La semaine dernière, j'ai fait quelques comparaisons de performances rapides, en opposant le nouveau STRING_AGG() fonction par rapport au traditionnel FOR XML PATH approche que j'utilise depuis des lustres. J'ai testé à la fois l'ordre indéfini/arbitraire ainsi que l'ordre explicite, et STRING_AGG() est arrivé en tête dans les deux cas :
- SQL Server v.Next :performances de STRING_AGG(), partie 1
Pour ces tests, j'ai omis plusieurs choses (pas toutes intentionnellement) :
- Mikael Eriksson et Grzegorz Łyp ont tous deux souligné que je n'utilisais pas le
FOR XML PATHle plus efficace. construire (et pour être clair, je ne l'ai jamais fait). - Je n'ai effectué aucun test sur Linux ; uniquement sur Windows. Je ne m'attends pas à ce que ceux-ci soient très différents, mais comme Grzegorz a vu des durées très différentes, cela mérite une enquête plus approfondie.
- J'ai également testé uniquement lorsque la sortie serait une chaîne finie et non LOB - ce qui, à mon avis, est le cas d'utilisation le plus courant (je ne pense pas que les gens concatèneront généralement chaque ligne d'une table en une seule ligne séparée par des virgules chaîne, mais c'est pourquoi j'ai demandé dans mon post précédent votre ou vos cas d'utilisation).
- Pour les tests de classement, je n'ai pas créé d'index qui pourrait être utile (ni essayé quoi que ce soit où toutes les données provenaient d'une seule table).
Dans cet article, je vais traiter quelques-uns de ces éléments, mais pas tous.
POUR CHEMIN XML
J'avais utilisé ce qui suit :
... FOR XML PATH, TYPE).value(N'.[1]', ...
Après ce commentaire de Mikael, j'ai mis à jour mon code pour utiliser à la place cette construction légèrement différente :
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux contre Windows
Au départ, je n'avais pris la peine de faire des tests que sous Windows :
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Mais Grzegorz a fait valoir que lui (et probablement beaucoup d'autres) n'avait accès qu'à la version Linux de CTP 1.1. J'ai donc ajouté Linux à ma matrice de test :
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Quelques observations intéressantes mais complètement tangentielles :
@@VERSIONn'affiche pas l'édition dans cette version, maisSERVERPROPERTY('Edition')renvoie l'Developer Edition (64-bit)attendu .- Sur la base des temps de construction encodés dans les binaires, les versions Windows et Linux semblent maintenant être compilées en même temps et à partir de la même source. Ou c'était une folle coïncidence.
Tests non ordonnés
J'ai commencé par tester la sortie ordonnée arbitrairement (où il n'y a pas d'ordre explicitement défini pour les valeurs concaténées). Après Grzegorz, j'ai utilisé WideWorldImporters (Standard), mais j'ai effectué une jointure entre Sales.Orders et Sales.OrderLines . L'exigence fictive ici est de produire une liste de toutes les commandes, et avec chaque commande, une liste séparée par des virgules de chaque StockItemID .
Depuis StockItemID est un entier, nous pouvons utiliser un varchar défini , ce qui signifie que la chaîne peut contenir 8 000 caractères avant que nous ayons à nous soucier d'avoir besoin de MAX. Étant donné qu'un int peut avoir une longueur maximale de 11 (vraiment 10, s'il n'est pas signé), plus une virgule, cela signifie qu'une commande devrait prendre en charge environ 8 000/12 (666) articles en stock dans le pire des cas (par exemple, toutes les valeurs StockItemID ont 11 chiffres). Dans notre cas, l'ID le plus long est à 3 chiffres, donc jusqu'à ce que les données soient ajoutées, nous aurions en fait besoin de 8 000/4 (2 000) articles en stock uniques dans une seule commande pour justifier MAX. Dans notre cas, il n'y a que 227 articles en stock au total, donc MAX n'est pas nécessaire, mais vous devriez garder un œil dessus. Si une si grande chaîne est possible dans votre scénario, vous devrez utiliser varchar(max) au lieu de la valeur par défaut (STRING_AGG() renvoie nvarchar(max) , mais tronque à 8 000 octets à moins que l'entrée est un type MAX).
Les requêtes initiales (pour afficher un exemple de sortie et pour observer les durées d'exécutions uniques) :
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
J'ai complètement ignoré les données de temps d'analyse et de compilation, car elles étaient toujours exactement nulles ou suffisamment proches pour ne pas être pertinentes. Il y avait des variations mineures dans les temps d'exécution pour chaque exécution, mais pas beaucoup - les commentaires ci-dessus reflètent le delta typique de l'exécution (STRING_AGG semblait tirer un peu parti du parallélisme là-bas, mais uniquement sous Linux, tandis que FOR XML PATH n'a pas sur l'une ou l'autre plate-forme). Les deux machines avaient un seul socket, un processeur quadricœur alloué, 8 Go de mémoire, une configuration prête à l'emploi et aucune autre activité.
Ensuite, j'ai voulu tester à grande échelle (simplement une seule session exécutant la même requête 500 fois). Je ne voulais pas renvoyer toutes les sorties, comme dans la requête ci-dessus, 500 fois, car cela aurait submergé SSMS - et, espérons-le, ne représente pas de toute façon des scénarios de requête du monde réel. J'ai donc assigné la sortie à des variables et juste mesuré le temps total pour chaque lot :
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); J'ai effectué ces tests trois fois, et la différence était profonde - près d'un ordre de grandeur. Voici la durée moyenne des trois tests :
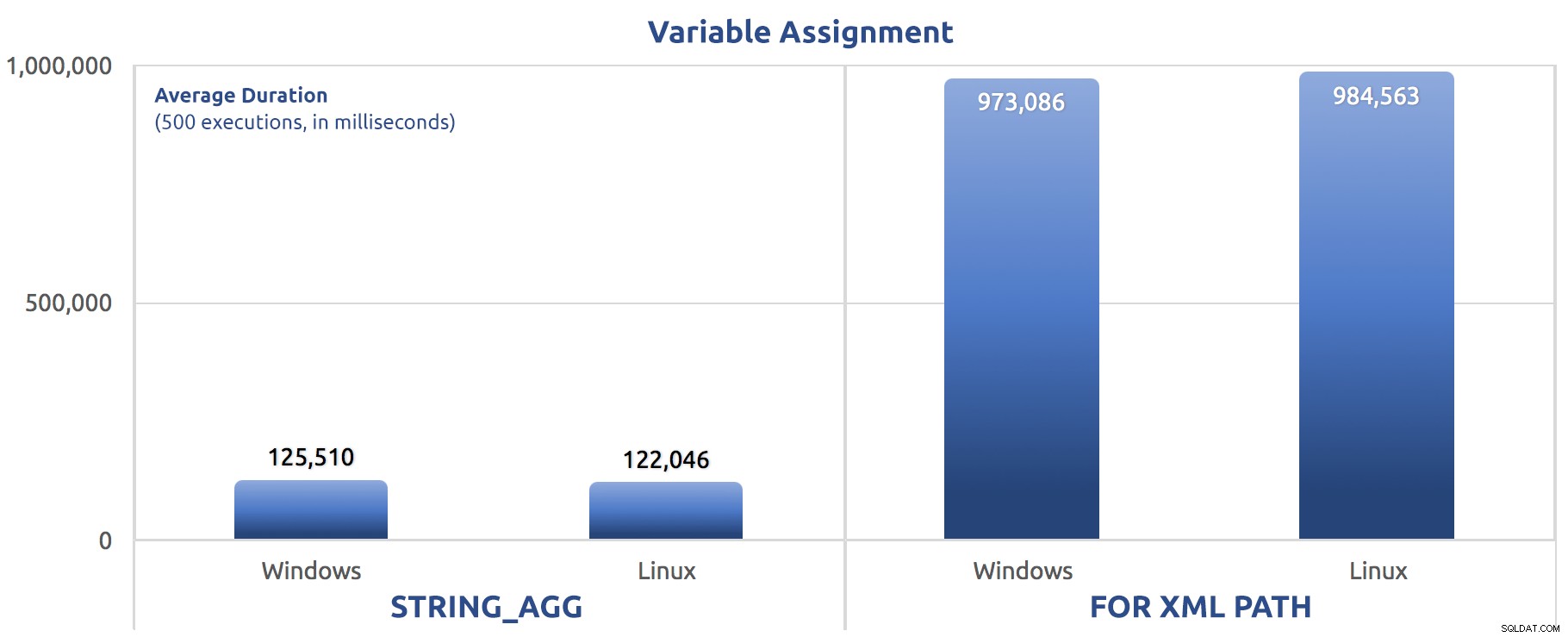 Durée moyenne, en millisecondes, pour 500 exécutions d'affectation de variable
Durée moyenne, en millisecondes, pour 500 exécutions d'affectation de variable
J'ai également testé une variété d'autres choses de cette façon, principalement pour m'assurer que je couvrais les types de tests que Grzegorz exécutait (sans la partie LOB).
- Sélectionner uniquement la longueur de la sortie
- Obtenir la longueur maximale de la sortie (d'une ligne arbitraire)
- Sélectionner toutes les sorties dans une nouvelle table
Sélectionner uniquement la longueur de la sortie
Ce code parcourt simplement chaque commande, concatène toutes les valeurs StockItemID, puis renvoie uniquement la longueur.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Pour la version par lots, encore une fois, j'ai utilisé l'affectation de variables, plutôt que d'essayer de renvoyer de nombreux jeux de résultats à SSMS. L'affectation de variable se retrouverait sur une ligne arbitraire, mais cela nécessite toujours des analyses complètes, car la ligne arbitraire n'est pas sélectionnée en premier.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Métriques de performance de 500 exécutions :
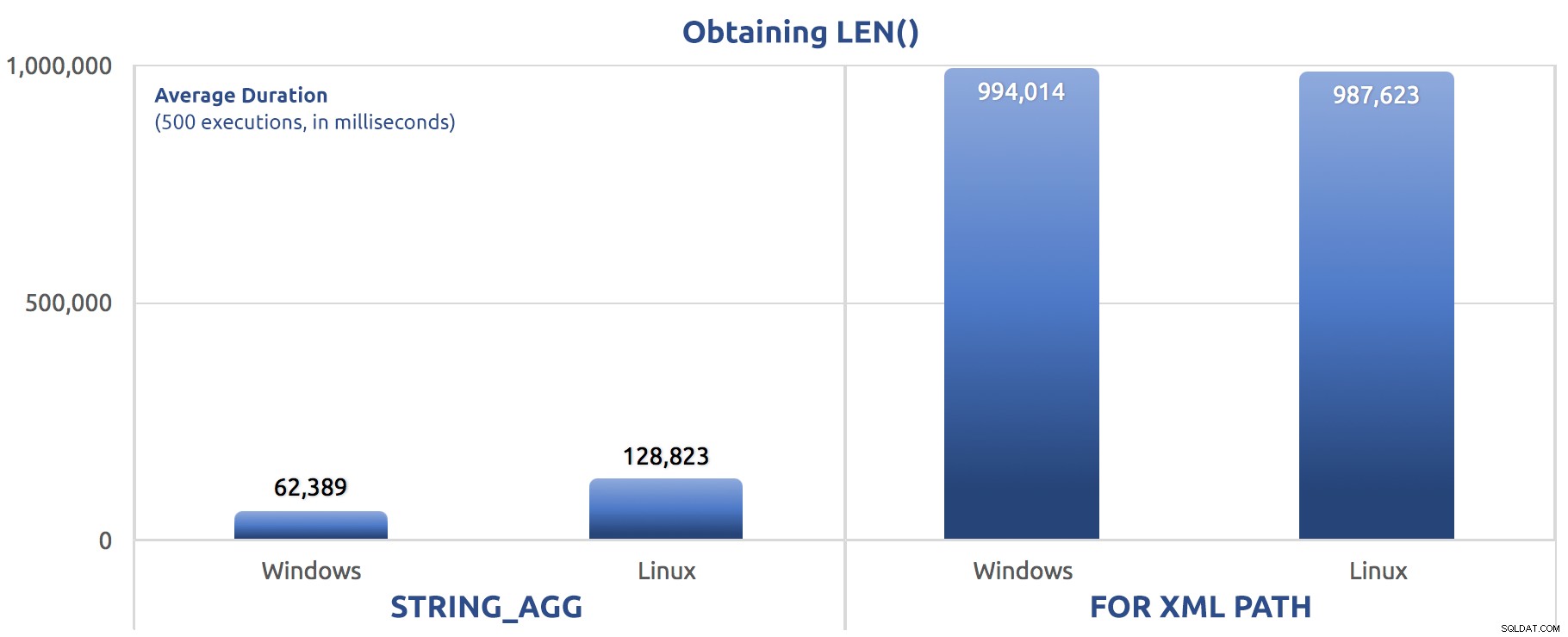 500 exécutions d'attribution de LEN() à une variable
500 exécutions d'attribution de LEN() à une variable
Encore une fois, nous voyons FOR XML PATH est beaucoup plus lent, à la fois sous Windows et Linux.
Sélection de la longueur maximale de la sortie
Une légère variation par rapport au test précédent, celui-ci récupère juste le maximum longueur de la sortie concaténée :
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Et à grande échelle, nous attribuons à nouveau cette sortie à une variable :
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Résultats de performances, pour 500 exécutions, moyennés sur trois exécutions :
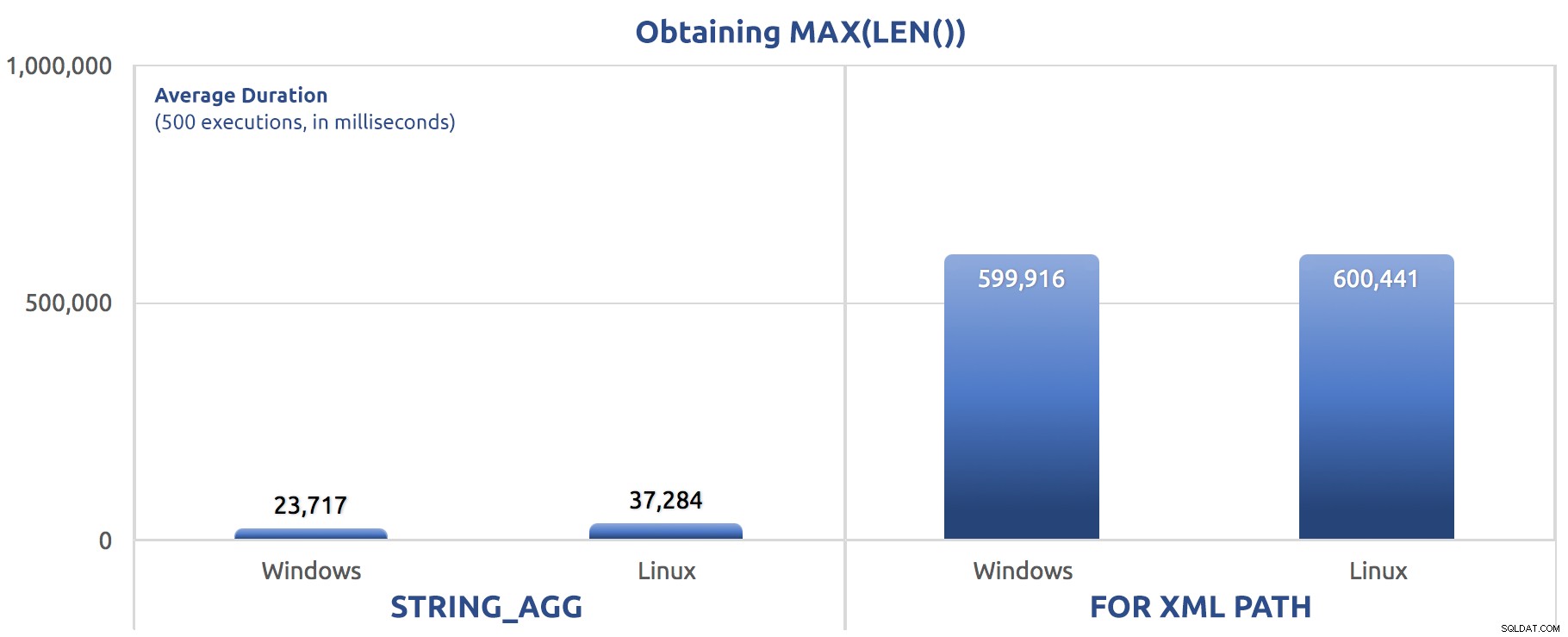 500 exécutions d'affectation de MAX(LEN()) à une variable
500 exécutions d'affectation de MAX(LEN()) à une variable
Vous pourriez commencer à remarquer un modèle à travers ces tests - FOR XML PATH est toujours un chien, même avec les améliorations de performances suggérées dans mon post précédent.
SÉLECTIONNER DANS
Je voulais voir si la méthode de concaténation avait un impact sur l'écriture les données sur disque, comme c'est le cas dans d'autres scénarios :
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
Dans ce cas, nous voyons que peut-être SELECT INTO a pu profiter d'un peu de parallélisme, mais nous voyons toujours FOR XML PATH lutte, avec des temps d'exécution d'un ordre de grandeur plus long que STRING_AGG .
La version par lots vient d'échanger les commandes SET STATISTICS pour SELECT sysdatetime(); et ajouté le même GO 500 après les deux lots principaux comme pour les tests précédents. Voici comment cela s'est passé (encore une fois, dites-moi si vous avez déjà entendu celui-ci):
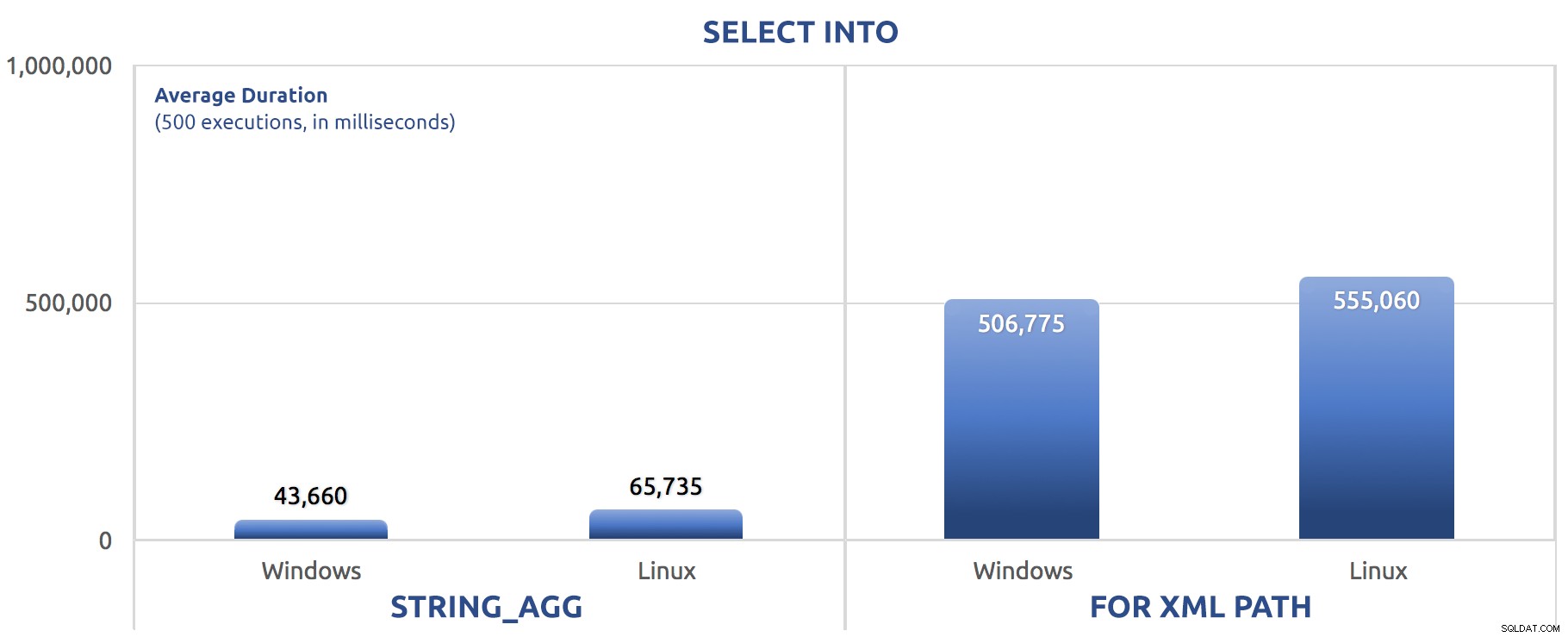 500 exécutions de SELECT INTO
500 exécutions de SELECT INTO
Tests commandés
J'ai exécuté les mêmes tests en utilisant la syntaxe ordonnée, par exemple :
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Cela a eu très peu d'impact sur quoi que ce soit :le même ensemble de quatre bancs d'essai a montré des métriques et des modèles presque identiques dans tous les domaines.
Je serai curieux de voir si cela est différent lorsque la sortie concaténée est dans un non-LOB ou lorsque la concaténation doit ordonner des chaînes (avec ou sans index de support).
Conclusion
Pour les chaînes non LOB , il est clair pour moi que STRING_AGG a un avantage définitif en termes de performances par rapport à FOR XML PATH , sur Windows et Linux. Notez que, pour éviter l'exigence de varchar(max) ou nvarchar(max) , je n'ai rien utilisé de similaire aux tests exécutés par Grzegorz, ce qui aurait signifié simplement concaténer toutes les valeurs d'une colonne, sur une table entière, en une seule chaîne. Dans mon prochain article, j'examinerai le cas d'utilisation où la sortie de la chaîne concaténée pourrait être supérieure à 8 000 octets, et donc les types LOB et les conversions devraient être utilisés.