Les problèmes de décalage de réplication dans PostgreSQL ne sont pas un problème répandu pour la plupart des configurations. Cependant, cela peut se produire et, le cas échéant, cela peut avoir un impact sur vos configurations de production. PostgreSQL est conçu pour gérer plusieurs threads, tels que le parallélisme des requêtes ou le déploiement de threads de travail pour gérer des tâches spécifiques en fonction des valeurs attribuées dans la configuration. PostgreSQL est conçu pour gérer des charges lourdes et stressantes, mais parfois (en raison d'une mauvaise configuration) votre serveur peut encore aller vers le sud.
Identifier le décalage de réplication dans PostgreSQL n'est pas une tâche compliquée à faire, mais il existe plusieurs approches différentes pour examiner le problème. Dans ce blog, nous verrons ce qu'il faut regarder lorsque votre réplication PostgreSQL est en retard.
Types de réplication dans PostgreSQL
Avant de plonger dans le sujet, voyons d'abord comment la réplication dans PostgreSQL évolue car il existe divers ensembles d'approches et de solutions en matière de réplication.
Warm standby pour PostgreSQL a été implémenté dans la version 8.2 (en 2006) et était basé sur la méthode d'envoi de journaux. Cela signifie que les enregistrements WAL sont directement déplacés d'un serveur de base de données à un autre pour être appliqués, ou simplement une approche analogue à PITR, ou très similaire à ce que vous faites avec rsync.
Cette approche, même ancienne, est encore utilisée aujourd'hui et certaines institutions préfèrent d'ailleurs cette approche plus ancienne. Cette approche implémente un envoi de journaux basé sur des fichiers en transférant les enregistrements WAL un fichier (segment WAL) à la fois. Bien qu'il ait un inconvénient; Une panne majeure sur les serveurs primaires, les transactions non encore expédiées seront perdues. Il y a une fenêtre pour la perte de données (vous pouvez régler cela en utilisant le paramètre archive_timeout, qui peut être réglé sur quelques secondes seulement, mais un réglage aussi bas augmentera considérablement la bande passante requise pour l'envoi de fichiers).
Dans PostgreSQL version 9.0, la réplication en continu a été introduite. Cette fonctionnalité nous a permis de rester plus à jour par rapport à l'envoi de journaux basé sur des fichiers. Son approche consiste à transférer des enregistrements WAL (un fichier WAL est composé d'enregistrements WAL) à la volée (un simple envoi de journaux basé sur des enregistrements), entre un serveur maître et un ou plusieurs serveurs de secours. Ce protocole n'a pas besoin d'attendre que le fichier WAL soit rempli, contrairement à l'envoi de journaux basé sur les fichiers. En pratique, un processus appelé récepteur WAL, s'exécutant sur le serveur de secours, se connectera au serveur primaire à l'aide d'une connexion TCP/IP. Dans le serveur primaire, un autre processus existe nommé WAL sender. Son rôle est d'envoyer les registres WAL au(x) serveur(s) de secours au fur et à mesure qu'ils se produisent.
Les configurations de réplication asynchrone dans la réplication en continu peuvent entraîner des problèmes tels que la perte de données ou le décalage de l'esclave, c'est pourquoi la version 9.1 introduit la réplication synchrone. Dans la réplication synchrone, chaque validation d'une transaction d'écriture attendra jusqu'à ce que la confirmation soit reçue que la validation a été écrite dans le journal à écriture anticipée sur le disque du serveur principal et du serveur de secours. Cette méthode minimise la possibilité de perte de données, car pour que cela se produise, nous aurons besoin que les deux, le maître et le standby échouent en même temps.
L'inconvénient évident de cette configuration est que le temps de réponse pour chaque transaction d'écriture augmente, car nous devons attendre que toutes les parties aient répondu. Contrairement à MySQL, il n'y a pas de support comme dans un environnement semi-synchrone de MySQL, il reviendra à asynchrone si le délai d'attente s'est produit. Ainsi, dans With PostgreSQL, le temps d'un commit est (au minimum) l'aller-retour entre le primaire et le standby. Les transactions en lecture seule ne seront pas affectées par cela.
Au fur et à mesure de son évolution, PostgreSQL s'améliore continuellement et pourtant sa réplication est diversifiée. Par exemple, vous pouvez utiliser la réplication asynchrone en continu physique ou la réplication en continu logique. Les deux sont surveillés différemment, mais utilisent la même approche lors de l'envoi de données via la réplication, qui est toujours la réplication en continu. Pour plus de détails, consultez le manuel pour différents types de solutions dans PostgreSQL concernant la réplication.
Causes du retard de réplication PostgreSQL
Comme défini dans notre blog précédent, un décalage de réplication est le coût du retard pour la ou les transaction(s) ou opération(s) calculé par sa différence de temps d'exécution entre le primaire/maître et le standby/esclave nœud.
Étant donné que PostgreSQL utilise la réplication en continu, il est conçu pour être rapide car les modifications sont enregistrées sous la forme d'un ensemble de séquences d'enregistrements de journal (octet par octet) interceptés par le récepteur WAL puis écrit ces enregistrements de journal au fichier WAL. Ensuite, le processus de démarrage par PostgreSQL rejoue les données de ce segment WAL et la réplication en continu commence. Dans PostgreSQL, un décalage de réplication peut se produire par ces facteurs :
- Problèmes de réseau
- Impossible de trouver le segment WAL du primaire. Habituellement, cela est dû au comportement de point de contrôle où les segments WAL sont tournés ou recyclés
- Nœuds occupés (principal et redondant(s)). Peut être causé par des processus externes ou par de mauvaises requêtes nécessitant beaucoup de ressources
- Mauvais matériel ou problèmes matériels entraînant un certain décalage
- Mauvaise configuration dans PostgreSQL, comme un petit nombre de max_wal_senders définis lors du traitement de tonnes de demandes de transaction (ou d'un grand volume de modifications).
Que rechercher avec le décalage de réplication PostgreSQL
La réplication PostgreSQL est encore diversifiée, mais la surveillance de la santé de la réplication est subtile mais pas compliquée. Dans cette approche, nous allons présenter sont basés sur une configuration de secours primaire avec une réplication de streaming asynchrone. La réplication logique ne peut pas bénéficier à la plupart des cas dont nous discutons ici, mais la vue pg_stat_subscription peut vous aider à collecter des informations. Cependant, nous ne nous concentrerons pas là-dessus dans ce blog.
Utilisation de la vue pg_stat_replication
L'approche la plus courante consiste à exécuter une requête faisant référence à cette vue dans le nœud principal. N'oubliez pas que vous ne pouvez récolter des informations qu'à partir du nœud principal à l'aide de cette vue. Cette vue contient la définition de table suivante basée sur PostgreSQL 11, comme illustré ci-dessous :
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Où les champs sont définis comme (inclut la version PG <10),
- pid :ID de processus du processus walsender
- usesysid :OID de l'utilisateur utilisé pour la réplication en continu.
- nom d'utilisateur :Nom de l'utilisateur utilisé pour la réplication Streaming
- nom_application :Nom de l'application connectée au maître
- adresse_client :Adresse de la réplication de secours/flux
- nom_hôte_client :Nom d'hôte de secours.
- port_client :numéro de port TCP sur lequel standby communique avec l'expéditeur WAL
- backend_start :Heure de début lorsque le SR est connecté au maître.
- backend_xmin :horizon xmin de standby rapporté par hot_standby_feedback.
- état :État actuel de l'expéditeur WAL, c'est-à-dire le streaming
- sent_lsn /sent_location :emplacement de la dernière transaction envoyé en attente.
- write_lsn /write_location :Dernière transaction écrite sur disque en veille
- flush_lsn /flush_location :Dernier vidage de transaction sur disque en veille.
- replay_lsn /replay_location :Dernier vidage de transaction sur disque en veille.
- write_lag :Temps écoulé pendant les WAL validés du primaire au standby (mais pas encore commités dans le standby)
- flush_lag :Temps écoulé pendant les WAL validés du primaire au standby (les WAL ont déjà été vidés mais pas encore appliqués)
- replay_lag :Temps écoulé pendant les WAL validés du primaire au standby (entièrement commité dans le nœud standby)
- sync_priority :Priorité du serveur de secours choisi comme serveur de secours synchrone
- sync_state :État de synchronisation de veille (est-il asynchrone ou synchrone).
Un exemple de requête ressemblerait à ceci dans PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncCela vous indique essentiellement quels blocs d'emplacement dans les segments WAL ont été écrits, vidés ou appliqués. Il vous fournit un aperçu granulaire de l'état de la réplication.
Requêtes à utiliser dans le nœud de secours
Dans le nœud de secours, il existe des fonctions prises en charge pour lesquelles vous pouvez atténuer cela dans une requête et vous fournir une vue d'ensemble de la santé de votre réplication de secours. Pour ce faire, vous pouvez exécuter la requête suivante ci-dessous (la requête est basée sur la version PG > 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Dans les anciennes versions, vous pouvez utiliser la requête suivante :
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Que dit la requête ? Les fonctions sont définies en conséquence ici,
- pg_is_in_recovery ():(booléen) Vrai si la récupération est toujours en cours.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location() : (pg_lsn) L'emplacement du journal à écriture anticipée reçu et synchronisé sur le disque par la réplication en continu.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location() : (pg_lsn) Le dernier emplacement du journal à écriture anticipée rejoué pendant la récupération. Si la récupération est toujours en cours, cela augmentera de manière monotone.
- pg_last_xact_replay_timestamp () : (horodatage avec fuseau horaire) Obtenir l'horodatage de la dernière transaction rejouée lors de la récupération.
En utilisant quelques mathématiques de base, vous pouvez combiner ces fonctions. Les fonctions les plus couramment utilisées par les DBA sont,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
ou dans les versions PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Bien que cette requête ait été mise en pratique et soit utilisée par les DBA. Pourtant, cela ne vous fournit pas une vue précise du décalage. Pourquoi? Discutons-en dans la section suivante.
Identifier le décalage causé par l'absence du segment WAL
Les nœuds de secours PostgreSQL, qui sont en mode de récupération, ne vous signalent pas l'état exact de ce qui se passe de votre réplication. Sauf si vous affichez le journal PG, vous pouvez recueillir des informations sur ce qui se passe. Il n'y a pas de requête que vous pouvez exécuter pour déterminer cela. Dans la plupart des cas, les organisations et même les petites institutions proposent des logiciels tiers pour les alerter lorsqu'une alarme est déclenchée.
L'un d'eux est ClusterControl, qui vous offre une observabilité, envoie des alertes lorsque des alarmes sont déclenchées ou récupère votre nœud en cas de sinistre ou de catastrophe. Prenons ce scénario, mon cluster de réplication de streaming asynchrone de secours principal a échoué. Comment sauriez-vous si quelque chose ne va pas ? Combinons les éléments suivants :
Étape 1 :Déterminer s'il y a un décalage
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Étape 2 :Déterminez les segments WAL reçus du nœud principal et comparez-les avec le nœud de secours
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Pour les anciennes versions de PG < 10, utilisez pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Cela semble mauvais.
Étape 3 :Déterminez à quel point cela pourrait être grave
Maintenant, mélangeons la formule de l'étape 1 et de l'étape 2 et obtenons la différence. Comment faire cela, PostgreSQL a une fonction appelée pg_wal_lsn_diff qui est définie comme,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (location pg_lsn, location pg_lsn) : (numérique) Calcule la différence entre deux emplacements de journaux à écriture anticipée
Maintenant, utilisons-le pour déterminer le décalage. Vous pouvez l'exécuter dans n'importe quel nœud PG, car nous ne fournirons que les valeurs statiques :
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Estimons combien est 1800913104, qui semble être d'environ 1,6 Go pourrait avoir été absent dans le nœud de secours,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Enfin, vous pouvez poursuivre ou même avant la requête, consulter les journaux, comme utiliser tail -5f pour suivre et vérifier ce qui se passe. Effectuez cette opération pour les nœuds principal/de secours. Dans cet exemple, nous verrons qu'il a un problème,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Lorsque vous rencontrez ce problème, il est préférable de reconstruire vos nœuds de secours. Dans ClusterControl, c'est aussi simple qu'un clic. Allez simplement dans la section Nœuds/Topologie et reconstruisez le nœud comme ci-dessous :
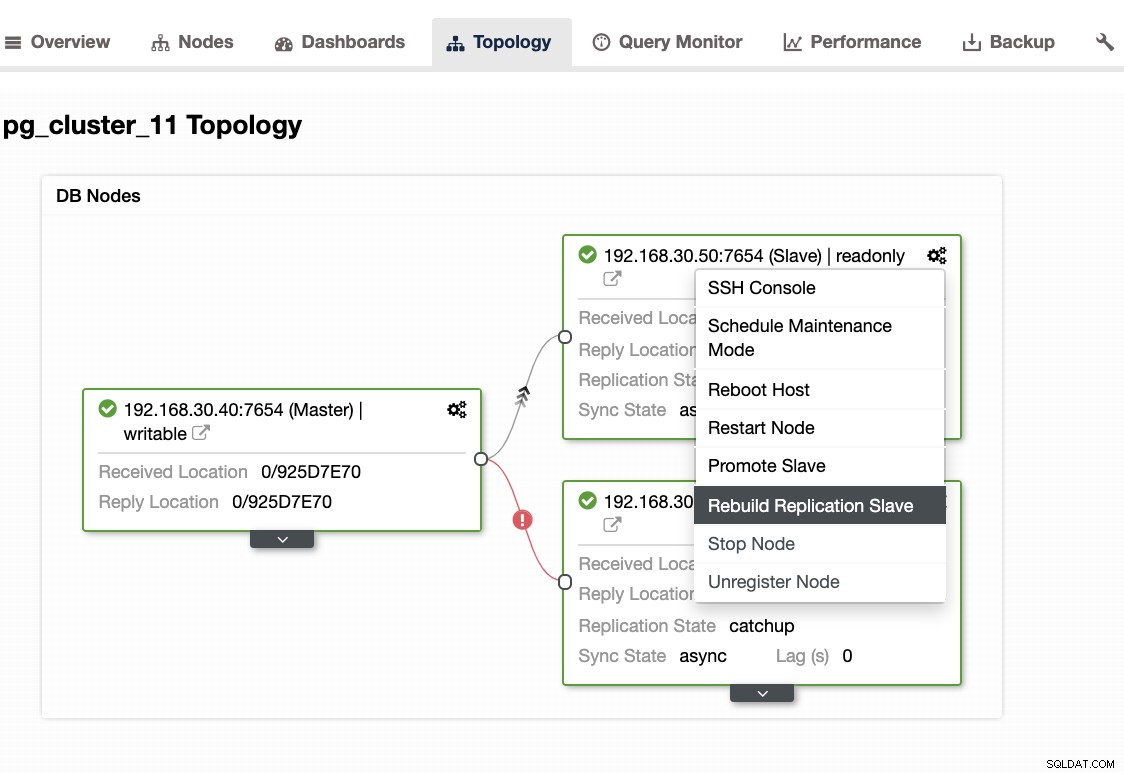
Autres choses à vérifier
Vous pouvez utiliser la même approche dans notre blog précédent (dans MySQL), en utilisant des outils système tels que ps, top, iostat, combinaison netstat. Par exemple, vous pouvez également obtenir le segment WAL récupéré actuel à partir du nœud de secours,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Comment ClusterControl peut-il vous aider ?
ClusterControl offre un moyen efficace de surveiller les nœuds de votre base de données, des nœuds principaux aux nœuds esclaves. Lorsque vous accédez à l'onglet Vue d'ensemble, vous avez déjà la vue de l'état de santé de votre réplication :
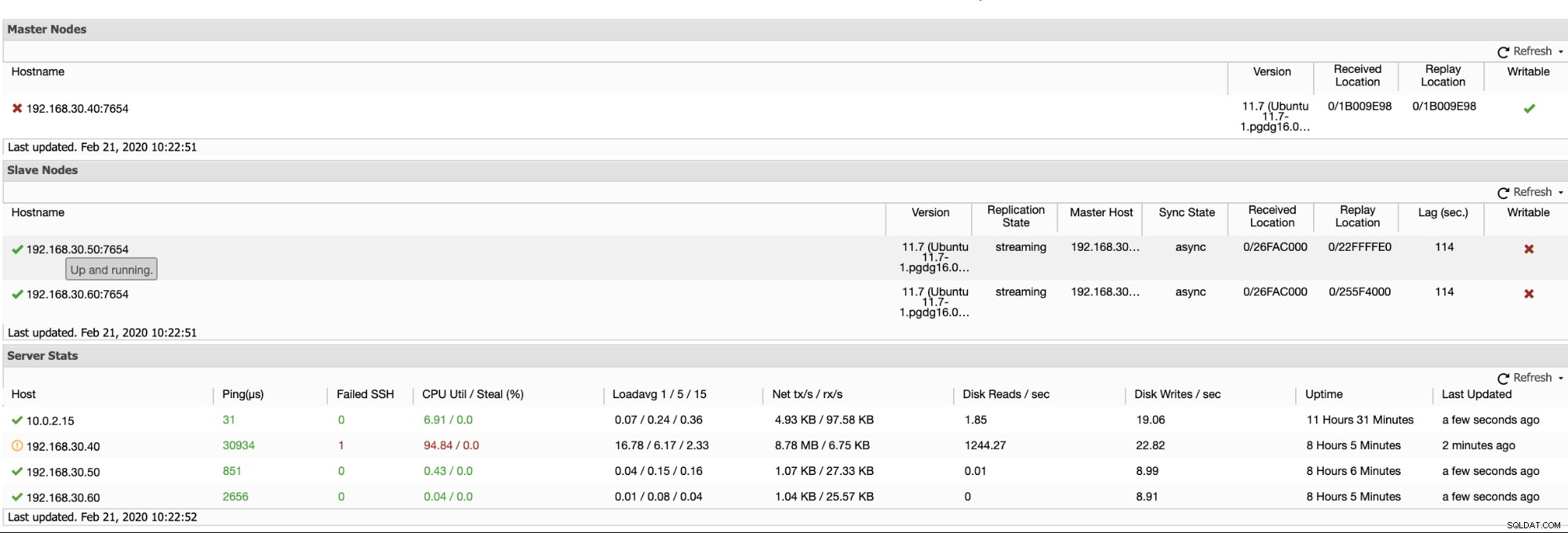
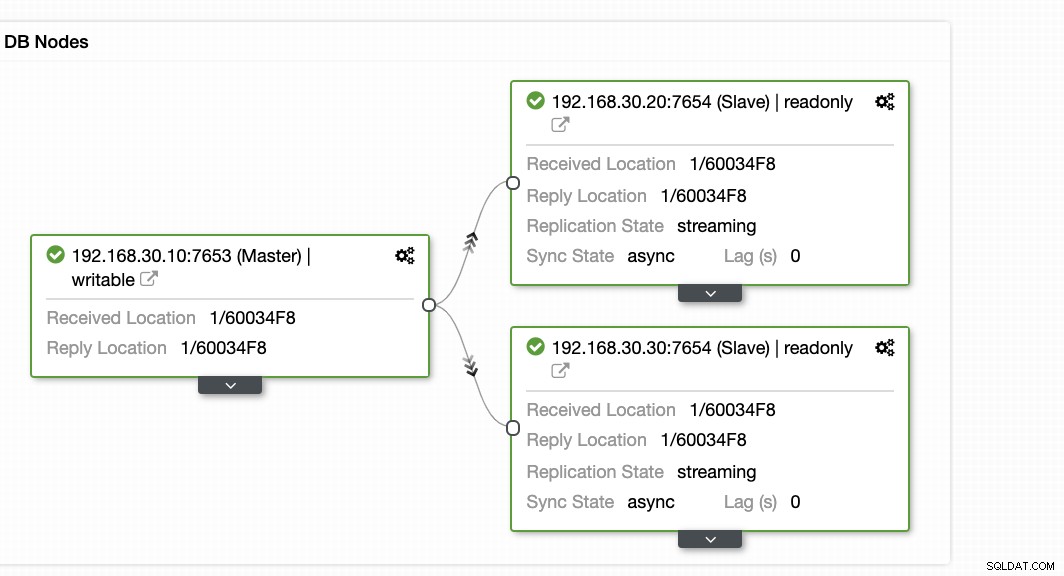
Fondamentalement, les deux captures d'écran ci-dessus affichent la santé de la réplication et quelle est la situation actuelle Segments WAL. Ce n'est pas du tout. ClusterControl affiche également l'activité actuelle de ce qui se passe avec votre cluster.
Conclusion
La surveillance de la santé de la réplication dans PostgreSQL peut aboutir à une approche différente tant que vous êtes en mesure de répondre à vos besoins. L'utilisation d'outils tiers avec observabilité qui peuvent vous avertir en cas de catastrophe est votre voie idéale, qu'il s'agisse d'une source ouverte ou d'une entreprise. Le plus important est que votre plan de reprise après sinistre et la continuité de vos activités soient planifiés avant de tels problèmes.



