Lors du déploiement d'un cluster de bases de données sur différents serveurs, vous aurez obtenu l'avantage de la réplication en améliorant la disponibilité des données. Cependant, il est nécessaire de suivre les processus et de voir s'ils sont en cours d'exécution ou non. L'un des programmes utilisés dans ce processus est Heartbeat qui a la capacité de vérifier et de vérifier la présence de ressources sur un ou plusieurs systèmes dans un cluster donné. Outre PostgreSQL et les systèmes de fichiers pour lesquels les données PostgreSQL sont stockées, le DRBD est l'une des ressources dont nous allons discuter dans cet article sur la façon dont le programme Heartbeat peut être utilisé.
Battement de cœur haute disponibilité
Comme indiqué précédemment dans le blog DRBD, la haute disponibilité des données est obtenue en exécutant différentes instances du serveur mais en servant les mêmes données. Ces instances de serveur en cours d'exécution peuvent être définies comme un cluster par rapport à un Heartbeat. Fondamentalement, chacune des instances de serveur est physiquement capable de fournir le même service que les autres au sein de ce cluster. Cependant, une seule instance peut fournir activement un service à la fois dans le but d'assurer une haute disponibilité des données. On peut donc définir les autres instances comme des « hot-spares » pouvant être mises en service en cas de défaillance du maître. Le package Heartbeat peut être téléchargé à partir de ce lien. Après avoir installé ce package, vous pouvez le configurer pour qu'il fonctionne avec votre système en suivant la procédure ci-dessous. Une structure simple de la configuration Heartbeat est :
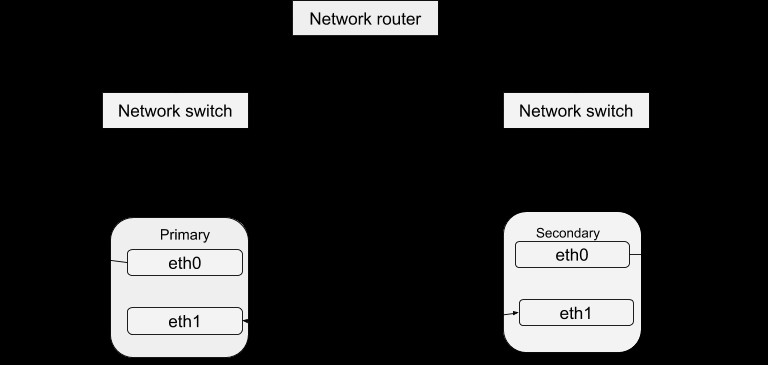
Configuration de la pulsation
En regardant dans ce répertoire /etc/ha.d, vous trouverez quelques fichiers qui sont utilisés dans le processus de configuration. Le fichier ha.cf constitue la principale configuration de pulsation. Il comprend la liste de tous les nœuds et les heures d'identification de l'échec en plus de diriger le battement de cœur sur le type de chemins de média à utiliser et comment les configurer. Les informations de sécurité du cluster sont enregistrées dans le fichier authkeys. Les informations enregistrées dans ces fichiers doivent être identiques pour tous les hôtes du cluster et cela peut être facilement réalisé grâce à la synchronisation sur tous les hôtes. C'est-à-dire que tout changement d'information dans un hôte doit être copié sur tous les autres.
Fichier Ha.cf
Le schéma de base du fichier ha.cf est
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility :celui-ci est utilisé pour diriger le Heartbeat sur quelle installation de journalisation syslog il doit utiliser pour enregistrer les messages. Les valeurs les plus couramment utilisées sont auth, authpriv, user, local0, syslog et daemon. Vous pouvez également décider de ne pas avoir de journaux, vous pouvez donc définir la valeur sur none .i.e
logfacility none - Keepalive :il s'agit du temps entre les battements de cœur, c'est-à-dire la fréquence à laquelle le signal de battement de cœur est envoyé aux autres hôtes. Dans l'exemple de code ci-dessus, il est défini sur 3 secondes.
- Deadtime :c'est le délai en secondes après lequel un nœud est déclaré défaillant.
- Warntime :est le délai en secondes après lequel un avertissement est enregistré dans un journal indiquant qu'un nœud ne peut plus être contacté.
- Initdead :il s'agit du temps d'attente en secondes pendant le démarrage du système avant que l'autre hôte ne soit considéré comme inactif.
- Mcast :il s'agit d'une procédure de méthode définie pour envoyer un signal de pulsation. Pour l'exemple de code ci-dessus, l'adresse réseau multidiffusion est utilisée sur un périphérique réseau délimité. Pour un cluster multiple, l'adresse de multidiffusion doit être unique pour chaque cluster. Vous pouvez également choisir une connexion série sur la multidiffusion ou si vous configurez de telle manière qu'il existe plusieurs interfaces réseau, utilisez les deux pour la connexion par pulsation comme dans l'exemple. L'avantage d'utiliser les deux est de surmonter les risques de défaillance transitoire qui peuvent par conséquent entraîner un événement de défaillance non valide.
- Auto_failback :cela reconnecte un serveur qui avait échoué au cluster s'il devient disponible. Cependant, cela peut entraîner une confusion si le serveur est allumé puis se connecte à un moment différent. En ce qui concerne le DRBD, s'il n'est pas bien configuré, vous risquez de vous retrouver avec plusieurs jeux de données sur le même serveur. Par conséquent, il est conseillé de toujours le désactiver.
- Nœud :décrit le nœud au sein du groupe de clusters Heartbeat. Vous devez avoir au moins 1 nœud pour chacun.
Configurations supplémentaires
Vous pouvez également définir des informations de configuration supplémentaires telles que :
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping :ceci est important pour garantir que vous disposez d'une connectivité sur l'interface publique pour les serveurs et d'une connexion à un autre hôte. Il est important de prendre en compte l'adresse IP plutôt que le nom d'hôte de la machine de destination.
- Respawn :il s'agit de la commande à exécuter en cas d'échec.
- Apiauth :est l'autorité responsable de l'échec. Vous devez configurer l'ID d'utilisateur et de groupe avec lequel la commande sera exécutée. Le fichier authkeys contient les informations d'autorisation pour le cluster Heartbeat et cette clé est tout à fait unique pour vérifier les machines au sein d'un cluster Heartbeat donné.
- Deadping :définit le délai avant qu'une non-réponse ne déclenche un échec.
Intégration de Heartbeat avec Postgres et DRBD
Comme mentionné précédemment, lorsqu'un serveur maître tombe en panne, un autre serveur avec un cluster donné entrera en action pour fournir le même service. Heartbeat aide à la configuration des ressources qui améliorent la sélection d'un serveur en cas de panne. Il définit par exemple quels serveurs individuels doivent être mis en place ou supprimés en cas de panne. En enregistrant le fichier haresources dans le répertoire /etc/ha.d, nous obtenons un aperçu des ressources pouvant être gérées. Le chemin du fichier de ressources est /etc/ha.d/resource.d et la définition de la ressource est sur une seule ligne :
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(notez les espaces).
- Drbd1 :fait référence au nom de l'hôte préféré pour être plus sécant au serveur qui est normalement utilisé comme maître par défaut pour gérer le service. Comme mentionné dans le blog DRBD, nous avons besoin de ressources pour notre serveur et celles-ci sont définies dans la ligne comme drbddisk, filesystem et postgres. Le dernier champ est une adresse IP virtuelle qui doit être utilisée pour partager le service, c'est-à-dire se connecter au serveur Postgres. Par défaut, il sera attribué au serveur qui est actif au début du Heartbeat. Lorsqu'une panne survient, ces ressources seront lancées sur le serveur de secours dans l'ordre de classement lors de l'appel du script correspondant. Dans le paramètre, le script basculera le disque DRBD sur l'hôte secondaire en mode principal, ce qui rendra le périphérique en lecture/écriture.
- Système de fichiers :cela va gérer les ressources du système de fichiers et dans ce cas, le DRBD a été sélectionné afin qu'il soit monté lors de l'appel du script de ressources.
- Postgres :cela démarrera ou gérera le serveur Postgres
Parfois, vous voudriez recevoir des notifications par e-mail. Pour ce faire, ajoutez cette ligne au fichier de ressources avec votre email pour recevoir les textes d'avertissement :
MailTo:: example@sqldat.com::DRBDFailurePour démarrer le rythme cardiaque, vous pouvez exécuter la commande
/etc/ha.d/heartbeat startou redémarrez les serveurs principal et secondaire. Maintenant, si vous exécutez la commande
$ /usr/lib64/heartbeat/hb_standbyLe nœud actuel sera déclenché pour abandonner ses ressources proprement à l'autre nœud.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancGestion des erreurs au niveau du système
Parfois, le noyau du serveur peut être corrompu, indiquant ainsi un problème potentiel avec votre serveur. Vous devrez configurer le serveur pour qu'il se retire du cluster en cas de problème. Ce problème est souvent appelé panique du noyau et déclenche par conséquent un redémarrage brutal de votre machine. Vous pouvez forcer un redémarrage en définissant les fichiers kernel.panic et kernel.panic_on_oop du fichier de contrôle du noyau /etc/sysctl.conf. C'est-à-dire
kernel.panic_on_oops = 1
kernel.panic = 1Une autre option consiste à le faire à partir de la ligne de commande à l'aide de la commande sysctl, c'est-à-dire :
$ sysctl -w kernel.panic=1Vous pouvez également modifier le fichier sysctl.conf et recharger les informations de configuration à l'aide de cette commande.
sysctl -pLa valeur indique le nombre de secondes à attendre avant le redémarrage. Le deuxième nœud de pulsation devrait alors détecter que le serveur est en panne, puis basculer sur l'hôte de basculement.
Conclusion
Heartbeat est un sous-système qui permet de sélectionner un serveur secondaire en système principal et un système de secours lorsqu'un serveur actif tombe en panne. Il détermine également si tous les autres serveurs sont actifs. Il assure également le transfert des ressources vers le nouveau nœud principal