Il y a quelques années (au pgconf.eu 2014 à Madrid), j'ai présenté une conférence intitulée "Performance Archaeology" qui a montré comment les performances ont changé dans les dernières versions de PostgreSQL. J'ai fait ce discours car je pense que la vision à long terme est intéressante et peut nous donner des idées qui peuvent être très précieuses. Pour les personnes qui travaillent réellement sur du code PostgreSQL comme moi, c'est un guide utile pour le développement futur, et pour les utilisateurs de PostgreSQL, cela peut aider à évaluer les mises à niveau.
J'ai donc décidé de répéter cet exercice et d'écrire quelques articles de blog analysant les performances de plusieurs versions de PostgreSQL. Lors de la conférence de 2014, j'ai commencé avec PostgreSQL 7.4, qui avait alors environ 10 ans (sorti en 2003). Cette fois, je vais commencer avec PostgreSQL 8.3, qui a environ 12 ans.
Pourquoi ne pas recommencer avec PostgreSQL 7.4 ? Il y a environ trois raisons principales pour lesquelles j'ai décidé de commencer avec PostgreSQL 8.3. Premièrement, la paresse générale. Plus la version est ancienne, plus il peut être difficile de construire en utilisant les versions actuelles du compilateur, etc. Deuxièmement, il faut du temps pour exécuter des benchmarks appropriés, en particulier avec de grandes quantités de données, donc l'ajout d'une seule version majeure peut facilement ajouter quelques jours de temps machine. Cela ne semblait tout simplement pas en valoir la peine. Et enfin, la 8.3 a introduit un certain nombre de changements importants – améliorations de l'autovacuum (activé par défaut, processus de travail simultanés, …), recherche en texte intégral intégrée au noyau, répartition des points de contrôle, etc. Je pense donc qu'il est parfaitement logique de commencer avec PostgreSQL 8.3. Qui a été publié il y a environ 12 ans, donc cette comparaison couvrira en fait une plus longue période.
J'ai décidé de comparer trois types de charge de travail de base :OLTP, analytique et recherche en texte intégral. Je pense que l'OLTP et l'analyse sont des choix assez évidents, car la plupart des applications sont un mélange de ces deux types de base. La recherche en texte intégral me permet de démontrer des améliorations dans des types d'index spéciaux, qui sont également utilisés pour indexer des types de données populaires comme JSONB, des types utilisés par PostGIS, etc.
Pourquoi faire ça ?
Est-ce que ça vaut vraiment le coup ? Après tout, nous faisons tout le temps des benchmarks pendant le développement pour montrer qu'un patch aide et/ou qu'il ne provoque pas de régressions, n'est-ce pas ? Le problème est qu'il ne s'agit généralement que de benchmarks "partiels", comparant deux commits particuliers, et généralement avec une sélection assez limitée de charges de travail que nous pensons pertinentes. Ce qui est parfaitement logique :vous ne pouvez tout simplement pas exécuter une batterie complète de charges de travail pour chaque validation.
De temps en temps (généralement peu de temps après la publication d'une nouvelle version majeure de PostgreSQL), des personnes effectuent des tests comparant la nouvelle version à la précédente, ce qui est agréable et je vous encourage à exécuter de tels benchmarks (que ce soit une sorte de benchmark standard, ou quelque chose de spécifique à votre application). Mais il est difficile de combiner ces résultats dans une vision à plus long terme, car ces tests utilisent des configurations et du matériel différents (généralement un plus récent pour la nouvelle version), etc. Il est donc difficile de porter des jugements clairs sur les changements en général.
Il en va de même pour les performances applicatives, qui sont bien sûr la « référence ultime ». Mais les gens ne peuvent pas mettre à niveau vers toutes les versions majeures (parfois, ils peuvent sauter quelques versions, par exemple de 9.5 à 12). Et lorsqu'elles sont mises à niveau, elles sont souvent combinées avec des mises à niveau matérielles, etc. Sans compter que les applications évoluent avec le temps (nouvelles fonctionnalités, complexité supplémentaire), que les quantités de données et le nombre d'utilisateurs simultanés augmentent, etc.
C'est ce que cette série de blogs essaie de montrer - les tendances à long terme des performances de PostgreSQL pour certaines charges de travail de base, afin que nous, les développeurs, obtenions une impression chaleureuse et floue du bon travail au fil des ans. Et pour montrer aux utilisateurs que même si PostgreSQL est un produit mature à ce stade, il y a encore des améliorations significatives dans chaque nouvelle version majeure.
Ce n'est pas mon objectif d'utiliser ces repères pour la comparaison avec d'autres produits de base de données, ou de produire des résultats pour répondre à un classement officiel (comme celui de TPC-H). Mon objectif est simplement de me former en tant que développeur PostgreSQL, peut-être d'identifier et d'étudier certains problèmes, et de partager les résultats avec d'autres.
Comparaison juste ?
Je ne pense pas que de telles comparaisons de versions publiées sur 12 ans ne puissent pas être tout à fait justes, car tout logiciel est développé dans un contexte particulier - le matériel est un bon exemple, pour un système de base de données. Si vous regardez les machines que vous utilisiez il y a 12 ans, combien de cœurs avaient-elles, combien de RAM ? Quel type de stockage ont-ils utilisé ?
Un serveur de milieu de gamme typique en 2008 avait peut-être 8 à 12 cœurs, 16 Go de RAM et un RAID avec quelques disques SAS. Aujourd'hui, un serveur de milieu de gamme typique peut avoir quelques dizaines de cœurs, des centaines de Go de RAM et un stockage SSD.
Le développement de logiciels est organisé par priorité - il y a toujours plus de tâches potentielles que vous n'en avez le temps, vous devez donc choisir des tâches avec le meilleur rapport coût/bénéfice pour vos utilisateurs (en particulier ceux qui financent le projet, directement ou indirectement). Et en 2008, certaines optimisations n'étaient probablement pas encore pertinentes - la plupart des machines n'avaient pas de quantités extrêmes de RAM, donc l'optimisation pour les grands tampons partagés n'en valait pas encore la peine, par exemple. Et de nombreux goulots d'étranglement du processeur ont été éclipsés par les E/S, car la plupart des machines disposaient d'un stockage « rouillé ».
Remarque :Bien sûr, certains clients utilisaient déjà de très grosses machines à l'époque. Certains ont utilisé la communauté Postgres avec divers ajustements, d'autres ont décidé de fonctionner avec l'une des différentes fourches Postgres avec des capacités supplémentaires (par exemple, parallélisme massif, requêtes distribuées, utilisation de FPGA, etc.). Et cela a également influencé le développement de la communauté, bien sûr.
Au fur et à mesure que les machines plus grandes devenaient plus courantes au fil des ans, davantage de personnes pouvaient s'offrir des machines avec de grandes quantités de RAM et un nombre élevé de cœurs, ce qui modifiait le rapport coût/bénéfice. Les goulots d'étranglement ont été étudiés et résolus, permettant aux nouvelles versions de mieux fonctionner.
Cela signifie qu'un benchmark comme celui-ci est toujours un peu injuste - il favorisera l'ancienne ou la nouvelle version, selon la configuration (matériel, configuration). J'ai essayé de choisir le matériel et les paramètres de configuration pour que ce ne soit pas trop mauvais pour les anciennes versions.
Le point que j'essaie de faire valoir est que cela ne signifie pas que les anciennes versions de PostgreSQL étaient de la merde - c'est ainsi que fonctionne le développement de logiciels. Vous résolvez les goulots d'étranglement que vos utilisateurs sont susceptibles de rencontrer, et non ceux qu'ils pourraient rencontrer dans 10 ans.
Matériel
Je préfère faire des benchmarks sur du matériel physique auquel j'ai un accès direct, car cela me permet de contrôler tous les détails, j'ai accès à tous les détails, etc. J'ai donc utilisé la machine que j'ai dans notre bureau - rien d'extraordinaire, mais j'espère assez bon pour cet usage.
- 2x E5-2620 v4 (16 cœurs, 32 threads)
- 64 Go de RAM
- SSD Intel Optane 900P 280 Go NVMe (données)
- 3 x 7.2k SATA RAID0 (tablespace temporaire)
- noyau 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
J'ai également utilisé une deuxième machine - beaucoup plus petite -, avec seulement 4 cœurs et 8 Go de RAM, qui montre généralement les mêmes améliorations/régressions, juste moins prononcées.
pgbench
En tant qu'outil d'analyse comparative, j'ai utilisé le pgbench bien connu, en utilisant la version la plus récente (de PostgreSQL 13) pour tester toutes les versions. Cela élimine les biais possibles dus aux optimisations effectuées dans pgbench au fil du temps, ce qui rend les résultats plus comparables.
Le benchmark teste un certain nombre de cas différents, faisant varier un certain nombre de paramètres, à savoir :
échelle
- petit – les données tiennent dans des tampons partagés, ce qui montre des problèmes de verrouillage, etc.
- moyen :données plus volumineuses que les tampons partagés, mais qui tiennent dans la RAM, généralement liées au processeur (ou éventuellement aux E/S pour les charges de travail en lecture-écriture)
- grand – données plus volumineuses que la RAM, principalement liées aux E/S
modes
- lecture seule – pgbench -S
- lecture-écriture – pgbench -N
nombre de clients
- 1, 4, 8, 16, 32, 64, 128, 256
- le nombre de threads pgbench (-j) est modifié en conséquence
Résultats
OK, regardons les résultats. Je vais d'abord présenter les résultats du stockage NVMe, puis je montrerai des résultats intéressants en utilisant le stockage RAID SATA.
SSD NVMe / lecture seule
Pour le petit ensemble de données (qui tient entièrement dans les tampons partagés), les résultats en lecture seule ressemblent à ceci :
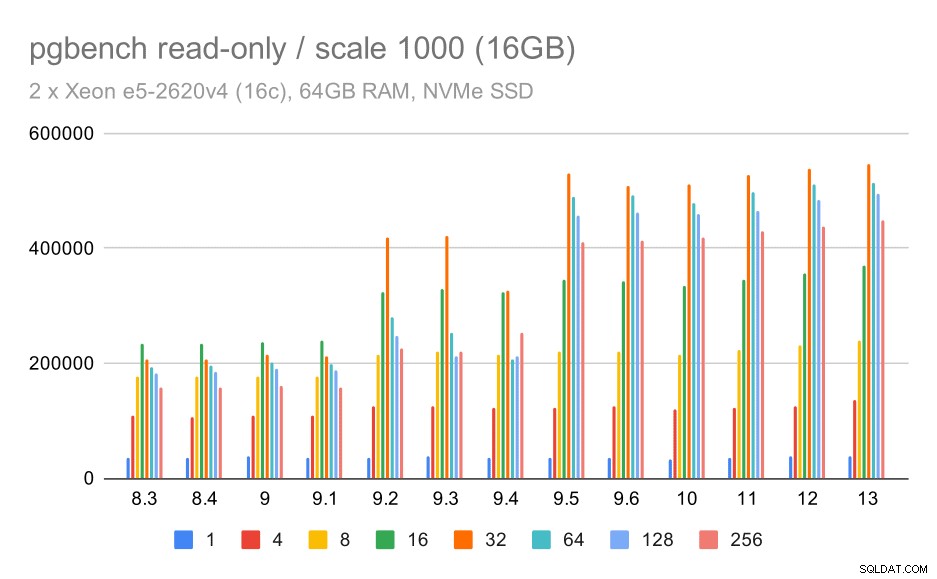
résultats de pgbench / en lecture seule sur un petit ensemble de données (échelle 100, soit 1,6 Go)
De toute évidence, il y a eu une augmentation significative du débit dans la version 9.2, qui contenait un certain nombre d'améliorations des performances, par exemple le raccourci pour le verrouillage. Le débit pour un seul client chute un peu – de 47 000 tps à seulement 42 000 tps environ. Mais pour un nombre de clients plus élevé, l'amélioration de la version 9.2 est assez claire.
résultats pgbench / lecture seule sur un jeu de données moyen (échelle 1000, soit 16 Go)
Pour l'ensemble de données moyen (qui est plus volumineux que les tampons partagés mais tient toujours dans la RAM), il semble également y avoir une amélioration dans 9.2, bien que pas aussi claire que ci-dessus, suivie d'une amélioration beaucoup plus nette dans 9.5, probablement grâce aux améliorations de l'évolutivité du verrouillage .
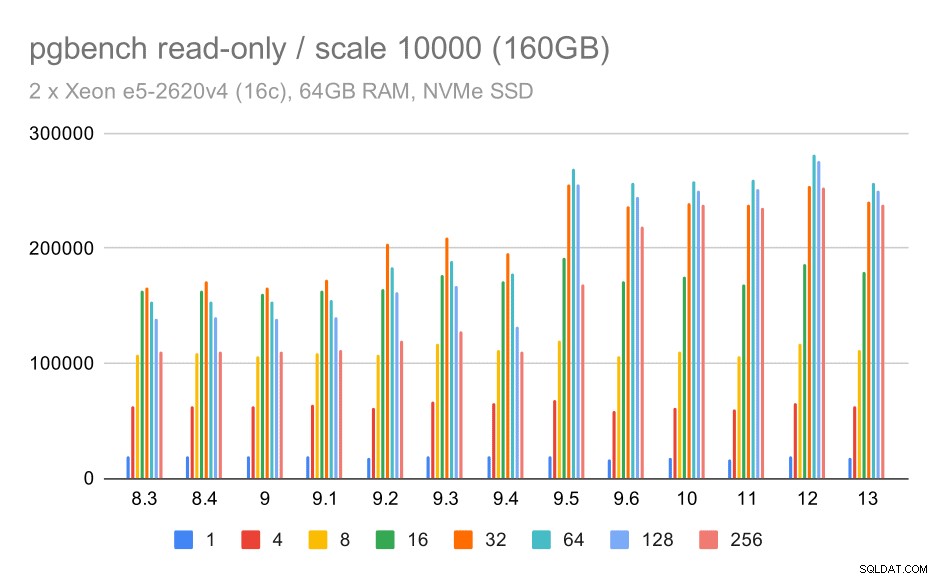
résultats pgbench / en lecture seule sur un grand ensemble de données (échelle 10000, soit 160 Go)
Sur le plus grand ensemble de données, qui concerne principalement la capacité à utiliser efficacement le stockage, il y a aussi une certaine accélération - probablement grâce aux améliorations de la 9.5 également.
SSD NVMe / lecture-écriture
Les résultats de lecture-écriture montrent également quelques améliorations, bien que moins prononcées. Sur le petit ensemble de données, les résultats ressemblent à ceci :
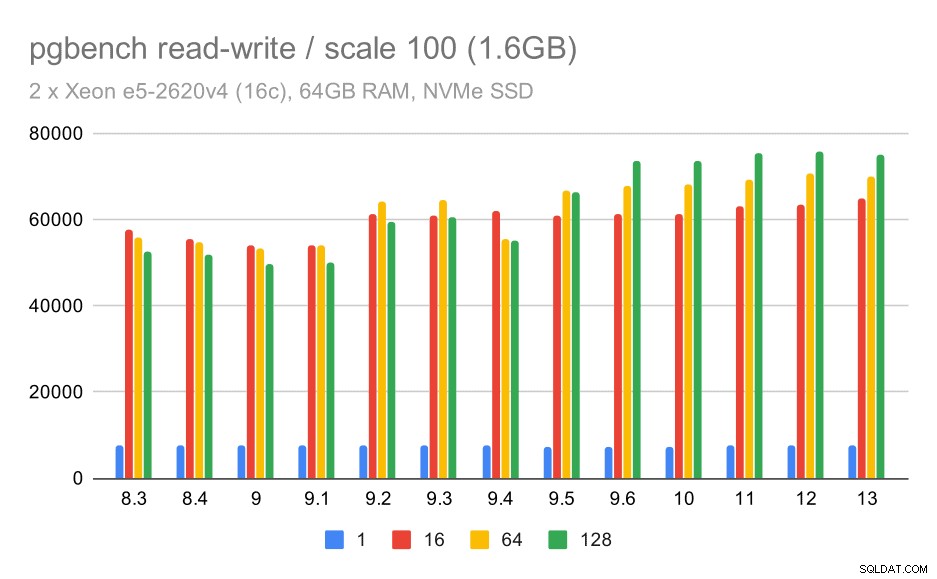
résultats de pgbench / lecture-écriture sur un petit ensemble de données (échelle 100, soit 1,6 Go)
Donc une amélioration modeste d'environ 52k à 75k tps avec un nombre suffisant de clients.
Pour l'ensemble de données moyen, l'amélioration est beaucoup plus nette :d'environ 27 000 à 63 000 tps, c'est-à-dire que le débit fait plus que doubler.
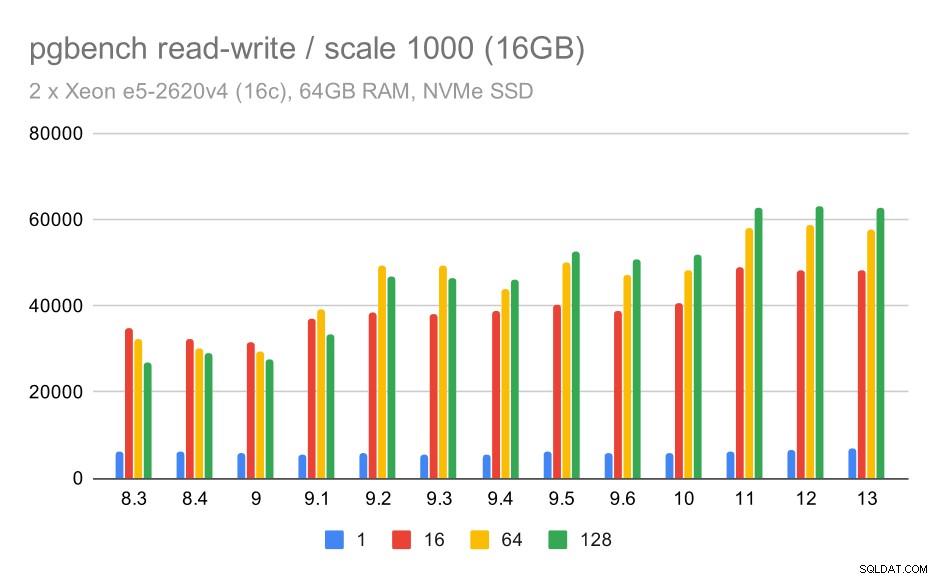
résultats pgbench / lecture-écriture sur un jeu de données moyen (échelle 1000, soit 16 Go)
Pour le plus grand ensemble de données, nous constatons une amélioration globale similaire, mais il semble y avoir une certaine régression entre 9,5 et 11.
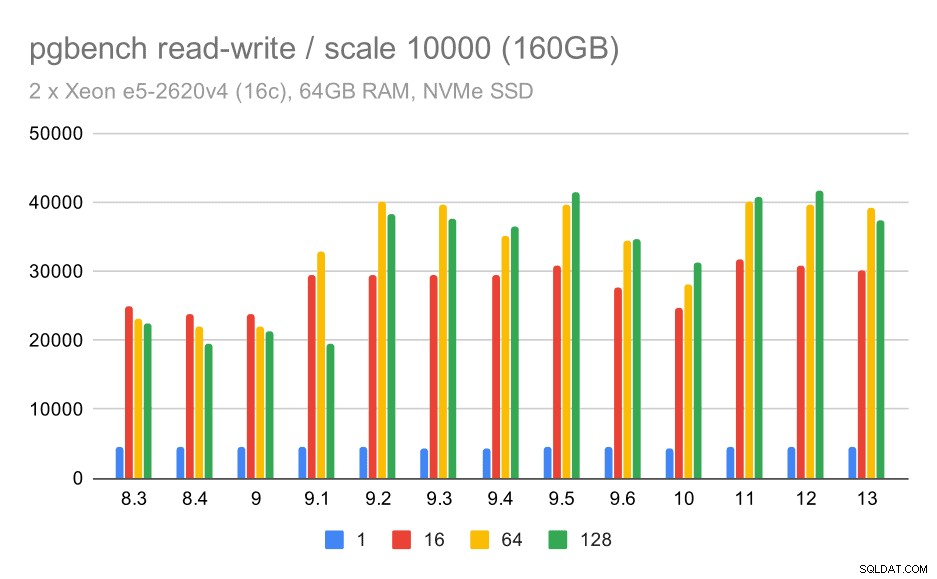
résultats de pgbench / lecture-écriture sur un grand ensemble de données (échelle 10000, soit 160 Go)
RAID SATA / lecture seule
Pour le stockage RAID SATA, les résultats en lecture seule ne sont pas très bons. Nous pouvons ignorer les petits et moyens ensembles de données, pour lesquels le système de stockage n'est pas pertinent. Pour le grand ensemble de données, le débit est quelque peu bruyant, mais il semble en fait diminuer avec le temps, en particulier depuis PostgreSQL 9.6. Je ne sais pas quelle en est la raison (rien dans les notes de version 9.6 ne ressort comme un candidat clair), mais cela ressemble à une sorte de régression.
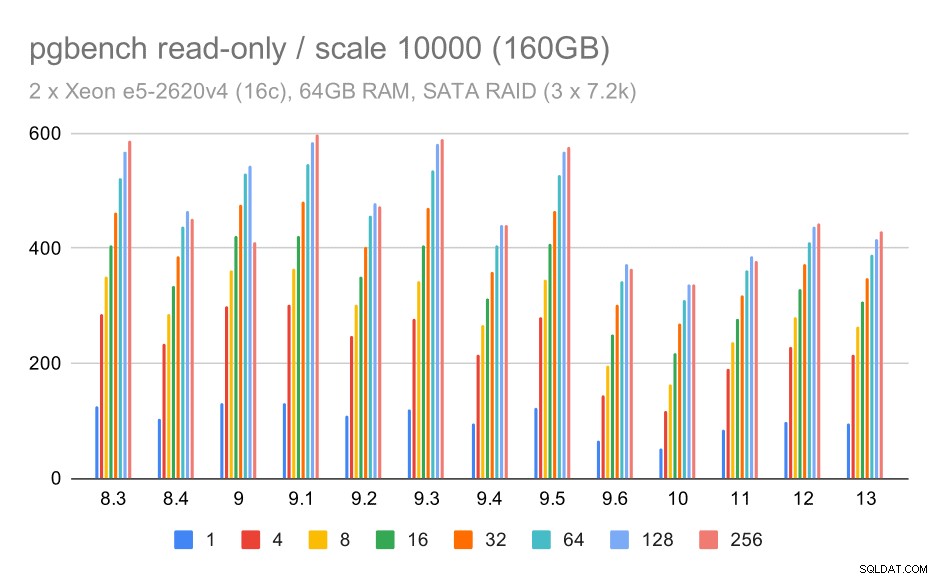
résultats de pgbench sur RAID SATA / lecture seule sur un grand ensemble de données (échelle 10000, c'est-à-dire 160 Go)
RAID SATA / lecture-écriture
Le comportement de lecture-écriture semble cependant beaucoup plus agréable. Sur le petit ensemble de données, le débit passe d'environ 600 tps à plus de 6000 tps. Je parie que c'est grâce aux améliorations apportées à la validation de groupe dans les versions 9.1 et 9.2.
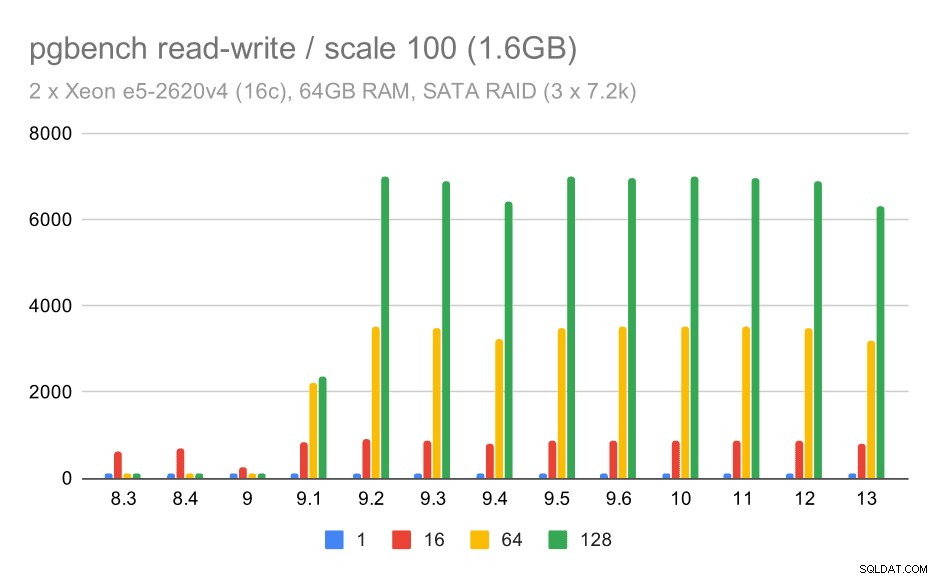
résultats de pgbench sur RAID SATA / lecture-écriture sur un petit ensemble de données (échelle 100, soit 1,6 Go)
Pour les moyennes et grandes échelles, nous pouvons constater une amélioration similaire, mais moindre, car le stockage doit également gérer les demandes d'E/S pour lire et écrire les blocs de données. Pour l'échelle moyenne, nous n'avons qu'à faire les écritures (car les données tiennent dans la RAM), pour l'échelle à grande échelle, nous devons également faire les lectures ; le débit maximal est donc encore plus faible.
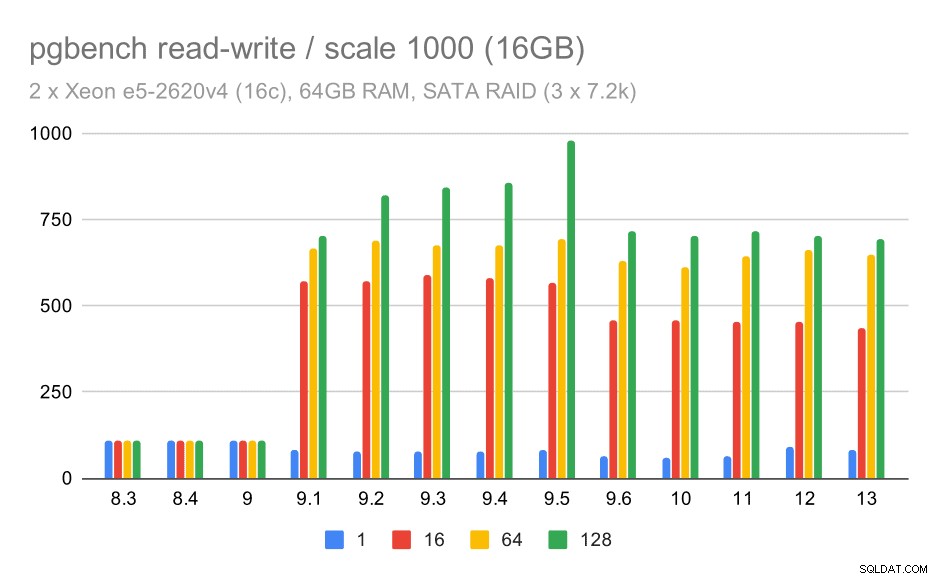
Résultats de pgbench sur RAID SATA / lecture-écriture sur un jeu de données moyen (échelle 1000, soit 16 Go)
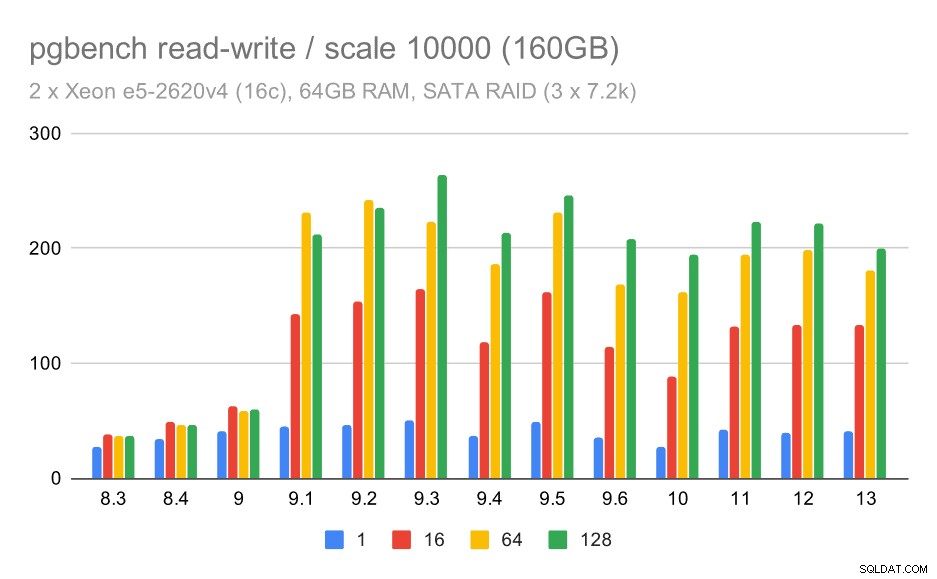
résultats de pgbench sur RAID SATA / lecture-écriture sur un grand ensemble de données (échelle 10000, soit 160 Go)
Résumé et avenir
Pour résumer cela, pour la configuration NVMe, les conclusions semblent plutôt positives. Pour la charge de travail en lecture seule, il y a une accélération modérée dans 9.2 et une accélération significative dans 9.5, grâce aux optimisations d'évolutivité, tandis que pour la charge de travail en lecture-écriture, les performances se sont améliorées d'environ 2 fois au fil du temps, dans plusieurs versions/étapes.
Avec la configuration SATA RAID, les conclusions sont quelque peu mitigées. Dans le cas de la charge de travail en lecture seule, il y a beaucoup de variabilité/bruit, et une régression possible dans 9.6. Pour la charge de travail en lecture-écriture, il y a une accélération massive dans 9.1 où le débit est soudainement passé de 100 tps à environ 600 tps.
Qu'en est-il des améliorations dans les futures versions de PostgreSQL ? Je n'ai pas une idée très claire de ce que sera la prochaine grande amélioration - je suis cependant sûr que d'autres hackers PostgreSQL proposeront des idées brillantes qui rendront les choses plus efficaces ou permettront de tirer parti des ressources matérielles disponibles. Le patch pour améliorer l'évolutivité avec de nombreuses connexions ou le patch pour ajouter la prise en charge des tampons WAL non volatiles sont des exemples de telles améliorations. Nous pourrions voir des améliorations radicales du stockage PostgreSQL (format sur disque plus efficace, utilisation d'E/S directes, etc.), de l'indexation, etc.