Découvrez l'architecture d'Hadoop, qui est le framework le plus adopté pour le stockage et le traitement de données massives.
Dans cet article, nous étudierons l'architecture Hadoop. L'article explique l'architecture Hadoop et les composants de l'architecture Hadoop que sont HDFS, MapReduce et YARN. Dans cet article, nous explorerons l'architecture Hadoop en détail, ainsi que le diagramme de l'architecture Hadoop.
Commençons maintenant par l'architecture Hadoop.
Architecture Hadoop
L'objectif de la conception d'Hadoop est de développer un cadre peu coûteux, fiable et évolutif qui stocke et analyse le volume croissant de données volumineuses.
Apache Hadoop est un framework logiciel conçu par Apache Software Foundation pour stocker et traiter de grands ensembles de données de tailles et de formats variés.
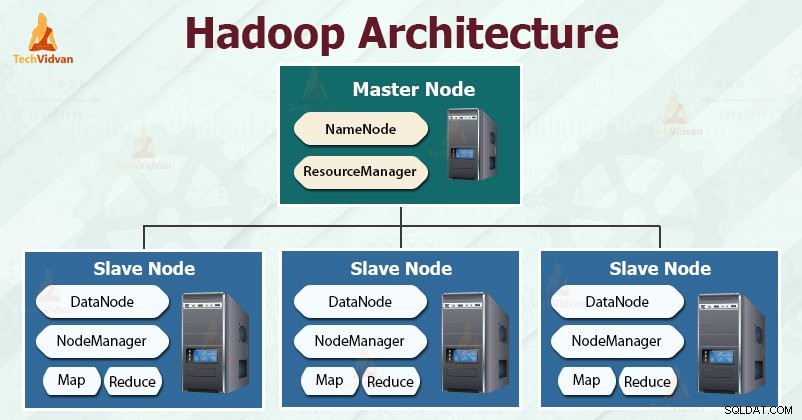
Hadoop suit le maître-esclave architecture pour stocker et traiter efficacement de grandes quantités de données. Les nœuds maîtres assignent des tâches aux nœuds esclaves.
Les nœuds esclaves sont chargés de stocker les données réelles et d'effectuer le calcul/traitement réel. Les nœuds maîtres sont responsables du stockage des métadonnées et de la gestion des ressources dans le cluster.
Les nœuds esclaves stockent les données commerciales réelles, tandis que le maître stocke les métadonnées.
L'architecture Hadoop comprend trois couches. Ce sont :
- Couche de stockage (HDFS)
- Couche de gestion des ressources (YARN)
- Couche de traitement (MapReduce)
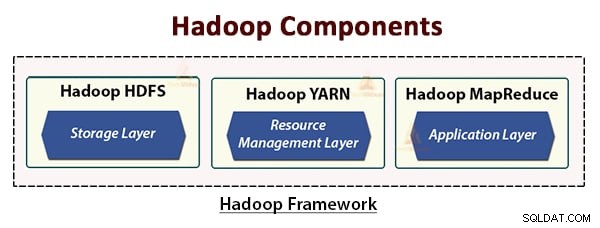
HDFS, YARN et MapReduce sont les composants de base du framework Hadoop.
Étudions maintenant ces trois composants de base en détail.
1. HDFS
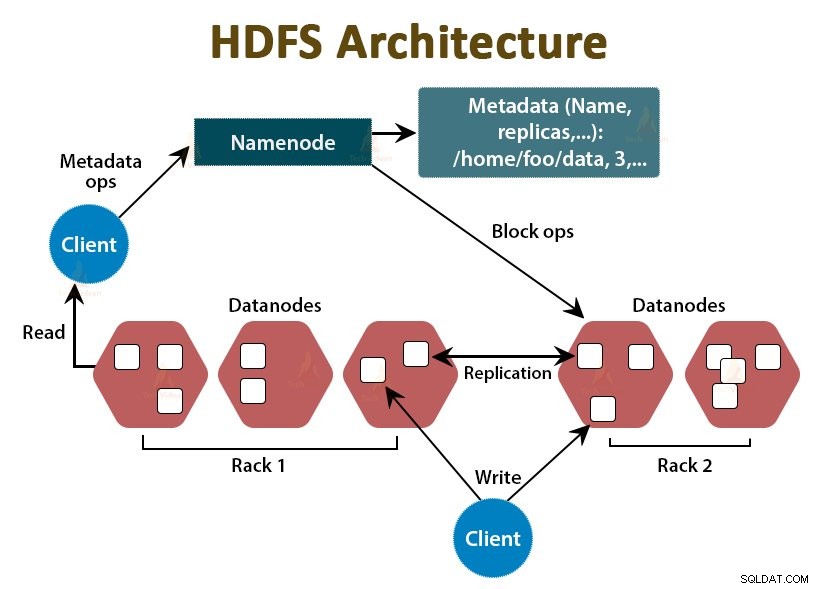
HDFS est le système de fichiers distribué Hadoop , qui fonctionne sur du matériel de base bon marché. C'est la couche de stockage pour Hadoop. Les fichiers dans HDFS sont divisés en blocs de la taille d'un bloc appelés blocs de données.
Ces blocs sont ensuite stockés sur les nœuds esclaves du cluster. La taille de bloc est de 128 Mo par défaut, que nous pouvons configurer selon nos besoins.
Comme Hadoop, HDFS suit également l'architecture maître-esclave. Il comprend deux démons - NameNode et DataNode. Le NameNode est le démon maître qui s'exécute sur le nœud maître. Les DataNodes sont le démon esclave qui s'exécute sur les nœuds esclaves.
NomNoeud
NameNode stocke les métadonnées du système de fichiers, c'est-à-dire les noms de fichiers, les informations sur les blocs d'un fichier, les emplacements des blocs, les autorisations, etc. Il gère les Datanodes.
Noeud de données
Les DataNodes sont les nœuds esclaves qui stockent les données commerciales réelles. Il sert les demandes de lecture/écriture du client en fonction des instructions NameNode.
DataNodes stocke les blocs des fichiers et NameNode stocke les métadonnées telles que les emplacements des blocs, les autorisations, etc.
2. MapReduce
C'est la couche de traitement des données de Hadoop. Il s'agit d'un cadre logiciel pour écrire des applications qui traitent de grandes quantités de données (des téraoctets aux pétaoctets dans la plage) en parallèle sur le cluster de matériel de base.
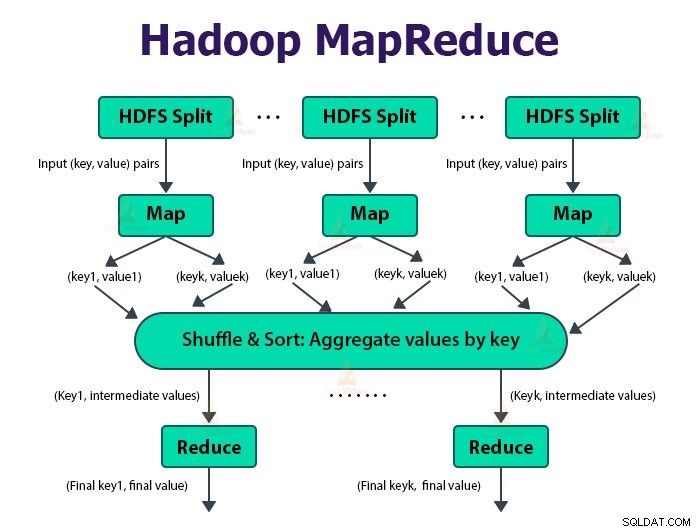
Le framework MapReduce fonctionne sur les paires
La tâche MapReduce est l'unité de travail que le client souhaite effectuer. Le travail MapReduce se compose principalement des données d'entrée, du programme MapReduce et des informations de configuration. Hadoop exécute les tâches MapReduce en les divisant en deux types de tâches qui sont des tâches de mappage et réduisez les tâches . Le Hadoop YARN a planifié ces tâches et est exécuté sur les nœuds du cluster.
En raison de certaines conditions défavorables, si les tâches échouent, elles seront automatiquement replanifiées sur un nœud différent.
L'utilisateur définit la fonction de carte et la fonction de réduction pour effectuer la tâche MapReduce.
L'entrée de la fonction map et la sortie de la fonction reduce est la paire clé, valeur.
La fonction des tâches cartographiques est de charger, d'analyser, de filtrer et de transformer les données. La sortie de la tâche de mappage est l'entrée de la tâche de réduction. Réduire la tâche effectue ensuite le regroupement et l'agrégation sur la sortie de la tâche de carte.
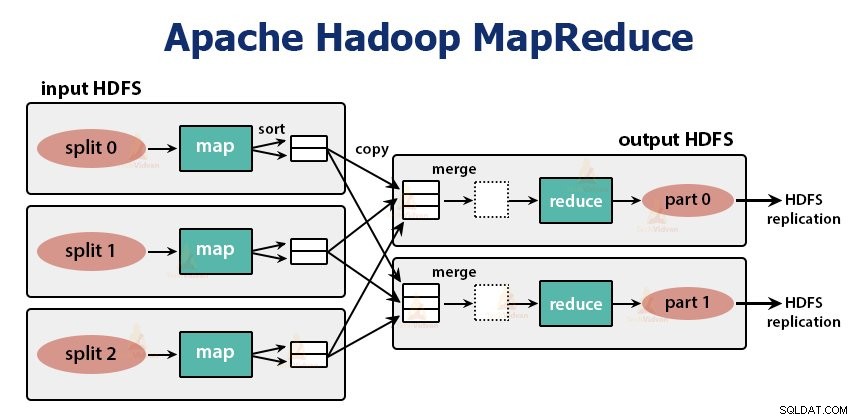
La tâche MapReduce se fait en deux phases-
1. Phase de carte
Hadoop divise les entrées de la tâche MapReduce en divisions de taille fixe appelées divisions d'entrée ou scissions. Le RecordReader transforme ces fractionnements en enregistrements et analyse les données en enregistrements, mais il n'analyse pas les enregistrements eux-mêmes. RecordReader fournit les données à la fonction mappeur dans des paires clé-valeur.
Dans la phase de mappage, Hadoop crée une tâche de mappage qui exécute une fonction définie par l'utilisateur appelée fonction de mappage pour chaque enregistrement dans la division d'entrée. Il génère zéro ou plusieurs paires clé-valeur intermédiaires en sortie de tâche de mappage.
La tâche de carte écrit sa sortie sur le disque local. Cette sortie intermédiaire est ensuite traitée par les tâches de réduction qui exécutent une fonction de réduction définie par l'utilisateur pour produire la sortie finale. Une fois le travail terminé, la sortie de la carte est supprimée.
L'entrée de la tâche de réduction unique est la sortie de tous les mappeurs qui est sortie de toutes les tâches de carte. Hadoop permet à l'utilisateur de définir une fonction de combinaison qui s'exécute sur la sortie de la carte.
Combinateur regroupe les données dans la phase de carte avant de les transmettre à Reducer. Il combine la sortie de la fonction map qui est ensuite transmise en entrée à la fonction reduce.
Lorsqu'il y a plusieurs réducteurs, les tâches de mappage partitionnent leur sortie, chacune créant une partition pour chaque tâche de réduction. Dans chaque partition, il peut y avoir plusieurs clés et leurs valeurs associées, mais les enregistrements d'une clé donnée se trouvent tous dans une seule partition.
Hadoop permet aux utilisateurs de contrôler le partitionnement en spécifiant une fonction de partitionnement définie par l'utilisateur. Généralement, il existe un partitionneur par défaut qui regroupe les clés à l'aide de la fonction de hachage.
2. Réduire la phase :
Les différentes phases de la réduction de tâche sont les suivantes :
La tâche Reducer commence par une étape de mélange et de tri. L'objectif principal de cette phase est de rassembler les clés équivalentes. La phase Sort and Shuffle télécharge les données écrites par le partitionneur sur le nœud où Reducer est en cours d'exécution.
Il trie chaque élément de données dans une grande liste de données. Le framework MapReduce effectue ce tri et mélange afin que nous puissions le parcourir facilement dans la tâche de réduction.
Le tri et brassage sont effectués automatiquement par le framework. Le développeur, via l'objet comparateur, peut contrôler la manière dont les clés sont triées et regroupées.
Le réducteur, qui est la fonction de réduction définie par l'utilisateur, s'exécute une fois par groupe de touches. Le réducteur filtre, agrège et combine les données de plusieurs manières différentes. Une fois la tâche de réduction terminée, elle donne zéro ou plusieurs paires clé-valeur à OutputFormat. La sortie de la tâche de réduction est stockée dans Hadoop HDFS.
Il prend la sortie du réducteur et l'écrit dans le fichier HDFS par RecordWriter. Par défaut, il sépare la clé, la valeur par une tabulation et chaque enregistrement par un caractère de saut de ligne.
3. FIL
YARN signifie Yet Another Resource Negotiator . C'est la couche de gestion des ressources de Hadoop. Il a été introduit dans Hadoop 2.
YARN est conçu avec l'idée de diviser les fonctionnalités de planification des tâches et de gestion des ressources en démons distincts. L'idée de base est d'avoir un ResourceManager global et un maître d'application par application où l'application peut être un travail unique ou un DAG de travaux.
YARN comprend ResourceManager, NodeManager et ApplicationMaster par application.
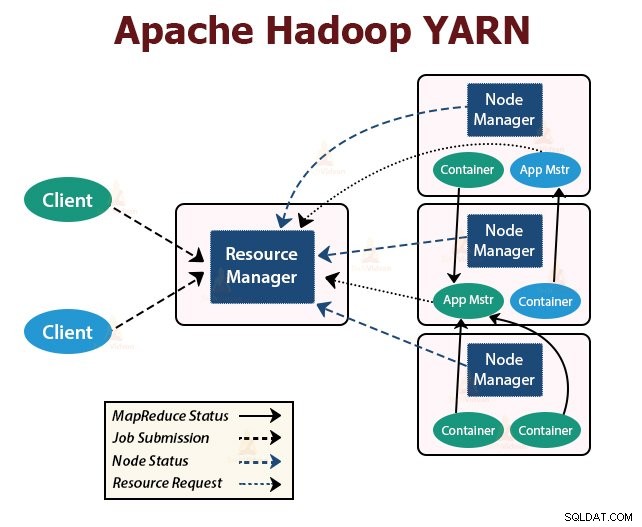
1. Gestionnaire de ressources
Il arbitre les ressources entre toutes les applications du cluster.
Il a deux composants principaux qui sont Scheduler et ApplicationManager.
- Le planificateur alloue des ressources aux différentes applications exécutées dans le cluster, en tenant compte des capacités, des files d'attente, etc.
- C'est un pur planificateur. Il ne surveille ni ne suit l'état de l'application.
- Scheduler ne garantit pas le redémarrage des tâches ayant échoué en raison d'une défaillance de l'application ou d'une défaillance matérielle.
- Il effectue la planification en fonction des besoins en ressources des applications.
- Ils sont responsables de l'acceptation des offres d'emploi.
- ApplicationManager négocie le premier conteneur pour l'exécution d'ApplicationMaster spécifique à l'application.
- Ils fournissent un service pour redémarrer le conteneur ApplicationMaster en cas d'échec.
- L'ApplicationMaster par application est responsable de la négociation des conteneurs à partir du planificateur. Il suit et surveille leur statut et leur progression.
2. Gestionnaire de nœud :
NodeManager s'exécute sur les nœuds esclaves. Il est responsable des conteneurs, en surveillant l'utilisation des ressources de la machine, c'est-à-dire l'utilisation du processeur, de la mémoire, du disque et du réseau, et en signalant la même chose au ResourceManager ou au Scheduler.
3. Maître d'application :
L'ApplicationMaster par application est une bibliothèque spécifique au framework. Il est responsable de la négociation des ressources auprès du ResourceManager. Il fonctionne avec le(s) NodeManager(s) pour exécuter et surveiller les tâches.
Résumé
Dans cet article, nous avons étudié l'architecture Hadoop. Le Hadoop suit la topologie maître-esclave. Les nœuds maîtres attribuent des tâches aux nœuds esclaves. L'architecture comprend trois couches qui sont HDFS, YARN et MapReduce.
HDFS est le système de fichiers distribué dans Hadoop pour stocker le Big Data. MapReduce est le cadre de traitement permettant de traiter de vastes données dans le cluster Hadoop de manière distribuée. YARN est responsable de la gestion des ressources entre les applications du cluster.
Le démon HDFS NameNode et le démon YARN ResourceManager s'exécutent sur le nœud maître du cluster Hadoop. Le démon HDFS DataNode et le YARN NodeManager s'exécutent sur les nœuds esclaves.
Le framework HDFS et MapReduce s'exécutent sur le même ensemble de nœuds, ce qui se traduit par une bande passante agrégée très élevée sur l'ensemble du cluster.
Continuez à apprendre !!



