Dans la première partie de cette série de blogs, j'ai présenté quelques résultats de référence montrant comment les performances de PostgreSQL OLTP ont changé depuis la version 8.3, publiée en 2008. Dans cette partie, je prévois de faire la même chose mais pour les requêtes analytiques/BI, le traitement de grandes quantités de données.
Il existe un certain nombre de références de l'industrie pour tester cette charge de travail, mais la plus couramment utilisée est probablement TPC-H, c'est donc ce que je vais utiliser pour ce billet de blog. Il existe également TPC-DS, une autre référence TPC pour tester les systèmes d'aide à la décision, qui peut être considérée comme une évolution ou un remplacement de TPC-H. J'ai décidé de m'en tenir à TPC-H pour plusieurs raisons.
Premièrement, TPC-DS est beaucoup plus complexe, à la fois en termes de schéma (plus de tables) et de nombre de requêtes (22 contre 99). Le régler correctement, en particulier lorsqu'il s'agit de plusieurs versions de PostgreSQL, serait beaucoup plus difficile. Deuxièmement, certaines des requêtes TPC-DS utilisent des fonctionnalités qui ne sont pas prises en charge par les anciennes versions de PostgreSQL (par exemple, les ensembles de regroupement), ce qui rend ces requêtes non pertinentes pour certaines versions. Et enfin, je dirais que les gens connaissent bien mieux TPC-H que TPC-DS.
L'objectif n'est pas de permettre une comparaison avec d'autres produits de base de données, mais uniquement de fournir une caractérisation raisonnable à long terme de l'évolution des performances de PostgreSQL depuis PostgreSQL 8.3.
Remarque :Pour une analyse très intéressante du benchmark TPC-H, je recommande fortement l'article "TPC-H Analyzed :Hidden Messages and Lessons Learned from an Influential Benchmark" de Boncz, Neumann et Erling.
Le matériel
La plupart des résultats de cet article de blog proviennent de la "plus grande boîte" que j'ai dans notre bureau, qui a ces paramètres :
- 2x E5-2620 v4 (16 cœurs, 32 threads)
- 64 Go de RAM
- SSD Intel Optane 900P 280 Go NVMe (données)
- 3 x 7.2k SATA RAID0 (tablespace temporaire)
- noyau 5.6.15, système de fichiers ext4
Je suis sûr que vous pouvez acheter des machines beaucoup plus robustes, mais je pense que c'est assez bon pour nous donner des données pertinentes. Il y avait deux variantes de configuration - une avec le parallélisme désactivé, une avec le parallélisme activé. La plupart des valeurs des paramètres sont les mêmes dans les deux cas, adaptées aux ressources matérielles disponibles (CPU, RAM, stockage). Vous trouverez des informations plus détaillées sur la configuration à la fin de cet article.
La référence
Je tiens à préciser très clairement que mon objectif n'est pas de mettre en œuvre un référentiel TPC-H valide qui pourrait satisfaire à tous les critères requis par le TPC. Mon objectif est d'évaluer l'évolution des performances de différentes requêtes analytiques au fil du temps, et non de rechercher une mesure abstraite des performances par dollar ou quelque chose du genre.
J'ai donc décidé de n'utiliser qu'un sous-ensemble de TPC-H - chargez simplement les données et exécutez les 22 requêtes (mêmes paramètres sur toutes les versions). Il n'y a pas d'actualisation des données, l'ensemble de données est statique après le chargement initial. J'ai choisi un certain nombre de facteurs d'échelle, 1, 10 et 75, de sorte que nous ayons des résultats pour les ajustements dans les tampons partagés (1), les ajustements en mémoire (10) et plus que la mémoire (75) . J'irais pour 100 pour en faire une "belle séquence", qui ne rentrerait pas dans le stockage de 280 Go dans certains cas (grâce aux index, aux fichiers temporaires, etc.). Notez que le facteur d'échelle 75 n'est même pas reconnu par TPC-H comme un facteur d'échelle valide.
Mais est-il même judicieux de comparer des ensembles de données de 1 Go ou 10 Go ? Les gens ont tendance à se concentrer sur des bases de données beaucoup plus volumineuses, il peut donc sembler un peu insensé de s'embêter à les tester. Mais je ne pense pas que ce serait utile - la grande majorité des bases de données dans la nature est assez petite, d'après mon expérience Et même lorsque toute la base de données est grande, les gens ne travaillent généralement qu'avec un petit sous-ensemble de celle-ci - des données récentes, commandes non résolues, etc. Je pense donc qu'il est logique de tester même avec ces petits ensembles de données.
Charges de données
Voyons d'abord combien de temps il faut pour charger les données dans la base de données - sans et avec parallélisme. Je ne montrerai que les résultats de l'ensemble de données de 75 Go, car le comportement global est presque le même pour les plus petits cas.
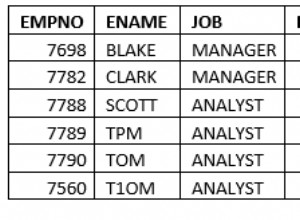
Durée de chargement des données TPC-H – échelle de 75 Go, pas de parallélisme
Vous pouvez clairement voir qu'il y a une tendance constante d'amélioration, réduisant d'environ 30 % la durée simplement en améliorant l'efficacité dans les quatre étapes - COPIER, créer des clés primaires et des index, et (surtout) configurer des clés étrangères. L'amélioration "alter" de la 9.2 est particulièrement nette.
| COPIER | PKEYS | INDEXES | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Voyons maintenant comment l'activation du parallélisme modifie le comportement. Le tableau suivant compare les résultats avec le parallélisme activé - marqués d'un "(p)" - aux résultats avec le parallélisme désactivé.
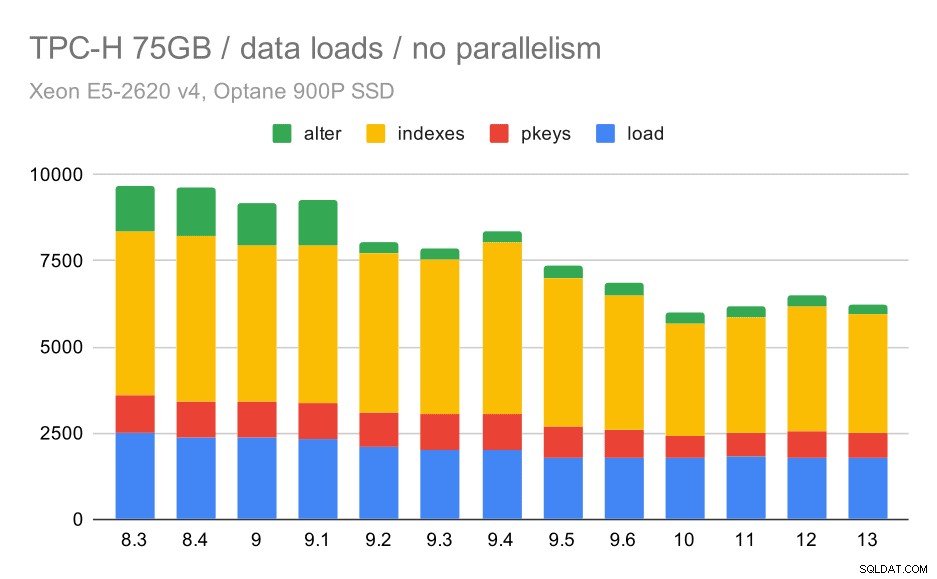
Durée de chargement des données TPC-H – échelle de 75 Go, parallélisme activé.
Malheureusement, il semble que l'effet du parallélisme soit très limité dans ce test - cela aide un peu, mais les différences sont assez faibles. L'amélioration globale reste donc d'environ 30 %.
| COPIER | PKEYS | INDEXES | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Requêtes
Nous pouvons maintenant examiner les requêtes. TPC-H a 22 modèles de requêtes - j'ai généré un ensemble de requêtes réelles et les ai exécutées deux fois sur toutes les versions - d'abord après avoir supprimé tous les caches et redémarré l'instance, puis avec le cache réchauffé. Tous les chiffres présentés dans les graphiques sont les meilleurs de ces deux séries (dans la plupart des cas, c'est la deuxième, bien sûr).
Pas de parallélisme
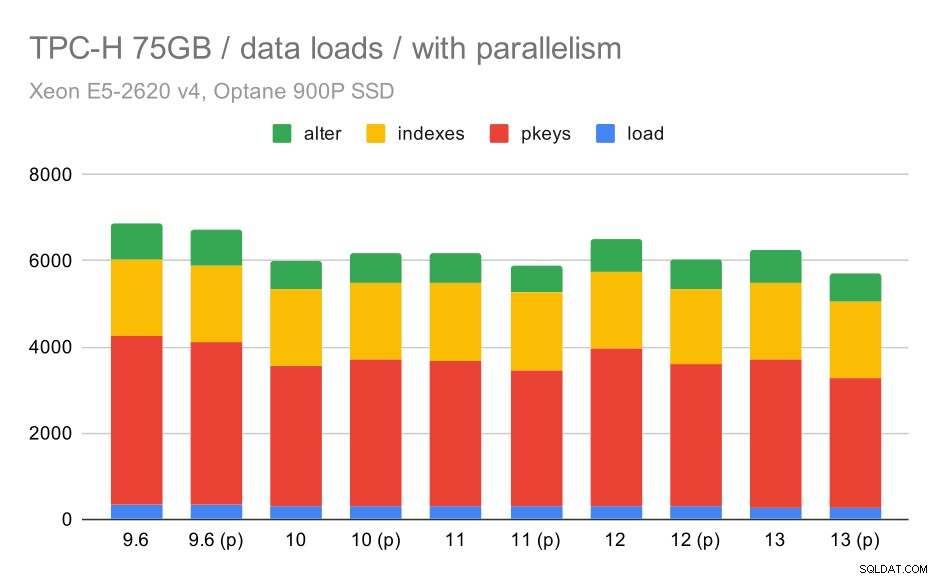
Sans parallélisme, les résultats sur le plus petit ensemble de données sont assez clairs - chaque barre est divisée en plusieurs parties avec des couleurs différentes pour chacune des 22 requêtes. Il est difficile de dire quelle partie correspond à quelle requête exacte, mais c'est suffisant pour identifier les cas où une requête s'améliore ou s'aggrave entre deux exécutions. Par exemple, dans le premier graphique, il est très clair que Q21 est devenu beaucoup plus rapide entre 8,3 et 8,4.
Requêtes TPC-H sur un petit ensemble de données (1 Go) – parallélisme désactivé
Pour l'échelle de 10 Go, les résultats sont quelque peu difficiles à interpréter, car sur 8.3, l'une des requêtes (Q21) prend tellement de temps à s'exécuter qu'elle éclipse tout le reste.
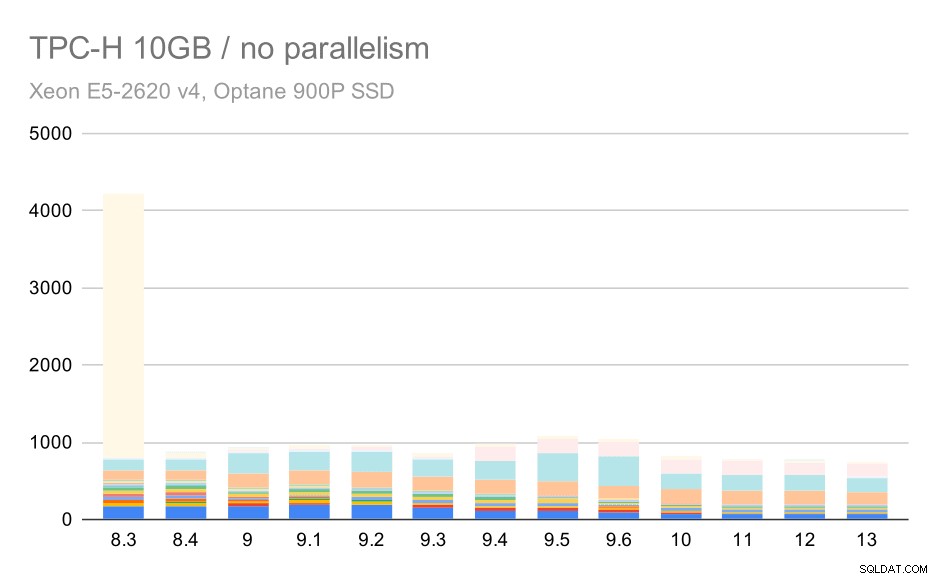
Requêtes TPC-H sur un ensemble de données moyen (10 Go) – parallélisme désactivé
Voyons donc à quoi ressemblerait le graphique sans Q21 :
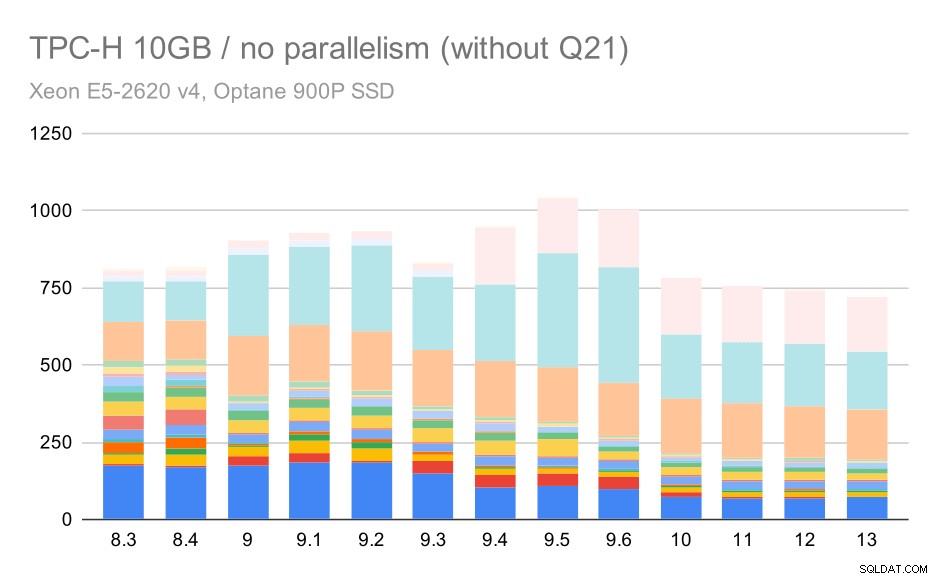
Requêtes TPC-H sur un jeu de données moyen (10 Go) - parallélisme désactivé, sans Q2 problématique
OK, c'est plus facile à lire. Nous pouvons clairement voir que la plupart des requêtes (jusqu'à Q17) sont devenues plus rapides, mais ensuite deux des requêtes (Q18 et Q20) sont devenues un peu plus lentes. Nous verrons un problème similaire sur le plus grand ensemble de données, je vais donc discuter de ce qui pourrait être la cause première.
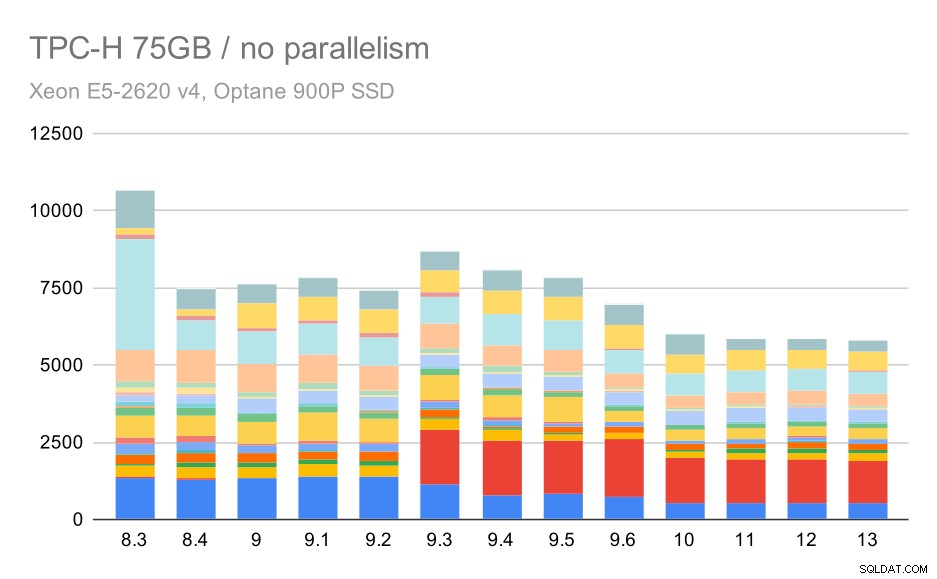
Requêtes TPC-H sur un grand ensemble de données (75 Go) - parallélisme désactivé
Encore une fois, nous constatons une augmentation soudaine pour l'une des requêtes de la version 9.3 :cette fois, il s'agit du deuxième trimestre, sans quoi le graphique ressemble à ceci :
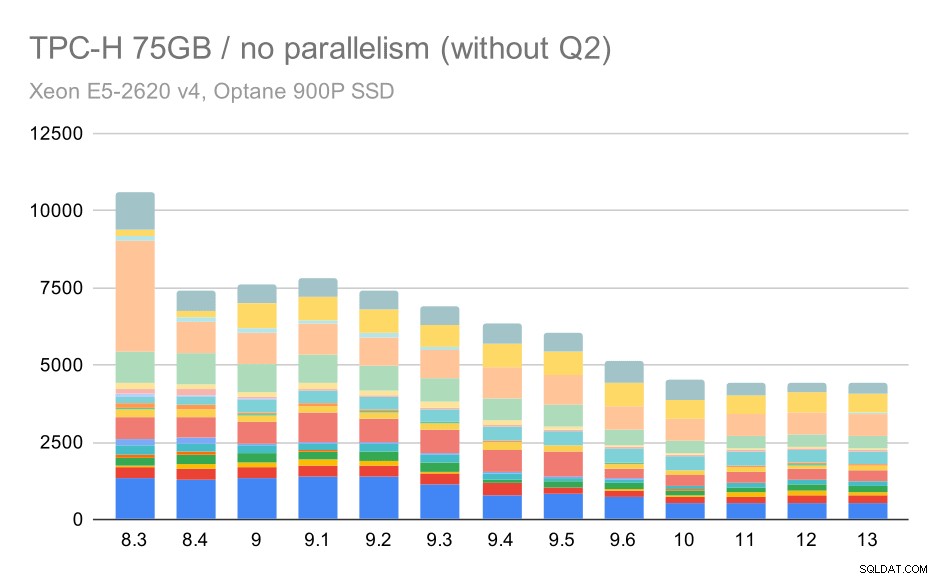
Requêtes TPC-H sur un grand ensemble de données (75 Go) - parallélisme désactivé, sans problème Q2
C'est une assez belle amélioration en général, accélérant toute l'exécution de ~ 2,7 heures à seulement ~ 1,2 h, simplement en rendant le planificateur et l'optimiseur plus intelligents, et en rendant l'exécuteur plus efficace (rappelez-vous, le parallélisme a été désactivé dans ces exécutions) .
Alors, quel pourrait être le problème avec Q2, le rendant plus lent en 9.3 ? La réponse simple est que chaque fois que vous rendez le planificateur et l'optimiseur plus intelligents - soit en construisant de nouveaux types de chemins/plans, soit en le rendant dépendant de certaines statistiques, cela signifie également que de nouvelles erreurs peuvent être commises lorsque les statistiques ou les estimations sont fausses. Dans Q2, la clause WHERE fait référence à une sous-requête agrégée. Une version simplifiée de la requête pourrait ressembler à ceci :
Sélectionnez 1From Partsuppwhere PS_SUPPLYCOST =(SELECT MIN (PS_SUPPLYCOST) De Partsupp, Fournisseur, Nation, région où P_PARTKEY =PS_PARTKEY et S_SUPPKEY =PS_SUPPKEY et S_NATIONKEY =N_NATIONKEY et N_REGIONKELe problème est que nous ne connaissons pas la valeur moyenne au moment de la planification, ce qui rend impossible le calcul d'estimations suffisamment bonnes pour la condition WHERE. Le Q2 réel contient des jointures supplémentaires, et leur planification dépend fondamentalement de bonnes estimations des relations jointes. Dans les anciennes versions, l'optimiseur semble avoir fait ce qu'il fallait, mais dans la version 9.3, nous l'avons rendu plus intelligent d'une certaine manière, mais avec une mauvaise estimation, il ne parvient pas à prendre la bonne décision. En d'autres termes, les bons plans des anciennes versions n'étaient que de la chance, grâce aux limitations du planificateur.
Je parierais que les régressions de Q18 et Q20 sur le plus petit ensemble de données sont également causées par quelque chose de similaire, bien que je n'aie pas étudié celles-ci en détail.
Je pense que certains de ces problèmes d'optimisation pourraient être résolus en ajustant les paramètres de coût (par exemple, random_page_cost, etc.), mais je n'ai pas essayé cela en raison de contraintes de temps. Cela montre cependant que les mises à niveau n'améliorent pas automatiquement toutes les requêtes. Parfois, une mise à niveau peut déclencher une régression. Il est donc conseillé de tester votre application de manière appropriée.
Parallélisme
Voyons donc dans quelle mesure le parallélisme des requêtes modifie les résultats. Encore une fois, nous n'examinerons que les résultats des versions depuis la version 9.6 étiquetant les résultats avec "(p)" lorsque la requête parallèle est activée.
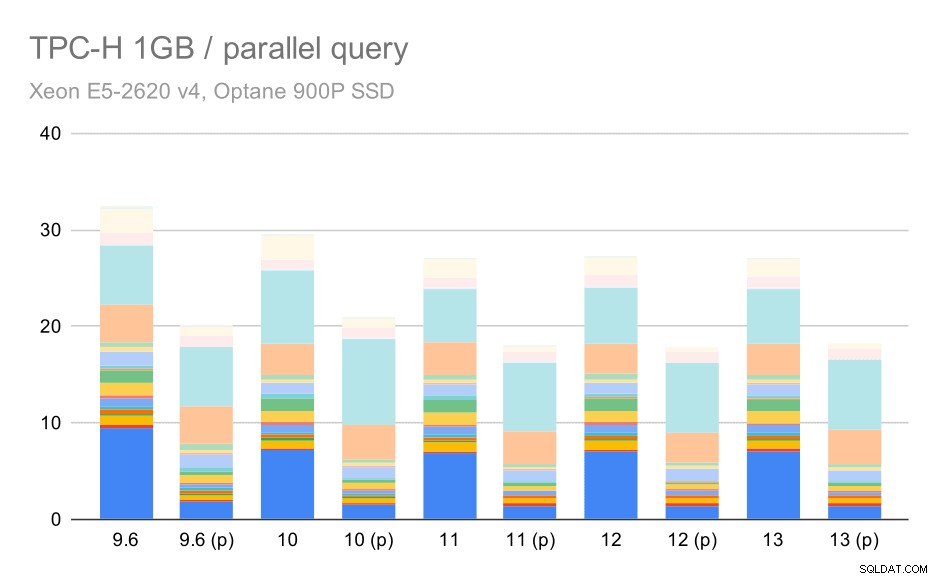
Requêtes TPC-H sur un petit ensemble de données (1 Go) – parallélisme activé
De toute évidence, le parallélisme aide un peu - il réduit d'environ 30% même sur ce petit ensemble de données. Sur l'ensemble de données moyen, il n'y a pas beaucoup de différence entre les exécutions régulières et parallèles :
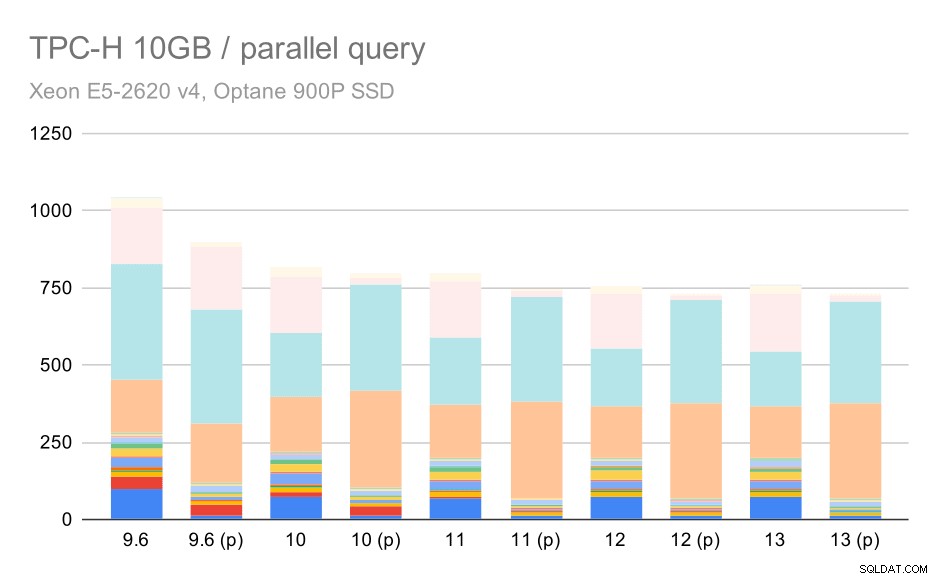
Requêtes TPC-H sur un ensemble de données moyen (10 Go) – parallélisme activé
Il s'agit d'une autre démonstration du problème déjà abordé :l'activation du parallélisme permet d'envisager des plans de requête supplémentaires, et il est clair que les estimations ou les coûts ne correspondent pas à la réalité, ce qui entraîne de mauvais choix de plans.
Et enfin le grand ensemble de données, où les résultats complets ressemblent à ceci :
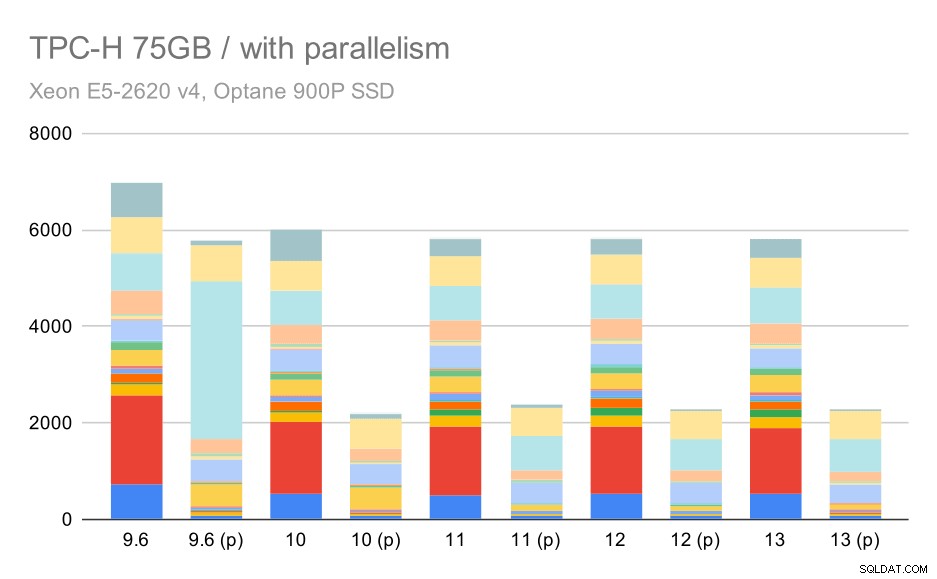
Requêtes TPC-H sur un grand ensemble de données (75 Go) – parallélisme activé
Ici, l'activation du parallélisme fonctionne à notre avantage - l'optimiseur parvient à créer un plan parallèle moins cher pour Q2, annulant le mauvais choix de plan introduit dans 9.3. Mais juste pour être complet, voici les résultats sans Q2.
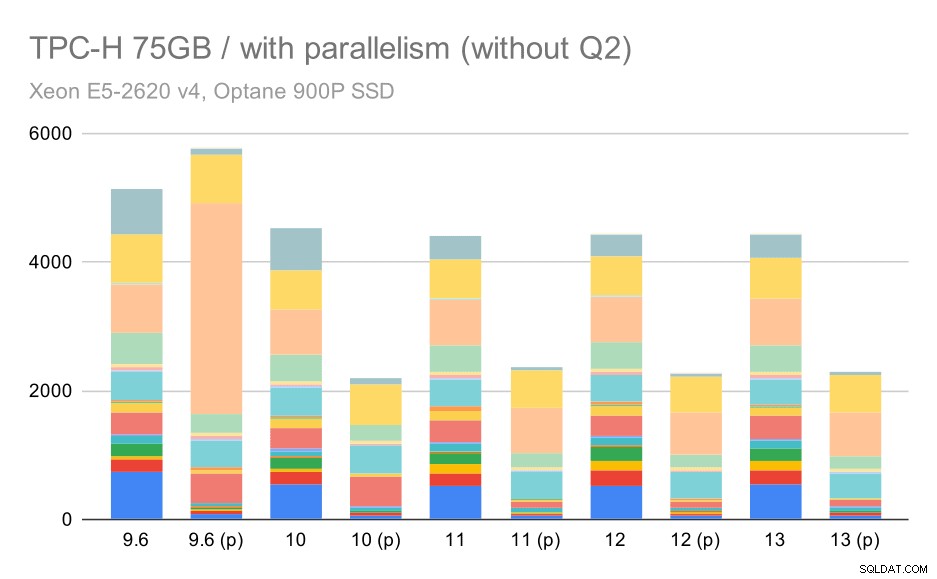
Requêtes TPC-H sur un grand ensemble de données (75 Go) - parallélisme activé, sans Q2 problématique
Même ici, vous pouvez repérer de mauvais choix de plans parallèles - par exemple, le plan parallèle pour Q9 est pire jusqu'à 11 où il devient plus rapide - probablement grâce à 11 nœuds d'exécution parallèles supplémentaires. D'autre part, certaines requêtes parallèles (Q18, Q20) ralentissent sur 11, il n'y a donc pas que des arcs-en-ciel et des licornes.
Résumé et avenir
Je pense que ces résultats démontrent bien les optimisations mises en œuvre depuis PostgreSQL 8.3. Les tests avec le parallélisme désactivé illustrent les améliorations d'efficacité (c'est-à-dire en faire plus avec la même quantité de ressources) - les chargements de données sont devenus environ 30 % plus rapides et les requêtes environ 2 fois plus rapides. Il est vrai que j'ai rencontré des problèmes avec des plans de requête inefficaces, mais c'est un risque inhérent à l'amélioration de l'intelligence du planificateur de requêtes. Nous travaillons en permanence pour rendre les résultats plus fiables, et je suis sûr que je pourrais atténuer la plupart de ces problèmes en ajustant un peu la configuration.
Les résultats avec le parallélisme activé montrent que nous pouvons utiliser efficacement des ressources supplémentaires (cœurs CPU en particulier). Les chargements de données ne semblent pas beaucoup en bénéficier - du moins pas dans ce benchmark, mais l'impact sur l'exécution des requêtes est significatif, ce qui entraîne une accélération ~2x (bien que différentes requêtes soient affectées différemment, bien sûr).
Il existe de nombreuses possibilités d'améliorer cela dans les futures versions de PostgreSQL. Par exemple, il existe une série de correctifs implémentant le parallélisme pour COPY, accélérant les chargements de données. Il existe divers correctifs améliorant l'exécution des requêtes analytiques - des petites optimisations localisées aux grands projets comme le stockage et l'exécution en colonnes, le push-down agrégé, etc. On peut également gagner beaucoup en utilisant le partitionnement déclaratif - une fonctionnalité que j'ai surtout ignorée en travaillant dessus référence, simplement parce que cela augmenterait trop la portée. Et je suis sûr qu'il existe de nombreuses autres opportunités que je ne peux même pas imaginer, mais des personnes plus intelligentes de la communauté PostgreSQL y travaillent déjà.
Annexe :Configuration de PostgreSQL
Parallélisme désactivé
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimiseurdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB
Parallélisme activé
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimiseurdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB