Obtenez un aperçu des mécanismes disponibles pour sauvegarder les données stockées dans Apache HBase et comment restaurer ces données en cas de divers scénarios de récupération/basculement des données
Avec l'adoption et l'intégration accrues de HBase dans les systèmes d'entreprise critiques, de nombreuses entreprises doivent protéger cet actif commercial important en élaborant des stratégies robustes de sauvegarde et de reprise après sinistre (BDR) pour leurs clusters HBase. Aussi décourageant que cela puisse paraître de sauvegarder et de restaurer rapidement et facilement des pétaoctets de données, HBase et l'écosystème Apache Hadoop fournissent de nombreux mécanismes intégrés pour y parvenir.
Dans cet article, vous obtiendrez un aperçu de haut niveau des mécanismes disponibles pour sauvegarder les données stockées dans HBase et comment restaurer ces données en cas de divers scénarios de récupération/basculement des données. Après avoir lu cet article, vous devriez être en mesure de prendre une décision éclairée sur la stratégie BDR la mieux adaptée aux besoins de votre entreprise. Vous devez également comprendre les avantages, les inconvénients et les implications en termes de performances de chaque mécanisme. (Les détails ci-dessous s'appliquent à CDH 4.3.0/HBase 0.94.6 et versions ultérieures.)
Remarque :Au moment de la rédaction de cet article, Cloudera Enterprise 4 offre une fonctionnalité de sauvegarde et de reprise après sinistre prête pour la production pour HDFS et Hive Metastore via Cloudera BDR 1.0 en tant que fonctionnalité sous licence individuelle. HBase n'est pas inclus dans cette version GA ; par conséquent, les différents mécanismes décrits dans ce blog sont nécessaires. (Cloudera Enterprise 5, actuellement en version bêta, offre la gestion des instantanés HBase via Cloudera BDR.)
Sauvegarde
HBase est un magasin de données distribué en arbre de fusion structuré en journaux avec des mécanismes internes complexes pour assurer l'exactitude, la cohérence, la gestion des versions des données, etc. Alors, comment diable pouvez-vous obtenir une copie de sauvegarde cohérente de ces données qui résident dans une combinaison de HFiles et de Write-Ahead-Logs (WAL) sur HDFS et en mémoire sur des dizaines de serveurs régionaux ?
Commençons par le mécanisme le moins perturbateur, le moins empreinte de données, le moins impactant sur les performances et progressons jusqu'à l'outil de type chariot élévateur le plus perturbateur :
- Instantanés
- Réplication
- Exporter
- Copier le tableau
- API HTable
- Sauvegarde hors ligne des données HDFS
Le tableau suivant donne un aperçu pour comparer rapidement ces approches, que je décrirai en détail ci-dessous.
| Impact sur les performances | Empreinte des données | Temps d'indisponibilité | Sauvegardes incrémentielles | Facilité de mise en œuvre | Temps moyen de récupération (MTTR) | |
| Instantanés | Minimal | Minuscule | Bref (uniquement sur restauration) | Non | Facile | Secondes |
| Réplication | Minimal | Grand | Aucun | Intrinsèque | Moyen | Secondes |
| Exporter | Élevé | Grand | Aucun | Oui | Facile | Élevé |
| CopierTable | Élevé | Grand | Aucun | Oui | Facile | Élevé |
| API | Moyen | Grand | Aucun | Oui | Difficile | À vous de décider |
| Manuel | N/A | Grand | Longue | Non | Moyen | Élevé |
Instantanés
Depuis CDH 4.3.0, les instantanés HBase sont entièrement fonctionnels, riches en fonctionnalités et ne nécessitent aucun temps d'arrêt du cluster lors de leur création. Mon collègue Matteo Bertozzi a très bien couvert les instantanés dans son entrée de blog et dans la plongée approfondie qui a suivi. Ici, je ne fournirai qu'un aperçu de haut niveau.
Les instantanés capturent simplement un moment dans le temps pour votre table en créant l'équivalent de liens physiques UNIX vers les fichiers de stockage de votre table sur HDFS (Figure 1). Ces instantanés s'exécutent en quelques secondes, n'imposent pratiquement aucune surcharge de performances au cluster et créent une empreinte de données minuscule. Vos données ne sont pas du tout dupliquées, mais simplement cataloguées dans de petits fichiers de métadonnées, ce qui permet au système de revenir à ce moment précis si vous avez besoin de restaurer cet instantané.
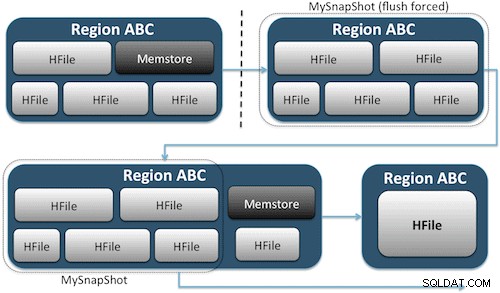
La création d'un instantané d'une table est aussi simple que d'exécuter cette commande à partir du shell HBase :
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Après avoir exécuté cette commande, vous trouverez quelques petits fichiers de données situés dans /hbase/.snapshot/myTable (CDH4) ou /hbase/.hbase-snapshots (Apache 0.94.6.1) dans HDFS qui contiennent les informations nécessaires pour restaurer votre instantané . La restauration est aussi simple que d'émettre ces commandes depuis le shell :
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Remarque :Comme vous pouvez le constater, la restauration d'un instantané nécessite une brève interruption car la table doit être hors ligne. Toutes les données ajoutées/mises à jour après la prise de l'instantané restauré seront perdues.
Si les besoins de votre entreprise sont tels que vous devez disposer d'une sauvegarde hors site de vos données, vous pouvez utiliser la commande exportSnapshot pour dupliquer les données d'une table dans votre cluster HDFS local ou un cluster HDFS distant de votre choix.
Les instantanés sont une image complète de votre table à chaque fois ; aucune fonctionnalité d'instantané incrémentiel n'est actuellement disponible.
Réplication HBase
La réplication HBase est un autre outil de sauvegarde à très faible surcharge. (Mon collègue Himanshu Vashishtha couvre la réplication en détail dans cet article de blog.) En résumé, la réplication peut être définie au niveau de la famille de colonnes, fonctionne en arrière-plan et synchronise toutes les modifications entre les clusters de la chaîne de réplication.
La réplication a trois modes :maître->esclave, maître<->maître et cyclique. Cette approche vous donne la flexibilité d'ingérer des données à partir de n'importe quel centre de données et garantit qu'elles sont répliquées sur toutes les copies de cette table dans d'autres centres de données. En cas de panne catastrophique dans un centre de données, les applications clientes peuvent être redirigées vers un autre emplacement pour les données à l'aide d'outils DNS.
La réplication est un processus robuste et tolérant aux pannes qui fournit une "cohérence éventuelle", ce qui signifie qu'à tout moment, les modifications récentes d'une table peuvent ne pas être disponibles dans toutes les répliques de cette table, mais sont garanties d'y arriver.
Remarque :Pour les tables existantes, vous devez d'abord copier manuellement la table source dans la table de destination via l'un des autres moyens décrits dans cet article. La réplication agit uniquement sur les nouvelles écritures/modifications après l'avoir activée.

(Depuis la page de réplication d'Apache)
Exporter
L'outil d'exportation de HBase est un utilitaire HBase intégré qui permet d'exporter facilement des données d'une table HBase vers des SequenceFiles simples dans un répertoire HDFS. Il crée une tâche MapReduce qui effectue une série d'appels d'API HBase vers votre cluster, et un par un, obtient chaque ligne de données de la table spécifiée et écrit ces données dans votre répertoire HDFS spécifié. Cet outil est plus gourmand en performances pour votre cluster car il utilise MapReduce et l'API client HBase, mais il est riche en fonctionnalités et prend en charge le filtrage des données par version ou plage de dates, permettant ainsi des sauvegardes incrémentielles.
Voici un exemple de la commande dans sa forme la plus simple :
hbase org.apache.hadoop.hbase.mapreduce.Export
Une fois votre table exportée, vous pouvez copier les fichiers de données résultants où vous le souhaitez (comme le stockage hors site/hors cluster). Vous pouvez également spécifier un cluster/répertoire HDFS distant comme emplacement de sortie de la commande, et Export écrira directement le contenu dans le cluster distant. Veuillez noter que cette approche introduira un élément réseau dans le chemin d'écriture de l'exportation, vous devez donc confirmer que votre connexion réseau au cluster distant est fiable et rapide.
Copier le tableau
L'utilitaire CopyTable est bien couvert dans l'entrée de blog de Jon Hsieh, mais je vais résumer les bases ici. Semblable à Export, CopyTable crée une tâche MapReduce qui utilise l'API HBase pour lire à partir d'une table source. La principale différence est que CopyTable écrit sa sortie directement dans une table de destination dans HBase, qui peut être locale à votre cluster source ou sur un cluster distant.
Un exemple de la forme la plus simple de la commande est :
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Cette commande copiera le contenu d'une table nommée "test" dans une table du même cluster nommée "testCopy".
Notez qu'il y a une surcharge de performances significative pour CopyTable dans la mesure où il utilise des "puts" individuels pour écrire les données, ligne par ligne, dans la table de destination. Si votre table est très volumineuse, CopyTable peut entraîner le remplissage du magasin de mémoire sur les serveurs de la région de destination, nécessitant des vidages du magasin de mémoire qui entraîneront éventuellement des compactages, une récupération de place, etc.
En outre, vous devez prendre en compte les implications en termes de performances de l'exécution de MapReduce sur HBase. Avec de grands ensembles de données, cette approche n'est peut-être pas idéale.
API HTable (telle qu'une application Java personnalisée)
Comme c'est toujours le cas avec Hadoop, vous pouvez toujours écrire votre propre application personnalisée qui utilise l'API publique et interroge directement la table. Vous pouvez le faire via les tâches MapReduce afin d'utiliser les avantages du traitement par lots distribué de ce framework, ou par tout autre moyen de votre propre conception. Cependant, cette approche nécessite une compréhension approfondie du développement Hadoop et de toutes les API et des implications sur les performances de leur utilisation dans votre cluster de production.
Sauvegarde hors ligne des données HDFS brutes
Le mécanisme de sauvegarde le plus brutal - également le plus perturbateur - implique la plus grande empreinte de données. Vous pouvez arrêter proprement votre cluster HBase et copier manuellement toutes les structures de données et de répertoires résidant dans /hbase dans votre cluster HDFS. Étant donné que HBase est en panne, cela garantira que toutes les données ont été conservées dans HFiles dans HDFS et vous obtiendrez une copie précise des données. Cependant, les sauvegardes incrémentielles seront presque impossibles à obtenir car vous ne pourrez pas déterminer quelles données ont été modifiées ou ajoutées lors de tentatives de sauvegardes futures.
Il est également important de noter que la restauration de vos données nécessiterait une méta-réparation hors ligne car le fichier .META. table contiendrait des informations potentiellement non valides au moment de la restauration. Cette approche nécessite également un réseau rapide et fiable pour transférer les données hors site et les restaurer ultérieurement si nécessaire.
Pour ces raisons, Cloudera déconseille fortement cette approche des sauvegardes HBase.
Reprise après sinistre
HBase est conçu pour être un système distribué extrêmement tolérant aux pannes avec une redondance native, en supposant que le matériel échouera fréquemment. La reprise après sinistre dans HBase se présente généralement sous plusieurs formes :
- Échec catastrophique au niveau du centre de données, nécessitant un basculement vers un emplacement de sauvegarde
- Devoir restaurer une copie précédente de vos données en raison d'une erreur de l'utilisateur ou d'une suppression accidentelle
- La possibilité de restaurer une copie ponctuelle de vos données à des fins d'audit
Comme pour tout plan de reprise après sinistre, les besoins de l'entreprise déterminent la manière dont le plan est conçu et le montant à investir. Une fois que vous avez établi les sauvegardes de votre choix, la restauration prend différentes formes en fonction du type de restauration requise :
- Basculement vers le cluster de secours
- Importer une table/Restaurer un instantané
- Pointer le répertoire racine HBase vers l'emplacement de sauvegarde
Si votre stratégie de sauvegarde est telle que vous avez répliqué vos données HBase sur un cluster de sauvegarde dans un centre de données différent, le basculement est aussi simple que de pointer vos applications d'utilisateur final vers le cluster de sauvegarde avec des techniques DNS.
Gardez toutefois à l'esprit que si vous prévoyez d'autoriser l'écriture de données sur votre cluster de sauvegarde pendant la période d'indisponibilité, vous devrez vous assurer que les données reviennent au cluster principal une fois l'indisponibilité terminée. La réplication maître à maître ou cyclique gérera ce processus automatiquement pour vous, mais un schéma de réplication maître-esclave laissera votre cluster maître désynchronisé, nécessitant une intervention manuelle après la panne.
Outre la fonction d'exportation décrite précédemment, il existe un outil d'importation correspondant qui peut prendre les données précédemment sauvegardées par Export et les restaurer dans une table HBase. Les mêmes implications de performances qui s'appliquaient à l'exportation sont également en jeu avec l'importation. Si votre schéma de sauvegarde impliquait de prendre des instantanés, revenir à une copie précédente de vos données est aussi simple que de restaurer cet instantané.
Vous pouvez également récupérer d'un sinistre en modifiant simplement la propriété hbase.root.dir dans hbase-site.xml et en la faisant pointer vers une copie de sauvegarde de votre répertoire /hbase si vous aviez fait la copie hors ligne par force brute des structures de données HDFS. . Cependant, il s'agit également de l'option de restauration la moins souhaitable car elle nécessite une interruption prolongée pendant que vous copiez l'intégralité de la structure de données vers votre cluster de production et, comme mentionné précédemment, .META. peut être désynchronisé.
Conclusion
En résumé, la récupération des données après une certaine forme de perte ou de panne nécessite un plan BDR bien conçu. Je vous recommande vivement de bien comprendre les exigences de votre entreprise en matière de disponibilité, de précision/disponibilité des données et de reprise après sinistre. Fort d'une connaissance détaillée des besoins de votre entreprise, vous pouvez choisir avec soin les outils qui répondent le mieux à ces besoins.
Cependant, la sélection des outils n'est que le début. Vous devez effectuer des tests à grande échelle de votre stratégie BDR pour vous assurer qu'elle fonctionne de manière fonctionnelle dans votre infrastructure, répond aux besoins de votre entreprise et que vos équipes d'exploitation connaissent très bien les étapes requises avant qu'une panne ne se produise et que vous découvriez à vos dépens que votre plan BDR ne fonctionnera pas.
Si vous souhaitez commenter ou discuter davantage de ce sujet, utilisez notre forum communautaire pour HBase.
Autres lectures :
- Présentation Strata + Hadoop World 2012 de Jon Hsieh
- HBase :le guide définitif (Lars George)
- HBase en action (Nick Dimiduk/Amandeep Khurana)



