La sauvegarde de la base de données est un élément essentiel de la gestion de la base de données et doit être soigneusement planifiée. Planifier une sauvegarde ne suffit pas, les données de sauvegarde doivent également être vérifiées pour leur cohérence et leur intégrité. Il existe d'autres considérations telles que le cryptage et l'archivage hors site. Un bon gestionnaire de sauvegarde aurait des fonctionnalités qui prennent en compte toutes ces différentes considérations.
Dans cet article de blog, nous allons examiner comment vous pouvez planifier vos sauvegardes de base de données avec ClusterControl.
Sauvegardes de bases de données à l'aide de ClusterControl
ClusterControl prend en charge un certain nombre de méthodes de sauvegarde en fonction du type de cluster, comme résumé dans le tableau suivant :
| Type de cluster | Méthode de sauvegarde prise en charge |
|---|---|
| MySQL (réplication, Galera, cluster NDB, réplication de groupe) |
|
| MongoDB (jeu de réplicas, cluster partagé) |
|
| PostgreSQL (réplication en continu) |
|
Lors de la planification d'une sauvegarde avec ClusterControl, chacune des méthodes de sauvegarde est configurable avec un ensemble d'options sur la façon dont vous souhaitez que la sauvegarde soit exécutée. Différentes charges de travail de base de données et stratégies de sauvegarde nécessiteraient la prise en charge de différentes fonctionnalités, par exemple :
- Limitation des IOPS de disque
- Limitation du réseau
- Verrouillages de sauvegarde
- Chiffrement
- Compression
- Période de conservation
- Vérification
ClusterControl définira automatiquement un certain nombre d'options de sauvegarde, en suivant les meilleures pratiques du fournisseur de base de données particulier. Par exemple, si le nœud de la base de données cible a un journal binaire activé, il ajoutera un indicateur supplémentaire, --master-data pour inclure les coordonnées binaires du journal (nom et position du fichier) du serveur vidé. S'il s'agit d'un nœud Galera et que la méthode de sauvegarde est xtrabackup, ClusterControl ajoutera un indicateur supplémentaire, --galera-info qui contient l'état du nœud local au moment de la sauvegarde.
Planifier une sauvegarde
Avant de planifier une sauvegarde, nous devons planifier comment l'opération de sauvegarde devrait être. Il serait utile de répondre aux exemples de questions suivants avant de créer une planification de sauvegarde :
- Quelle méthode de sauvegarde souhaitez-vous utiliser ? Certaines méthodes de sauvegarde sont non bloquantes, mais très gourmandes en ressources. Comprenez les compromis afin de ne pas être surpris du comportement du processus en production.
- À quelle fréquence souhaitez-vous sauvegarder vos bases de données ? L'exécution d'une sauvegarde complète peut être pénible si l'intervalle de sauvegarde est trop court. Vous avez probablement besoin d'un mélange de sauvegardes complètes et incrémentielles.
- À quelle vitesse souhaitez-vous restaurer vos données ? La sauvegarde physique est généralement beaucoup plus rapide que la sauvegarde logique en termes de temps de restauration complète. D'un autre côté, la sauvegarde logique est généralement plus rapide pour une restauration partielle.
- Quelle est la taille de vos données ? Dans certains cas, la sauvegarde logique n'est pas un bon choix pour les bases de données volumineuses, et la sauvegarde binaire est la seule solution.
- De combien d'espace libre disposez-vous pour stocker votre sauvegarde ? Les sauvegardes ont tendance à consommer beaucoup d'espace. Décidez si la compression est nécessaire et le niveau de compression que vous pouvez vous permettre. Une meilleure compression nécessite une utilisation plus importante du processeur.
- Que se passe-t-il si le serveur de sauvegarde est en panne pendant la période de sauvegarde ? Doit-il basculer la sauvegarde vers un autre hôte disponible ? Ignorer une sauvegarde en raison d'une fenêtre de maintenance n'est généralement pas une bonne idée.
- Comment garantir l'intégrité de la sauvegarde créée ? N'oubliez pas qu'une sauvegarde n'est pas une sauvegarde si elle n'est pas restaurable.
- Avez-vous confiance au stockage de sauvegarde ? Le chiffrement peut être une bonne idée pour protéger vos données.
Généralement, en répondant à ces questions, nous pouvons proposer une stratégie de sauvegarde appropriée. La liste des questions peut être plus longue en fonction de votre politique de sauvegarde et de restauration.
Nous avons couvert ce chapitre en détail dans notre livre blanc, Le guide DevOps des sauvegardes de bases de données pour MySQL et MariaDB.
Planification d'une sauvegarde
Avec ClusterControl, la planification est assez simple. Allez directement à Sauvegarder -> Créer une sauvegarde -> Programmer une sauvegarde et la boîte de dialogue suivante s'affichera :
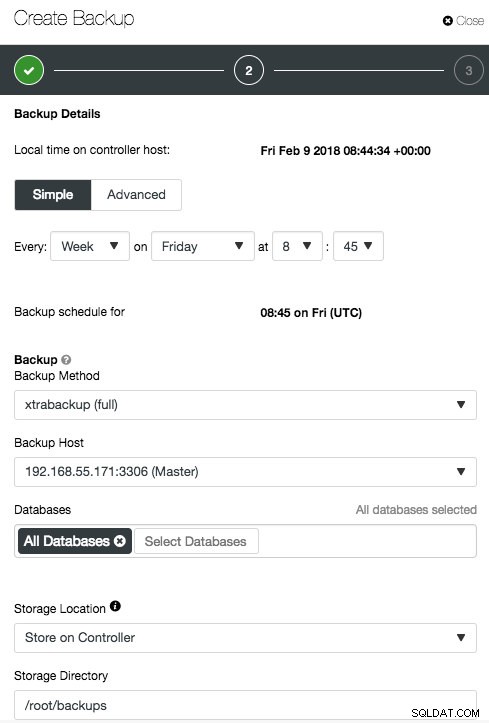
Selon le type de cluster, les options peuvent être différentes, comme illustré dans les captures d'écran suivantes pour PostgreSQL et MongoDB :
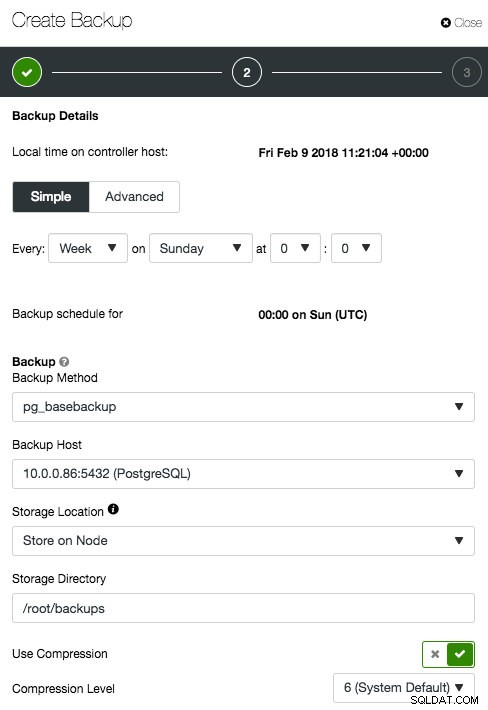 PostgreSQL
PostgreSQL 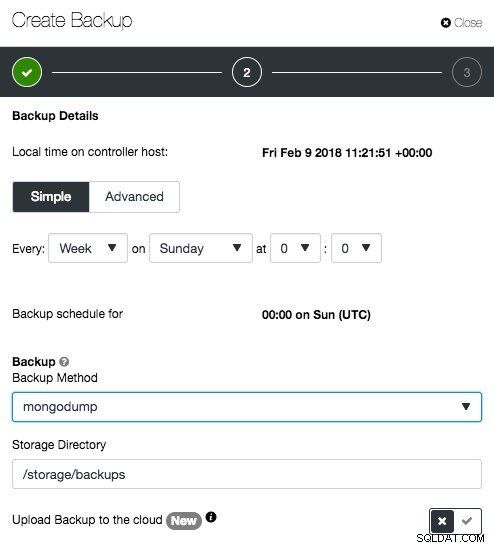 MongoDB
MongoDB La plupart des options sont explicites et sont décrites en détail dans le Guide de l'utilisateur. Une fois la planification créée, vous pouvez modifier les sauvegardes de configuration, activer/désactiver la sauvegarde ou supprimer la planification sous l'onglet "Sauvegardes planifiées" :

Prenez note lors de la planification de la sauvegarde avec ClusterControl, tout le temps doit être planifié dans le fuseau horaire UTC du serveur ClusterControl. La raison derrière cela est de couper la confusion du temps d'exécution de la sauvegarde. Lorsque vous travaillez avec un cluster, les serveurs de base de données peuvent être répartis dans différents fuseaux horaires et différentes zones géographiques. L'utilisation d'un fuseau horaire de référence pour tous les gérer garantira que les sauvegardes sont toujours exécutées au bon moment.
Vous pouvez surveiller la progression d'une sauvegarde en regardant Activité -> Travaux une fois le moment venu. Si la tâche de sauvegarde échouait, vous verriez immédiatement l'erreur :
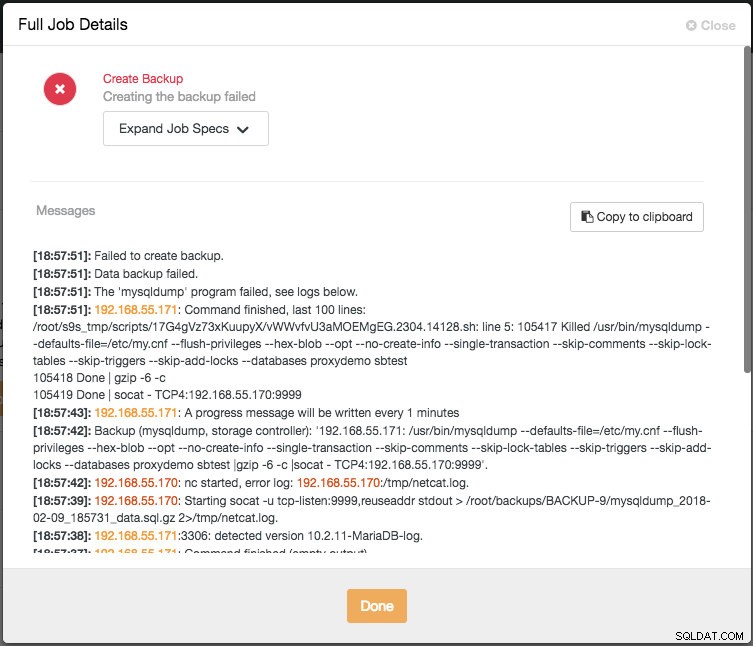
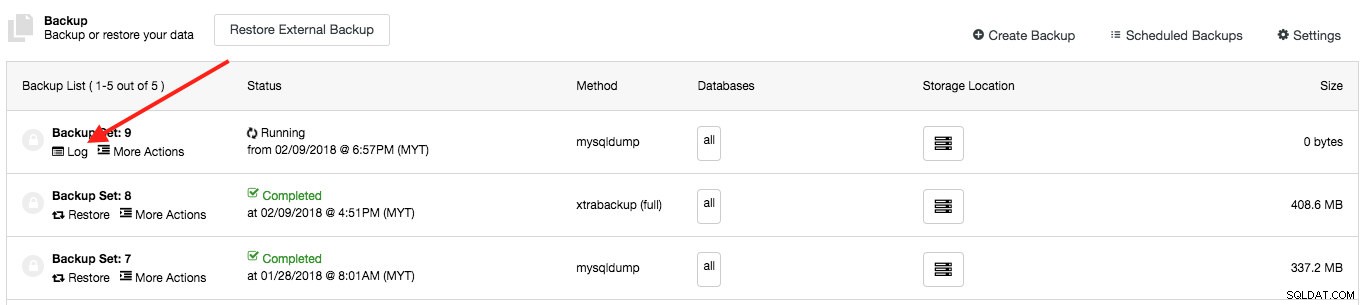
Le journal ci-dessus est également accessible sous l'onglet Sauvegarde sur chacune des entrées de sauvegarde :
Contrôles et vérification post-sauvegarde
Une fois le travail de sauvegarde terminé, cela ne signifie pas que votre responsabilité est terminée. Il y a quelques choses qui doivent être suivies. Le plus important est l'état de la sauvegarde créée. ClusterControl fournit des notifications par e-mail et vous informera de l'état. Ce service de notification est bien sûr configurable en fonction de la gravité sous Paramètres -> Paramètres généraux -> Paramètres des notifications par e-mail -> Sauvegarde :
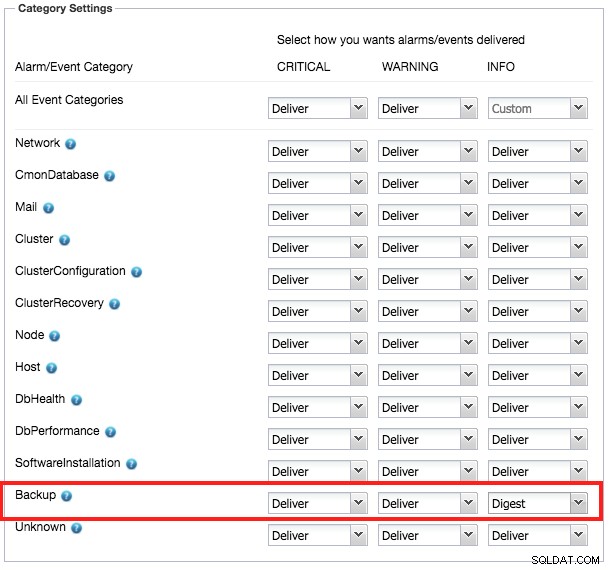
Livrer signifie que ClusterControl enverra une notification par e-mail immédiatement après le déclenchement d'une alarme pour ce composant. Vous pouvez également le configurer comme Ignore ou Digest, où ClusterControl envoie un résumé quotidien des alarmes déclenchées.
Si la sauvegarde est créée avec succès, il est fortement recommandé de vérifier si la sauvegarde est restaurable. Vous pouvez utiliser la fonction de vérification de sauvegarde en cliquant sur le bouton "Restaurer" de l'ID de sauvegarde choisi et vous serez présenté avec deux options de restauration :
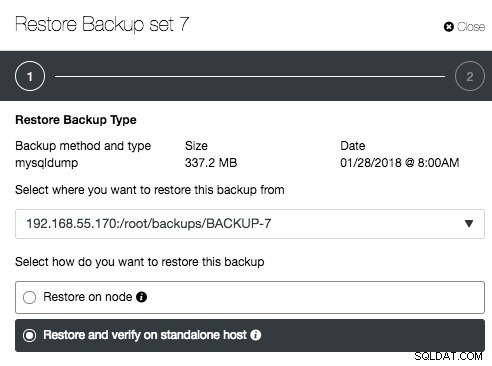
« Restauration et vérification sur un hôte autonome » nécessite un hôte distinct, qui ne fait pas déjà partie de la configuration de la base de données. ClusterControl va d'abord déployer une instance MySQL sur l'hôte cible, démarrer le service, copier la sauvegarde à partir du référentiel de sauvegarde et démarrer la restauration. Une fois cela fait, vous pouvez avoir la possibilité d'arrêter le serveur une fois restauré ou de le laisser fonctionner afin que vous puissiez mener une enquête plus approfondie sur le serveur.
Le ménage est également important afin de ne conserver que les sauvegardes utiles dans votre stockage. Ainsi, configurez la rétention de sauvegarde si nécessaire. Par défaut, ClusterControl purge les sauvegardes datant de plus de 30 jours. Vous pouvez également personnaliser chacune des planifications de sauvegarde avec différentes périodes de conservation.
Si le stockage de sauvegarde approche des limites d'espace, ou si vous souhaitez archiver votre sauvegarde hors jeu, vous pouvez choisir de supprimer manuellement le fichier en cliquant sur l'icône de la corbeille ou de le télécharger sur le cloud, comme indiqué ci-dessous :
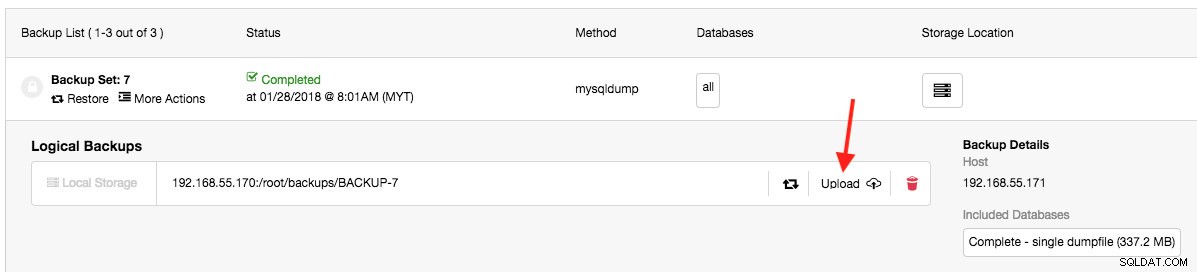
Au moment de la rédaction, AWS S3 et GCP Cloud Storage sont pris en charge. Les informations d'identification cloud doivent être préconfigurées dans le menu latéral -> Intégrations -> Fournisseurs cloud.
C'est tout, les amis. Bon regroupement !