Dans cet article, nous parlerons des points de contrôle SQL Server.
Pour améliorer les performances, SQL Server applique des modifications aux pages de base de données en mémoire. Souvent, cette mémoire est appelée cache de tampons ou pool de tampons. SQL Server ne vide pas ces pages sur le disque après chaque modification. Au lieu de cela, le moteur de base de données effectue une opération de point de contrôle sur chaque base de données de temps en temps. Le POINT DE CONTRÔLE l'opération écrit les pages modifiées (pages modifiées en mémoire actuelles) et écrit également des détails sur le journal des transactions.
SQL Server prend en charge quatre types de points de contrôle :
EXEC sp_configure 'recovery interval', 'seconds'
Dans le modèle de récupération SIMPLE, un point de contrôle automatique est également déclenché lorsque le journal des transactions est plein à 70 %.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Lors de la configuration, tenez compte des capacités du sous-système d'E/S sous-jacent. Il peut être judicieux de régler ce paramètre plus bas pour des sous-systèmes d'E / S plus rapides (par exemple, des SSD). Attention, ce paramètre persiste pendant la sauvegarde et la restauration. La restauration sur un matériel plus lent peut donc entraîner des problèmes de performances en raison d'une charge d'E/S trop importante.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration est un entier utilisé pour définir la durée pendant laquelle un point de contrôle doit se terminer. Ce paramètre régit également le nombre de ressources affectées à l'opération de point de contrôle. Si le paramètre n'est pas spécifié, le point de contrôle se terminera dans le temps qui minimise l'impact sur les performances.
- Un fichier de données est ajouté ou supprimé
- Une fermeture de base de données se produit (pour quelque raison que ce soit)
- Une sauvegarde ou un instantané de base de données est créé
- Une commande DBCC est exécutée et crée un instantané de base de données masqué (ou, par exemple, DBCC_CHECKDB, DBCC_CHECKTABLE).
Pourquoi les points de contrôle sont-ils utiles ?
Les points de contrôle réduisent le temps de récupération après un crash. Cela se produit car les pages du fichier de données ne sont pas écrites sur le disque en même temps que les enregistrements du journal. Certaines pages de fichiers de données en mémoire sont plus à jour que les pages de fichiers de données sur disque.
Les points de contrôle réduisent les E/S sur le disque et améliorent les performances. La raison pour laquelle les pages du fichier de données ne sont pas écrites sur le disque au moment de la validation de la transaction est de réduire le nombre d'opérations d'E/S. Imaginez les plusieurs milliers de transactions UPDATE sur une seule page de données. Il est plus efficace d'écrire une page de données sur le disque une seule fois, lors d'un point de contrôle, plutôt qu'après chaque modification.
Pages propres et sales
Le pool de mémoire tampon conserve un certain nombre de pages de données en mémoire. Il existe deux types de pages de données :propres et sale . Une page propre est une page qui n'a pas été modifiée depuis sa dernière lecture à partir du disque ou sa dernière écriture sur le disque. Une page sale est une page qui a été modifiée et les modifications n'ont pas été écrites sur le disque. Les points de contrôle font référence aux "pages sales".
Les informations sur la page peuvent être consultées à l'aide de sys.dm_os_buffer_descriptors . Voyons ce que cette fonction renvoie :
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
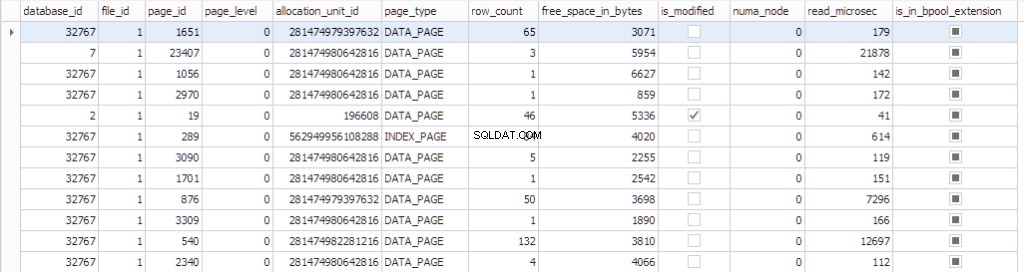
Chaque page est associée à une structure de contrôle qui suit l'état de la page :
- Une base de données qui a le datdabase_id 32767 est une base de données de ressources en lecture seule qui contient tous les objets système.
- file_id , id_page , allocation_unit_id cette page appartient.
- De quel type de page il s'agit :soit une page de données, soit une page d'index.
- Le nombre de lignes sur la page.
- L'espace libre sur la page
- Si la page est sale ou non
- Le numa_node auquel appartient la page particulière
- Quelques informations sur l'algorithme Last-Recently-Used
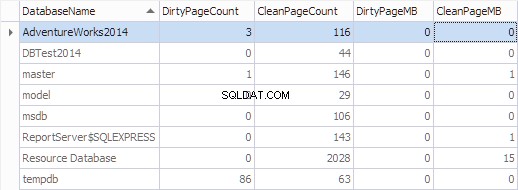
Agrégeons ces informations par base de données en utilisant le code suivant :
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Mécanisme de point de contrôle
Lorsque le point de contrôle se produit, il écrit toutes les pages modifiées sur le disque. Les pages marquées comme sales dès qu'elles ont des modifications. Peu importe que la transaction qui a effectué la modification soit validée ou non validée au moment du point de contrôle. Une fois les pages écrites sur le disque, le bit « sale » est effacé. Lorsque le point de contrôle se produit, les actions suivantes ont lieu :
- Un nouvel enregistrement de journal indique le début d'un point de contrôle
- Des enregistrements de journal supplémentaires apparaissent avec des informations de point de contrôle (comme l'état du journal des transactions au moment où le point de contrôle est lancé)
- Toutes les pages modifiées sont écrites sur le disque
- Marquez le LSN du point de contrôle dans la page de démarrage de la base de données (dans le dbi_checkptLSN), ceci est essentiel pour la récupération après un crash
- Si le modèle de récupération SIMPLE est utilisé, essayez d'effacer le journal
- Un enregistrement final du journal indique que le point de contrôle est terminé
Il est possible que des points de contrôle de plusieurs bases de données se produisent en parallèle. Le SQL Server 2000 était limité à un point de contrôle à la fois. Lorsque le gestionnaire de tampon écrit une page, il recherche les pages modifiées adjacentes qui peuvent être incluses dans une seule opération de collecte-écriture. De plus, le pool de mémoire tampon va essayer de s'assurer qu'il ne surcharge pas le sous-système d'E/S. Il garde une trace du temps qu'il faut pour que les E/S se terminent. Si la latence d'écriture dépasse 20 ms pendant le point de contrôle, il se limite. Pendant l'arrêt, le seuil de limitation augmente à 100 ms. Vous pouvez trouver une explication plus détaillée ici. Vous pouvez utiliser l'option de démarrage "-kXX" non documentée pour définir le taux d'E/S du point de contrôle à XX Mo/s.
Lorsque la page du fichier de données est écrite sur le disque par un point de contrôle, la journalisation à écriture anticipée garantit que tous les enregistrements de journal affectant cette page doivent d'abord être écrits dans le journal des transactions sur le disque. Tous les enregistrements de journal jusqu'au dernier qui a affecté la page sont écrits, quelle que soit la transaction à laquelle ils appartiennent. Les enregistrements de journal sont écrits de trois manières :
- Lorsqu'une transaction est validée ou abandonnée
- Lorsque la page du fichier de données est écrite sur le disque
- Lorsqu'un bloc de journal atteint la taille maximale de 60 Ko et se termine de force
Enregistrement du journal des points de contrôle
Les points de contrôle écrivent plusieurs enregistrements de journal dans le journal des transactions :
- LOP_BEGIN_CKPT — signifie que le point de contrôle a commencé
- LOP_XACT_CKPT avec un contexte NULL (uniquement s'il y a des transactions non validées au moment où le point de contrôle a démarré) - contient un décompte du nombre de transactions non validées. Il répertorie également les LSN des enregistrements de journal LOP_BEGIN_XACT des transactions non validées.
- LOP_BEGIN_CKPT avec un contexte de LOP_BOOT_PAGE_CKPT (SQL Server 2012 uniquement) — signifie que la page de démarrage a été mise à jour.
- LOP_END_CKPT — signifie la fin du point de contrôle.
Surveillance des points de contrôle
Il peut être utile de corréler les points de contrôle se produisant avec des pics d'E/S afin que des modifications puissent être apportées à la base de données spécifique (pour le sous-système d'E/S) afin d'atténuer le pic d'E/S s'il surcharge le sous-système d'E/S. Par exemple, effectuer des points de contrôle manuels plus fréquents ou configurer un intervalle de récupération inférieur sur SQL Server 2012 avec des points de contrôle indirects. Cela produira une charge d'E/S plus constante sans pics élevés qui surchargent le sous-système d'E/S. Cependant, la cause principale peut être que davantage d'E/S sont effectuées en raison d'un changement quelque part, alors n'acceptez pas simplement une augmentation soudaine de l'activité des points de contrôle sans rechercher pourquoi cela s'est produit.
Le compteur Buffer Manager/Checkpoint pages/sec n'est pas spécifique à la base de données, donc l'identification de la base de données impliquée nécessite des indicateurs de trace ou des événements étendus.
Indicateur de suivi 3502 écrit des messages dans le journal des erreurs concernant le point de contrôle de la base de données.
Indicateur de suivi 3504 écrit des informations plus détaillées sur le nombre de pages écrites et la latence d'écriture moyenne.
Ces indicateurs de trace peuvent être utilisés en toute sécurité en production pour une durée limitée. Tout ce qu'ils font, c'est imprimer des messages dans le journal des erreurs.
Si vous souhaitez utiliser des événements étendus, vous pouvez utiliser deux événements :checkpoint_begin et checkpoint_end.
Résumé
Dans cet article, nous avons parlé des points de contrôle dans SQL Server - le principal mécanisme d'écriture des pages de fichiers de données sur le disque après leur modification.



