De mémoire, j'ai une solution à 50 % pour vous.
Le problème
SSIS vraiment se soucie des métadonnées, de sorte que leurs variations ont tendance à entraîner des exceptions. DTS était beaucoup plus indulgent dans ce sens. Ce fort besoin de métadonnées cohérentes rend l'utilisation de la source de fichier plat gênante.
Solution basée sur des requêtes
Si le problème vient du composant, ne l'utilisons pas. Ce que j'aime dans cette approche, c'est que conceptuellement, c'est la même chose que d'interroger une table :l'ordre des colonnes n'a pas d'importance, pas plus que la présence de colonnes supplémentaires.
Variables
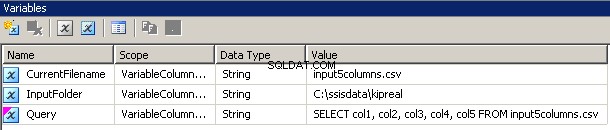
J'ai créé 3 variables, toutes de type chaîne :CurrentFileName, InputFolder et Query.
- InputFolder est câblé au dossier source. Dans mon exemple, c'est
C:\ssisdata\Kipreal - CurrentFileName est le nom d'un fichier. Au moment de la conception, c'était
input5columns.csvmais cela changera au moment de l'exécution. - La requête est une expression
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Gestionnaire de connexion
Configurez une connexion au fichier d'entrée à l'aide du pilote JET OLEDB. Après l'avoir créé comme décrit dans l'article lié, je l'ai renommé FileOLEDB et défini une expression sur le ConnectionManager de "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Flux de contrôle
Mon flux de contrôle ressemble à une tâche de flux de données imbriquée dans un énumérateur de fichier Foreach
Énumérateur de fichiers Foreach
Mon énumérateur Foreach File est configuré pour fonctionner sur des fichiers. J'ai mis une expression sur le répertoire pour @[User::InputFolder] Notez qu'à ce stade, si la valeur de ce dossier doit changer, elle sera correctement mise à jour à la fois dans le gestionnaire de connexions et dans l'énumérateur de fichiers. Dans "Récupérer le nom du fichier", au lieu de "Complètement qualifié" par défaut, choisissez "Nom et extension"
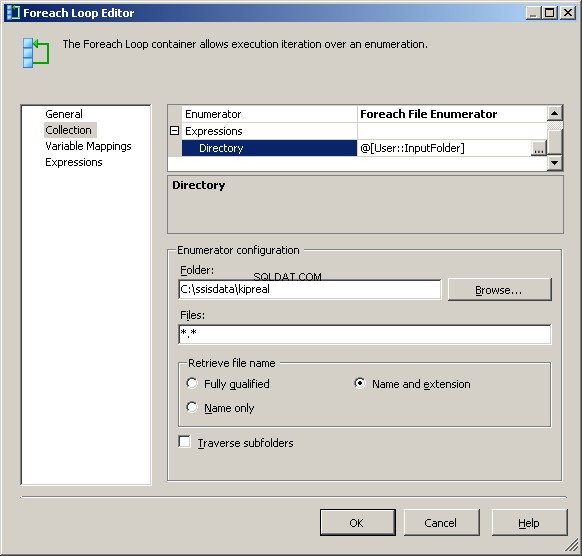
Dans l'onglet Variable Mappings, attribuez la valeur à notre @[User::CurrentFileName] variables
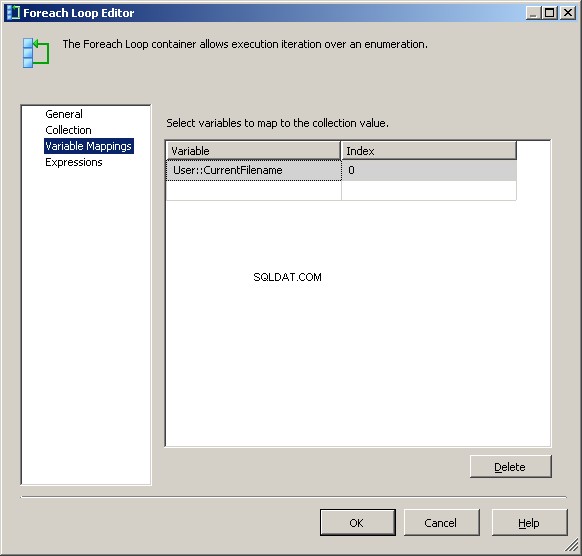
À ce stade, chaque itération de la boucle modifiera la valeur de @[User::Query pour refléter le nom de fichier actuel.
Flux de données
C'est en fait la pièce la plus simple. Utilisez une source OLE DB et câblez-la comme indiqué.
Utilisez le gestionnaire de connexions FileOLEDB et changez le mode d'accès aux données en "Commande SQL à partir d'une variable". Utilisez le @[User::Query] variable là-dedans, cliquez sur OK et vous êtes prêt à travailler. 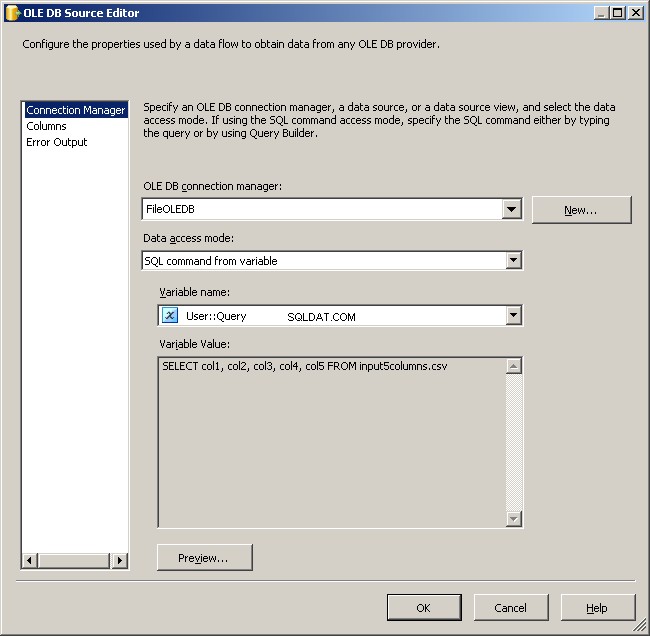
Exemples de données
J'ai créé deux exemples de fichiers input5columns.csv et input7columns.csv Toutes les colonnes de 5 sont en 7 mais 7 les a dans un ordre différent (col2 est la position ordinale 2 et 6). J'ai nié toutes les valeurs de 7 pour qu'il soit facilement évident sur quel fichier est opéré.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
et
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
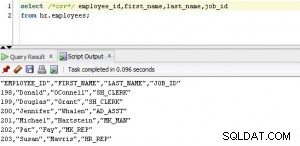
L'exécution du package donne ces deux captures d'écran
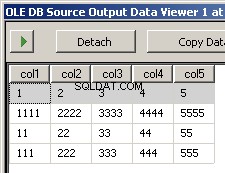
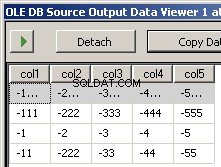
Ce qui manque
Je ne connais pas de moyen de dire à l'approche basée sur les requêtes que tout va bien si une colonne n'existe pas. S'il y a une clé unique, je suppose que vous pourriez définir votre requête pour n'avoir que les colonnes qui doivent être là, puis effectuer des recherches dans le fichier pour essayer d'obtenir les colonnes qui devraient être là et ne pas échouer la recherche si la colonne n'existe pas. Assez maladroit cependant.