Alors que Jeff Atwood et Joe Celko semblent penser que le coût des GUID n'est pas un gros problème (voir le billet de blog de Jeff, "Primary Keys:IDs versus GUIDs", et ce fil de newsgroup, intitulé "Identity Vs. Uniqueidentifier"), d'autres experts - plus spécifiquement les experts en index et en architecture se concentrant sur l'espace SQL Server - ont tendance à être en désaccord. Par exemple, Kimberly Tripp passe en revue certains détails dans son article, "L'espace disque est bon marché - CE N'EST PAS LE POINT !", où elle explique que l'impact n'est pas seulement sur l'espace disque et la fragmentation, mais surtout sur la taille de l'index et la mémoire. empreinte.
Ce que dit Kimberly est vraiment vrai - je rencontre tout le temps la justification "l'espace disque est bon marché" pour les GUID (exemple de la semaine dernière). Il existe d'autres justifications pour les GUID, notamment la nécessité de générer des identifiants uniques en dehors de la base de données (et parfois avant que la ligne ne soit réellement créée) et le besoin d'identifiants uniques sur des systèmes distribués distincts (et lorsque les plages d'identité ne sont pas pratiques). Mais je veux vraiment dissiper le mythe selon lequel les GUID ne coûtent pas si cher, car ils le font, et vous devez peser ces coûts dans votre décision.
Je me suis lancé dans cette mission pour tester les performances de différentes tailles de clé, étant donné les mêmes données sur le même nombre de lignes, avec les mêmes index et à peu près la même charge de travail (rejouer *exactement* la même charge de travail peut être assez difficile). Non seulement je voulais mesurer les éléments de base tels que la taille et la fragmentation des index, mais également les effets qu'ils ont sur toute la ligne, tels que :
- impact sur l'utilisation du pool de mémoire tampon
- fréquence des "mauvais" fractionnements de page
- impact global sur la durée réaliste de la charge de travail
- impact sur les durées d'exécution moyennes des requêtes individuelles
- impact sur la durée d'exécution des déclencheurs après
- impact sur l'utilisation de tempdb
J'utiliserai diverses techniques pour étudier ces données, y compris les événements étendus, la trace par défaut, les DMV liées à tempdb et SQL Sentry Performance Advisor.
Configuration
Tout d'abord, j'ai créé un million de clients à placer dans une table de départ à l'aide de métadonnées SQL Server intégrées ; cela garantirait que les clients "aléatoires" seraient constitués des mêmes données naturelles tout au long de chaque test.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =GAUCHE(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. nom, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;GO SELECT TOP (10) * FROM dbo.CustomerSeeds ORDER BY rn;GO
Votre kilométrage peut varier, mais sur mon système, cette population a pris 86 secondes. Dix rangées représentatives (cliquez pour agrandir) :
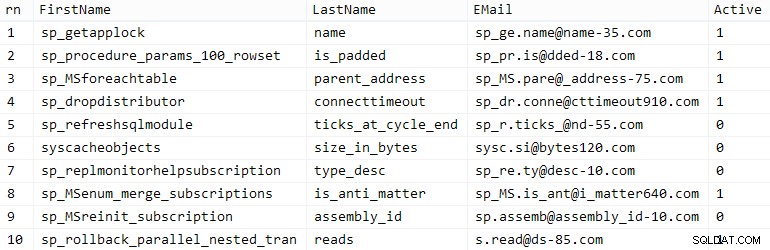 Exemples de clients
Exemples de clients
Ensuite, j'avais besoin de tables pour héberger les données de départ pour chaque cas d'utilisation, avec quelques index supplémentaires pour simuler une sorte de réalité, et j'ai proposé des suffixes courts pour faciliter toutes sortes de diagnostics ultérieurs :
| type de données | par défaut | compression | suffixe de cas d'utilisation |
|---|---|---|---|
| INT | IDENTITÉ | aucun | Je |
| INT | IDENTITÉ | page + ligne | Ic |
| GRANDINT | IDENTITÉ | aucun | B |
| GRANDINT | IDENTITÉ | page + ligne | Bc |
| IDENTIFIANT UNIQUE | NEWID() | aucun | G |
| IDENTIFIANT UNIQUE | NEWID() | page + ligne | GC |
| IDENTIFIANT UNIQUE | NEWSEQUENTIALID() | aucun | S |
| IDENTIFIANT UNIQUE | NEWSEQUENTIALID() | page + ligne | Sc |
Tableau 1 :Cas d'utilisation, types de données et suffixes
Huit tableaux au total, tous issus du même modèle (je modifierais simplement les commentaires pour qu'ils correspondent au cas d'utilisation et remplaceraient $use_case$ avec le suffixe approprié du tableau ci-dessus) :
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, EMail NVARCHAR(320) NOT NULL, Actif BIT NOT NULL DEFAULT 1, Créé DATETIME NOT NULL DEFAULT SYSDATETIME(), DATETIME NULL mis à jour, CONTRAINTE C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE INDEX C_Email_Customers_$use_case$ ON dbo. Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Actif =1 --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(LastName, FirstName) INCLUDE (EMail) --WITH (DATA_COMPRESSION =PAGE);GOUne fois les tableaux créés, j'ai commencé à remplir les tableaux et à mesurer bon nombre des mesures auxquelles j'ai fait allusion ci-dessus. J'ai redémarré le service SQL Server entre chaque test pour m'assurer qu'ils partaient tous de la même ligne de base, que les DMV seraient réinitialisés, etc.
Inserts non contestés
Mon objectif final était de remplir la table avec 1 000 000 de lignes, mais je voulais d'abord voir l'impact du type de données et de la compression sur les insertions brutes sans conflit. J'ai généré la requête suivante - qui remplirait la table avec les 200 000 premiers contacts, 2 000 lignes à la fois - et l'ai exécutée sur chaque table :
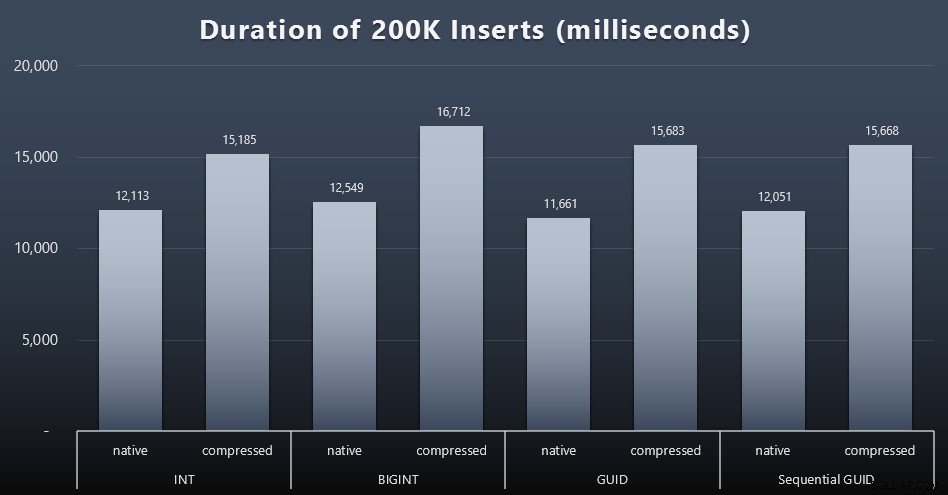
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Actif) SELECT FirstName, LastName, Email, Actif FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RECUPERER LES 2000 LIGNES SUIVANTES UNIQUEMENT ; SET @i +=1;ENDRésultats (cliquez pour agrandir) :
Chaque cas a pris environ 12 secondes (sans compression) et 16 secondes (avec compression), sans aucun gagnant clair dans les deux modes de stockage. L'effet de la compression (principalement sur la surcharge du processeur) est assez cohérent, mais comme il s'exécute sur un SSD rapide, l'impact des E/S des différents types de données est négligeable. En fait, la compression par rapport à BIGINT semblait avoir le plus grand impact (et cela a du sens, puisque chaque valeur inférieure à 2 milliards serait compressée).
Charge de travail plus litigieuse
Ensuite, je voulais voir comment une charge de travail mixte serait en concurrence pour les ressources et fonctionnerait généralement par rapport à chaque type de données. J'ai donc créé ces procédures (en remplaçant
$use_case$et$data_type$de manière appropriée pour chaque test) :-- mises à jour aléatoires de singletons sur les données de plusieurs indexCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON ; UPDATE dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- lit ("pagination") - prend en charge plusieurs trie-- utilise SQL dynamique pour suivre séparément les statistiques des requêtesCREATE PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT CustomerID, FirstName, LastName, Email, Actif, Créé, Mis à jour FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) RECUPERER LES LIGNES SUIVANTES @ps UNIQUEMENT LES LIGNES ;' ; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOEnsuite, j'ai créé des tâches qui appelaient ces procédures à plusieurs reprises, avec de légers retards, et aussi - simultanément - finissaient de remplir les 800 000 contacts restants. Ce script crée les 32 tâches et imprime également une sortie qui peut être utilisée ultérieurement pour appeler toutes les tâches pour un test spécifique de manière asynchrone :
USE msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Renseigner les clients', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Prénom, Nom, Email, Actif) SELECT FirstName, LastName, Email, Actif FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) ROWS FETCH NEXT 2000 ROWS ONLY ; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Paging workload 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- trier par ID client SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; ATTENTE DELAI ''00:00:01'' ; SET @i +=2 ; END'),( N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- trier par Nom, Prénom SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Nom, Prénom'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; ATTENTE DELAI ''00:00:01''; SET @i +=2; FIN'); DECLARE @n SYSNAME, @c NVARCHAR(MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT nom =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; OUVERT c ; FETCH c INTO @n, @c ; WHILE @@FETCH_STATUS <> -1BEGIN IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa' ; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs' ; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(local)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDMesurer les délais de travail dans chaque cas était trivial - je pouvais vérifier les dates de début/fin dans
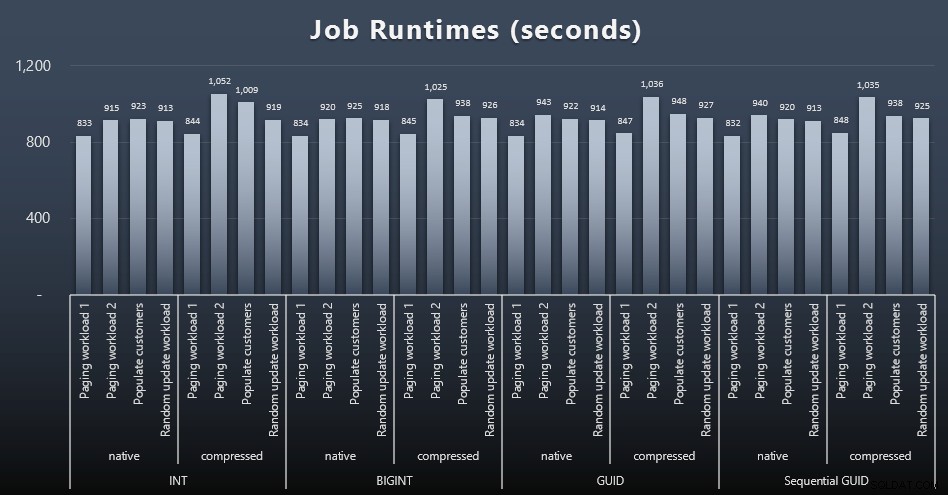
msdb.dbo.sysjobhistoryou extrayez-les de SQL Sentry Event Manager. Voici les résultats (cliquez pour agrandir) :
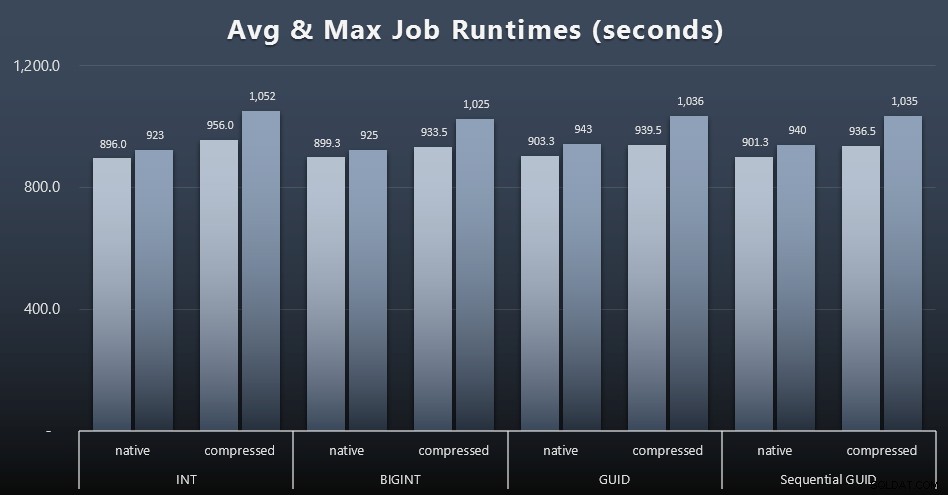
Et si vous vouliez en avoir un peu moins à digérer, regardez simplement les durées d'exécution moyennes et maximales des quatre tâches (cliquez pour agrandir) :
Mais même dans ce deuxième graphique, il n'y a pas vraiment assez de variance pour plaider en faveur ou contre l'une des approches.
Exécutions de requête
J'ai pris quelques métriques de
sys.dm_exec_query_statsetsys.dm_exec_trigger_statspour déterminer la durée moyenne des requêtes individuelles.
Population
Les 200 000 premiers clients ont été chargés assez rapidement (moins de 20 secondes) en raison de l'absence de charges de travail concurrentes. Cependant, une fois que les quatre tâches s'exécutaient simultanément, il y avait un impact significatif sur les durées d'écriture en raison de la simultanéité. Les 800 000 lignes restantes ont nécessité au moins un ordre de grandeur de temps supplémentaire pour être complétées, en moyenne. Voici les résultats de la moyenne de chaque insertion de 2 000 clients (cliquez pour agrandir) :
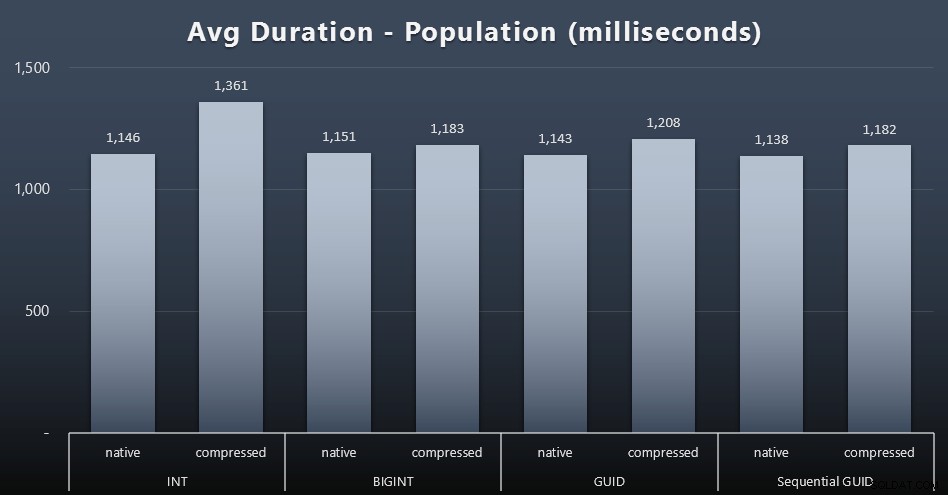
Nous voyons ici que la compression d'un INT était la seule véritable valeur aberrante - j'ai quelques théories à ce sujet, mais rien de concluant pour le moment.
Charges de travail de pagination
Les durées d'exécution moyennes des requêtes de pagination semblent également avoir été considérablement affectées par la simultanéité par rapport à mes tests isolés. Voici les résultats (cliquez pour agrandir) :
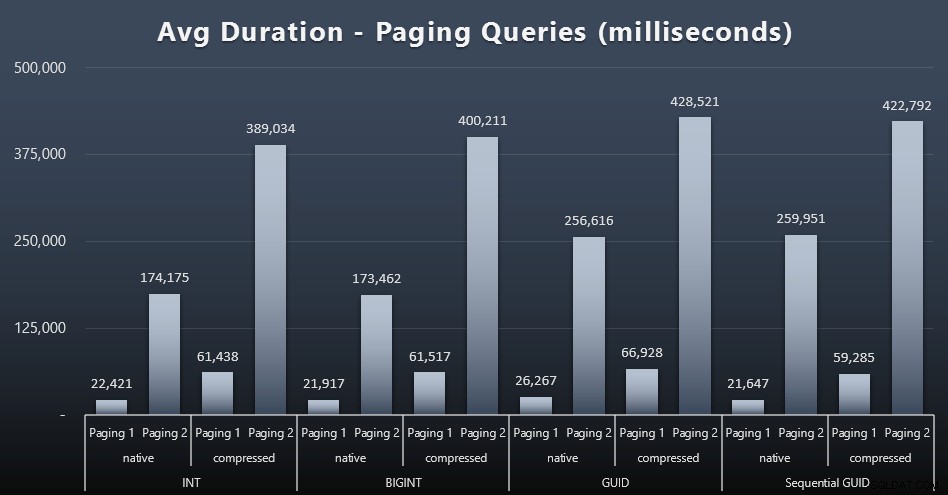
(Paging 1 =commande par CustomerID, Paging 2 =commande par LastName, FirstName.)
Nous constatons que pour la pagination 1 (ordre par CustomerID) et la pagination 2 (ordre par noms), il y a un impact significatif sur le temps d'exécution en raison de la compression (jusqu'à ~ 700 %). Les deux GUID semblent être les chevaux les plus lents de cette course, NEWID() étant le pire.
Mettre à jour les charges de travail
Les mises à jour des singletons ont été assez rapides, même en cas de forte concurrence, mais il y avait encore des différences notables dues à la compression, et même des différences surprenantes entre les types de données (cliquez pour agrandir) :
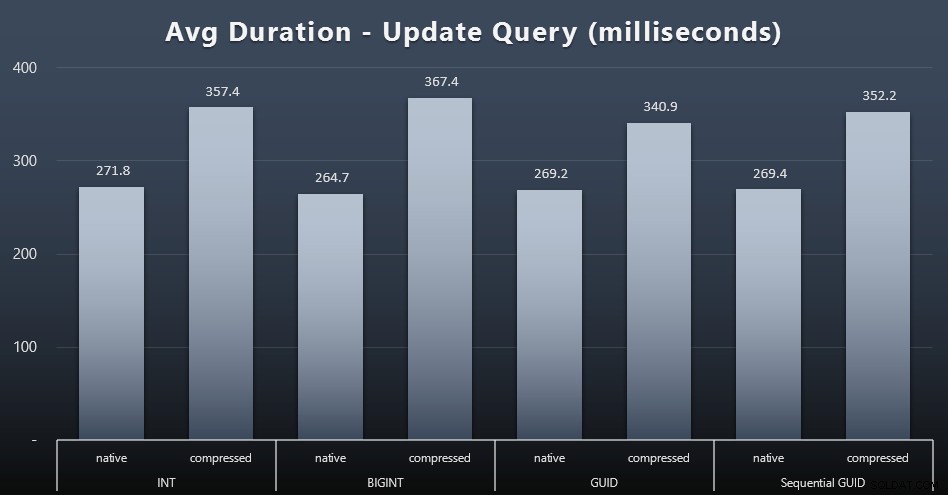
Plus particulièrement, les mises à jour des lignes contenant des valeurs GUID étaient en fait plus rapides que les mises à jour contenant INT/BIGINT, lorsque la compression était en cours d'utilisation. Avec le stockage natif, les différences étaient moins notables (mais INT y était toujours perdant).
Statistiques de déclenchement
Voici les durées d'exécution moyennes et maximales pour le déclencheur simple dans chaque cas (cliquez pour agrandir) :
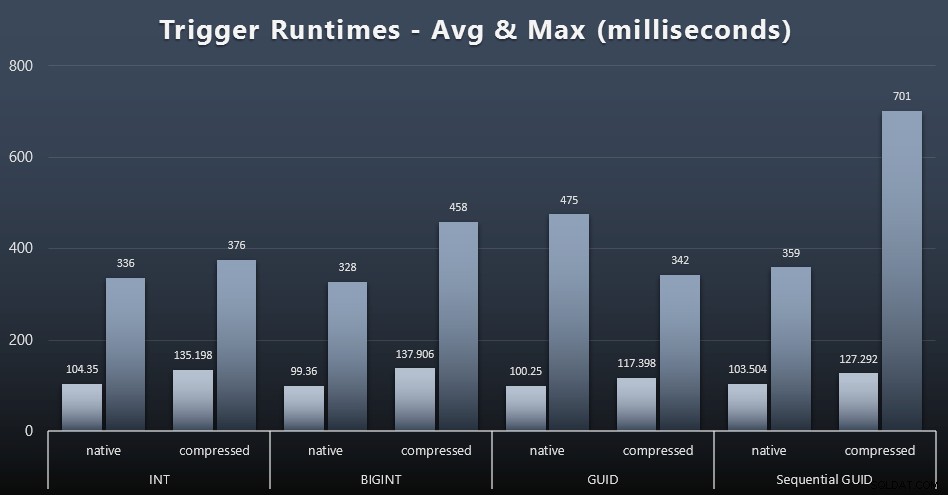
La compression semble avoir un impact beaucoup plus important ici que le choix du type de données (bien que cela serait probablement plus prononcé si une partie de ma charge de travail de mise à jour avait mis à jour de nombreuses lignes au lieu de se composer uniquement de recherches sur une seule ligne). Le maximum pour le GUID séquentiel est clairement une valeur aberrante quelconque sur laquelle je n'ai pas enquêté (vous pouvez dire qu'il est insignifiant sur la base de la moyenne toujours en ligne dans tous les domaines).
Qu'attendaient ces requêtes ?
Après chaque charge de travail, j'ai également examiné les principales attentes du système, en supprimant les attentes évidentes de la file d'attente/du minuteur (comme décrit par Paul Randal) et les activités non pertinentes des logiciels de surveillance (comme TRACEWRITE ). Voici les 3 attentes les plus fréquentes dans chaque cas (cliquez pour agrandir) :
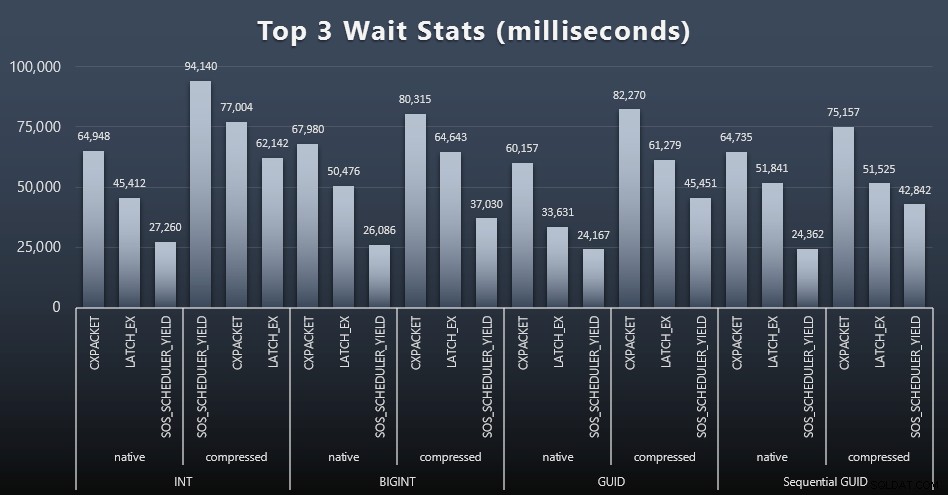
Dans la plupart des cas, les attentes étaient CXPACKET, puis LATCH_EX, puis SOS_SCHEDULER_YIELD. Dans le cas d'utilisation impliquant des nombres entiers et la compression, cependant, SOS_SCHEDULER_YIELD a pris le relais, ce qui implique pour moi une certaine inefficacité dans l'algorithme de compression des nombres entiers (ce qui peut être complètement indépendant de l'algorithme utilisé pour compresser les BIGINT en INT). Je n'ai pas approfondi cette question et je n'ai pas non plus trouvé de justification pour le suivi des attentes par requête individuelle.
Espace disque / Fragmentation
Bien que j'aie tendance à convenir qu'il ne s'agit pas d'espace disque, c'est toujours une métrique qui mérite d'être présentée. Même dans ce cas très simpliste où il n'y a qu'une seule table et la clé n'est pas présente dans toutes les autres tables liées (qui existeraient sûrement dans une application réelle), la différence est significative. Regardons d'abord le reserved colonne de sp_spaceused (cliquez pour agrandir) :
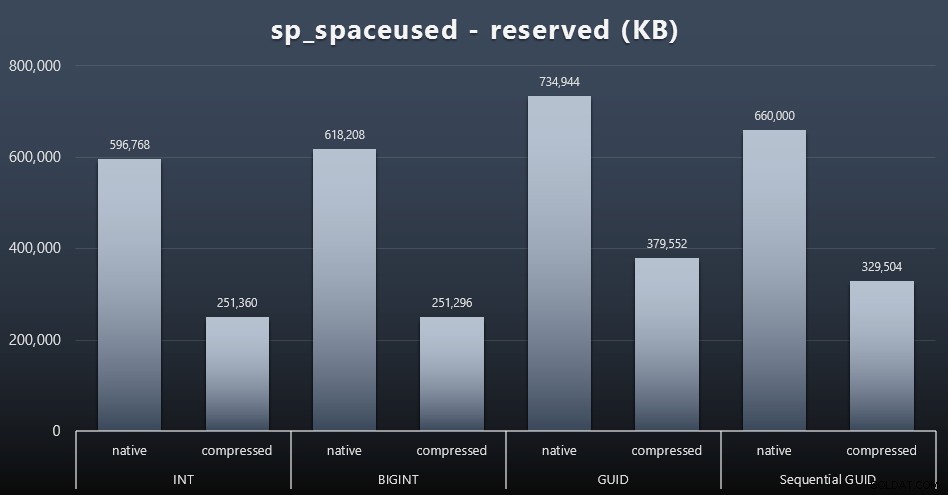
Ici, BIGINT n'a pris qu'un peu plus d'espace que INT, et GUID (comme prévu) a fait un saut plus important. Le GUID séquentiel a eu une augmentation moins importante de l'espace utilisé et a également été bien mieux compressé que le GUID traditionnel. Encore une fois, pas de surprises ici - un GUID est plus grand qu'un nombre, point final. Maintenant, les partisans du GUID pourraient faire valoir que le prix que vous payez en termes d'espace disque n'est pas si élevé (18 % par rapport à BIGINT sans compression, environ 50 % avec compression). Mais rappelez-vous qu'il s'agit d'une seule table de 1 million de lignes. Imaginez comment cela va extrapoler lorsque vous avez 10 millions de clients et que beaucoup d'entre eux ont 10, 30 ou 500 commandes :ces clés peuvent être répétées dans une douzaine d'autres tableaux et occuper le même espace supplémentaire dans chaque ligne.
Lorsque j'ai examiné la fragmentation après chaque charge de travail (rappelez-vous, aucune maintenance d'index n'est effectuée) à l'aide de cette requête :
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Les résultats ont donné des visuels beaucoup moins intéressants; tous les index non clusterisés étaient fragmentés à plus de 99 %. Les index groupés, cependant, étaient soit très fortement fragmentés, soit pas fragmentés du tout (cliquez pour agrandir) :
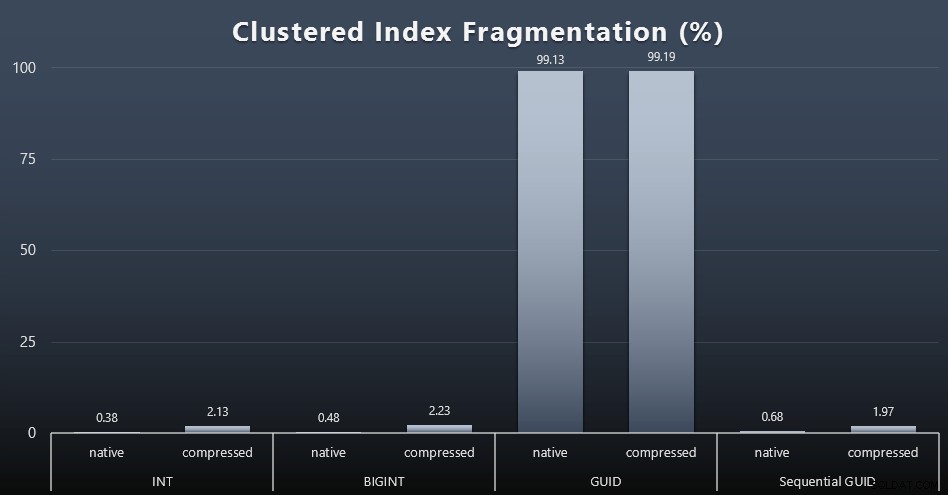
La fragmentation est une autre mesure qui signifie souvent beaucoup moins quand on parle de SSD, mais il est important de noter tout de même, car tous les systèmes ne peuvent pas se permettre d'ignorer parfaitement l'impact que la fragmentation peut avoir sur les modèles d'E/S. Je pense qu'en utilisant des GUID non séquentiels, sur un système plus lié aux E/S, l'impact de cette fragmentation seule serait considérablement amplifié sur la plupart des autres métriques de ce test.
Utilisation du pool de tampons
C'est là qu'être judicieux quant à la quantité d'espace disque utilisée par vos tables est vraiment payant - plus vos tables sont grandes, plus elles occupent d'espace dans le pool de mémoire tampon. Déplacer des données dans et hors du pool de mémoire tampon coûte cher, et encore une fois, il s'agit d'un cas très simpliste où les tests ont été exécutés de manière isolée et où il n'y avait pas d'autres applications et bases de données sur l'instance en concurrence pour la précieuse mémoire.
Il s'agit d'une simple mesure de la requête suivante à la fin de chaque charge de travail :
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE Clerk_name =N'Buffer Pool' ;
Résultats (cliquez pour agrandir) :
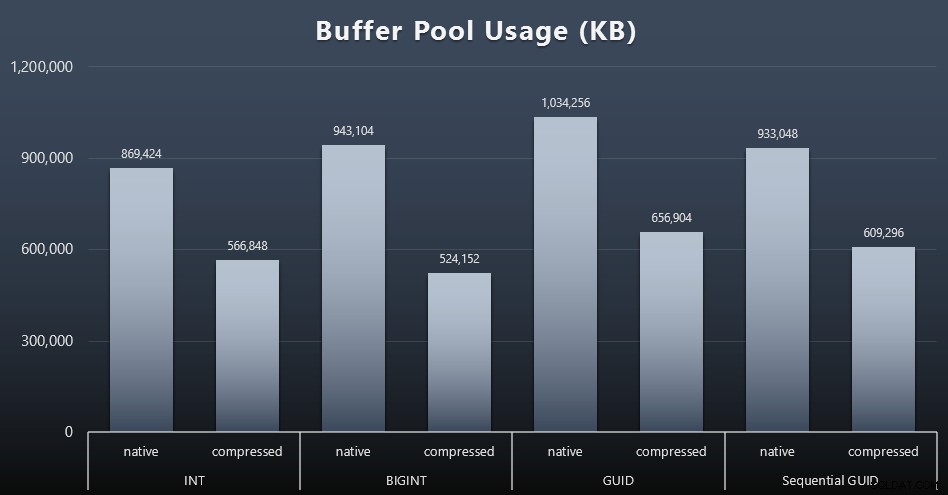
Bien que la majeure partie de ce graphique ne soit pas du tout surprenante - GUID prend plus d'espace que BIGINT, BIGINT plus que INT - j'ai trouvé intéressant qu'un GUID séquentiel prenne moins de place qu'un BIGINT, même sans compression. J'ai pris note d'effectuer des analyses au niveau de la page afin de déterminer quel type d'efficacité a lieu ici sous les couvertures.
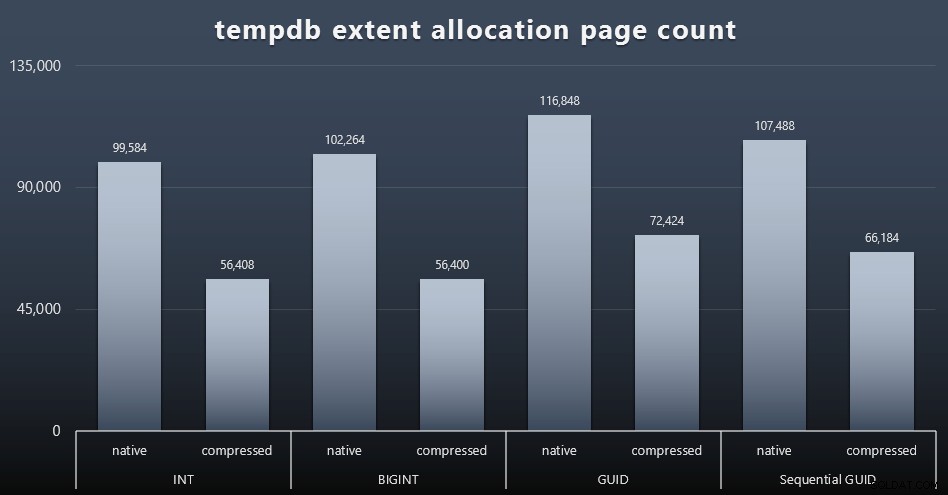
Utilisation de tempdb
Je ne suis pas sûr de ce à quoi je m'attendais ici, mais après chaque charge de travail, j'ai rassemblé le contenu des trois DMV d'utilisation de l'espace liés à tempdb, sys.dm_db_file|session|task_space_usage . Le seul qui semblait montrer une volatilité basée sur le type de données était sys.dm_db_file_space_usage extent_allocation_page_count de . Cela montre que - du moins dans ma configuration et cette charge de travail spécifique - les GUID soumettront tempdb à un entraînement légèrement plus approfondi (cliquez pour agrandir) :
"Mauvais" fractionnements de page
L'une des choses que je voulais mesurer était l'impact sur les fractionnements de page - pas les fractionnements de page normaux (lorsque vous ajoutez une nouvelle page) mais lorsque vous devez réellement déplacer des données entre les pages pour faire de la place pour plus de lignes. Jonathan Kehayias en parle plus en détail dans son article de blog, "Tracking Problematic Pages Splits in SQL Server 2012 Extended Events - No Really This Time!", qui fournit également la base de la session Extended Events que j'ai utilisée pour capturer les données :
CREATE EVENT SESSION [BadPageSplits] ON SERVER ADD EVENT sqlserver.transaction_log (WHERE operation =11 AND database_id =10) ADD TARGET package0.histogram ( SET filtering_event_name ='sqlserver.transaction_log', source_type =0, source ='alloc_unit_id' ); SESSION D'ÉVÉNEMENT GOALTER [BadPageSplits] SUR L'ÉTAT DU SERVEUR =START;GO
Et la requête que j'ai utilisée pour le tracer :
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='histogramme' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name ; Et voici les résultats (cliquez pour agrandir) :
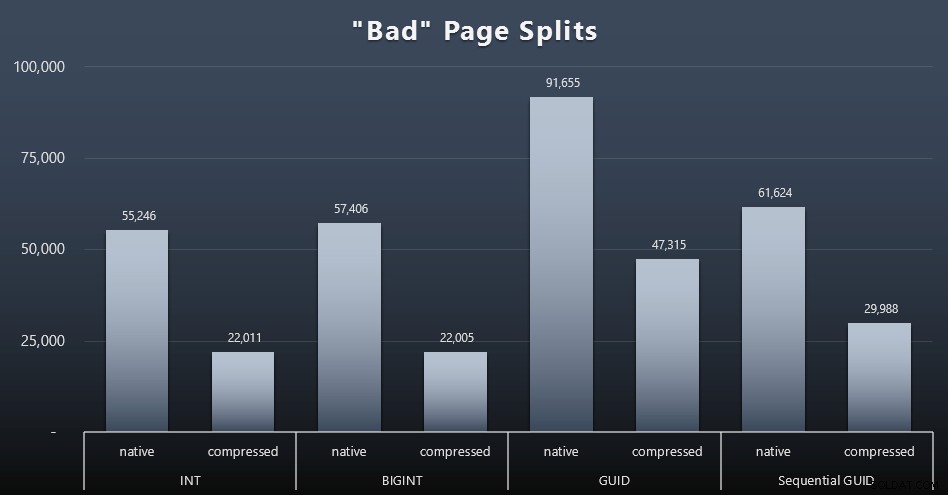
Bien que j'aie déjà noté que dans mon scénario (où j'exécute sur des SSD rapides), la différence incontestable d'activité d'E/S n'a pas d'impact direct sur le temps d'exécution global, il s'agit toujours d'une mesure que vous voudrez prendre en compte, en particulier si vous n'avez pas de SSD ou si votre charge de travail est déjà liée aux E/S.
Conclusion
Bien que ces tests m'aient ouvert un peu plus les yeux sur la façon dont mes perceptions de longue date ont été modifiées par du matériel plus moderne, je suis toujours fermement opposé au gaspillage d'espace sur le disque ou en mémoire. Alors que j'ai essayé de démontrer un certain équilibre et de laisser briller les GUID, il y a très peu ici du point de vue des performances pour prendre en charge le passage de INT/BIGINT à l'une ou l'autre forme de UNIQUEIDENTIFIER - à moins que vous n'en ayez besoin pour d'autres raisons moins tangibles (telles que la création de la clé dans l'application ou le maintien de valeurs de clé uniques sur des systèmes disparates). Un résumé rapide, montrant que NEWID() est le pire choix parmi de nombreuses métriques où il y avait une différence substantielle (et dans la plupart de ces cas, NEWSEQUENTIALID() était juste derrière) :
| Métrique | Effacer le(s) perdant(s) ? |
|---|---|
| Inserts non contestés | – dessiner – |
| Charge de travail simultanée | – dessiner – |
| Requêtes individuelles – Population | INT (compressé) |
| Requêtes individuelles – Paging | NEWID() / NEWSEQUENTIALID() |
| Requêtes individuelles – Mise à jour | INT (natif) / BIGINT (compressé) |
| Requêtes individuelles – déclencheur APRÈS | – dessiner – |
| Espace disque | NEWID() |
| Fragmentation d'index cluster | NEWID() |
| Utilisation du pool de tampons | NEWID() |
| Utilisation de tempdb | NEWID() |
| "Mauvais" fractionnements de page | NEWID() |
Tableau 2 : les plus grands perdants
N'hésitez pas à tester ces choses par vous-même; Je peux assembler mon ensemble complet de scripts si vous souhaitez les exécuter dans votre propre environnement. L'objectif court de tout cet article est assez simple :il existe de nombreuses mesures importantes à prendre en compte en dehors de l'impact prévisible sur l'espace disque, il ne doit donc pas être utilisé seul comme argument dans les deux sens.
Maintenant, je ne veux pas que cette ligne de pensée se limite aux clés en soi. Il faut vraiment y penser chaque fois qu'un choix de type de données est fait. Je vois datetime étant souvent choisi, par exemple, lorsque seule une date ou smalldatetime est nécessaire. Sur les tables transactionnelles, cela peut également générer beaucoup d'espace disque gaspillé, et cela se répercute également sur certaines de ces autres ressources.
Dans un futur test, j'aimerais comparer les résultats d'une table beaucoup plus grande (> 2 milliards de lignes). Je peux simuler cela avec INT en définissant la graine d'identité sur -2 milliards, ce qui permet d'avoir environ 4 milliards de lignes. Et j'aimerais que les comparaisons de charge de travail et d'espace disque/d'empreinte mémoire impliquent plus d'une seule table, car l'un des avantages d'une clé maigre est que cette clé est représentée dans des dizaines de tables associées. Je surveillais les événements de croissance automatique, mais il n'y en avait pas, car la base de données était suffisamment grande pour s'adapter à la croissance, et je n'ai pas pensé à mesurer l'utilisation réelle du journal dans le fichier journal existant, donc j'aimerais tester à nouveau avec les valeurs par défaut pour la taille du journal et la croissance automatique, et cette fois en mesurant DBCC SQLPERF(LOGSPACE); . Il serait également intéressant de chronométrer les reconstructions et de mesurer l'utilisation des journaux à la suite de ces opérations. Enfin, j'aimerais faire des E/S un facteur plus pertinent en trouvant un serveur avec des disques durs mécaniques - je sais qu'il y en a beaucoup, mais dans certains magasins, ils sont assez rares.