Ce billet de blog présentera un exemple simple de type « hello world » sur la façon d'obtenir des données stockées dans S3 indexées et servies par un service Apache Solr hébergé dans un cluster de découverte et d'exploration de données dans CDP. Pour les curieux :DDE est une option de déploiement de cluster optimisée par Solr dans CDP et récemment publiée dans l'aperçu technique . Nous ne couvrirons que les environnements AWS et S3 dans ce blog. Les options de déploiement Azure et ADLS sont également disponibles dans l'aperçu technique, mais seront couvertes dans un futur article de blog.
Nous décrirons le scénario le plus simple pour faciliter le démarrage. Il existe bien sûr des configurations de pipeline de données plus avancées et des schémas plus riches, mais c'est un bon point de départ pour un débutant.
Hypothèses :
- Vous disposez déjà d'un compte CDP et disposez de droits d'utilisateur avancé ou d'administrateur pour l'environnement dans lequel vous envisagez de lancer ce service.
Si vous n'avez pas de compte AWS CDP, veuillez contacter votre représentant Cloudera préféré ou inscrivez-vous pour un essai CDP ici. - Vous avez des environnements et des identités mappés et configurés. Plus explicitement, tout ce dont vous avez besoin est d'avoir le mappage de l'utilisateur CDP à un rôle AWS qui accorde l'accès au compartiment s3 spécifique à partir duquel vous souhaitez lire (et écrire).
- Vous avez déjà défini un mot de passe de charge de travail (FreeIPA).
- Vous avez un cluster DDE en cours d'exécution. Vous pouvez également trouver plus d'informations sur l'utilisation des modèles dans CDP Data Hub ici.
- Vous disposez d'un accès CLI à ce cluster.
- Le port SSH est ouvert sur AWS comme pour votre adresse IP. Vous pouvez obtenir l'adresse IP publique de l'un des nœuds Solr dans les détails du cluster Datahub. Découvrez ici comment vous connecter en SSH à un cluster AWS.
- Vous disposez d'un fichier journal dans un compartiment S3 accessible à votre utilisateur (
/sample.log dans cet exemple). Si vous n'en avez pas, voici un lien vers celui que nous avons utilisé.
Flux de travail
Les sections suivantes vous guideront à travers les étapes pour indexer les données à l'aide de l'outil Crunch Indexer fourni avec DDE.

Créer une collection pour contenir votre index
Dans HUE, il y a un concepteur d'index ; cependant, tant que DDE est dans Tech Preview, il sera quelque peu en cours de reconstruction et n'est pas recommandé à ce stade. Mais s'il vous plaît, essayez-le après la mise en disponibilité de DDE, et dites-nous ce que vous en pensez.
Pour l'instant, vous pouvez créer votre schéma et vos configurations Solr à l'aide de l'outil CLI "solrctl". Créez une configuration appelée « my-own-logs-config » et une collection appelée « my-own-logs ». Cela nécessite que vous disposiez d'un accès CLI.
1. SSH à l'un des nœuds de travail de votre cluster.
2. kinit en tant qu'utilisateur autorisé à créer la configuration de la collection :
kinit
3. Assurez-vous que la variable d'environnement SOLR_ZK_ENSEMBLE est définie dans /etc/solr/conf/solr-env.sh. Enregistrez sa valeur car cela sera nécessaire dans les étapes suivantes.
Appuyez sur Entrée et saisissez le mot de passe de votre charge de travail (FreeIPA).
Par exemple :
cat /etc/solr/conf/solr-env.sh
Sortie attendue :
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Ceci est automatiquement défini sur les hôtes avec un rôle Solr Server ou Gateway dans Cloudera Manager.
4. Pour générer des fichiers de configuration pour la collection, exécutez la commande suivante :
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate est l'un des modèles par défaut fournis avec Solr dans CDP mais, étant un modèle, il est immuable. Pour les besoins de ce workflow, vous devez le copier et ainsi en créer un nouveau qui soit mutable (c'est ce que fait l'option immutable=false). Cela vous offre une configuration flexible et sans schéma. La création d'un schéma bien conçu vaut la peine d'investir du temps de conception, mais n'est pas nécessaire pour une utilisation exploratoire. Pour cette raison, cela dépasse le cadre de cet article de blog. Cependant, dans un environnement de production réel, nous recommandons fortement l'utilisation de schémas bien conçus - et nous sommes heureux de fournir l'aide d'un expert si nécessaire !
5. Créez une nouvelle collection à l'aide de la commande suivante :
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Cela crée la collection "my-own-logs" basée sur la configuration de la collection "my-own-logs-config" sur une partition.
6. Pour valider la création de la collection, vous pouvez accéder à l'interface utilisateur Solr Admin. La collection pour "my-own-logs" sera disponible via le menu déroulant sur la navigation de gauche.

Indexez vos données
Nous décrivons ici, à l'aide d'un exemple simple, comment configurer et exécuter l'outil Crunch Indexer intégré pour indexer rapidement les données dans S3 et servir via Solr dans DDE. Étant donné que la sécurisation du cluster peut utiliser CM Auto TLS, Knox, Kerberos et Ranger, "Spark submit" peut dépendre d'aspects non couverts dans cet article.
L'indexation des données à partir de S3 est identique à l'indexation à partir de HDFS.
Effectuez ces étapes sur le nœud de travail Yarn (appelé « Yarnworker » sur l'interface utilisateur Web de la console de gestion).
1. Connectez-vous en SSH au nœud de travail Yarn dédié du cluster DDE en tant qu'utilisateur administrateur Solr.
Pour connaître l'adresse IP du nœud de travail Yarn, cliquez sur Matériel sur la page des détails du cluster, puis faites défiler jusqu'au nœud "Yarnworker".

2. Accédez à votre répertoire de ressources (ou créez-en un si vous ne l'avez pas déjà :
cd
Utilisez le dossier personnel de l'utilisateur administrateur comme répertoire de ressources (
3. Kinit votre utilisateur :
kinit
Appuyez sur Entrée et saisissez le mot de passe de votre charge de travail (FreeIPA).
4. Exécutez la commande curl suivante, en remplaçant
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Créez un fichier de configuration Morphline pour l'outil Crunch Indexer, read-log-morphline.conf dans cet exemple. Remplacer
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
] Cette Morphline lit les traces de la pile à partir du fichier journal donné, puis écrit un journal d'entrée de débogage et le charge dans le Solr spécifié.
6. Créez un fichier log4j.properties pour la configuration du journal :
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Vérifiez si le fichier que vous souhaitez lire existe sur S3 (si vous n'en avez pas, voici un lien vers celui que nous avons utilisé pour cet exemple simple :
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Exécutez la commande spark-submit :
Remplacez les espaces réservés dans
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Si vous rencontrez un message similaire, vous pouvez l'ignorer :
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
9. Pour surveiller l'exécution de la commande, accédez au gestionnaire de ressources.

Une fois là-bas, sélectionnez les Applications onglet > Cliquez sur l'ID d'application de la tentative d'application que vous souhaitez surveiller > Sélectionnez Journaux> Choisissez une tentative de récupération des conteneurs> Choisissez un conteneur pour récupérer les journaux> Choisissez un journal pour le conteneur> Sélectionnez le stderr log> Cliquez sur Cliquez ici pour le journal complet .
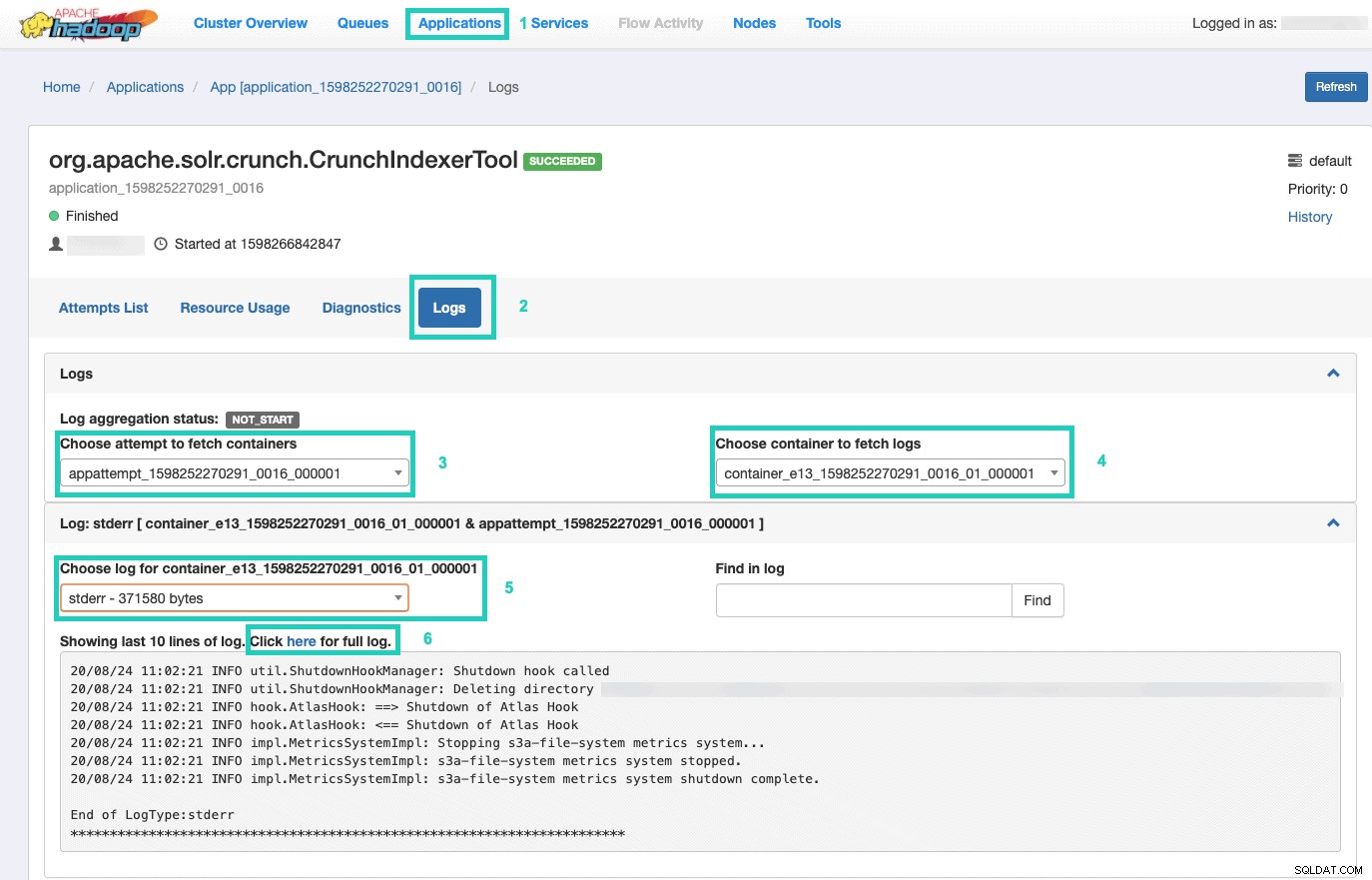
Servez votre index
Vous disposez de nombreuses options pour fournir les données indexées consultables aux utilisateurs finaux. Vous pouvez créer votre propre application riche basée sur les API riches de Solr (très courantes). Vous pouvez connecter votre outil tiers préféré, tel que Qlik, Tableau, etc. via leurs connexions Solr certifiées. Vous pouvez utiliser le tableau de bord solr simple de Hue pour créer des applications prototypes.
Pour faire ce dernier :
1. Allez à Teinte.

2. Dans la vue du tableau de bord, accédez au fichier d'index de votre choix (par exemple, celui que vous venez de créer).
3. Commencez à faire glisser et déposer divers éléments du tableau de bord et sélectionnez les champs de l'index pour remplir les données du visuel à portée de main.
Un didacticiel vidéo rapide sur le tableau de bord du passé peut être trouvé ici, pour vous inspirer.
Nous laisserons une plongée plus profonde pour un futur article de blog.
Résumé
Nous espérons que vous avez beaucoup appris de ce billet de blog sur la façon d'obtenir des données dans S3 indexées par Solr dans un DDE à l'aide de l'outil Crunch Indexer. Bien sûr, il existe de nombreuses autres façons (Spark dans l'expérience Data Engineering, Nifi dans l'expérience Data Flow, Kafka dans l'expérience Stream Management, etc.), mais celles-ci seront couvertes dans de futurs articles de blog. Nous espérons que vous réussirez votre voyage continu vers la création d'applications d'analyse puissantes impliquant du texte et d'autres données non structurées. Si vous décidez d'essayer DDE dans CDP, faites-nous savoir comment tout s'est passé !



