Nous allons générer des adresses IP, les géolocaliser et les tracer :
library(iptools)
library(rgeolocate)
library(tidyverse)
Générez un million d'adresses IPv4 aléatoires (trop uniformément réparties) :
ips <- ip_random(1000000)
Et, géolocalisez-les :
system.time(
rgeolocate::maxmind(
ips, "~/Data/GeoLite2-City.mmdb", c("longitude", "latitude")
) -> xdf
)
## user system elapsed
## 5.016 0.131 5.217
5s pour 1m IPv4s. 👍🏼
Maintenant, en raison de l'uniformité, les bulles seront stupides, donc juste pour cet exemple, nous allons les arrondir un peu :
xdf %>%
mutate(
longitude = (longitude %/% 5) * 5,
latitude = (latitude %/% 5) * 5
) %>%
count(longitude, latitude) -> pts
Et tracez-les :
ggplot(pts) +
geom_point(
aes(longitude, latitude, size = n),
shape=21, fill = "steelblue", color = "white", stroke=0.25
) +
ggalt::coord_proj("+proj=wintri") +
ggthemes::theme_map() +
theme(legend.justification = "center") +
theme(legend.position = "bottom")
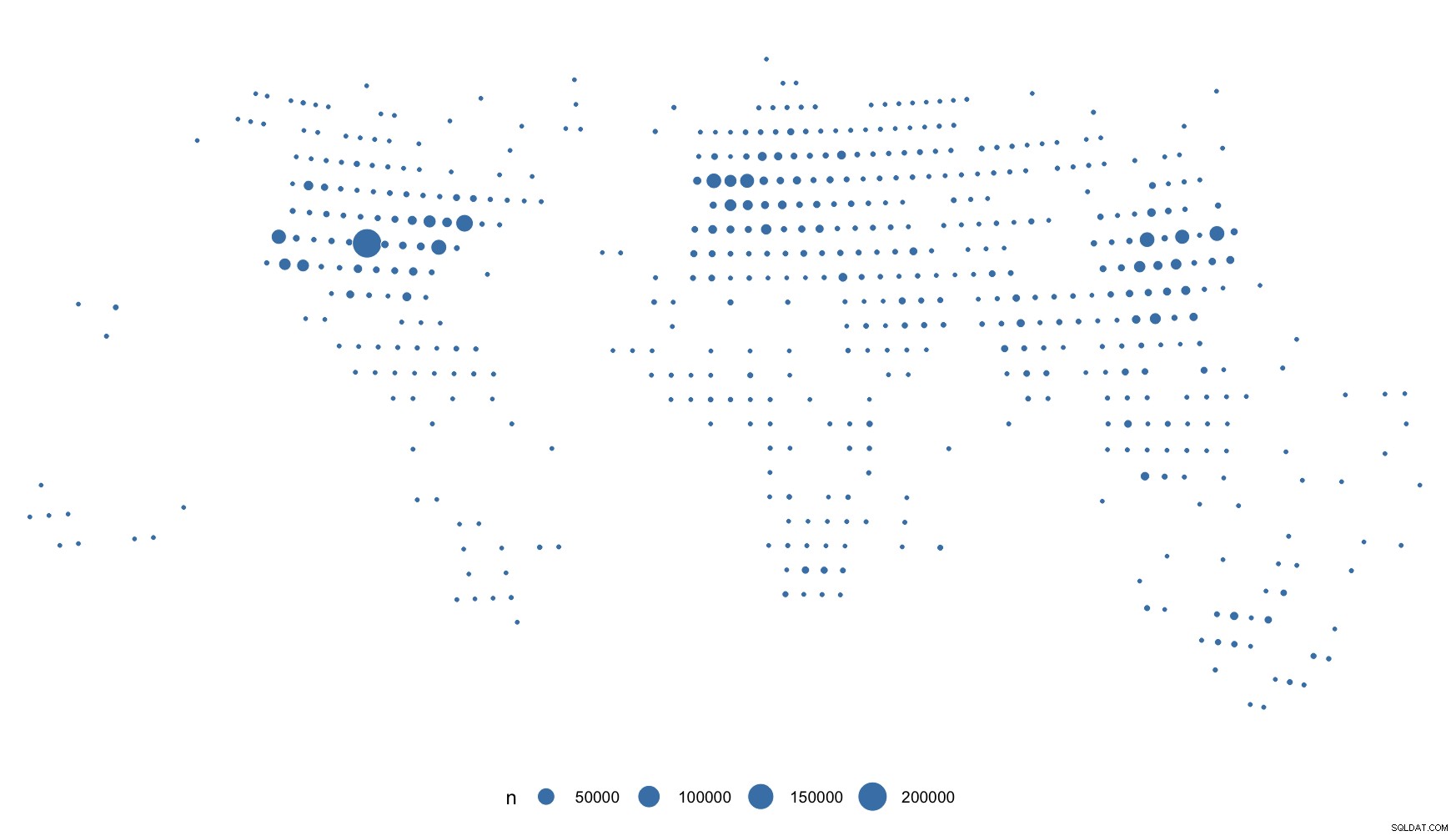
Vous pouvez voir ce que je veux dire par "trop uniforme". Mais, vous avez de "vrais" IPv4, vous devriez donc être gtg.
Envisagez d'utiliser scale_size_area() , mais, honnêtement, envisagez de ne pas tracer du tout les IPv4 sur une carte géographique. Je fais des recherches sur Internet pour gagner ma vie et les revendications d'exactitude laissent beaucoup à désirer. Je vais rarement en dessous de l'attribution au niveau du pays pour cette raison (et nous payons pour des données "réelles").