Dans un blog précédent, nous avons annoncé une nouvelle fonctionnalité de ClusterControl 1.7.4 appelée Cluster-to-Cluster Replication. Il automatise l'ensemble du processus de configuration d'un cluster DR à partir de votre cluster principal, avec une réplication entre les deux. Pour des informations plus détaillées, veuillez vous référer à l'entrée de blog mentionnée ci-dessus.
Maintenant, dans ce blog, nous allons voir comment configurer cette nouvelle fonctionnalité pour un cluster existant. Pour cette tâche, nous supposerons que vous avez installé ClusterControl et que le cluster maître a été déployé à l'aide de celui-ci.
Exigences pour le cluster maître
Il y a certaines exigences pour que le cluster principal fonctionne :
- Percona XtraDB Cluster version 5.6.x et ultérieure, ou MariaDB Galera Cluster version 10.x et ultérieure.
- GTID activé.
- Journalisation binaire activée sur au moins un nœud de base de données.
- Les informations d'identification de sauvegarde doivent être les mêmes sur le cluster maître et le cluster esclave.
Préparer le cluster maître
Le cluster principal doit être prêt à utiliser cette nouvelle fonctionnalité. Il nécessite une configuration du côté de ClusterControl et de la base de données.
Configuration du contrôle de cluster
Dans le nœud de la base de données, vérifiez les informations d'identification de l'utilisateur de sauvegarde stockées dans /etc/my.cnf.d/secrets-backup.cnf (pour les systèmes d'exploitation basés sur RedHat) ou dans /etc/mysql/secrets-backup .cnf (pour les systèmes d'exploitation basés sur Debian).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElDans le nœud ClusterControl, modifiez le fichier de configuration /etc/cmon.d/cmon_ID.cnf (où ID est le numéro d'identification du cluster) et assurez-vous qu'il contient les mêmes informations d'identification stockées dans secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Toute modification de ce fichier nécessite un redémarrage du service cmon :
$ service cmon restartVérifiez les paramètres de réplication de la base de données pour vous assurer que le GTID et la journalisation binaire sont activés.
Configuration de la base de données
Dans le nœud de la base de données, vérifiez le fichier /etc/my.cnf (pour le système d'exploitation basé sur RedHat) ou /etc/mysql/my.cnf (pour le système d'exploitation basé sur Debian) pour voir la configuration liée au processus de réplication.
Percona XtraDB :
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Cluster MariaDB Galera :
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Au lieu de vérifier les fichiers de configuration, vous pouvez vérifier s'il est activé dans l'interface utilisateur de ClusterControl. Accédez à ClusterControl -> Sélectionnez Cluster -> Nœuds. Là, vous devriez avoir quelque chose comme ça :

Le rôle "Maître" ajouté dans le premier nœud signifie que la journalisation binaire est activé.
Activer la journalisation binaire
Si la journalisation binaire n'est pas activée, accédez à ClusterControl -> Sélectionnez Cluster -> Nœuds -> Actions de nœud -> Activer la journalisation binaire.
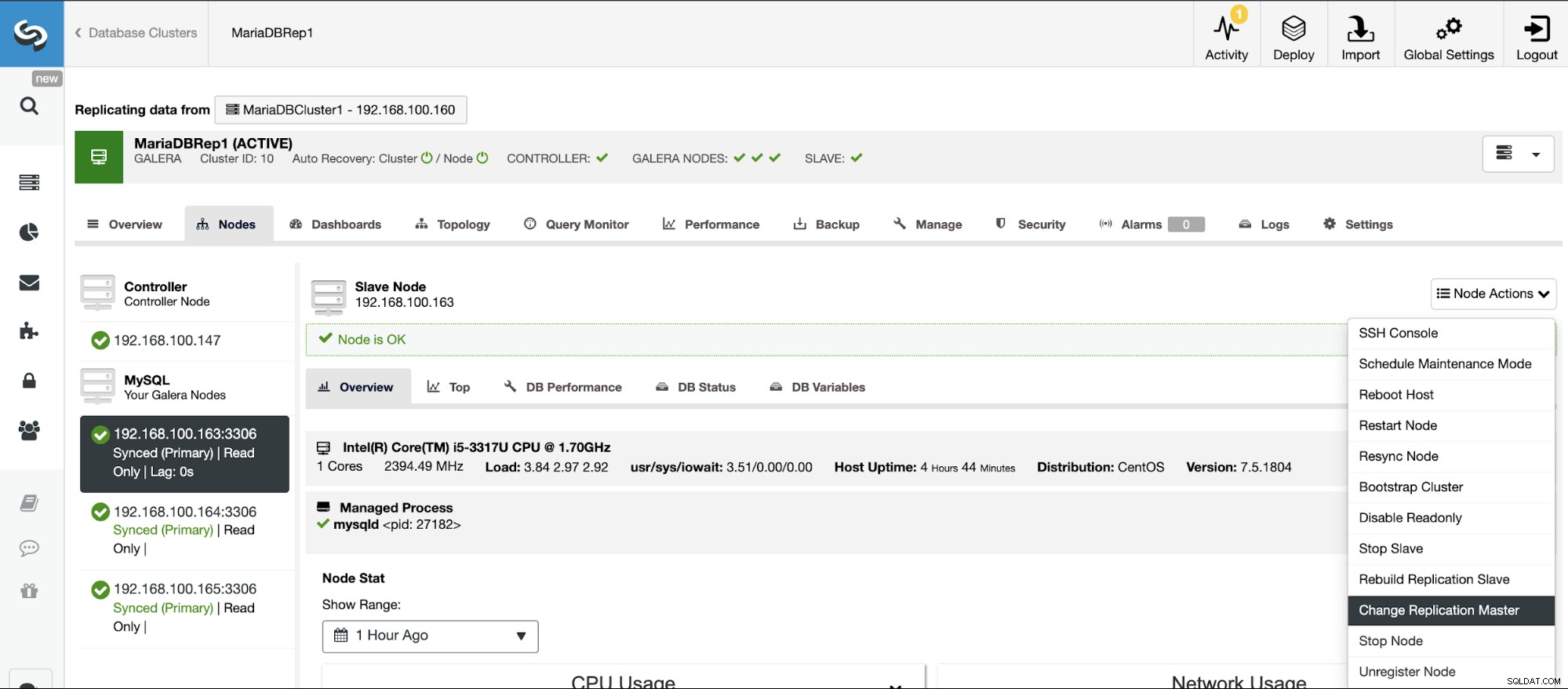
Ensuite, vous devez spécifier la rétention du journal binaire et le chemin de stockage ce. Vous devez également spécifier si vous souhaitez que ClusterControl redémarre le nœud de la base de données après l'avoir configuré, ou si vous préférez le redémarrer par vous-même.
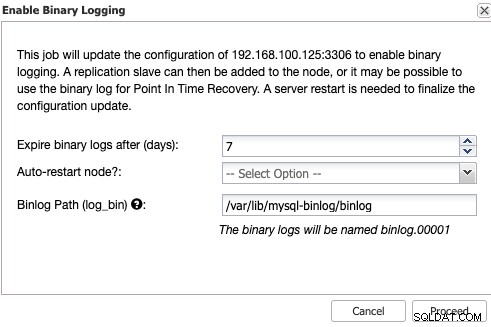
Gardez à l'esprit que l'activation de la journalisation binaire nécessite toujours un redémarrage du service de base de données .
Création du cluster esclave à partir de l'interface graphique ClusterControl
Pour créer un nouveau cluster esclave, accédez à ClusterControl -> Sélectionner un cluster -> Actions du cluster -> Créer un cluster esclave.
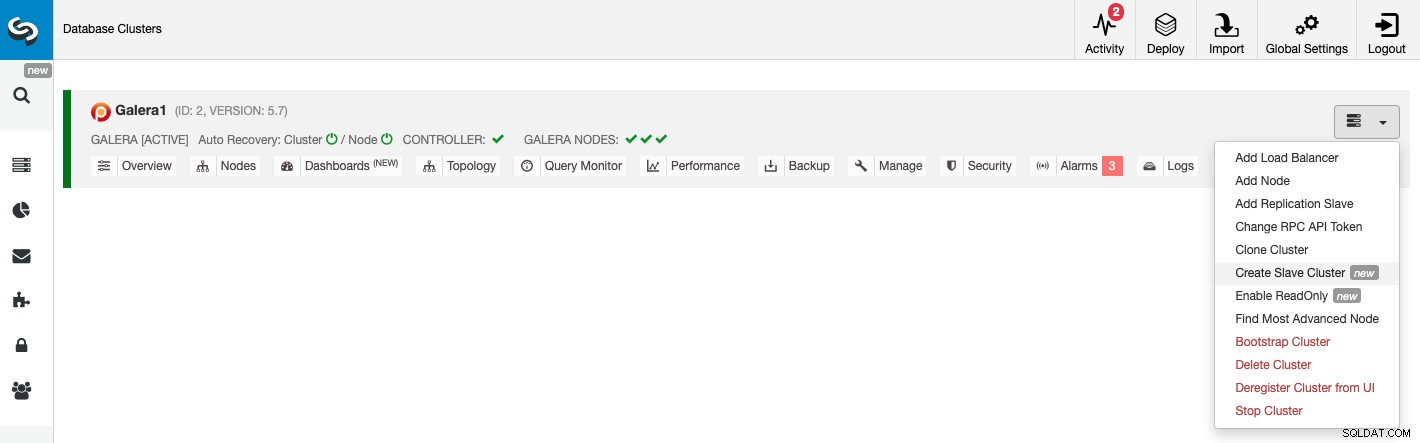
Le cluster esclave peut être créé en diffusant des données depuis le cluster maître actuel ou en utilisant une sauvegarde existante.
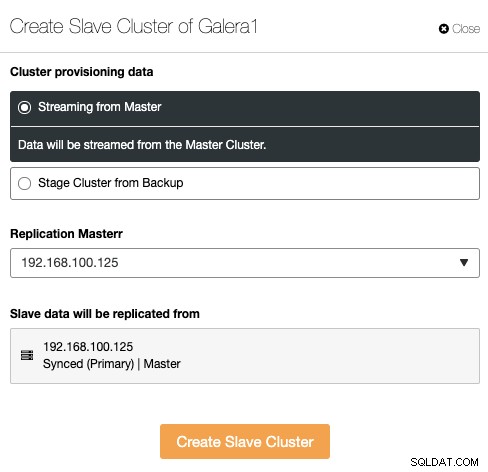
Dans cette section, vous devez également choisir le nœud maître du cluster actuel à partir duquel les données seront répliquées.
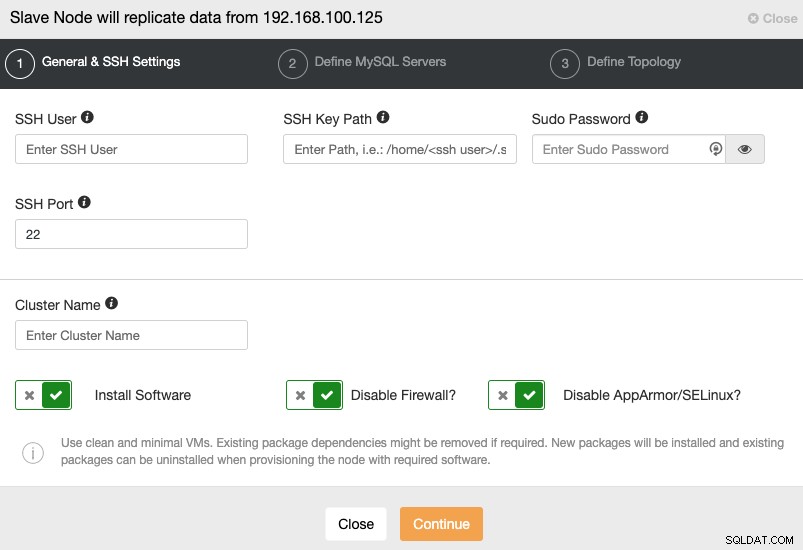
Lorsque vous passez à l'étape suivante, vous devez spécifier Utilisateur, Clé ou Mot de passe et port pour se connecter en SSH à vos serveurs. Vous avez également besoin d'un nom pour votre cluster esclave et si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
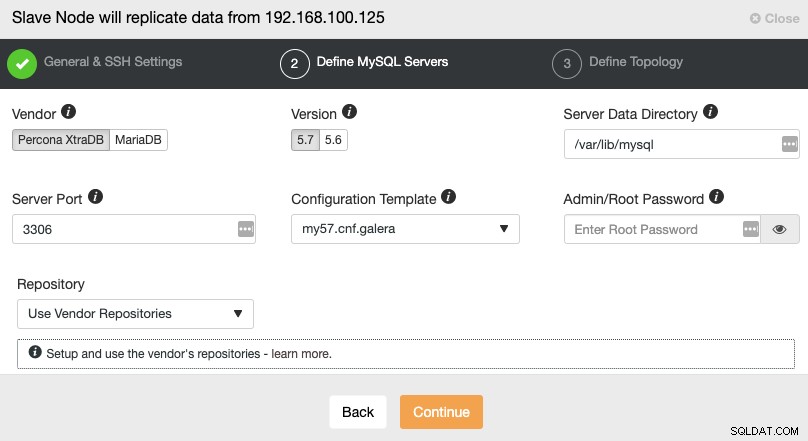
Après avoir configuré les informations d'accès SSH, vous devez définir le fournisseur de la base de données et version, datadir, port de la base de données et le mot de passe admin. Assurez-vous d'utiliser le même fournisseur/version et les mêmes informations d'identification que ceux utilisés par le cluster maître. Vous pouvez également spécifier le référentiel à utiliser.
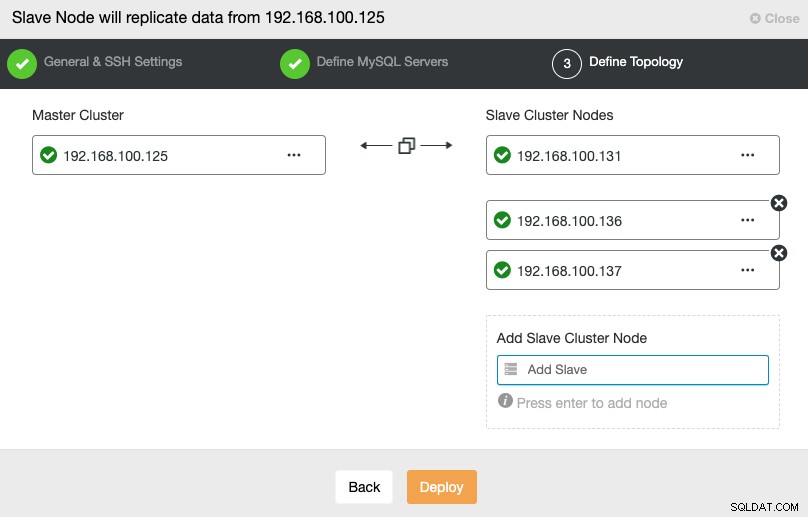
Dans cette étape, vous devez ajouter des serveurs au nouveau cluster esclave. Pour cette tâche, vous pouvez entrer à la fois l'adresse IP ou le nom d'hôte de chaque nœud de base de données.
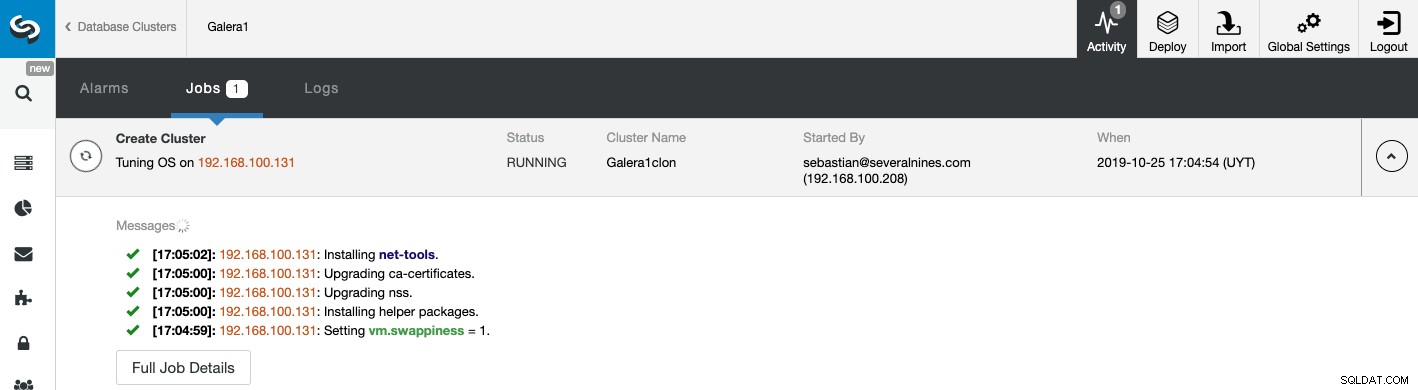
Vous pouvez surveiller l'état de la création de votre nouveau cluster esclave à partir du Moniteur d'activité ClusterControl. Une fois la tâche terminée, vous pouvez voir le cluster dans l'écran principal de ClusterControl.
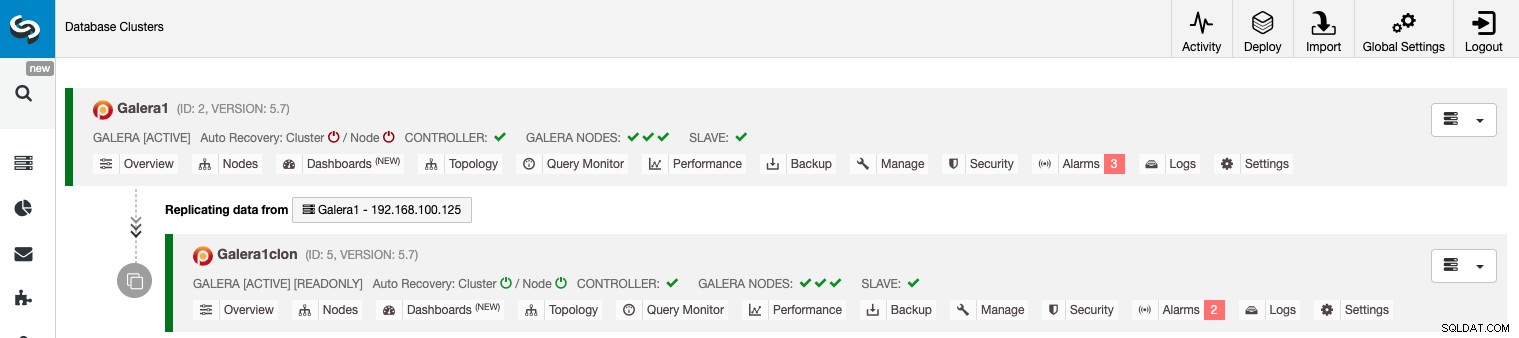
Gestion de la réplication de cluster à cluster à l'aide de l'interface graphique ClusterControl
Maintenant que votre réplication de cluster à cluster est opérationnelle, il y a différentes actions à effectuer sur cette topologie à l'aide de ClusterControl.
Configurer les clusters actifs-actifs
Comme vous pouvez le voir, par défaut, le cluster esclave est configuré en mode lecture seule. Il est possible de désactiver l'indicateur de lecture seule sur les nœuds un par un à partir de l'interface utilisateur de ClusterControl, mais gardez à l'esprit que le clustering actif-actif n'est recommandé que si les applications ne touchent que des ensembles de données disjoints sur l'un ou l'autre des clusters puisque MySQL/MariaDB ne le fait pas. offrir toute détection ou résolution de conflit.
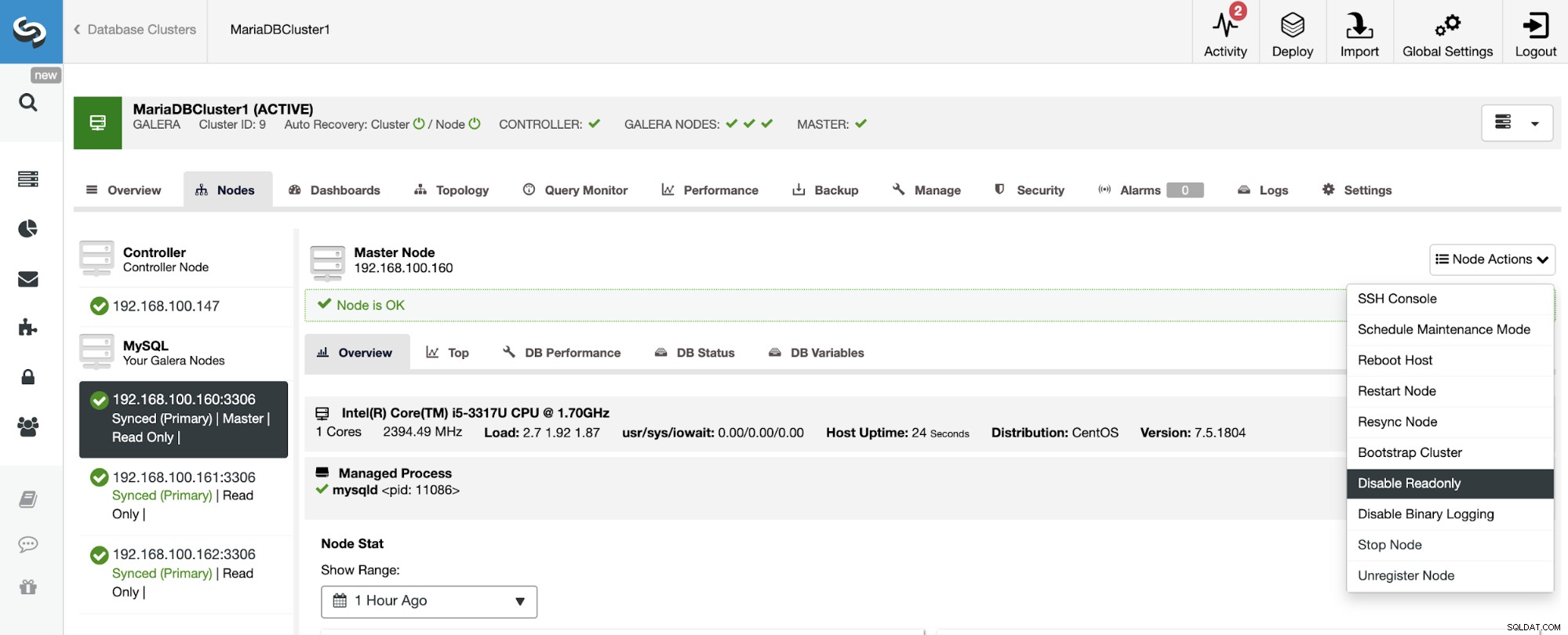
Pour désactiver le mode lecture seule, allez dans ClusterControl -> Select Slave Cluster -> Nœuds. Dans cette section, sélectionnez chaque nœud et utilisez l'option Désactiver la lecture seule.
Reconstruire un cluster esclave
Pour éviter les incohérences, si vous souhaitez reconstruire un cluster esclave, celui-ci doit être un cluster en lecture seule, cela signifie que tous les nœuds doivent être en mode lecture seule.
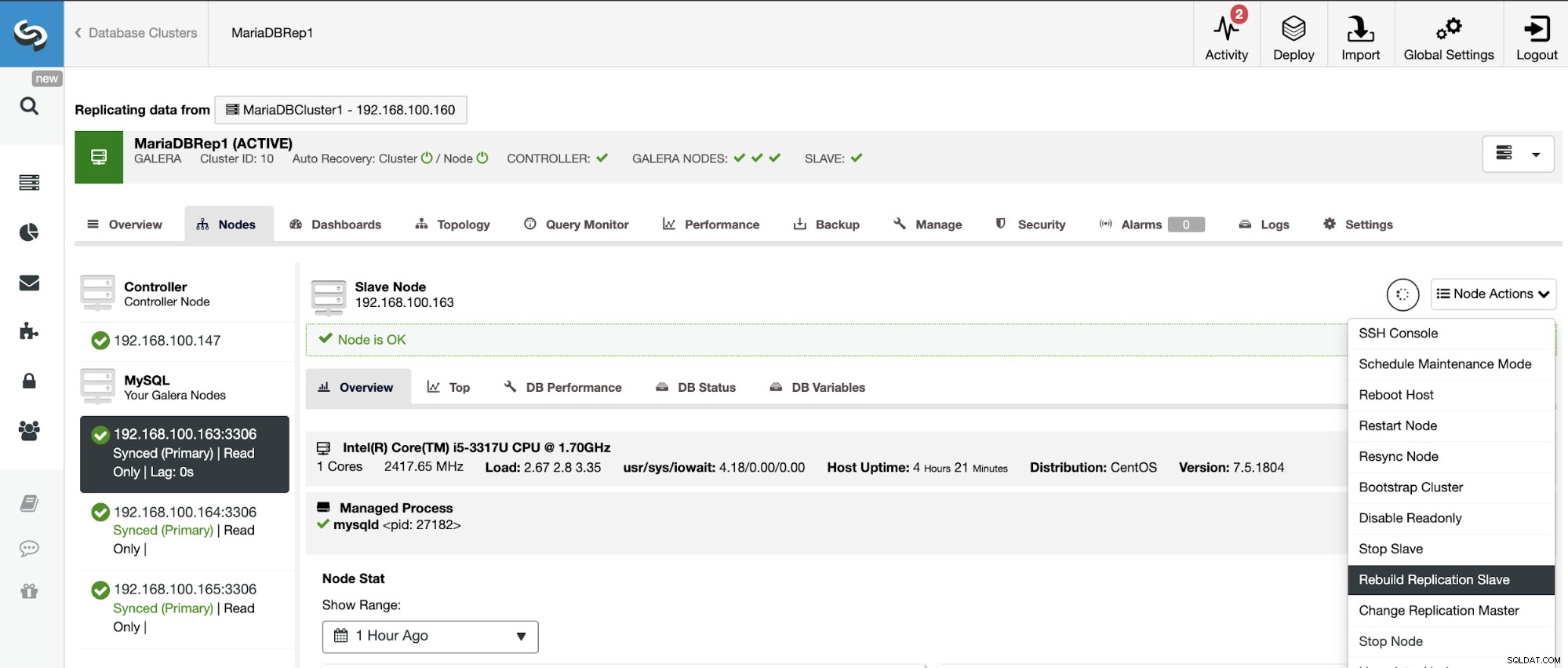
Allez dans ClusterControl -> Sélectionnez le cluster esclave -> Nœuds -> Choisissez le Nœud connecté au cluster maître -> Actions du nœud -> Reconstruire l'esclave de réplication.
Modifications de la topologie
Si vous avez la topologie suivante :
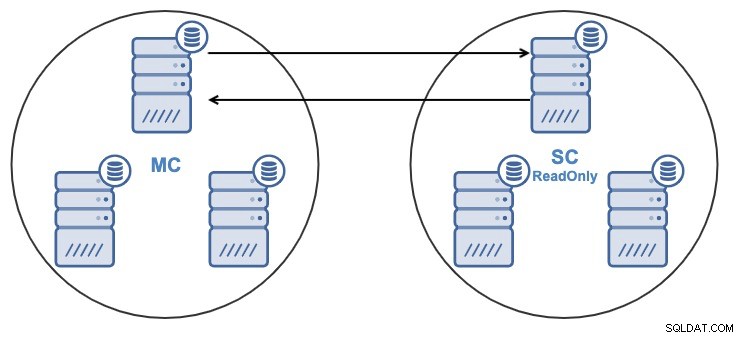
Et pour une raison quelconque, vous souhaitez modifier le nœud de réplication dans le maître Groupe. Il est possible de remplacer le nœud maître utilisé par le cluster esclave par un autre nœud maître du cluster maître.
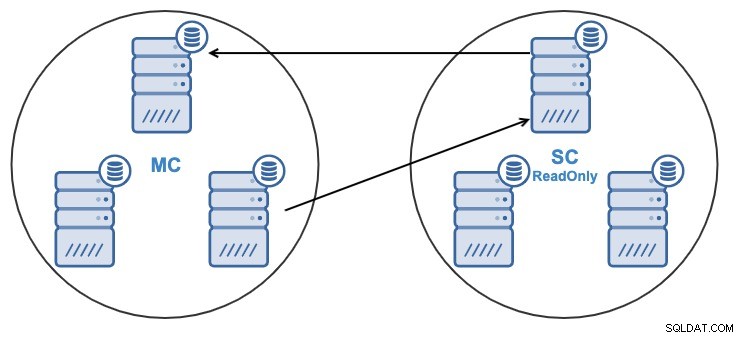
Pour être considéré comme un nœud maître, il doit avoir la journalisation binaire activée .
Allez dans ClusterControl -> Sélectionnez le cluster esclave -> Nœuds -> Choisissez le Nœud connecté au cluster maître -> Actions du nœud -> Arrêter l'esclave/Démarrer l'esclave.
Arrêter/Démarrer l'esclave de réplication
Vous pouvez arrêter et démarrer facilement les esclaves de réplication à l'aide de ClusterControl.
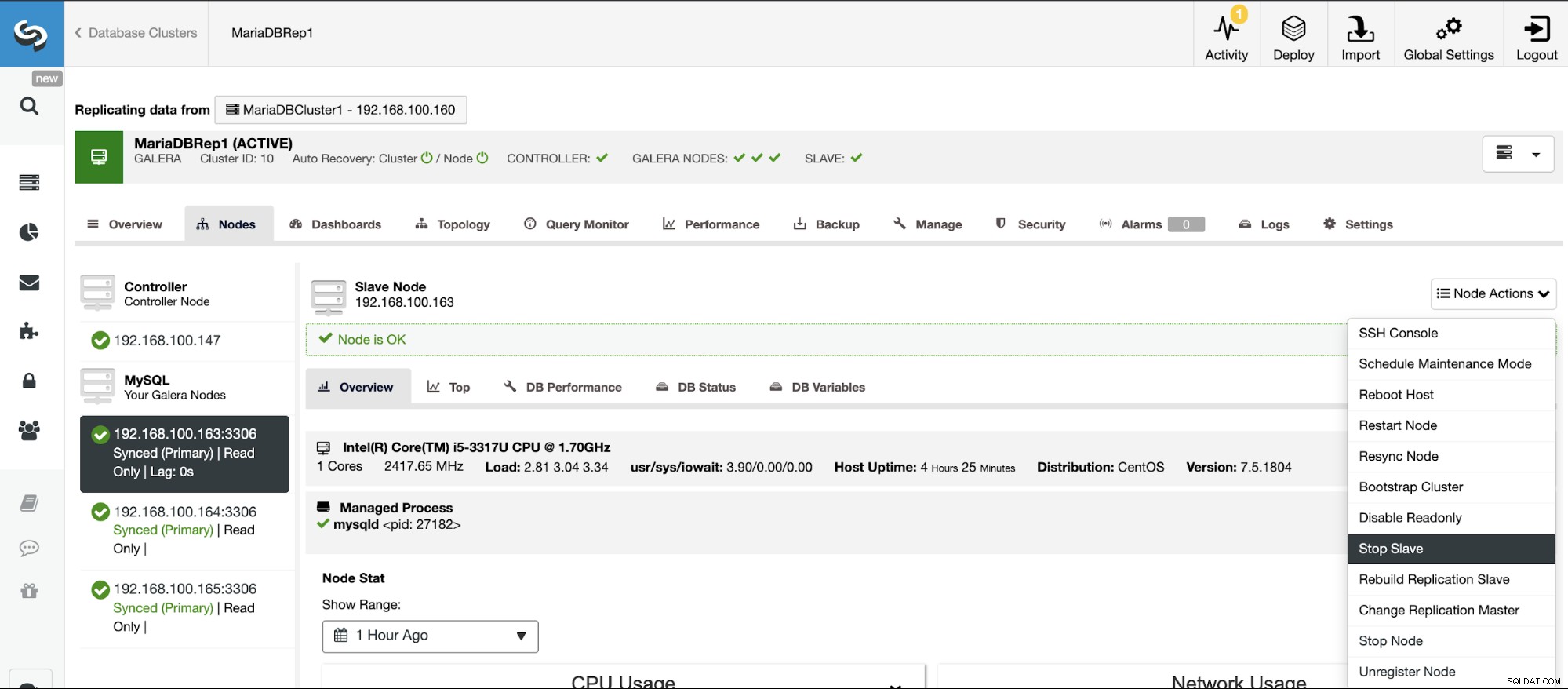
Allez dans ClusterControl -> Sélectionnez le cluster esclave -> Nœuds -> Choisissez le Nœud connecté au cluster maître -> Actions du nœud -> Arrêter l'esclave/Démarrer l'esclave.
Réinitialiser l'esclave de réplication
Avec cette action, vous pouvez réinitialiser le processus de réplication en utilisant RESET SLAVE ou RESET SLAVE ALL. La différence entre eux est que RESET SLAVE ne modifie aucun paramètre de réplication comme l'hôte maître, le port et les informations d'identification. Pour supprimer ces informations, vous devez utiliser RESET SLAVE ALL qui supprime toute la configuration de réplication, donc en utilisant cette commande, le lien de réplication cluster à cluster sera détruit.
Avant d'utiliser cette fonctionnalité, vous devez arrêter le processus de réplication (veuillez vous reporter à la fonctionnalité précédente).
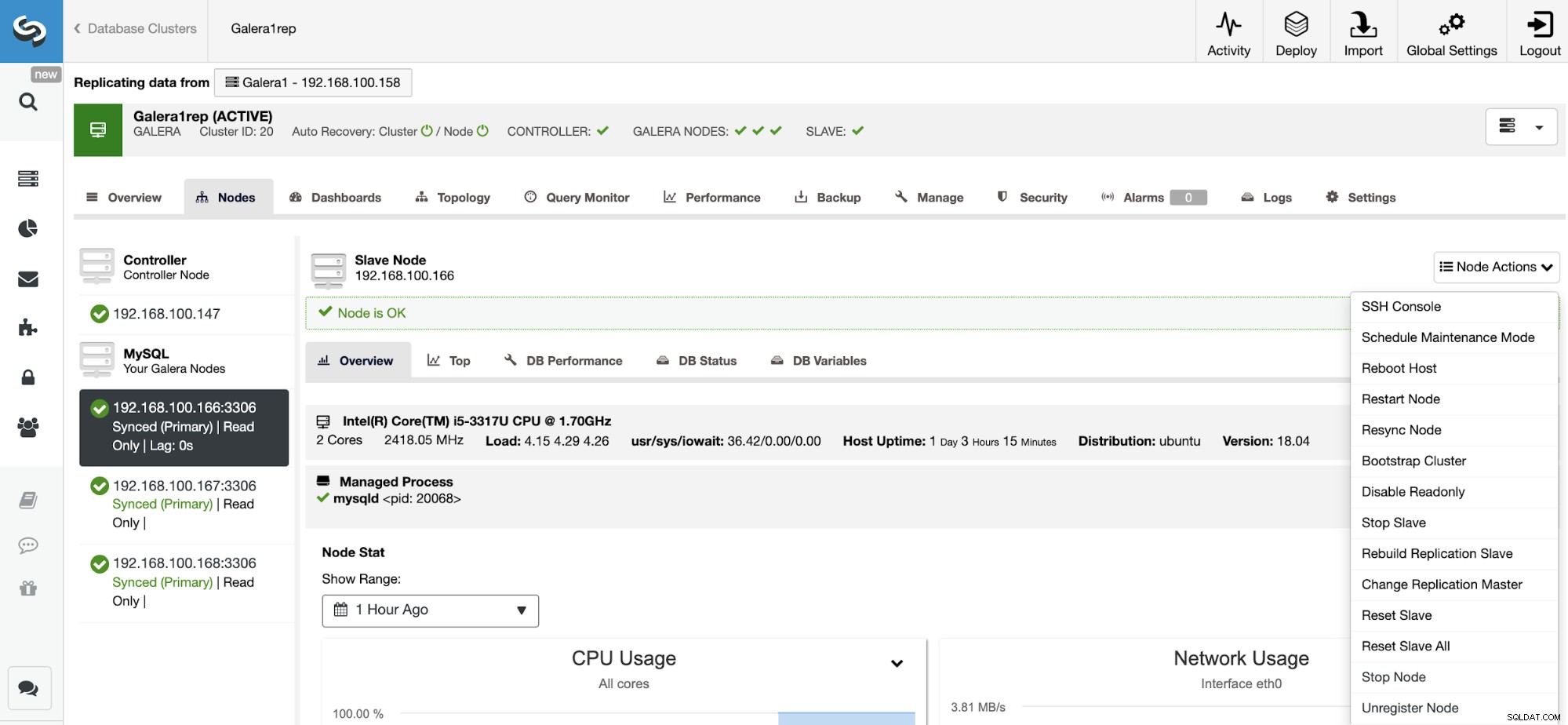
Allez dans ClusterControl -> Sélectionnez le cluster esclave -> Nœuds -> Choisissez le Nœud connecté au cluster maître -> Actions du nœud -> Réinitialiser l'esclave/Réinitialiser tout l'esclave.
Gestion de la réplication de cluster à cluster à l'aide de l'interface de ligne de commande ClusterControl
Dans la section précédente, vous avez pu voir comment gérer une réplication de cluster à cluster à l'aide de l'interface utilisateur de ClusterControl. Voyons maintenant comment le faire en utilisant la ligne de commande.
Remarque :comme nous l'avons mentionné au début de ce blog, nous supposerons que vous avez installé ClusterControl et que le cluster principal a été déployé à l'aide de celui-ci.
Créer le cluster esclave
Tout d'abord, voyons un exemple de commande pour créer un cluster esclave à l'aide de la CLI ClusterControl :
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logMaintenant que votre processus de création d'esclave est en cours d'exécution, voyons chaque paramètre utilisé :
- Cluster :pour répertorier et manipuler les clusters.
- Créer :créez et installez un nouveau cluster.
- Cluster-name :le nom du nouveau cluster esclave.
- Cluster-type :le type de cluster à installer.
- Provider-version :la version du logiciel.
- Nœuds :liste des nouveaux nœuds du cluster esclave.
- Os-user :le nom d'utilisateur pour les commandes SSH.
- Os-key-file :fichier de clé à utiliser pour la connexion SSH.
- Db-admin :le nom d'utilisateur de l'administrateur de la base de données.
- Db-admin-passwd :le mot de passe de l'administrateur de la base de données.
- Remote-cluster-id :ID de cluster maître pour la réplication de cluster à cluster.
- Journal :attendez et surveillez les messages de tâche.
En utilisant le drapeau --log, vous pourrez voir les journaux en temps réel :
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Configurer les clusters actifs-actifs
Comme vous avez pu le voir précédemment, vous pouvez désactiver le mode Lecture seule dans le nouveau cluster en le désactivant dans chaque nœud, voyons donc comment le faire depuis la ligne de commande.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logVoyons chaque paramètre :
- Nœud :pour gérer les nœuds.
- Set-read-write :configurez le nœud en mode lecture-écriture.
- Nœuds :le nœud où le modifier.
- Cluster-id :ID du cluster dans lequel se trouve le nœud.
Ensuite, vous verrez :
192.168.100.166:3306: Setting read_only=OFF.Reconstruire un cluster esclave
Vous pouvez reconstruire un cluster esclave à l'aide de la commande suivante :
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logLes paramètres sont :
- Réplication :pour surveiller et contrôler la réplication des données.
- Étape :étape/reconstruction d'un esclave de réplication.
- Maître :maître de réplication dans le cluster maître.
- Esclave :l'esclave de réplication dans le cluster esclave.
- Cluster-id :l'ID du cluster esclave.
- Remote-cluster-id :l'ID du cluster principal.
- Journal :attendez et surveillez les messages de tâche.
Le journal des tâches doit ressembler à celui-ci :
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Modifications de la topologie
Vous pouvez modifier votre topologie en utilisant un autre nœud du cluster maître à partir duquel répliquer les données, par exemple, vous pouvez exécuter :
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logVérifions les paramètres utilisés.
- Réplication :pour surveiller et contrôler la réplication des données.
- Basculement :prendre le rôle de maître à partir d'un ancien maître défaillant.
- Maître :le nouveau maître de réplication dans le cluster maître.
- Esclave :l'esclave de réplication dans le cluster esclave.
- Cluster-id :ID du cluster esclave.
- Remote-Cluster-id :ID du cluster maître.
- Journal :attendez et surveillez les messages de tâche.
Vous verrez ce journal :
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Arrêter/Démarrer l'esclave de réplication
Vous pouvez arrêter de répliquer les données du cluster maître de cette manière :
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logVous verrez ceci :
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.Et maintenant, vous pouvez le redémarrer :
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logDonc, vous verrez :
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Maintenant, vérifions les paramètres utilisés.
- Réplication :pour surveiller et contrôler la réplication des données.
- Stop/Start :pour que l'esclave arrête/démarre la réplication.
- Esclave :le nœud esclave de réplication.
- Cluster-id :ID du cluster dans lequel se trouve le nœud esclave.
- Journal :attendez et surveillez les messages de tâche.
Réinitialiser l'esclave de réplication
A l'aide de cette commande, vous pouvez réinitialiser le processus de réplication en utilisant RESET SLAVE ou RESET SLAVE ALL. Pour plus d'informations sur cette commande, veuillez vérifier son utilisation dans la section précédente de l'interface utilisateur de ClusterControl.
Avant d'utiliser cette fonctionnalité, vous devez arrêter le processus de réplication (veuillez vous reporter à la commande précédente).
RÉINITIALISER L'ESCLAVE :
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logLe journal devrait ressembler à :
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.RÉINITIALISER TOUT ESCLAVE :
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logEt ce journal devrait être :
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Voyons les paramètres utilisés pour RESET SLAVE et RESET SLAVE ALL.
- Réplication :pour surveiller et contrôler la réplication des données.
- Réinitialiser :réinitialisez le nœud esclave.
- Forcer :en utilisant cet indicateur, vous utiliserez la commande RESET SLAVE ALL sur le nœud esclave.
- Esclave :le nœud esclave de réplication.
- Cluster-id :l'ID du cluster esclave.
- Journal :attendez et surveillez les messages de tâche.
Conclusion
Cette nouvelle fonctionnalité ClusterControl vous permettra de créer rapidement une réplication de cluster à cluster et de la gérer de manière simple et conviviale. Cet environnement améliorera la topologie de votre base de données/cluster et serait utile pour un plan de reprise après sinistre, un environnement de test et encore plus d'options mentionnées dans le blog de présentation.