Un modèle de données de paie vous permet de calculer facilement le salaire de vos employés. Comment fonctionne ce modèle ?
Que vous dirigiez une petite ou une grande entreprise, vous avez besoin d'une sorte de solution de paie. C'est là qu'une application de paie est utile. De plus, plus l'entreprise est grande, plus il est difficile de gérer les calculs de salaire des employés ; ici, une application de paie devient une nécessité. Pour vous aider à comprendre toutes les données requises pour une telle application, nous vous guiderons à travers un modèle de données associé.
Voyons comment fonctionne notre modèle de données de paie !
Modèle de données
En créant ce modèle de données, j'ai essayé de créer un modèle généralement applicable à toutes les entreprises. Bien sûr, il y aura toujours des différences dans les réglementations, les politiques de l'entreprise, etc. qui nécessiteront que le modèle soit personnalisé pour couvrir les besoins d'une masse salariale spécifique. Cependant, les principes énoncés dans ce modèle devraient être pertinents pour la plupart des organisations.
Il faut noter que ce modèle a été créé avec plusieurs hypothèses :
- Les salaires convenus dans le contrat de travail sont annuels.
- Les salaires nets (c'est-à-dire avec certains montants déduits pour les impôts, etc.) sont versés aux employés.
- Les salaires sont payés mensuellement.
Le modèle de données se compose de quatorze tables et est divisé en deux domaines :
EmployeesSalaries
Pour mieux comprendre le modèle, il est nécessaire de parcourir chaque domaine de manière approfondie.
Employés
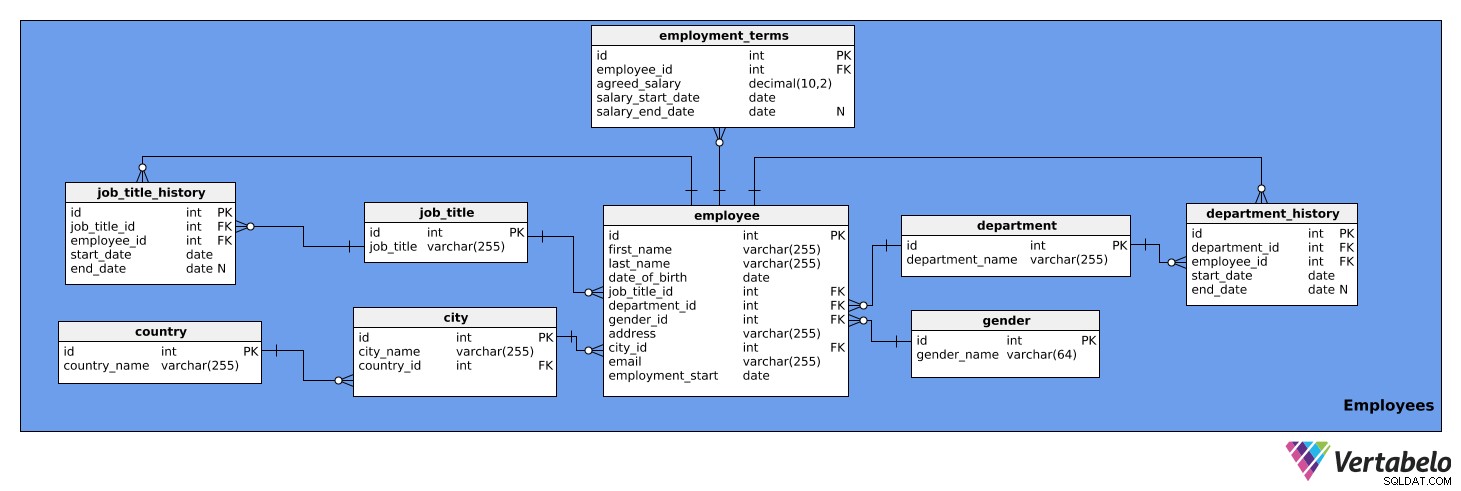
Ce domaine contient des informations détaillées sur les employés. Il se compose de neuf tables :
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
Le premier tableau que nous allons examiner est le employee table. Il contient une liste de tous les employés et leurs détails pertinents. Les attributs du tableau sont :
id– Un identifiant unique pour chaque employé.first_name– Le prénom de l'employé.last_name– Le nom de famille de l'employé.job_title_id– Fait référence aujob_titletableau.department_id– Référence ledepartmenttableau.gender_id– Fait référence augendertableau.address– L'adresse de l'employé.city_id– Référence lacitytableau.email– L'e-mail de l'employé.employment_start– La date à laquelle l'emploi de cette personne a commencé.
Notez que les colonnes job_title_id et department_id sont redondants, car les informations sur les intitulés de poste et les départements actuels sont accessibles depuis le job_title_history et department_history les tables. Cependant, nous conserverons ces deux colonnes dans ce tableau pour un accès plus rapide aux informations.
Voici les employment_terms table. Il stocke des données sur le salaire de chaque employé, comme convenu dans le contrat de travail, et sur son évolution dans le temps. Les attributs du tableau sont :
id– Un identifiant unique pour chaque ensemble de conditions d'emploi.employee_id– Fait référence auemployeetableau.agreed_salary– Le salaire indiqué dans le contrat de travail.salary_start_date– La date de début du salaire convenu.salary_end_date– La date de fin du salaire convenu. Cela peut être NULL car un salaire peut ne pas avoir de changement prévu.
Le job_title table est une liste des intitulés de poste pouvant être attribués à divers employés de l'entreprise, par ex. analyste, chauffeur, secrétaire, directeur, etc. La table a les attributs suivants :
id– Un identifiant unique pour chaque intitulé de poste.job_title– Le nom de l'intitulé du poste. C'est la clé secondaire.
Nous avons également besoin d'une table pour stocker l'historique des titres de poste de chaque employé. Nous en avons besoin car les employés peuvent être promus, rétrogradés ou réaffectés au sein de l'entreprise. Le job_title_history table gérera ces informations et se composera des attributs suivants :
id– Un identifiant unique pour l'entrée historique du titre du poste.job_title_id– Fait référence aujob_titletableau.employee_id– Fait référence auemployeetableau.start_date– La date à laquelle l'employé a occupé ce poste pour la première fois.end_date– Lorsque l'employé a cessé d'avoir ce titre d'emploi. Cela peut être NULL parce que l'employé peut actuellement détenir ce titre de poste.
La combinaison de job_title_id , employee_id , et start_date est la clé alternative pour le tableau ci-dessus. Un employé ne peut avoir qu'un seul titre de poste attribué à une date donnée.
Le tableau suivant est le department table. Celui-ci listera simplement tous les services de l'entreprise, tels que l'informatique, la comptabilité, le juridique, etc. Il contient deux attributs :
id– Un identifiant unique pour chaque département.department_name– Le nom de chaque département. C'est la clé secondaire.
Les employés peuvent également changer de service au sein de l'entreprise. Par conséquent, nous avons besoin d'un department_history table. Cette table stockera les éléments suivants :
id– Un ID unique pour cette entrée historique de service.department_id– Référence ledepartmenttableau.employee_id– Fait référence auemployeetableau.start_date– La date à laquelle un employé a commencé à travailler dans un service.end_date- La date à laquelle un employé a cessé de travailler dans ce service. Cela peut être NULL car l'employé peut toujours y travailler.
La combinaison de department_id , employee_id , et start_date est la clé alternative. Un employé ne peut travailler que dans un seul département à la fois.
Le tableau suivant dont nous parlerons est la city table. Ceci est une liste de toutes les villes concernées. Il a les attributs suivants :
id– Un identifiant unique pour chaque ville.city_name– Le nom de la ville.country_id– Fait référence aucountrytableau.
Le country table est la suivante dans notre modèle. Il s'agit simplement d'une liste de pays et elle contient les informations suivantes :
id– Un identifiant unique pour chaque pays.country_name– Le nom du pays. C'est la clé secondaire.
Le dernier tableau de ce domaine est le gender table. Ce tableau répertorie tous les sexes. Il contient les attributs suivants :
id– Un identifiant unique pour chaque sexe.gender_name– Le nom du genre.
Analysons maintenant le deuxième domaine.
Salaire
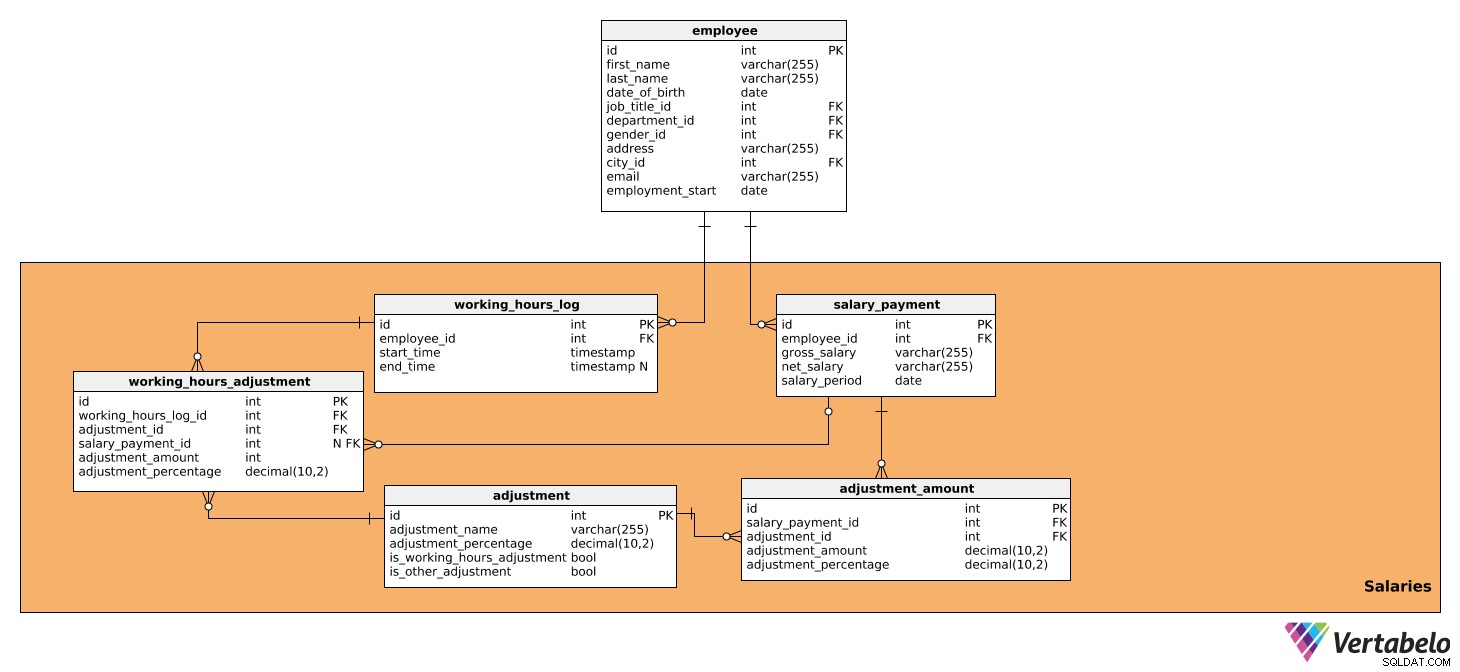
Ce domaine se compose de tableaux qui contiennent toutes les données qui influencent directement les calculs de salaire pour chaque période ainsi que le montant à payer. Il est composé de cinq tableaux :
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Examinons maintenant chaque tableau.
Le premier tableau est salary_payment . Il contient tous les détails pertinents sur le salaire versé à chaque employé et possède les attributs suivants :
id– Un identifiant unique pour chaque salaire.employee_id– Fait référence auemployeetableau.gross_salary– Le salaire brut, qui servira de base aux ajustements ultérieurs.net_salary– Le salaire net (c'est-à-dire le montant reçu par l'employé après diverses déductions).salary_period– La période pour laquelle le salaire est calculé et payé.
Le deuxième est le working_hours_log table. Il contient des données sur le nombre d'heures travaillées par chaque employé, ce qui peut influencer certains ajustements salariaux. Ce tableau a les attributs suivants :
id– Un identifiant unique pour chaque entrée de journal.employee_id– Fait référence auemployeetableau.start_time– L'heure à laquelle l'employé s'est connecté, c'est-à-dire qu'il a commencé à travailler pour la journée.end_time– Lorsque l'employé s'est déconnecté. Il peut être NULL car nous ne connaîtrons pas l'heure exacte jusqu'à ce que l'employé se déconnecte.
Le prochain tableau que nous analyserons est working_hours_adjustment . Ce tableau ne sera utilisé que dans le calcul des ajustements basés sur les heures travaillées, c'est-à-dire ceux qui ont une valeur TRUE dans is_working_hours_adjustment dans le adjustment table. Les attributs sont les suivants :
id– Un identifiant unique pour chaque ajustement.working_hours_log_id– Fait référence auworking_hours_logtableau.adjustment_id- Fait référence à l'adjustmenttableau.salary_payment_id– Fait référence ausalary_paymenttable. Cette valeur peut être NULL carsalary_payment_idne sera utilisé qu'une fois par mois, lorsque nous lancerons un calcul de salaire.adjustment_amount– Le montant de l'ajustement.adjustment_percentage– Le pourcentage de l'ajustement. Il sera utilisé à des fins historiques, car le pourcentage peut changer au fil du temps.
Le tableau suivant dont nous parlerons est l'adjustment table. Il contient des informations sur tous les ajustements utilisés pour le calcul du salaire, c'est-à-dire tous les impôts et cotisations qui ont un impact sur le montant du salaire. De plus, il contiendra tous les ajustements qui dépendent des heures travaillées et non travaillées, comme les primes, les heures supplémentaires, les congés de maladie et les congés de maternité/paternité. Pour cela, nous avons besoin des données suivantes :
id– Un identifiant unique pour chaque ajustement.adjustment_name– Un nom décrivant cet ajustement.adjustment_percentage– Le pourcentage du montant de l'ajustement particulier.is_working_hours_adjustment– Il s'agit d'un signalement si un ajustement dépend directement des heures de travail, par ex. heures supplémentaires, congés de maladie, etc.is_other_adjustment– Il s'agit d'un drapeau marquant des ajustements qui ne font pas dépendent directement des heures travaillées, telles que les déductions fiscales, les cotisations de sécurité sociale, les cotisations patronales, etc.
Après cela, nous avons besoin du adjustment_amount table. Il sera utilisé pour calculer tous les ajustements de salaire sauf ceux déjà dans le working_hours_adjustment , c'est-à-dire ceux qui ont une valeur TRUE dans is_other_adjustment dans le adjustment table. Le tableau contient les attributs suivants :
id– Un identifiant unique pour chaque entrée de montant d'ajustement.salary_payment_id– Fait référence ausalary_paymenttableau.adjustment_id– Fait référence auadjustmenttableau.adjustment_amount– Le montant de chaque ajustement calculé.adjustment_percentage- Le pourcentage du montant de l'ajustement. Il sera utilisé à des fins historiques, car le pourcentage peut changer au fil du temps.
Permettez-moi de vous donner un exemple de la façon dont les tables working_hours_log , working_hours_adjustment , adjustment , et adjustment_amount travailler ensemble pour calculer un salaire. Chaque jour, l'employé se connecte quand il arrive au travail et quand il part. Ces données peuvent être consultées dans le working_hours_log table. Disons que notre employé a travaillé 10 heures supplémentaires pendant un mois et, selon la politique de l'entreprise, il sera payé 20 % de plus de l'heure pour chaque heure supplémentaire. En faisant référence au adjustment tableau, nous pourrons trouver l'ajustement requis, c'est-à-dire les heures supplémentaires, qui auront un certain pourcentage (20%). Nous aurons également is_working_hours_adjustment défini sur VRAI. En utilisant les données de ces deux tables, nous pourrons calculer l'ajustement et le stocker dans le working_hours_adjustment table.
Nous pouvons maintenant calculer tous les autres ajustements qui ne le font pas dépendent des heures travaillées. Cela se fera dans le adjustment_amount table. Tout comme nous l'avons fait ci-dessus, nous ferons référence à l'adjustment tableau et trouver les ajustements dont nous avons besoin - par ex. déduction fiscale, cotisation de sécurité sociale ou contribution de l'employeur - et leurs pourcentages respectifs. Le is_other_adjustment drapeau dans le adjustment table sera défini sur TRUE pour ces ajustements.
Sur la base de ces calculs, nous pouvons stocker les données de salaire brut et de salaire net dans le salary_payment table.
En parcourant cet exemple, nous avons tout couvert dans notre modèle de données !
Avez-vous aimé le modèle de données de paie ?
J'ai essayé de créer un modèle qui pourrait être utilisé dans presque toutes les situations. Cependant, il est impossible d'inclure tous les paramètres spécifiques qui influencent le calcul du salaire dans un article de cette longueur. En couvrant les principes généraux, j'ai essayé de faire de ce modèle une base solide pour votre modèle de données de paie.
Que pensez-vous du modèle de données de paie ? Est-il applicable comme solution pour vos besoins en matière de paie? Avez-vous trouvé quelque chose de différent? Y a-t-il des problèmes spécifiques que vous avez trouvés qui modifieraient considérablement le modèle de données ? Exprimez-vous dans la section des commentaires.



