PostgreSQL Streaming Replication est un excellent moyen de mettre à l'échelle les clusters PostgreSQL et de leur ajouter ainsi une haute disponibilité. Comme pour chaque réplication, l'idée est que l'esclave est une copie du maître et que l'esclave est constamment mis à jour avec les changements qui se sont produits sur le maître en utilisant une sorte de mécanisme de réplication.
Il peut arriver que l'esclave, pour une raison quelconque, se désynchronise avec le maître. Comment puis-je le ramener dans la chaîne de réplication ? Comment puis-je m'assurer que l'esclave est à nouveau synchronisé avec le maître ? Jetons un coup d'œil dans ce court article de blog.
Ce qui est très utile, il n'y a aucun moyen d'écrire sur un esclave s'il est en mode de récupération. Vous pouvez le tester comme ça :
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionIl peut toujours arriver que l'esclave se désynchronise avec le maître. Corruption des données - ni le matériel ni les logiciels ne sont exempts de bogues et de problèmes. Certains problèmes avec le lecteur de disque peuvent déclencher une corruption des données sur l'esclave. Certains problèmes avec le processus de « vide » peuvent entraîner la modification des données. Comment récupérer de cet état ?
Reconstruire l'esclave à l'aide de pg_basebackup
L'étape principale consiste à provisionner l'esclave à l'aide des données du maître. Étant donné que nous utiliserons la réplication en continu, nous ne pouvons pas utiliser la sauvegarde logique. Heureusement, il existe un outil prêt à l'emploi qui peut être utilisé pour configurer les choses :pg_basebackup. Voyons quelles seraient les étapes à suivre pour provisionner un serveur esclave. Pour être clair, nous utilisons PostgreSQL 12 dans le cadre de cet article de blog.
L'état initial est simple. Notre esclave ne réplique pas à partir de son maître. Les données qu'il contient sont corrompues et ne peuvent être ni utilisées ni approuvées. Par conséquent, la première étape que nous ferons sera d'arrêter PostgreSQL sur notre esclave et de supprimer les données qu'il contient :
example@sqldat.com:~# systemctl stop postgresqlOu même :
example@sqldat.com:~# killall -9 postgresMaintenant, vérifions le contenu du fichier postgresql.auto.conf, nous pouvons utiliser les identifiants de réplication stockés dans ce fichier plus tard, pour pg_basebackup :
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Nous sommes intéressés par l'utilisateur et le mot de passe utilisés pour configurer la réplication.
Enfin, nous sommes d'accord pour supprimer les données :
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Une fois les données supprimées, nous devons utiliser pg_basebackup pour obtenir les données du maître :
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointLes drapeaux que nous avons utilisés ont la signification suivante :
- -Xs : nous aimerions diffuser WAL pendant la création de la sauvegarde. Cela permet d'éviter les problèmes de suppression des fichiers WAL lorsque vous avez un grand ensemble de données.
- -P : nous aimerions voir la progression de la sauvegarde.
- -R : nous voulons que pg_basebackup crée le fichier standby.signal et prépare le fichier postgresql.auto.conf avec les paramètres de connexion.
pg_basebackup attendra le point de contrôle avant de démarrer la sauvegarde. Si cela prend trop de temps, vous pouvez utiliser deux options. Tout d'abord, il est possible de définir le mode de point de contrôle sur rapide dans pg_basebackup en utilisant l'option "-c fast". Alternativement, vous pouvez forcer les points de contrôle en exécutant :
postgres=# CHECKPOINT;
CHECKPOINTD'une manière ou d'une autre, pg_basebackup démarrera. Avec l'indicateur -P, nous pouvons suivre la progression :
416906/1588478 kB (26%), 0/1 tablespaceceaceUne fois la sauvegarde prête, tout ce que nous avons à faire est de nous assurer que le contenu du répertoire de données a le bon utilisateur et le bon groupe assigné - nous avons exécuté pg_basebackup en tant que 'root' donc nous voulons le changer en 'postgres ' :
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/C'est tout, nous pouvons démarrer l'esclave et il devrait commencer à se répliquer à partir du maître.
example@sqldat.com:~# systemctl start postgresqlVous pouvez revérifier la progression de la réplication en exécutant la requête suivante sur le maître :
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Comme vous pouvez le voir, les deux esclaves se répliquent correctement.
Reconstruire l'esclave à l'aide de ClusterControl
Si vous êtes un utilisateur de ClusterControl, vous pouvez facilement obtenir exactement la même chose en choisissant simplement une option dans l'interface utilisateur.
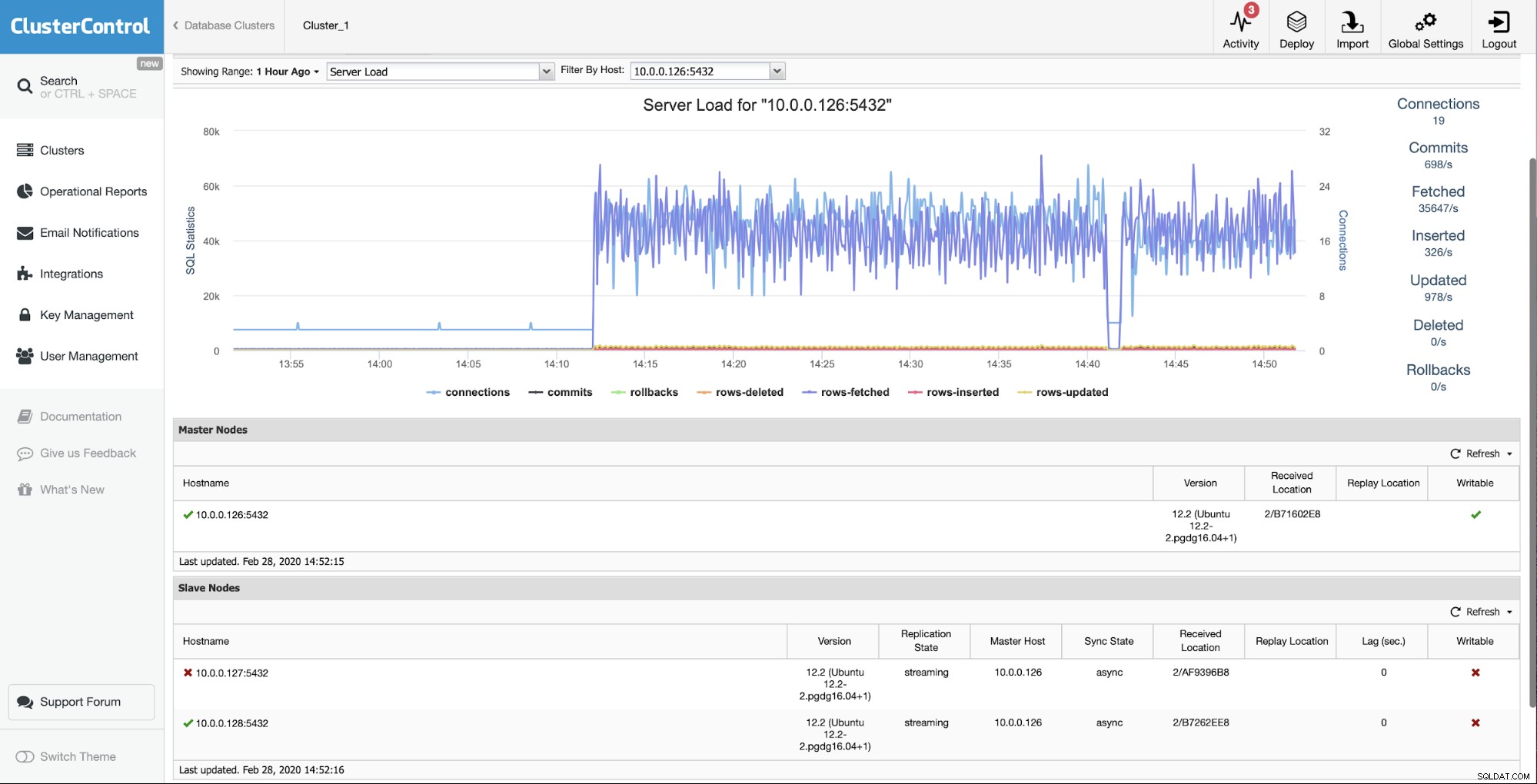
La situation initiale est que l'un des esclaves (10.0.0.127) est ne fonctionne pas et ne se réplique pas. Nous avons estimé que la reconstruction était la meilleure option pour nous.
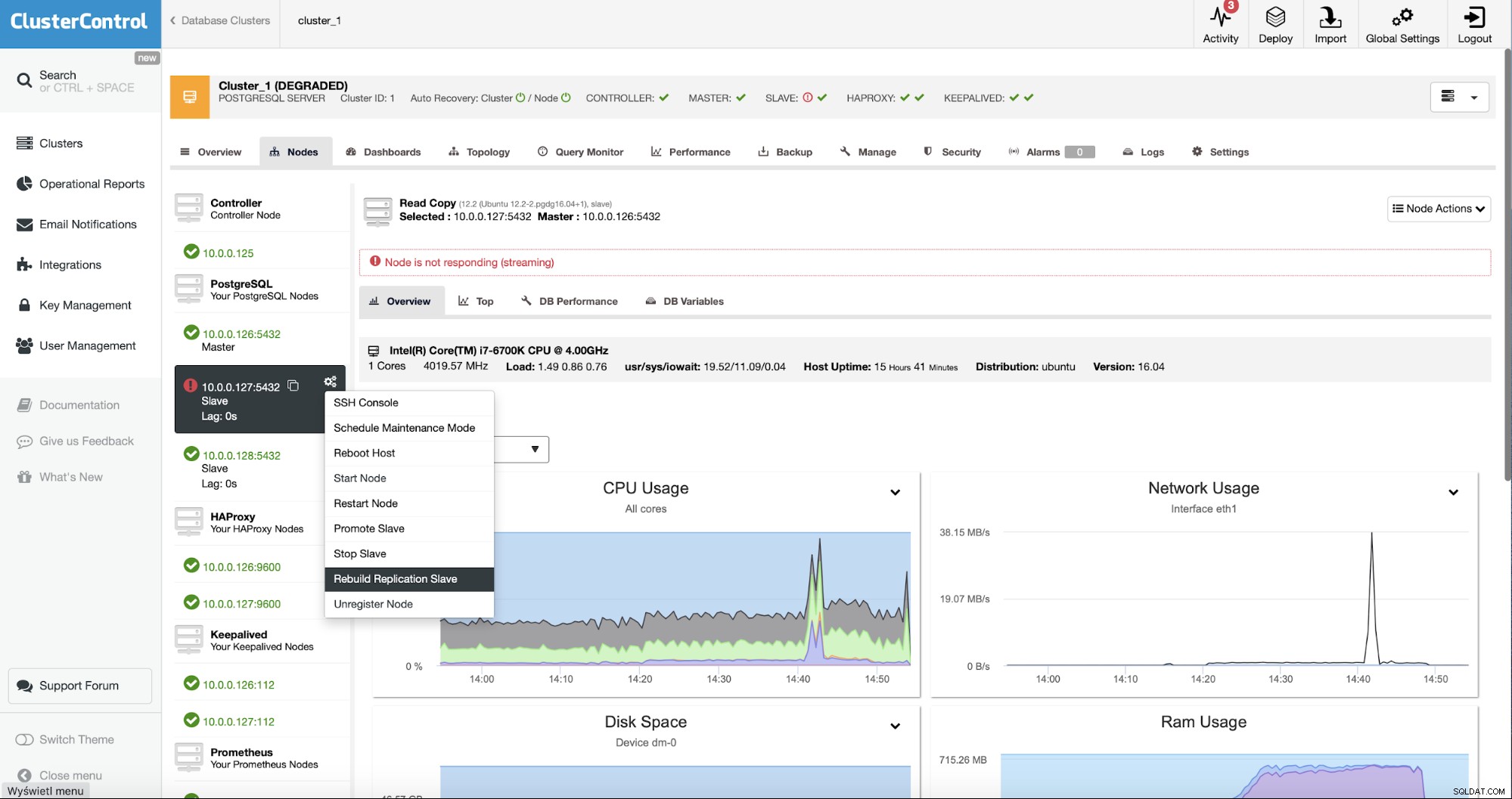
En tant qu'utilisateurs de ClusterControl, tout ce que nous avons à faire est d'aller dans les "Nodes " et exécutez la tâche "Reconstruire l'esclave de réplication".
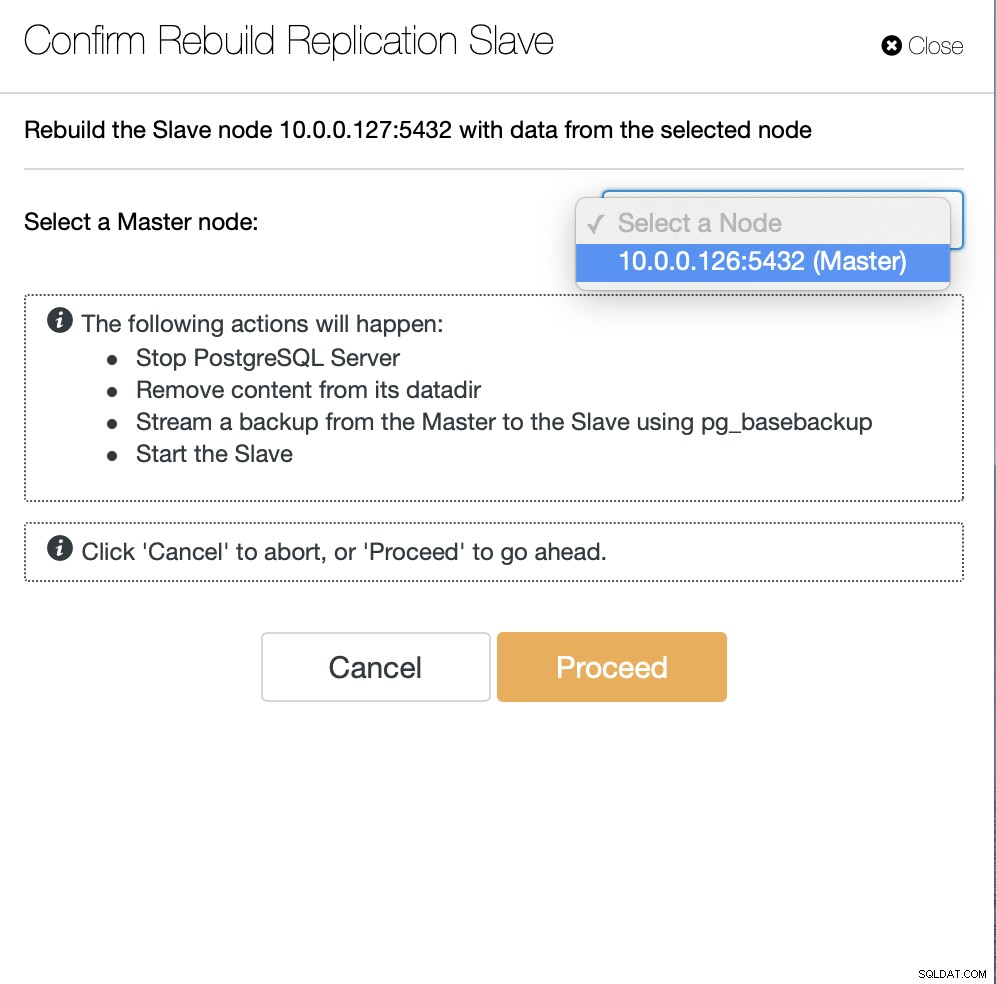
Ensuite, nous devons choisir le nœud à partir duquel reconstruire l'esclave et c'est tout. ClusterControl utilisera pg_basebackup pour configurer l'esclave de réplication et configurer la réplication dès que les données seront transférées.
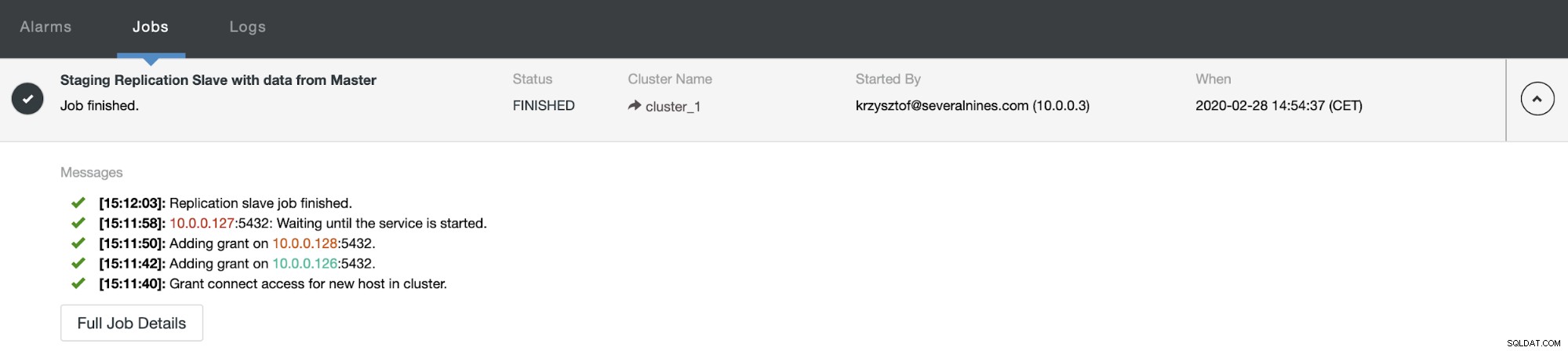
Après un certain temps, le travail se termine et l'esclave est de retour dans la chaîne de réplication :
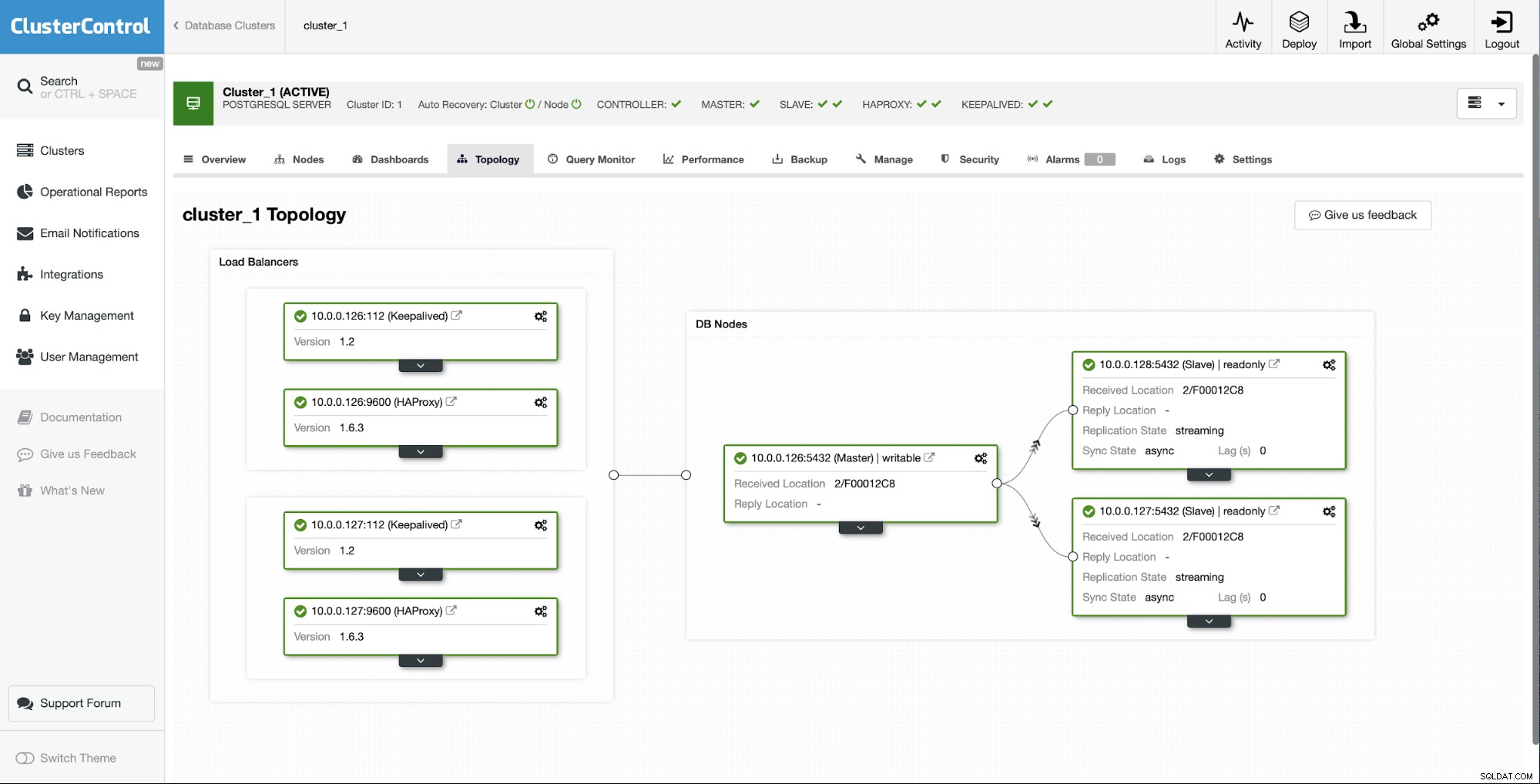
Comme vous pouvez le voir, en quelques clics, grâce à ClusterControl, nous avons réussi à reconstruire notre esclave défaillant et à le ramener au cluster.