Python est très populaire de nos jours. Étant donné que Python est un langage de programmation à usage général, il peut également être utilisé pour effectuer le processus Extract, Transform, Load (ETL). Différents modules ETL sont disponibles, mais aujourd'hui, nous nous en tiendrons à la combinaison de Python et MySQL. Nous utiliserons Python pour invoquer des procédures stockées et préparer et exécuter des instructions SQL.
Nous utiliserons deux approches similaires mais différentes. Tout d'abord, nous invoquerons des procédures stockées qui feront tout le travail, puis nous analyserons comment nous pourrions faire le même processus sans procédures stockées en utilisant le code MySQL en Python.
Prêt? Avant de creuser, examinons le modèle de données - ou les modèles de données, car il y en a deux dans cet article.
Les modèles de données
Nous aurons besoin de deux modèles de données, l'un pour stocker nos données opérationnelles et l'autre pour stocker nos données de rapport.
Le premier modèle est montré dans l'image ci-dessus. Ce modèle est utilisé pour stocker des données opérationnelles (en direct) pour une entreprise basée sur un abonnement. Pour plus d'informations sur ce modèle, veuillez consulter notre article précédent, Création d'un DWH, première partie :un modèle de données d'entreprise par abonnement.
La séparation des données opérationnelles et des rapports est généralement une décision très judicieuse. Pour réaliser cette séparation, nous devrons créer un entrepôt de données (DWH). Nous l'avons déjà fait; vous pouvez voir le modèle dans l'image ci-dessus. Ce modèle est également décrit en détail dans l'article Création d'un DWH, deuxième partie :un modèle de données d'entreprise par abonnement.
Enfin, nous devons extraire les données de la base de données en direct, les transformer et les charger dans notre DWH. Nous l'avons déjà fait en utilisant des procédures stockées SQL. Vous pouvez trouver une description de ce que nous voulons réaliser ainsi que des exemples de code dans Création d'un entrepôt de données, partie 3 :un modèle de données métier d'abonnement.
Si vous avez besoin d'informations supplémentaires concernant les DWH, nous vous recommandons de lire ces articles :
- Le schéma en étoile
- Le schéma du flocon de neige
- Schéma en étoile contre schéma en flocon de neige.
Notre tâche aujourd'hui est de remplacer les procédures stockées SQL par du code Python. Nous sommes prêts à faire de la magie Python. Commençons par utiliser uniquement les procédures stockées en Python.
Méthode 1 :ETL à l'aide de procédures stockées
Avant de commencer à décrire le processus, il est important de mentionner que nous avons deux bases de données sur notre serveur.
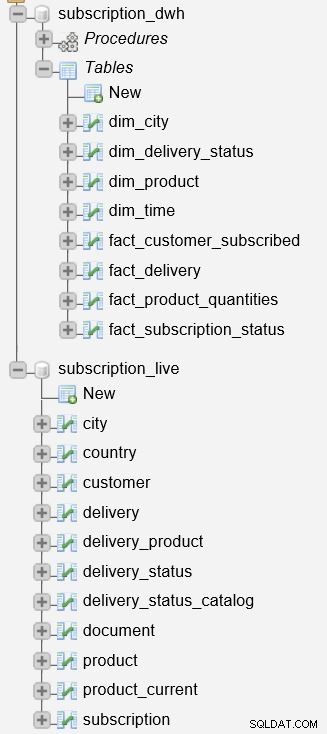
Le subscription_live la base de données est utilisée pour stocker les données transactionnelles/en direct, tandis que le subscription_dwh est notre base de données de rapports (DWH).
Nous avons déjà décrit les procédures stockées utilisées pour mettre à jour les tables de dimensions et de faits. Ils liront les données de subscription_live base de données, combinez-la avec les données dans le subscription_dwh base de données et insérez de nouvelles données dans le subscription_dwh base de données. Ces deux procédures sont :
p_update_dimensions– Met à jour les tables de dimensiondim_timeetdim_city.p_update_facts– Met à jour deux tables de faits,fact_customer_subscribedetfact_subscription_status.
Si vous souhaitez voir le code complet de ces procédures, lisez Création d'un entrepôt de données, partie 3 :un modèle de données métier par abonnement.
Nous sommes maintenant prêts à écrire un script Python simple qui se connectera au serveur et exécutera le processus ETL. Examinons d'abord l'ensemble du script (etl_procedures.py ). Ensuite, nous expliquerons les parties les plus importantes.
# import MySQL connectorimport mysql.connector# connect to serverconnection =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('Connecté à base de données.')cursor =connection.cursor()# Je mets à jour les dimensionscursor.callproc('subscription_dwh.p_update_dimensions')print('Tables de dimensions mises à jour.')# II met à jour les faitscursor.callproc('subscription_dwh.p_update_facts')print('Fact tables mises à jour.')# commit &close connectioncursor.close()connection.commit()connection.close()print('Déconnecté de la base de données.')
etl_procedures.py
Importer des modules et se connecter à la base de données
Python utilise des modules pour stocker des définitions et des déclarations. Vous pouvez utiliser un module existant ou écrire le vôtre. L'utilisation de modules existants vous simplifiera la vie car vous utilisez du code pré-écrit, mais écrire votre propre module est également très utile. Lorsque vous quittez l'interpréteur Python et que vous le relancez, vous perdez les fonctions et les variables que vous avez précédemment définies. Bien sûr, vous ne voulez pas taper le même code encore et encore. Pour éviter cela, vous pouvez stocker vos définitions dans un module et l'importer dans Python.
Retour à etl_procedures.py . Dans notre programme, nous commençons par importer MySQL Connector :
# import MySQL connectorimport mysql.connector
Le connecteur MySQL pour Python est utilisé comme un pilote standardisé qui se connecte à un serveur/une base de données MySQL. Vous devrez le télécharger et l'installer si vous ne l'avez pas déjà fait. Outre la connexion à la base de données, il offre un certain nombre de méthodes et de propriétés pour travailler avec une base de données. Nous en utiliserons certains, mais vous pouvez consulter la documentation complète ici.
Ensuite, nous devrons nous connecter à notre base de données :
# connect to serverconnection =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('Connecté à la base de données.')cursor =connection .curseur()
La première ligne se connectera à un serveur (dans ce cas, je me connecte à ma machine locale) en utilisant vos identifiants (remplacez
connection =mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Je me suis intentionnellement connecté uniquement à un serveur et non à une base de données spécifique car je vais utiliser deux bases de données situées sur le même serveur.
La commande suivante - print – est ici juste une notification que nous avons été connectés avec succès. Bien qu'il n'ait aucune signification de programmation, il pourrait être utilisé pour déboguer le code en cas de problème dans le script.
La dernière ligne de cette partie est :
curseur =connection.cursor()
Les curseurs sont la structure de gestionnaire utilisée pour travailler avec les données. Nous les utiliserons pour récupérer des données de la base de données (SELECT), mais aussi pour modifier les données (INSERT, UPDATE, DELETE). Avant d'utiliser un curseur, nous devons le créer. Et c'est ce que fait cette ligne.
Procédures d'appel
La partie précédente était générale et pouvait être utilisée pour d'autres tâches liées à la base de données. La partie suivante du code est spécifiquement pour ETL :appeler nos procédures stockées avec le cursor.callproc commande. Il ressemble à ceci :
# 1. mettre à jour les dimensionscursor.callproc('subscription_dwh.p_update_dimensions')print('Tables de dimension mises à jour.')# 2. mettre à jour les faitscursor.callproc('subscription_dwh.p_update_facts')print('Tables de faits mises à jour.') Les procédures d'appel sont assez explicites. Après chaque appel, une commande d'impression était ajoutée. Encore une fois, cela nous donne juste une notification que tout s'est bien passé.
Valider et fermer
La dernière partie du script valide les modifications de la base de données et ferme tous les objets utilisés :
# commit &close connectioncursor.close()connection.commit()connection.close()print('Disconnected from database.') Les procédures d'appel sont assez explicites. Après chaque appel, une commande d'impression était ajoutée. Encore une fois, cela nous donne juste une notification que tout s'est bien passé.
L'engagement est essentiel ici; sans cela, aucune modification ne sera apportée à la base de données, même si vous avez appelé une procédure ou exécuté une instruction SQL.
Exécuter le script
La dernière chose que nous devons faire est d'exécuter notre script. Nous utiliserons les commandes suivantes dans Python Shell pour y parvenir :
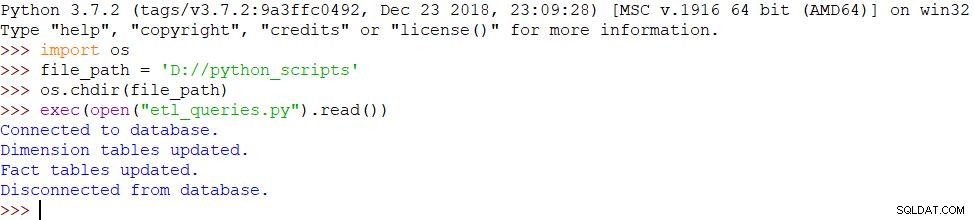
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())
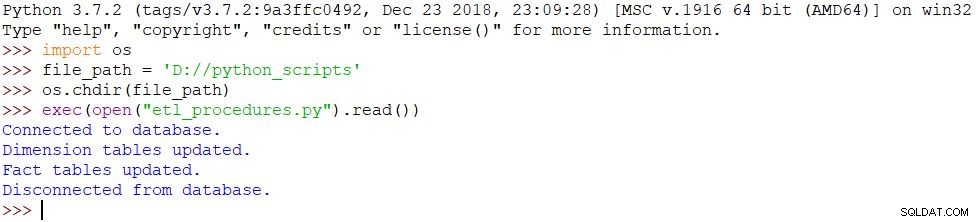
Le script est exécuté et toutes les modifications sont apportées à la base de données en conséquence. Le résultat peut être vu dans l'image ci-dessous.
Méthode 2 :ETL avec Python et MySQL
L'approche présentée ci-dessus ne diffère pas beaucoup de l'approche consistant à appeler des procédures stockées directement dans MySQL. La seule différence est que nous avons maintenant un script qui fera tout le travail pour nous.
Nous pourrions utiliser une autre approche :mettre tout dans le script Python. Nous inclurons des instructions Python, mais nous préparerons également des requêtes SQL et les exécuterons sur la base de données. La base de données source (live) et la base de données de destination (DWH) sont les mêmes que dans l'exemple avec les procédures stockées.
Avant d'approfondir cela, examinons le script complet (etl_queries.py ):
from datetime import date# import MySQL connectorimport mysql.connector# connect to serverconnection =mysql.connector.connect(user='', password='', host='127.0.0.1')print ('Connecté à la base de données.')# 1. mettre à jour les dimensions# 1.1 mettre à jour dim_time# date - hierhier =date.fromordinal(date.today().toordinal()-1)yesterday_str ='"' + str(hier) + ' "'# teste si la date est déjà dans la tablecursor =connection.cursor()query =( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date =" + hier_str)cursor.execute(query)result =curseur .fetchall()yesterday_subscription_count =int(result[0][0])if hier_subscription_count ==0 :hier_année ='ANNEE("' + str(hier) + '")' hier_mois ='MOIS("' + str(hier) ) + '")' hier_semaine ='WEEK("' + str(hier) + '")' hier_semaine ='WEEKDAY("' + str(hier) + '")' query =( "INSERT INTO subscription_dwh.`dim_time `(`heure_date`, `heure_année`, `heure_mois`, `heure_semaine` , `time_weekday`, `ts`) " " VALEURS (" + hier_str + ", " + hier_année + ", " + hier_mois + ", " + hier_semaine + ", " + hier_semaine + ", Maintenant())") curseur .execute(query)# 1.2 update dim_cityquery =( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name , Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id =country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh. postal_code AND country_live.country_name =city_dwh.country_name " "WHERE city_dwh.id IS NULL")cursor.execute(query)print('Dimension tables updated.')# 2. mettre à jour les faits# 2.1 mettre à jour les clients abonnés# supprimer les anciennes données pour le même datequery =( "SUPPRIMER subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fa ct_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` =subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` =" + hier_str)curseur. execute(query)# insert new dataquery =( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active =1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active =0 THEN 1 ELSE 0 END) AS total_inactive, SUM( CASE WHEN customer_live.active =1 AND DATE(customer_live.time_updated) =@time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active =0 AND DATE(customer_live.time_updated) =@time_date THEN 1 ELSE 0 END) ) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscri ption_live.`city` city_live ON customer_live.city_id =city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id =country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live .postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date =" + hier_str + " " "GROUP BY city_dwh.id, time_dwh.id")cursor.execute(query )# 2.2 update subscription statuses# delete old data for the same datequery =( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.` dim_time_id` =subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` =" + hier_str)cursor.execute(query)# insert new dataquery =( "INSERT INTO subscription_dwh.`fact _subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active =1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active =0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active =1 AND DATE(subscription_live.time_updated) =@ time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active =0 AND DATE(subscription_live.time_updated) =@time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live .`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id =customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id =city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id =country_live.id " "INTÉRIEUR JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " " INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date =" + hier_str + " " " GROUPE BY city_dwh.id, time_dwh.id")cursor.execute(query)print('Tables de faits mises à jour.')# commit &close connectioncursor.close()connection.commit()connection.close()print('Déconnecté de la base de données .')
etl_queries.py
Importer des modules et se connecter à la base de données
Encore une fois, nous devrons importer MySQL en utilisant le code suivant :
importer mysql.connector
Nous allons également importer le module datetime, comme indiqué ci-dessous. Nous en avons besoin pour les opérations liées à la date en Python :
à partir de la date d'importation datetime
Le processus de connexion à la base de données est le même que dans l'exemple précédent.
Mettre à jour la dimension dim_time
Pour mettre à jour le dim_time table, nous devrons vérifier si la valeur (pour hier) est déjà dans la table. Nous devrons utiliser les fonctions de date de Python (au lieu de celles de SQL) pour ce faire :
# date - hierhier =date.fromordinal(date.today().toordinal()-1)yesterday_str ='"' + str(hier) + '"'
La première ligne de code renverra la date d'hier dans la variable de date, tandis que la deuxième ligne stockera cette valeur sous forme de chaîne. Nous en aurons besoin en tant que chaîne car nous la concatènerons avec une autre chaîne lorsque nous créerons la requête SQL.
Ensuite, nous devrons tester si cette date est déjà dans le dim_time table. Après avoir déclaré un curseur, nous allons préparer la requête SQL. Pour exécuter la requête, nous utiliserons le cursor.execute commande :
# teste si la date est déjà dans la tablecursor =connection.cursor()query =( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date =" + hier_str)cursor.execute(query)'" '
Nous stockerons le résultat de la requête dans le résultat variable. Le résultat aura 0 ou 1 lignes, nous pouvons donc tester la première colonne de la première ligne. Il contiendra un 0 ou un 1. (N'oubliez pas que nous ne pouvons avoir la même date qu'une seule fois dans une table de dimension.)
Si la date n'est pas déjà dans le tableau, nous préparerons les chaînes qui feront partie de la requête SQL :
result =cursor.fetchall() yesterday_subscription_count =int(result[0][0])if hier_subscription_count ==0 :hier_année ='ANNEE("' + str(hier) + '")' hier_mois ='MOIS( "' + str(hier) + '")' hier_semaine ='WEEK("' + str(hier) + '")' hier_semaine ='WEEKDAY("' + str(hier) + '")' Enfin, nous allons créer une requête et l'exécuter. Cela mettra à jour le dim_time table après sa validation. Veuillez noter que j'ai utilisé le chemin complet vers la table, y compris le nom de la base de données (subscription_dwh ).
query =( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALEURS (" + hier_str + ", " + hier_année + ", " + hier_mois + ", " + hier_semaine + ", " + hier_semaine + ", Maintenant())") curseur.execute(requête) Mettre à jour la dimension dim_city
Mise à jour de dim_city tableau est encore plus simple car nous n'avons pas besoin de tester quoi que ce soit avant l'insertion. Nous allons en fait inclure ce test dans la requête SQL.
# 1.2 update dim_cityquery =( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now () " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id =country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "WHERE city_dwh.id IS NULL")cursor.execute(query)
Ici, nous préparons et exécutons la requête SQL. Notez que j'ai de nouveau utilisé les chemins d'accès complets aux tables, y compris les noms des deux bases de données (subscription_live et subscription_dwh ).
Mise à jour des tableaux de faits
La dernière chose que nous devons faire est de mettre à jour nos tables de faits. Le processus est presque identique à la mise à jour des tables de dimension :nous préparons les requêtes et les exécutons. Ces requêtes sont beaucoup plus complexes, mais ce sont les mêmes que celles utilisées dans les procédures stockées.
Nous avons ajouté une amélioration par rapport aux procédures stockées :supprimer les données existantes pour la même date dans la table de faits. Cela nous permettra d'exécuter un script plusieurs fois pour la même date. À la fin, nous devrons valider la transaction et fermer tous les objets et la connexion.
Exécuter le script
Nous avons un changement mineur dans cette partie, qui appelle un script différent :
- import os- file_path ='D://python_scripts'- os.chdir(file_path)- exec(open("etl_queries.py").read())
Comme nous avons utilisé les mêmes messages et que le script s'est terminé avec succès, le résultat est le même :
Comment utiliseriez-vous Python dans ETL ?
Aujourd'hui, nous avons vu un exemple d'exécution du processus ETL avec un script Python. Il existe d'autres moyens de le faire, par ex. un certain nombre de solutions open source qui utilisent des bibliothèques Python pour travailler avec des bases de données et effectuer le processus ETL. Dans le prochain article, nous jouerons avec l'un d'entre eux. En attendant, n'hésitez pas à partager votre expérience avec Python et ETL.