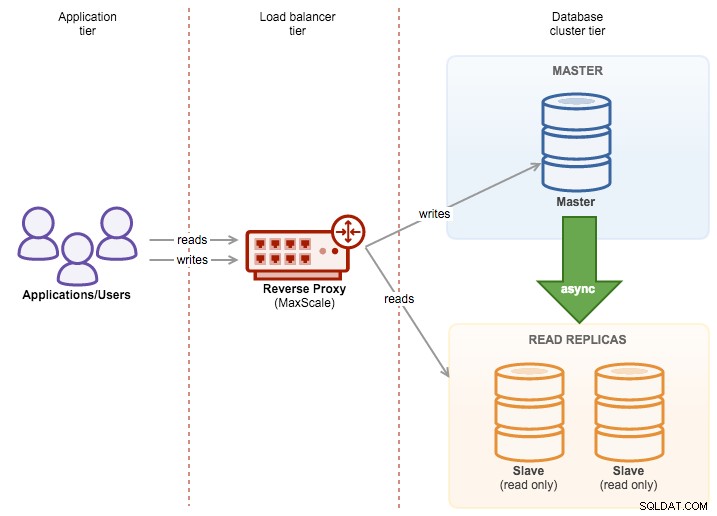
ClusterControl est un excellent outil pour déployer et gérer des clusters de bases de données - si vous êtes dans MySQL, vous pouvez facilement déployer des clusters basés sur la réplication traditionnelle maître-esclave MySQL, Galera Cluster ou MySQL NDB Cluster. Pour atteindre une haute disponibilité, le déploiement d'un cluster n'est cependant pas suffisant. Les nœuds peuvent (et vont très probablement) tomber en panne, et votre système doit être capable de s'adapter à ces changements.
Cette adaptation peut se faire à différents niveaux. Vous pouvez implémenter une sorte de logique dans l'application - elle vérifierait l'état des nœuds du cluster et dirigerait le trafic vers ceux qui sont accessibles à un moment donné. Vous pouvez également créer une couche proxy qui implémentera la haute disponibilité dans votre système. Dans cet article de blog, nous aimerions partager quelques conseils sur la façon dont vous pouvez y parvenir en utilisant ClusterControl.
Déployer HAProxy à l'aide de ClusterControl
HAProxy est la norme - l'un des proxys les plus populaires utilisés en relation avec MySQL (mais pas seulement, bien sûr). ClusterControl prend en charge le déploiement et la surveillance des nœuds HAProxy. Cela aide également à implémenter la haute disponibilité du proxy lui-même à l'aide de keepalived.
Le déploiement est assez simple - vous devez choisir ou remplir l'adresse IP d'un hôte sur lequel HAProxy sera installé, choisir le port, la politique d'équilibrage de charge, décider si ClusterControl doit utiliser le référentiel existant ou le code source le plus récent pour déployer HAProxy. Vous pouvez également choisir les nœuds principaux que vous souhaitez inclure dans la configuration du proxy, et s'ils doivent être actifs ou de secours.
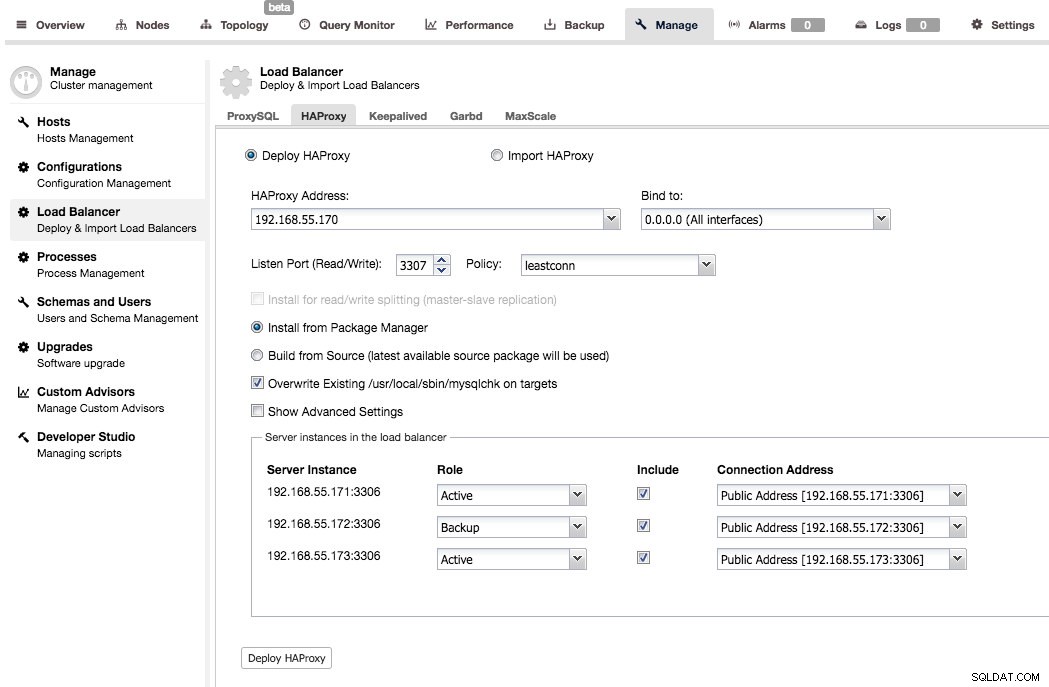
Par défaut, l'instance HAProxy déployée par ClusterControl fonctionnera sur MySQL Cluster (NDB), Galera Cluster, la réplication en continu PostgreSQL et la réplication MySQL. Pour la réplication maître-esclave, ClusterControl peut configurer deux écouteurs, un pour la lecture seule et un autre pour la lecture-écriture. Les applications devront alors envoyer des lectures et des écritures aux ports respectifs. Pour la réplication multimaître, ClusterControl configurera l'équilibrage de charge TCP standard basé sur l'algorithme d'équilibrage de moindre connexion (par exemple, pour Galera Cluster où tous les nœuds sont accessibles en écriture).
Keepalived est utilisé pour ajouter une haute disponibilité à la couche proxy. Lorsque vous avez au moins deux nœuds HAProxy dans votre système, vous pouvez installer Keepalived à partir de l'interface utilisateur de ClusterControl.
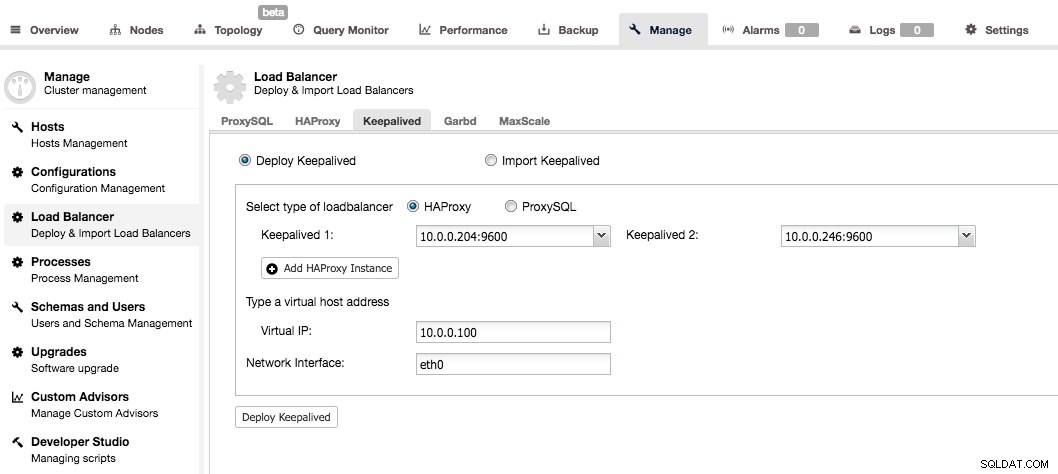
Vous devrez choisir deux nœuds HAProxy et ils seront configurés comme une paire active - en veille. Une adresse IP virtuelle serait attribuée au serveur actif et, en cas d'échec, elle serait réattribuée au proxy de secours. De cette façon, vous pouvez simplement vous connecter au VIP et toutes vos requêtes seront acheminées vers le nœud HAProxy actuellement actif et fonctionnel.
Vous pouvez trouver plus de détails sur la configuration des composants internes en lisant notre tutoriel HAProxy.
Déployer ProxySQL à l'aide de ClusterControl
Bien que HAProxy soit un proxy solide et un choix très populaire, il manque de prise en compte de la base de données, par exemple, la division lecture-écriture. La seule façon de le faire dans HAProxy est de créer deux backends et d'écouter sur deux ports - un pour les lectures et un pour les écritures. C'est généralement correct, mais cela vous oblige à implémenter des modifications dans votre application - l'application doit comprendre ce qu'est une lecture et ce qu'est une écriture, puis diriger ces requêtes vers le bon port. Il serait beaucoup plus facile de se connecter à un seul port et de laisser le proxy décider quoi faire ensuite - c'est quelque chose que HAProxy ne peut pas faire car ce qu'il fait est simplement de router les paquets - aucune inspection des paquets n'est effectuée et, surtout, il n'a pas compréhension du protocole MySQL.
ProxySQL résout ce problème - il parle du protocole MySQL et il peut (entre autres) effectuer une séparation lecture-écriture grâce à ses puissantes règles de requête et acheminer le trafic MySQL entrant selon divers critères. L'installation de ProxySQL à partir de ClusterControl est simple - vous voulez aller dans la section Gérer -> Équilibreur de charge et remplir l'onglet "Déployer ProxySQL" avec les données requises.
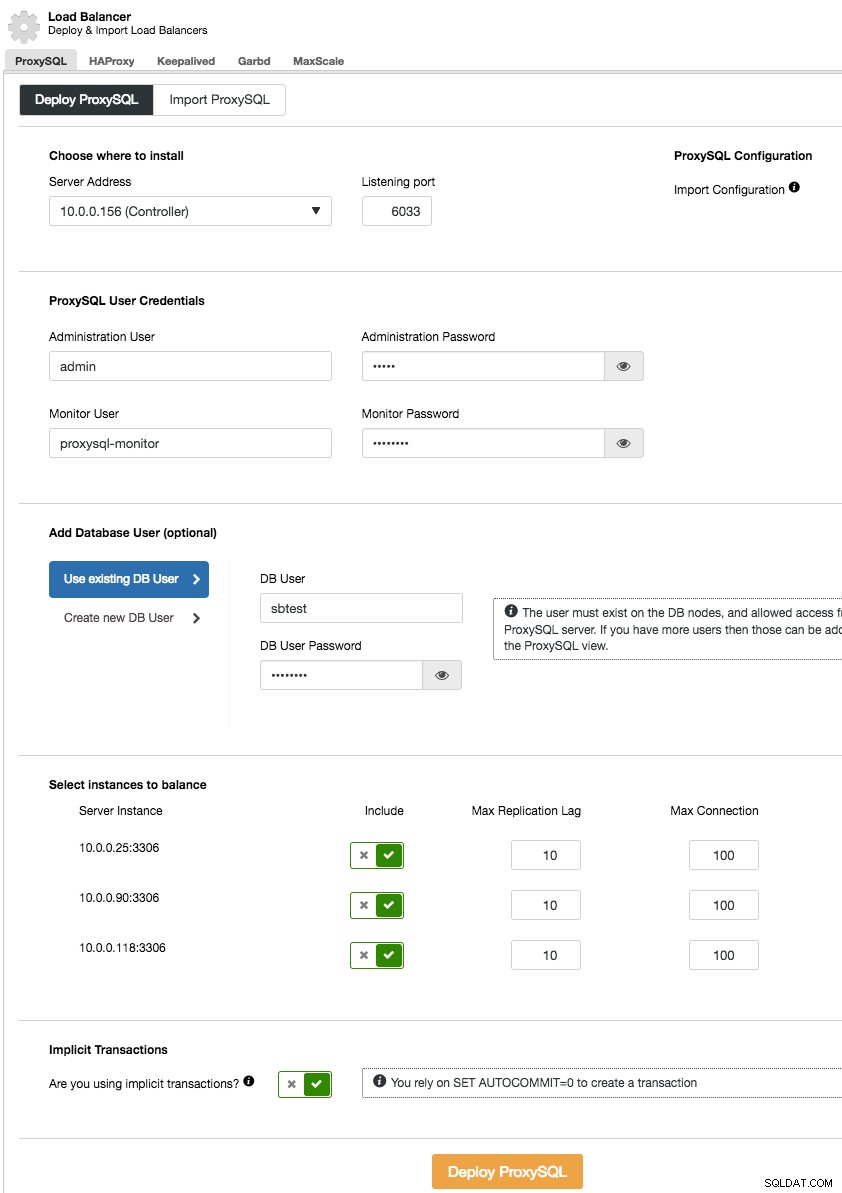
En bref, nous devons choisir où ProxySQL sera installé, quel utilisateur d'administration et quel mot de passe il doit avoir, quel utilisateur de surveillance il doit utiliser pour se connecter aux backends MySQL et vérifier leur statut et l'état du moniteur. À partir de ClusterControl, vous pouvez soit créer un nouvel utilisateur à utiliser par l'application - vous pouvez décider de son nom, de son mot de passe, de l'accès aux bases de données accordées et des privilèges MySQL que cet utilisateur aura. Cet utilisateur sera créé à la fois côté MySQL et ProxySQL. La deuxième option, plus adaptée aux infrastructures existantes, consiste à utiliser les utilisateurs de la base de données existante. Vous devez transmettre le nom d'utilisateur et le mot de passe, et cet utilisateur ne sera créé que sur ProxySQL.
Enfin, vous devez répondre à une question :utilisez-vous des transactions implicites ? Nous entendons par là les transactions démarrées en exécutant SET autocommit=0 ; Si vous l'utilisez, ClusterControl configurera ProxySQL pour envoyer tout le trafic au maître. Ceci est nécessaire pour garantir que ProxySQL traitera correctement les transactions dans ProxySQL 1.3.x et versions antérieures. Si vous n'utilisez pas SET autocommit=0 pour créer une nouvelle transaction, ClusterControl configurera le fractionnement lecture/écriture.
ProxySQL, comme tout proxy, peut devenir un point de défaillance unique et doit être rendu redondant pour atteindre une haute disponibilité. Il existe plusieurs méthodes pour le faire. L'un d'eux consiste à colocaliser ProxySQL sur les nœuds Web. L'idée ici est que, la plupart du temps, le processus ProxySQL fonctionnera très bien et la raison de son indisponibilité est que tout le nœud est tombé en panne. Dans ce cas, si ProxySQL est colocalisé avec le nœud Web, peu de mal a été fait car ce nœud Web particulier ne sera pas disponible non plus.
Une autre méthode consiste à utiliser Keepalived de la même manière que nous l'avons fait dans le cas de HAProxy.
Vous pouvez trouver plus de détails sur la configuration des éléments internes en lisant notre didacticiel ProxySQL.



