La mise en surbrillance des hits est une fonctionnalité que de nombreuses personnes souhaitent que la recherche en texte intégral de SQL Server prenne en charge de manière native. C'est là que vous pouvez renvoyer le document entier (ou un extrait) et indiquer les mots ou les phrases qui ont permis de faire correspondre ce document à la recherche. Le faire de manière efficace et précise n'est pas une tâche facile, comme je l'ai découvert de première main.
À titre d'exemple de surbrillance :lorsque vous effectuez une recherche dans Google ou Bing, vous obtenez les mots clés en gras dans le titre et l'extrait (cliquez sur l'une ou l'autre des images pour les agrandir) :

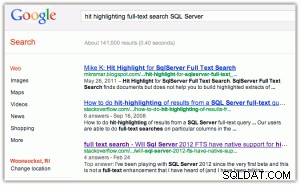
[En passant, je trouve deux choses amusantes ici :(1) que Bing favorise beaucoup plus les propriétés de Microsoft que Google, et (2) que Bing dérange de renvoyer 2,2 millions de résultats, dont beaucoup ne sont probablement pas pertinents.]
Ces extraits sont communément appelés "extraits" ou "résumés basés sur les requêtes". Nous réclamons cette fonctionnalité dans SQL Server depuis un certain temps, mais nous n'avons pas encore entendu de bonnes nouvelles de Microsoft :
- Connect #295100 :résumés de recherche en texte intégral (mise en surbrillance des résultats)
- Connect #722324 :Ce serait bien si la recherche de texte intégral SQL fournissait la prise en charge des extraits/de la mise en surbrillance
La question apparaît également de temps en temps sur Stack Overflow :
- Comment mettre en surbrillance les résultats d'une requête en texte intégral SQL Server
- Sql Server 2012 FTS aura-t-il une prise en charge native de la mise en surbrillance des hits ?
Il existe des solutions partielles. Ce script de Mike Kramar, par exemple, produira un extrait mis en surbrillance, mais n'applique pas la même logique (comme les séparateurs de mots spécifiques à la langue) au document lui-même. Il utilise également un nombre absolu de caractères, de sorte que l'extrait peut commencer et se terminer par des mots partiels (comme je le démontrerai bientôt). Ce dernier est assez facile à résoudre, mais un autre problème est qu'il charge le document entier en mémoire, plutôt que d'effectuer tout type de streaming. Je soupçonne que dans les index de texte intégral avec des documents de grande taille, ce sera un impact notable sur les performances. Pour l'instant, je vais me concentrer sur une taille de document moyenne relativement petite (35 Ko).
Un exemple simple
Supposons donc que nous ayons une table très simple, avec un index de texte intégral défini :
CREATE FULLTEXT CATALOG [FTSDemo];GO CREATE TABLE [dbo].[Document]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL , [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID));GO CREATE FULLTEXT INDEX ON [dbo].[Document]( [Content] LANGUAGE [English] , [Title] LANGUAGE [English])KEY INDEX [PK_Document] ON ([FTSDemo]);
Ce tableau est peuplé de quelques documents (en particulier, 7), tels que la Déclaration d'Indépendance et le discours "Je suis prêt à mourir" de Nelson Mandela. Une recherche typique en texte intégral dans ce tableau pourrait être :
SELECT d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID =t.[KEY] ORDRE PAR [RANK] DESC ;
Le résultat renvoie 4 lignes sur 7 :

Maintenant, en utilisant une fonction UDF comme celle de Mike Kramar :
SELECT d.Title, Extrait =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document ], *, N'états') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC ;
Les résultats montrent comment l'extrait fonctionne :un <SPAN> la balise est injectée au premier mot clé et l'extrait est découpé en fonction d'un décalage par rapport à cette position (sans tenir compte de l'utilisation de mots complets) :

(Encore une fois, c'est quelque chose qui peut être corrigé, mais je veux être sûr de représenter correctement ce qui existe actuellement.)
Pensez surligner
Eran Meyuchas de Interactive Thoughts a développé un composant qui résout bon nombre de ces problèmes. ThinkHighlight est implémenté en tant qu'assembly CLR avec deux fonctions à valeur scalaire CLR :
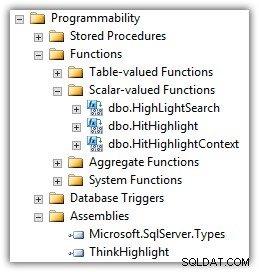
(Vous verrez également l'UDF de Mike Kramar dans la liste des fonctions.)
Maintenant, sans entrer dans tous les détails concernant l'installation et l'activation de l'assembly sur votre système, voici comment la requête ci-dessus serait représentée avec ThinkHighlight :
SELECT d.Title, Extrait =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC; Les résultats montrent comment les mots-clés les plus pertinents sont mis en surbrillance, et un extrait en est dérivé en fonction des mots complets et d'un décalage par rapport au terme mis en surbrillance :

Certains avantages supplémentaires que je n'ai pas démontrés ici incluent la possibilité de choisir différentes stratégies de résumé, le contrôle de la présentation de chaque mot-clé (plutôt que de tous) à l'aide d'un CSS unique, ainsi que la prise en charge de plusieurs langues et même de documents au format binaire (la plupart des IFilters sont pris en charge).
Résultats des performances
Au départ, j'ai testé les métriques d'exécution pour les trois requêtes à l'aide de SQL Sentry Plan Explorer, par rapport à la table à 7 lignes. Les résultats étaient :

Ensuite, je voulais voir comment ils se compareraient sur une taille de données beaucoup plus grande. J'ai inséré la table dans elle-même jusqu'à atteindre 4 000 lignes, puis j'ai exécuté la requête suivante :
SET STATISTICS TIME ON;GO SELECT /* FTS */ d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT /* UDF */ d.Title, Extrait =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)FROM dbo.[Document] AS DINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Extrait =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Document] AS DINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC;GO SET STATISTICS TIME OFF;GO
J'ai également surveillé sys.dm_exec_memory_grants pendant l'exécution des requêtes, pour détecter toute divergence dans les allocations de mémoire. Résultats moyens sur 10 exécutions :
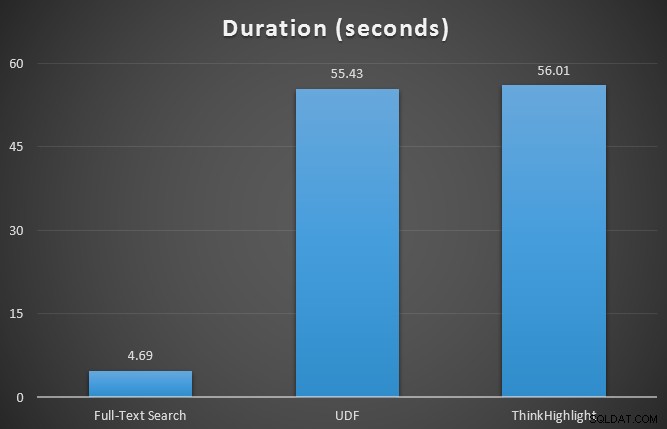
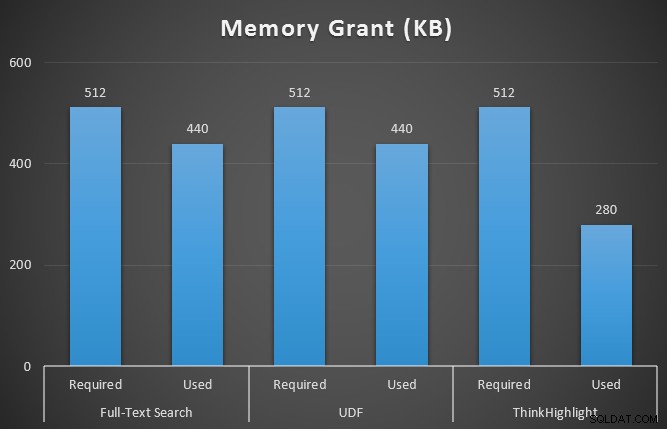
Alors que les deux options de mise en surbrillance des hits entraînent une pénalité significative par rapport à l'absence de surbrillance du tout, la solution ThinkHighlight - avec des options plus flexibles - représente un coût incrémental très marginal en termes de durée (~ 1%), tout en utilisant beaucoup moins de mémoire (36%) que la variante UDF.
Conclusion
Il ne faut pas s'étonner que la mise en surbrillance des hits soit une opération coûteuse et, compte tenu de la complexité de ce qui doit être pris en charge (pensez à plusieurs langues), que très peu de solutions existent. Je pense que Mike Kramar a fait un excellent travail en produisant une UDF de base qui vous aide à résoudre le problème, mais j'ai été agréablement surpris de trouver une offre commerciale plus robuste - et je l'ai trouvée très stable, même sous forme bêta. Je prévois d'effectuer des tests plus approfondis en utilisant une gamme plus large de tailles et de types de documents. En attendant, si la mise en surbrillance des hits fait partie des exigences de votre application, vous devriez essayer l'UDF de Mike Kramar et envisager de prendre ThinkHighlight pour un essai routier.



