. Par exemple, l'un des tunnels en cours de configuration est illustré dans l'image ci-dessous :
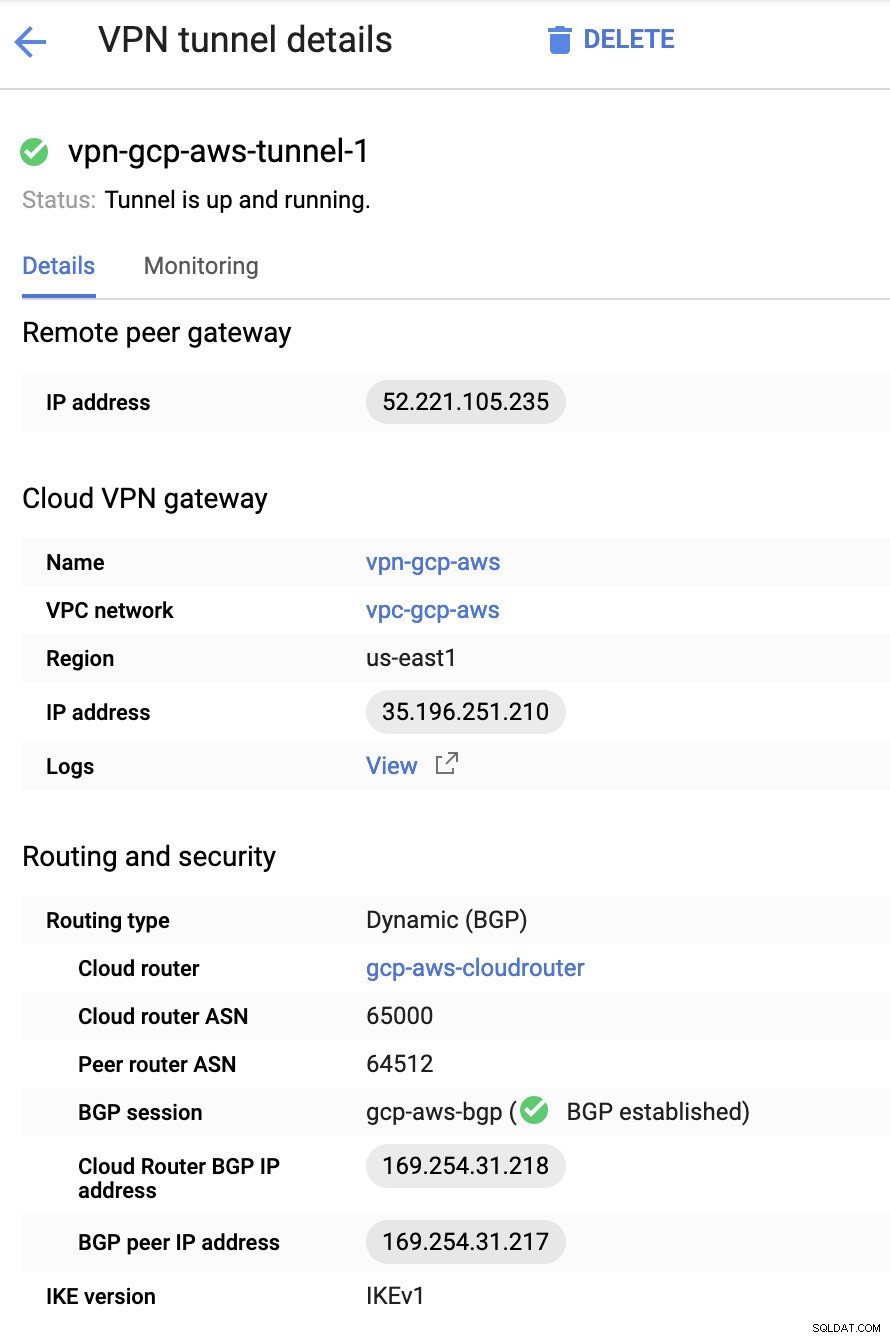
Fondamentalement, les choses les plus importantes ici sont les suivantes :
- Remote Peer Gateway : Adresse IP :il s'agit de l'adresse IP du serveur VPN indiquée sous Détails du tunnel -> Adresse IP externe . Cela ne doit pas être confondu avec l'adresse IP statique que nous avons créée sous GCP. C'est la passerelle Cloud VPN -> adresse IP cependant.
- ASN du routeur cloud :par défaut, AWS utilise 65 000. Mais vous obtiendrez probablement ces informations à partir du fichier de configuration téléchargé.
- ASN du routeur homologue :il s'agit de l'ASN de la passerelle privée virtuelle qui se trouve dans le fichier de configuration téléchargé.
- Adresse IP BGP du routeur cloud :il s'agit de la passerelle client trouvé dans le fichier de configuration téléchargé.
- Adresse IP du pair BGP :il s'agit de la passerelle privée virtuelle trouvé dans le fichier de configuration téléchargé.
-
Jetez un oeil à l'exemple de fichier de configuration que j'ai ci-dessous :
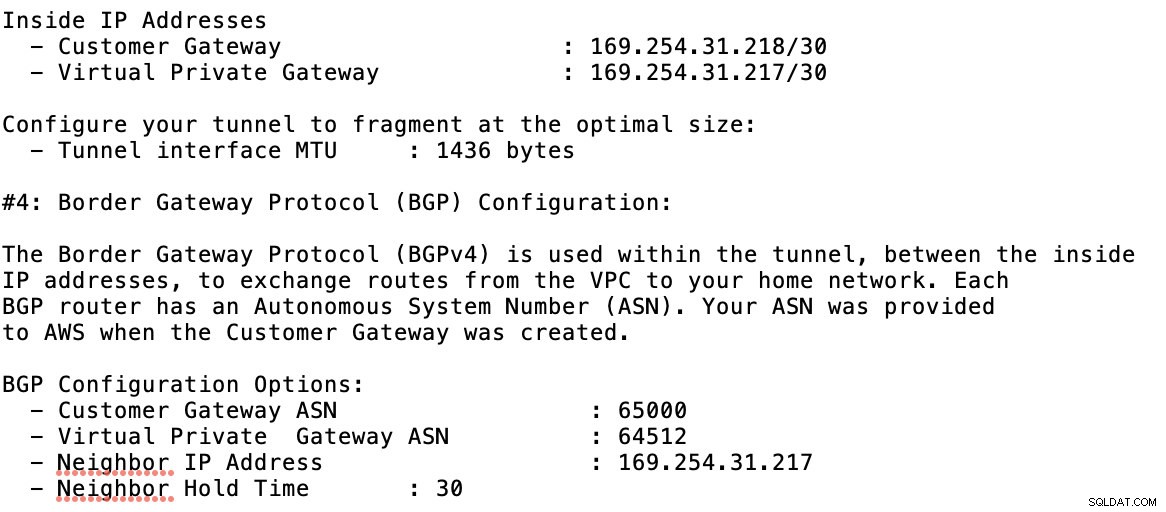
pour lequel vous devez faire correspondre cela lors de l'ajout de votre tunnel sous GCP -> Connectivité hybride -> VPN configuration de la connectivité. Voir l'image ci-dessous pour laquelle j'ai créé un routeur cloud et une session BGP lors de la création d'un exemple de tunnel :
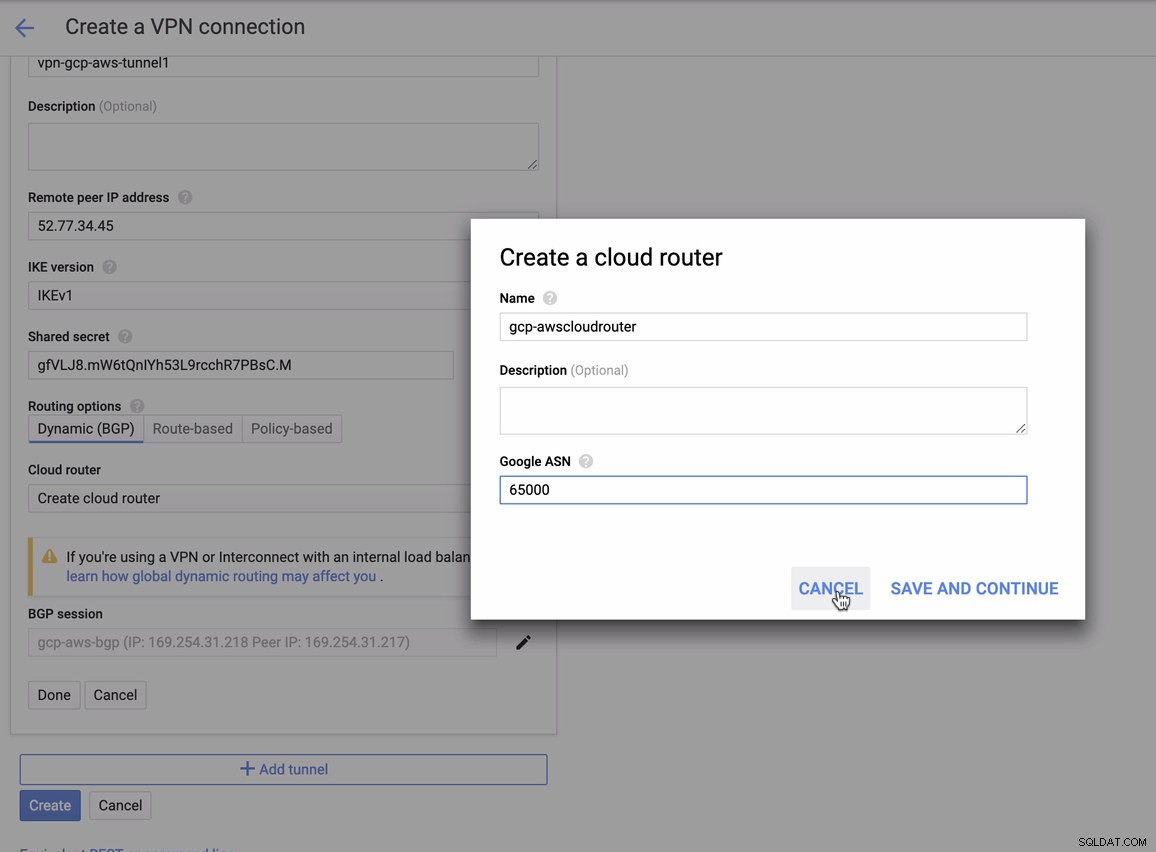
Puis session BGP en tant que,

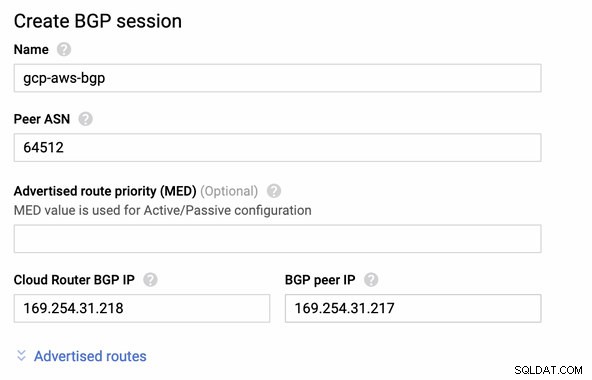
Remarque : Le fichier de configuration téléchargé contient le tunnel de configuration IPSec pour lequel AWS contient également deux (2) serveurs VPN prêts pour votre connexion. Vous devez configurer les deux afin d'avoir une configuration disponible élevée. Une fois sa configuration correcte pour les deux tunnels, la connexion AWS VPN sous l'onglet Tunnels indiquera que les deux Adresse IP extérieure sont debout. Voir l'image ci-dessous :

-
Enfin, puisque nous avons créé une passerelle Internet et une passerelle NAT, remplissez correctement les sous-réseaux publics et privés avec la destination correcte et Cible comme remarqué dans la capture d'écran des étapes précédentes. Cela peut être configuré en accédant à Services -> Mise en réseau et diffusion de contenu -> VPC -> Tables de routage et sélectionnez les tables de routage créées mentionnées dans les étapes précédentes. Voir l'image ci-dessous :
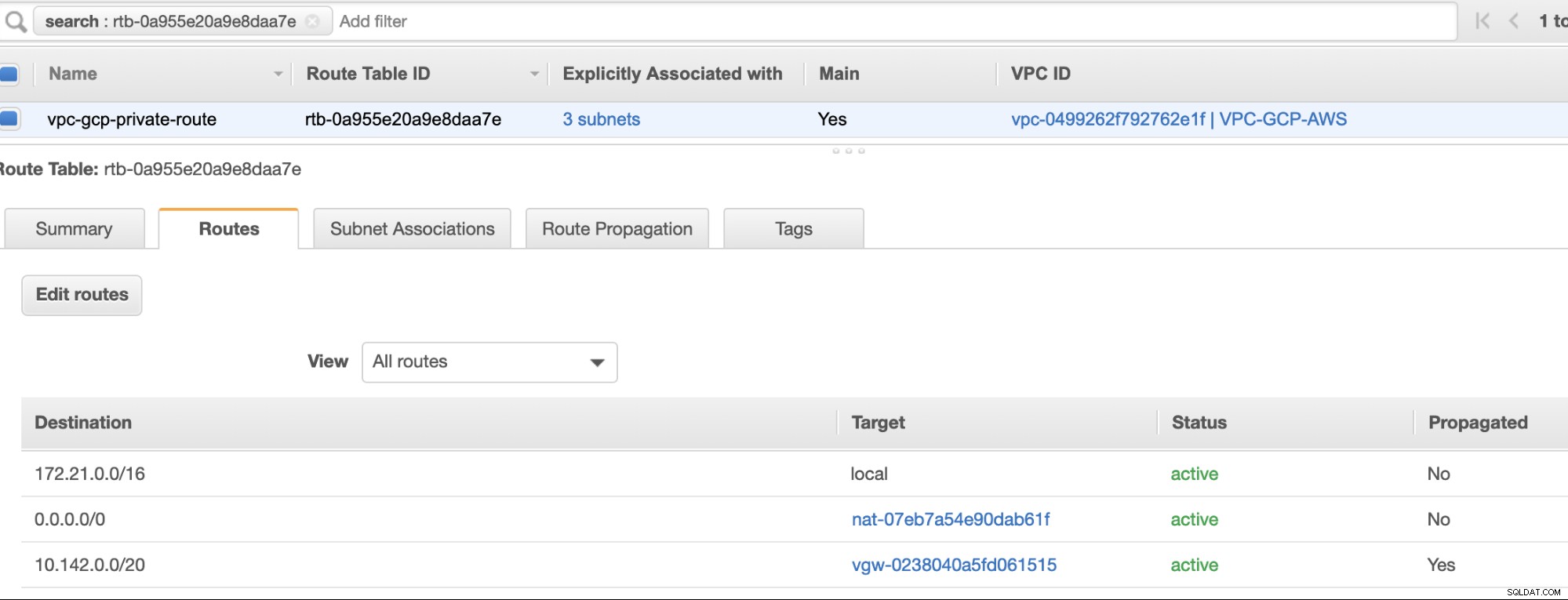
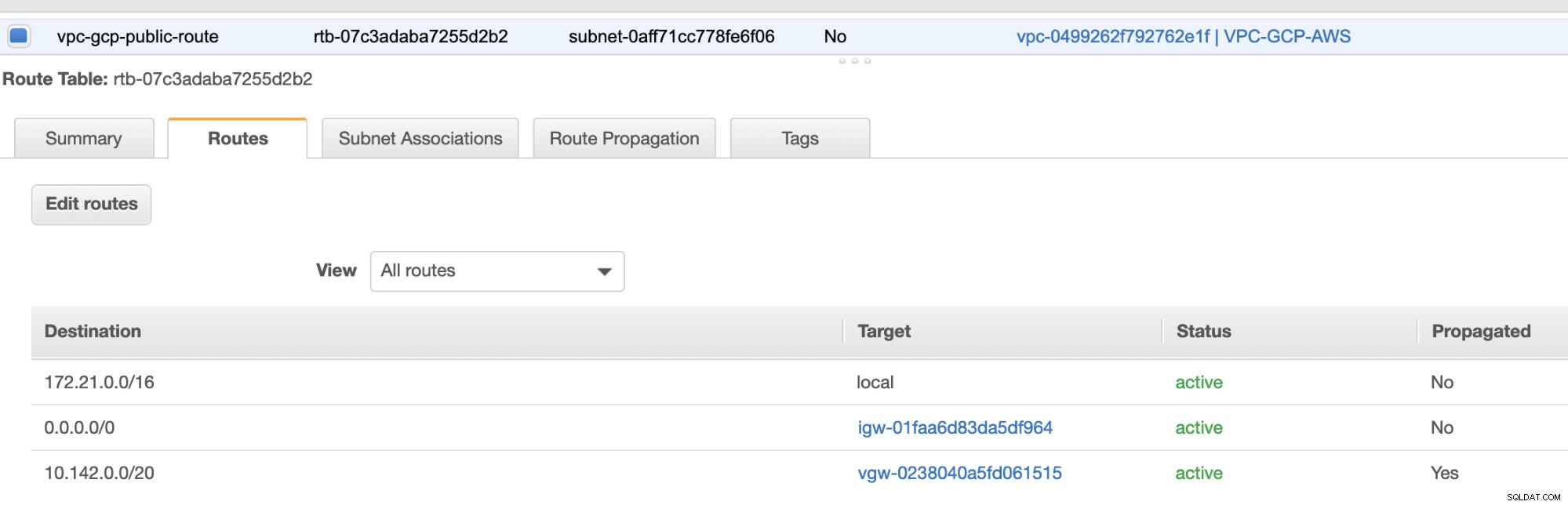
Comme vous l'avez remarqué, le igw-01faa6d83da5df964 est la passerelle Internet que nous avons créée et qui est utilisée par la voie publique. Alors que la table de routage privée a une destination et une cible définies sur nat-07eb7a54e90dab61f et les deux ont Destination défini sur 0.0.0.0/0 car il autorisera différentes connexions IPv4. N'oubliez pas non plus de définir la propagation de la route correctement pour la passerelle virtuelle comme le montre la capture d'écran qui a une cible vgw-0238040a5fd061515 . Cliquez simplement sur Route Propagation et réglez-le sur Oui, comme dans la capture d'écran ci-dessous :
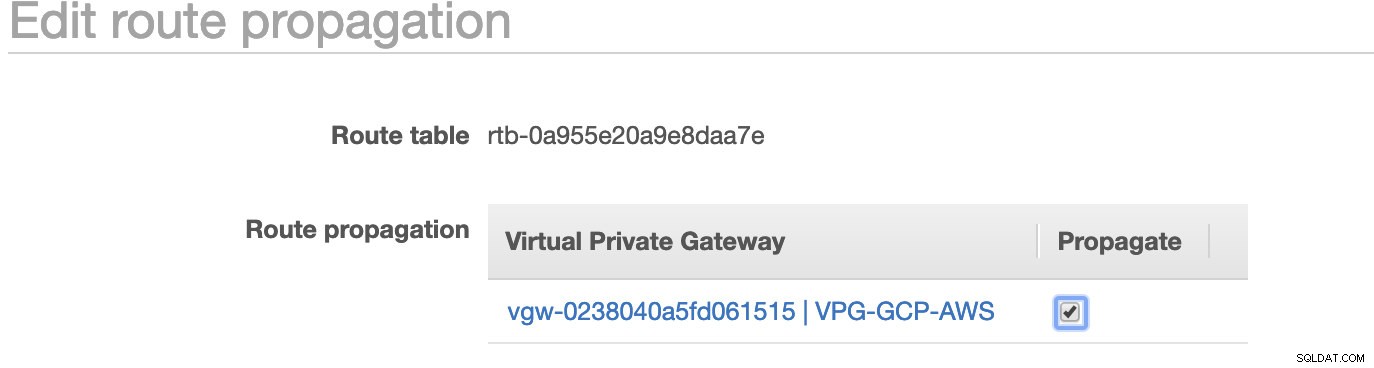
Ceci est très important pour que la connexion des connexions GCP externes soit acheminée vers les tables de routage dans AWS et qu'aucun autre travail manuel ne soit nécessaire. Sinon, votre GCP ne peut pas établir de connexion à AWS.
Maintenant que notre VPN est opérationnel, nous allons continuer à configurer nos nœuds privés, y compris l'hôte bastion.
Configuration des nœuds Compute Engine
La configuration des nœuds Compute Engine/EC2 sera rapide et facile puisque nous avons tout configuré en place. Je n'entrerai pas dans les détails, mais consultez les captures d'écran ci-dessous car elles expliquent la configuration.
Nœuds AWS EC2 :

Nœuds de calcul GCP :
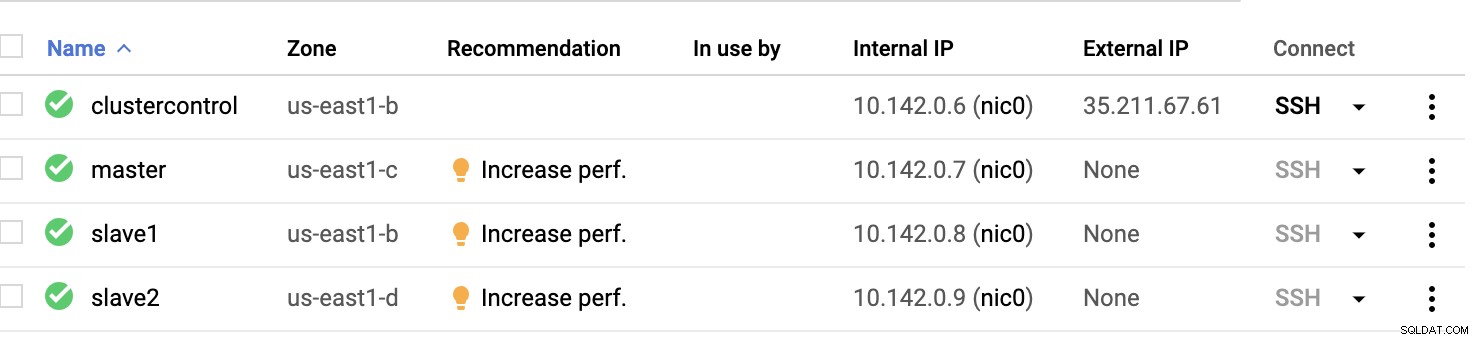
Fondamentalement, sur cette configuration. L'hôte clustercontrol sera le bastion ou l'hôte de saut et pour lequel le ClusterControl sera installé. De toute évidence, tous les nœuds ici ne sont pas accessibles par Internet. Ils n'ont pas d'IPv4 externe attribué et les nœuds communiquent via un canal très sécurisé utilisant VPN.
Enfin, tous ces nœuds d'AWS à GCP sont configurés avec un utilisateur système uniforme avec un accès sudo, ce qui est nécessaire dans notre section suivante. Découvrez comment ClusterControl peut vous faciliter la vie en mode multicloud et multirégion.
ClusterControl à la rescousse !!!
La gestion de plusieurs nœuds et sur différentes plates-formes de cloud public, ainsi que sur une "région" différente peut être une tâche "vraiment douloureuse et intimidante". Comment contrôler cela efficacement ? ClusterControl agit non seulement comme votre couteau suisse, mais aussi comme votre Virtual DBA. Voyons maintenant comment ClusterControl peut vous faciliter la vie.
Création d'un cluster à réplication multiple à l'aide de ClusterControl
Essayons maintenant de créer un cluster de réplication maître-esclave MariaDB en suivant la topologie "Multiple Replication".
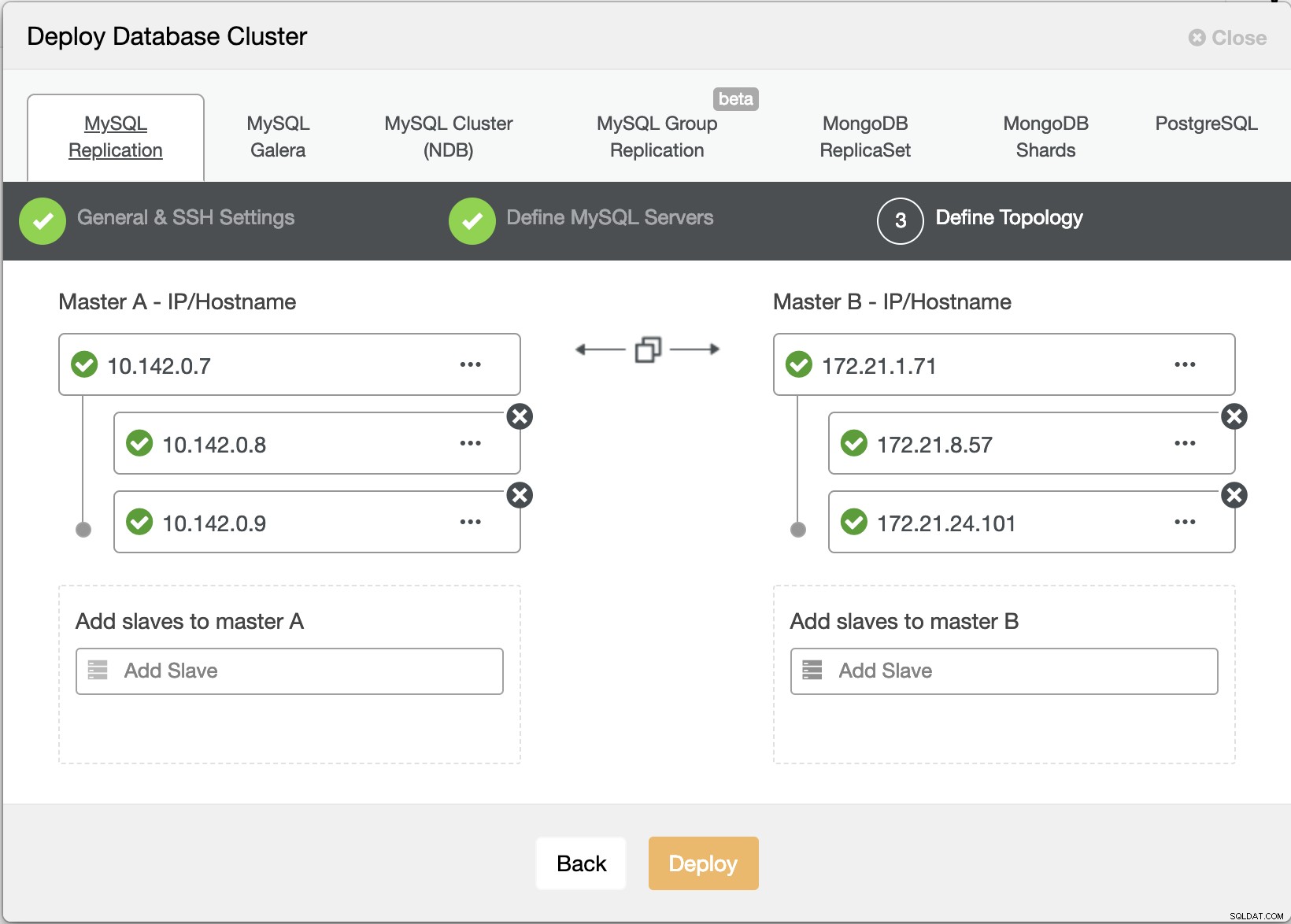 Assistant de déploiement de ClusterControl
Assistant de déploiement de ClusterControl Appuyer sur Déployer Le bouton installera les packages et configurera les nœuds en conséquence. Par conséquent, une vue logique de ce à quoi ressemblerait la topologie :
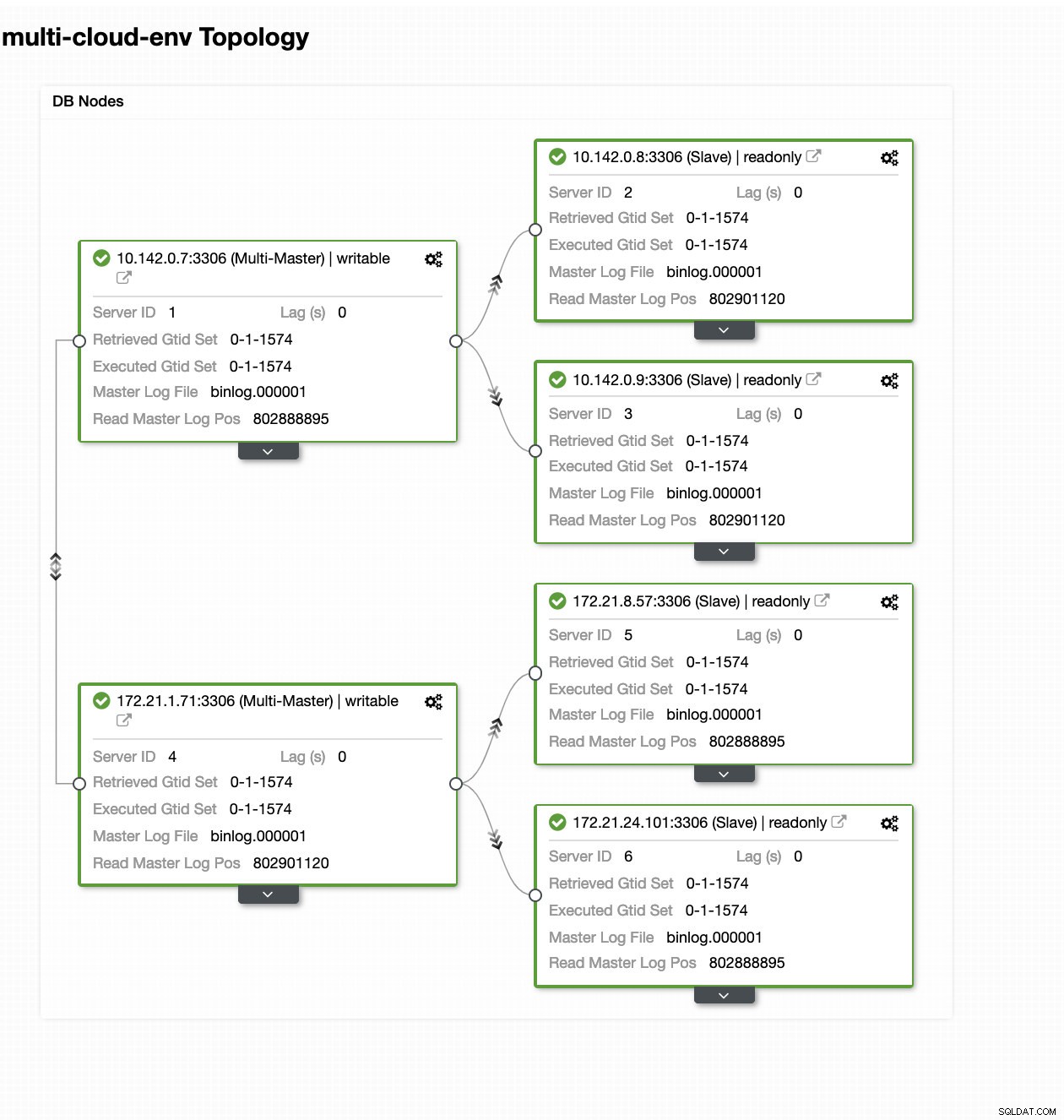 ClusterControl - Vue topologique
ClusterControl - Vue topologique Les adresses IP de la plage 172.21.0.0/16 des nœuds sont répliquées à partir de leur maître s'exécutant sur GCP.
Maintenant, que diriez-vous d'essayer de charger des écritures sur le maître ? Tout problème de connectivité ou de latence peut générer un décalage esclave, vous pourrez le repérer avec ClusterControl. Voir la capture d'écran ci-dessous :
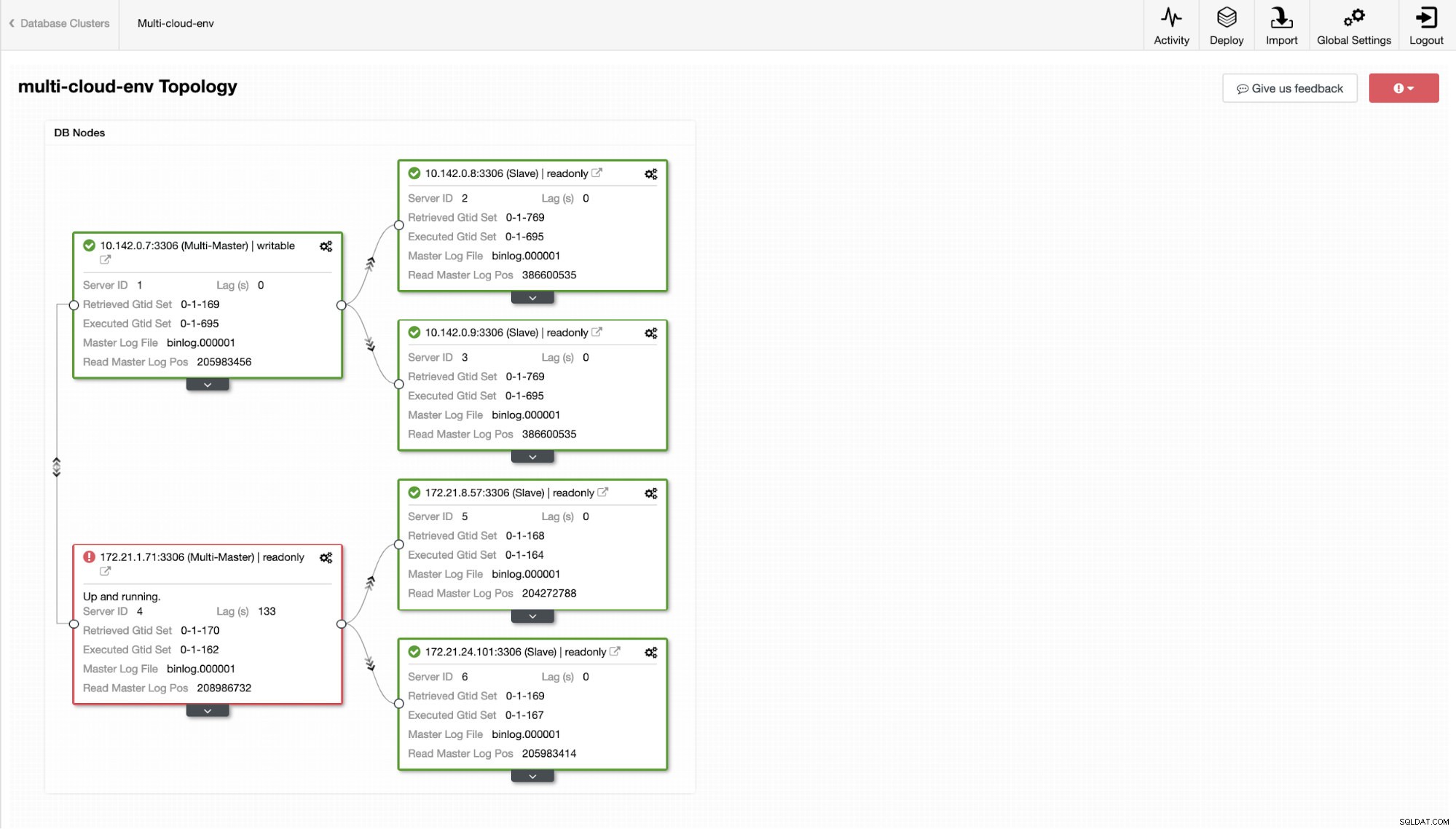
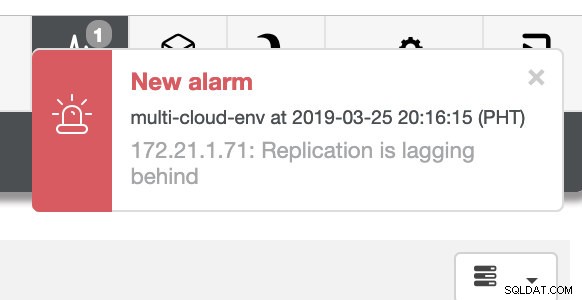
et comme vous le voyez dans le coin supérieur droit de la capture d'écran, il devient rouge car il indique que des problèmes ont été détectés. Par conséquent, une alarme était envoyée pendant que ce problème était détecté. Voir ci-dessous :
Nous devons creuser cela. Pour une surveillance précise, nous avons activé des agents sur les instances de base de données. Jetons un coup d'œil au tableau de bord.
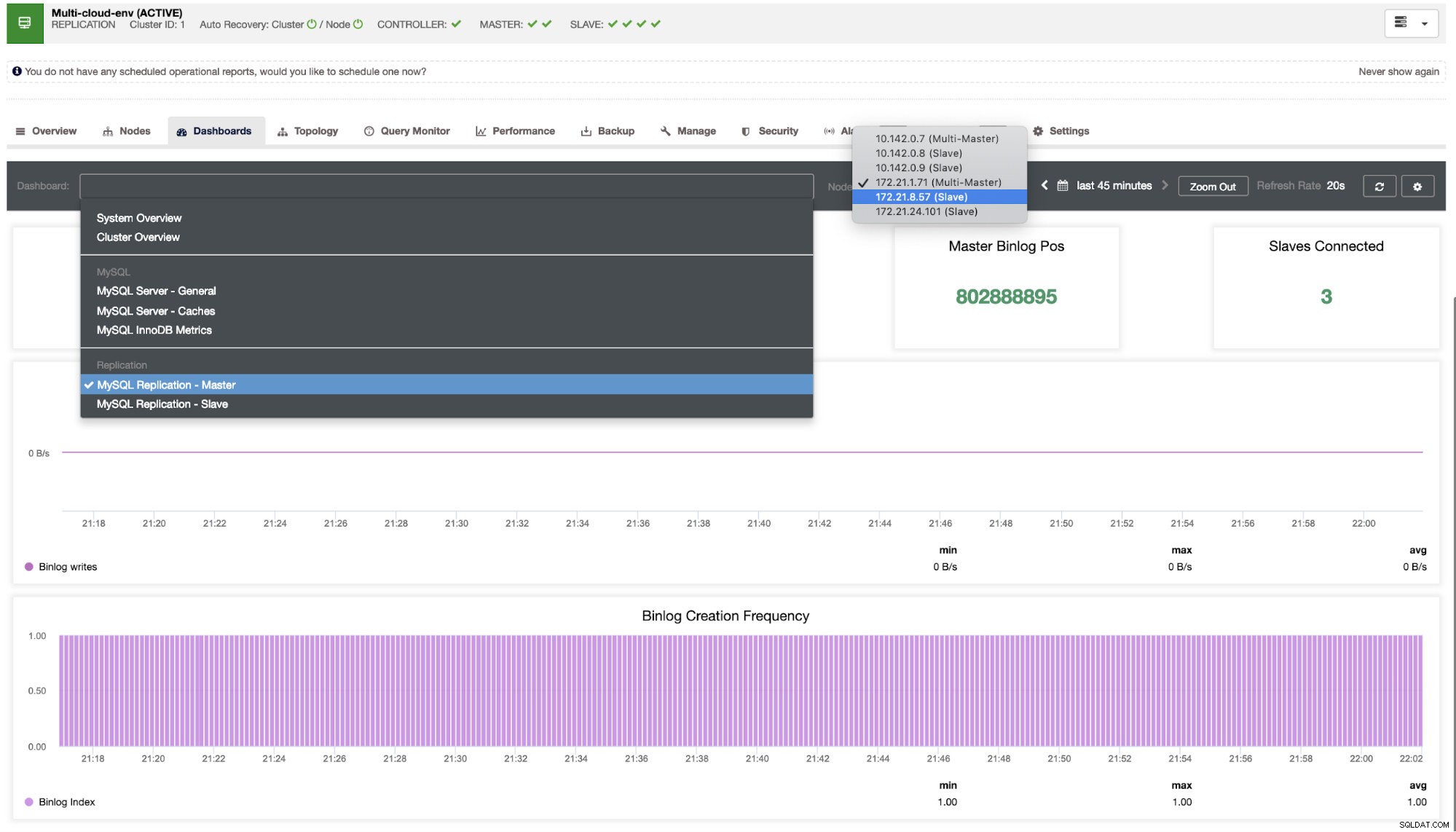
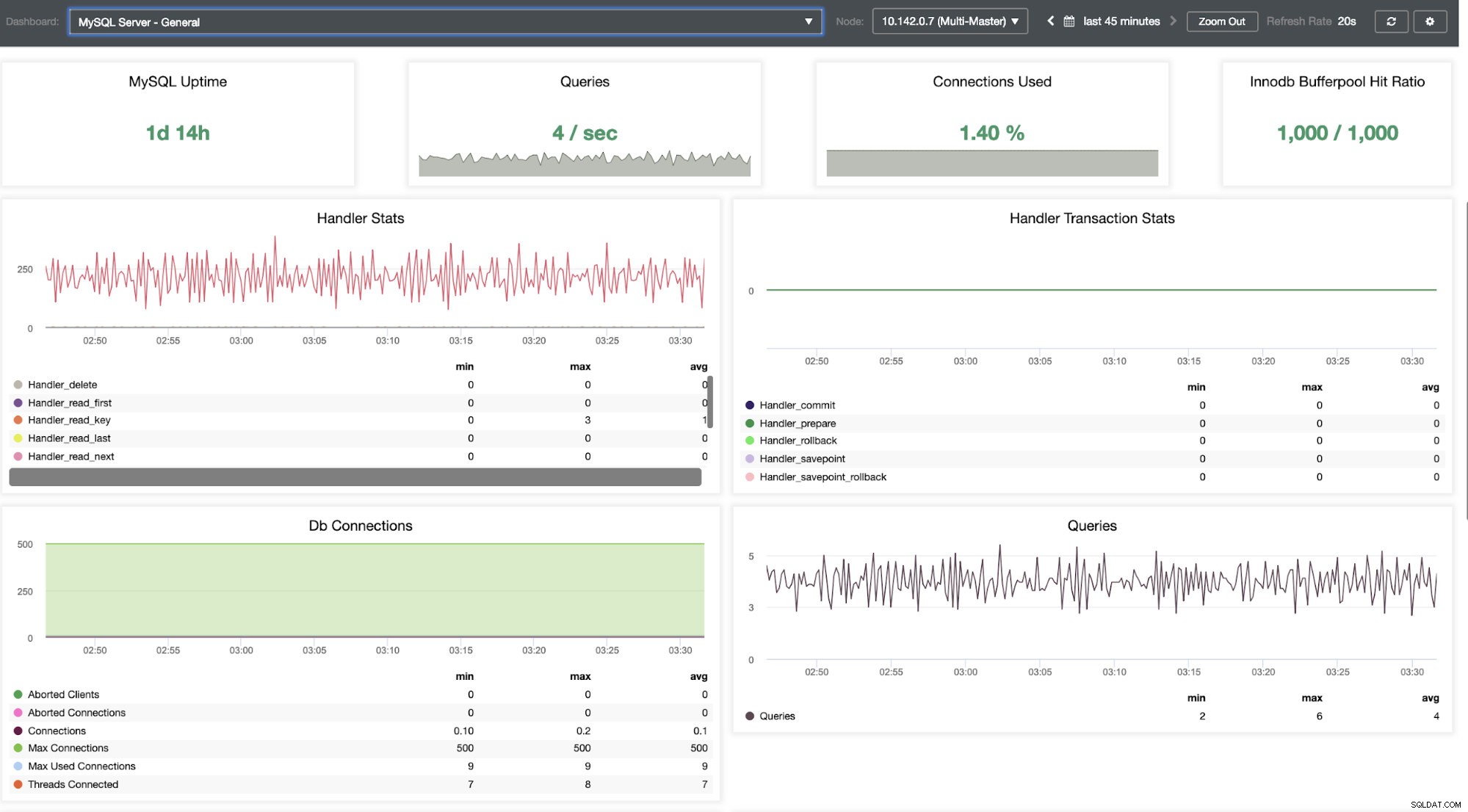
Il offre une expérience super fluide en termes de surveillance de vos nœuds.
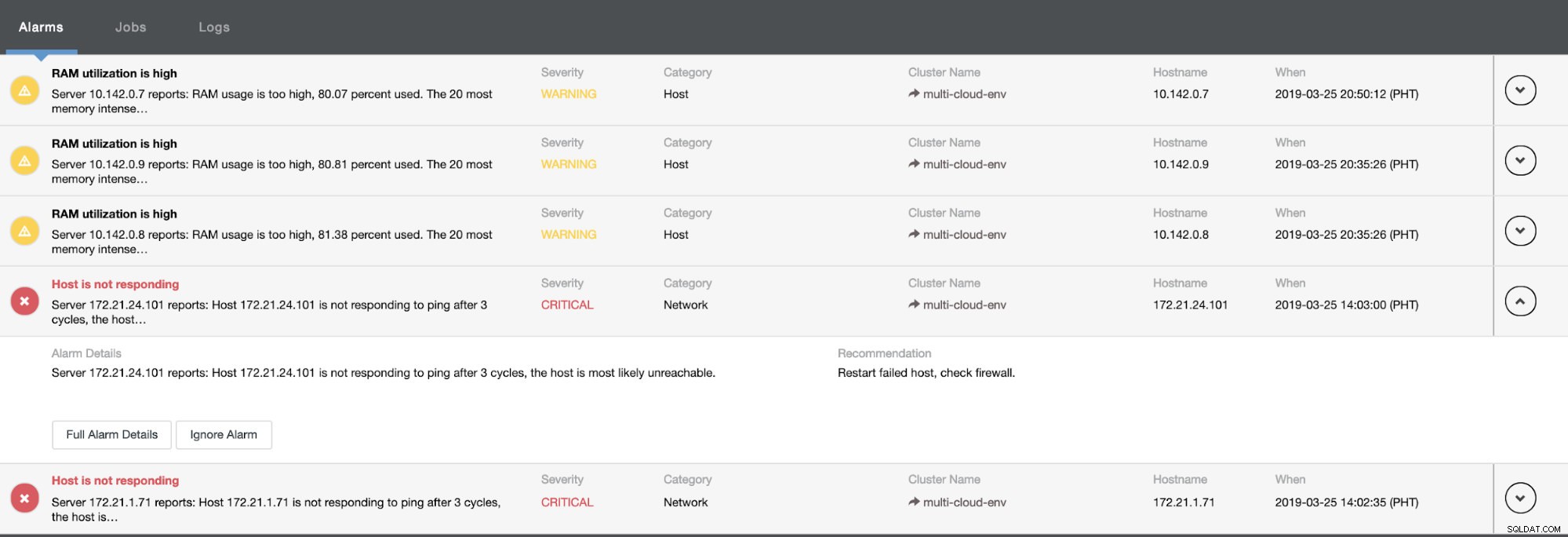
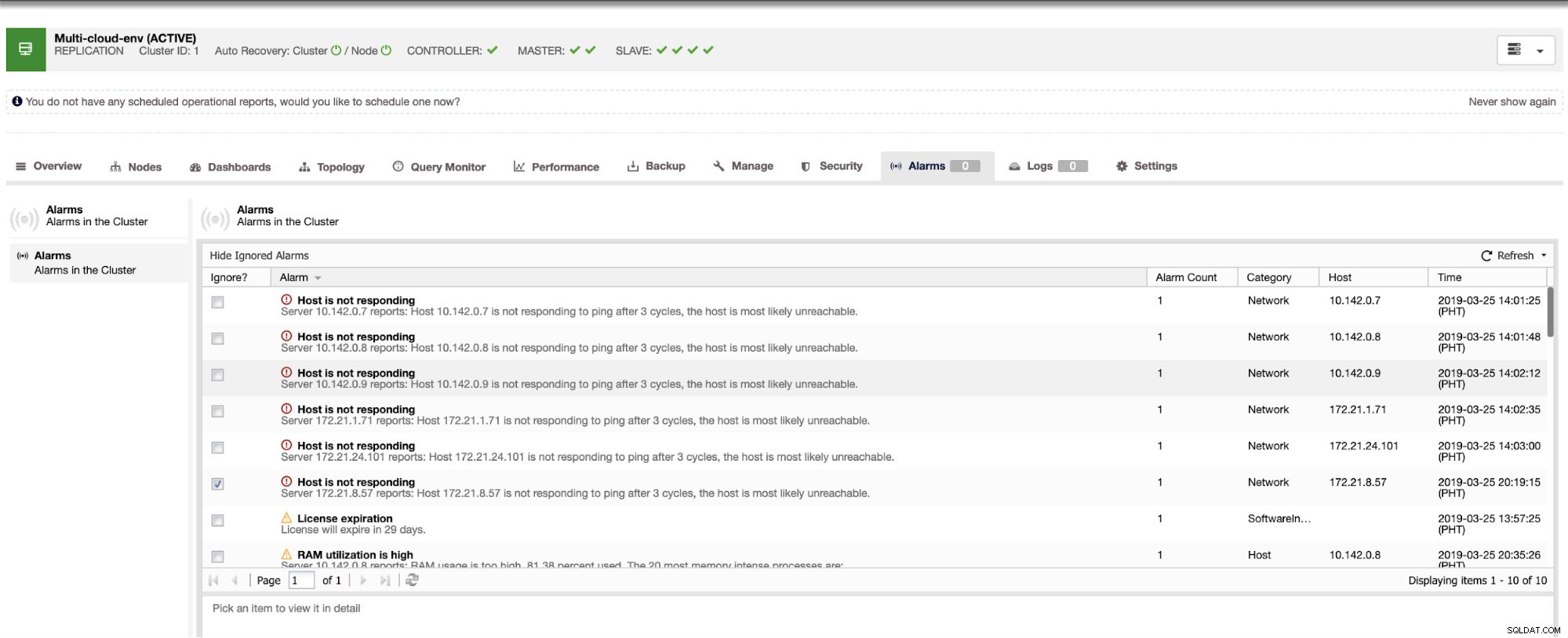
Il nous indique que l'utilisation est élevée ou que l'hôte ne répond pas. Même si ce n'était qu'un ping échec de réponse, vous pouvez ignorer l'alerte pour vous empêcher de la bombarder. Par conséquent, vous pouvez "désignorer" si nécessaire en allant dans Cluster -> Alarmes dans le Clustercontrol. Voir ci-dessous :
Gestion des pannes et exécution du basculement
Supposons que le nœud maître us-east1 est en panne ou nécessite une révision majeure en raison d'une mise à niveau du système ou du matériel. Disons que c'est la topologie en ce moment (voir l'image ci-dessous) :
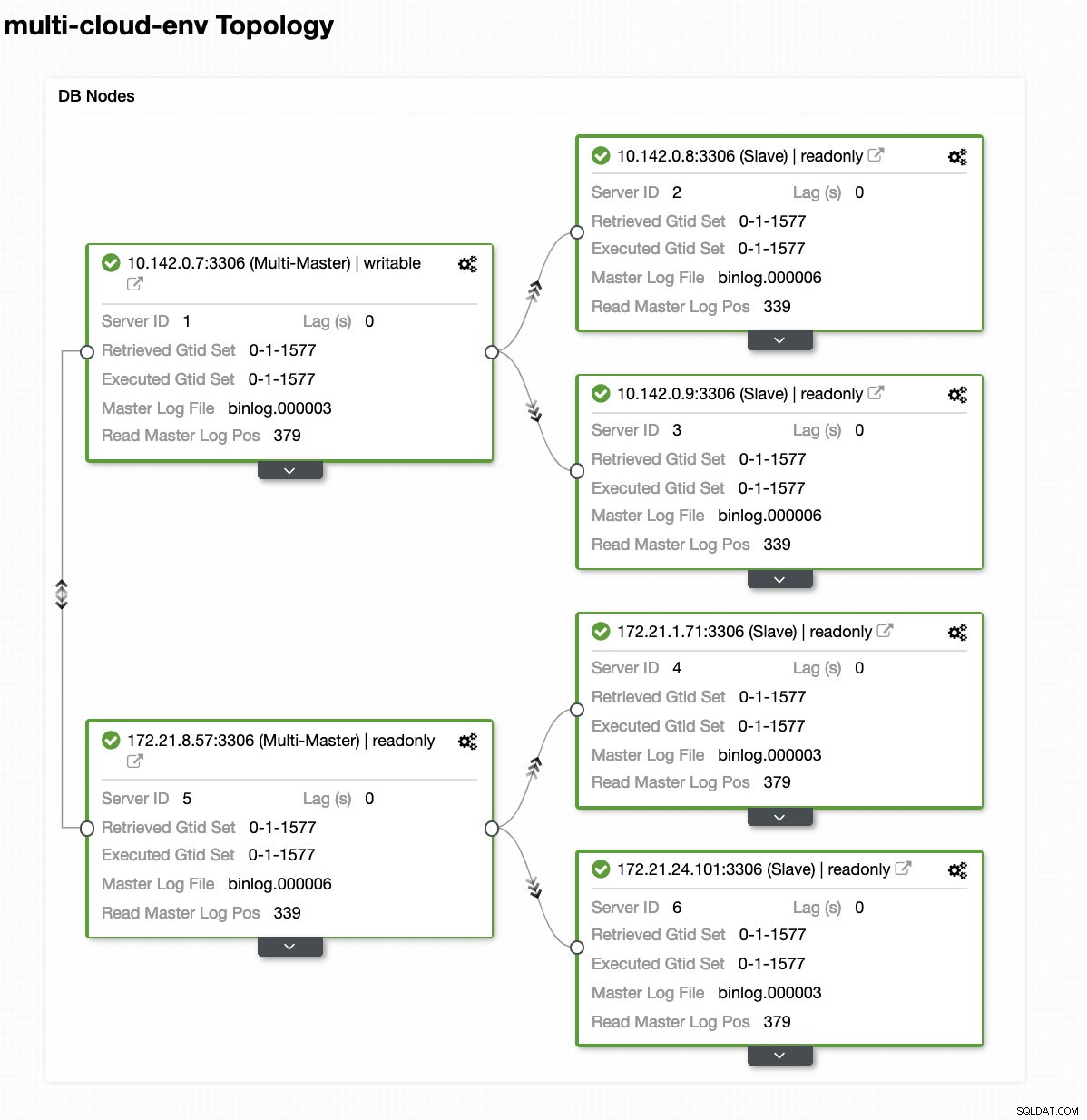
Essayons d'arrêter l'hôte 10.142.0.7 qui est le maître sous la région us-east1. Voir les captures d'écran ci-dessous comment ClusterControl réagit à cela :
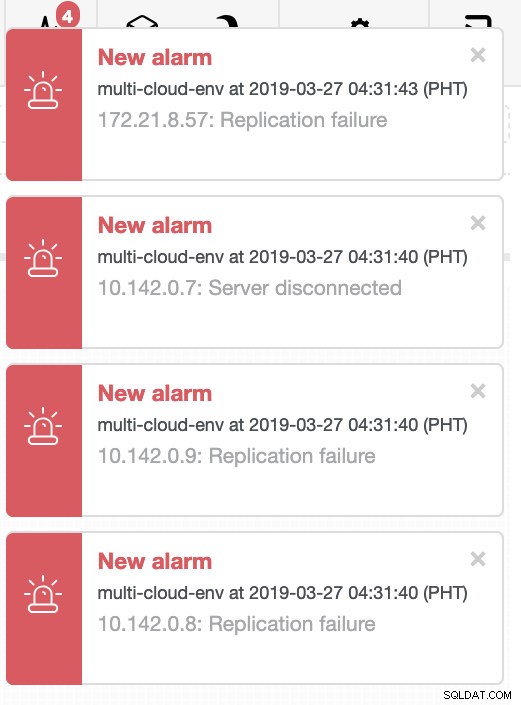
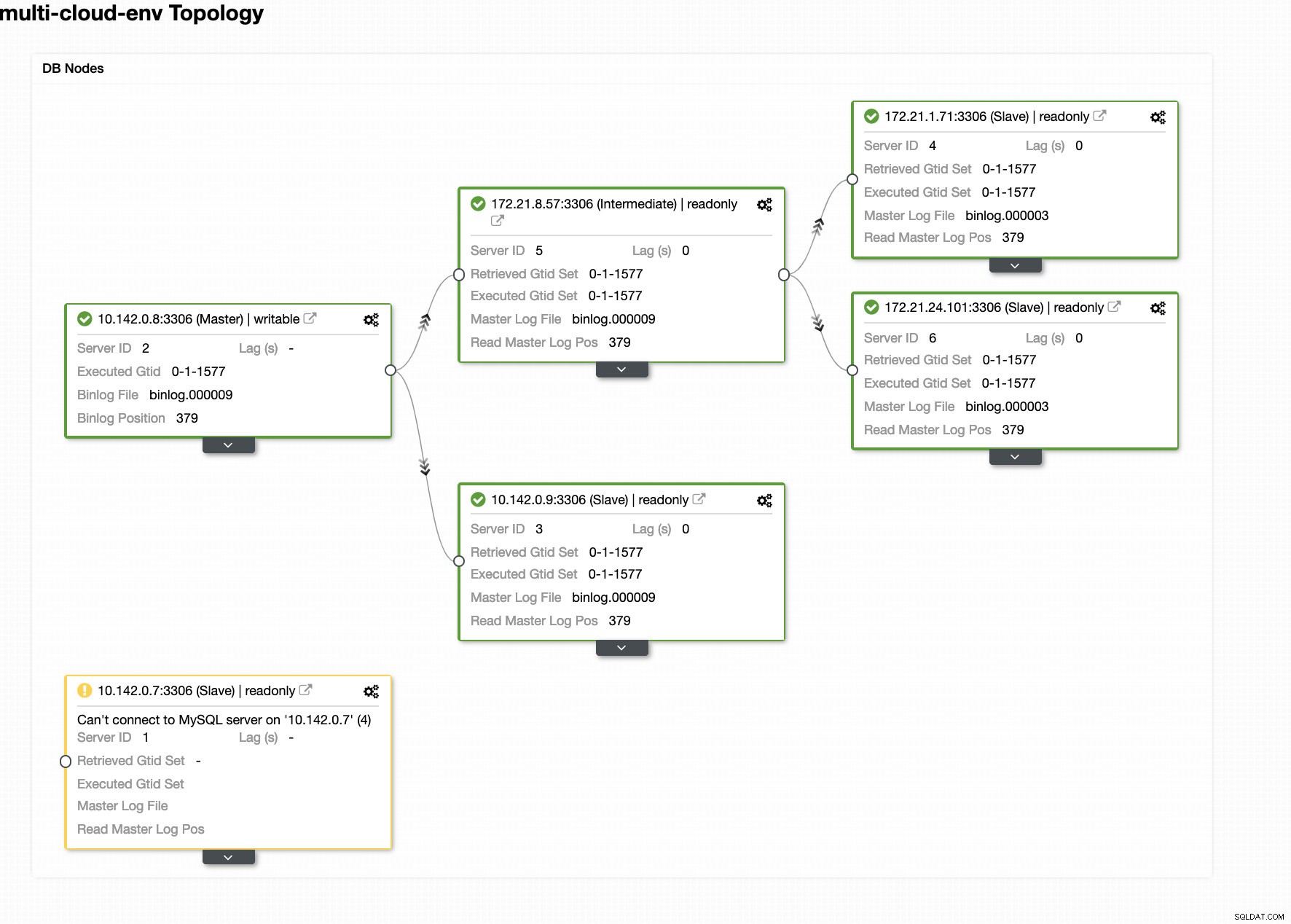
ClusterControl envoie des alarmes dès qu'il détecte des anomalies dans le cluster. Ensuite, il essaie de faire un basculement vers un nouveau maître en choisissant le bon candidat (voir image ci-dessous) :

Ensuite, il a mis de côté le maître défaillant qui a déjà été retiré du cluster (voir image ci-dessous) :
Ceci n'est qu'un aperçu de ce que ClusterControl peut faire, il existe d'autres fonctionnalités intéressantes telles que les sauvegardes, la surveillance des requêtes, le déploiement/la gestion des équilibreurs de charge, et bien d'autres !
Conclusion
La gestion de votre configuration de réplication MySQL dans un multicloud peut être délicate. Il faut faire très attention pour sécuriser notre configuration, donc j'espère que ce blog donne une idée sur la façon de définir les sous-réseaux et de protéger les nœuds de la base de données. Après la sécurité, il y a un certain nombre de choses à gérer et c'est là que ClusterControl peut être très utile.
Essayez-le maintenant et faites-nous savoir comment ça se passe. Vous pouvez nous contacter ici à tout moment.