Un aperçu de la récupération traditionnelle
Comme avec tous les systèmes de bases de données relationnelles, SQL Server garantit la pérennité des données en implémentant la reprise sur incident. La durabilité dans l'acronyme ACID qui fait référence aux caractéristiques des transactions dans les bases de données relationnelles signifie que nous pouvons être assurés que si la base de données tombe en panne soudainement, nos données sont en sécurité.
SQL Server implémente cette fonctionnalité à l'aide du journal des transactions. Les modifications apportées par toutes les opérations de manipulation de données dans SQL Server sont capturées dans le journal des transactions avant d'être appliquées aux fichiers de données (via le processus de point de contrôle) au cas où il serait nécessaire de revenir en arrière ou de progresser.
Le processus de récupération après incident en trois phases dans SQL Server est le suivant :
Analyse – SQL Server lit le journal des transactions du dernier point de contrôle à la fin du journal des transactions
Rétablir – SQL Server rejoue le journal depuis la transaction non validée la plus ancienne jusqu'à la fin du journal
Annuler – SQL Server lit le journal depuis la fin du journal jusqu'à la transaction non validée la plus ancienne et annule toutes les transactions qui étaient actives pendant le crash
Les administrateurs de base de données expérimentés auraient, à un moment ou à un autre de leur carrière, eu l'expérience décourageante d'attendre, impuissants, que la récupération sur incident soit terminée sur une très grande base de données. La transaction ROLLBACK utilise un mécanisme similaire au processus de récupération après incident. Microsoft a considérablement amélioré le processus de récupération dans SQL Server 2019.
Récupération accélérée de la base de données
Accelerated Database Recovery est une nouvelle fonctionnalité basée sur la gestion des versions qui augmente considérablement le taux de récupération en cas de ROLLBACK ou de récupération après un crash.
Dans SQL Server 2019, trois nouveaux mécanismes au sein du moteur SQL Server modifient la manière dont la récupération est gérée et réduisent efficacement le temps nécessaire pour effectuer une restauration/rollforward.
Magasin de versions persistantes (PVS) – Capture les versions de ligne dans la base de données en question. Le magasin de versions persistantes peut être défini dans un groupe de fichiers séparé pour des raisons de performances ou de taille
Retour logique - Utilise les versions de ligne stockées dans PVS pour effectuer une restauration lorsqu'une restauration est invoquée pour une transaction particulière ou lorsque la phase d'annulation de la récupération après incident est invoquée.
sLog – Cela signifie peut-être secondaire journal . Il s'agit d'un flux de journal en mémoire utilisé pour capturer les opérations qui ne peuvent pas être versionnées. Lorsque l'ADR est activé dans la base de données, le sLog est toujours reconstruit pendant la phase d'analyse de la reprise sur incident. Pendant la refaire phase, le sLog est utilisé plutôt que le journal des transactions réel, ce qui accélère le processus car il se trouve en mémoire et contient moins de transactions. Le processus de récupération traditionnel gère les transactions à partir du dernier point de contrôle. Le sLog est également utilisé lors de l'annulation étape.
Nettoyant – Supprime les versions de ligne inutiles du PVS. Microsoft fournit également une procédure stockée pour forcer manuellement un nettoyage des versions de lignes inutiles.
-- LISTING 1: INVOKE THE BACKGROUND CLEANER USE TSQLV4_ADR GO EXECUTE sys.sp_persistent_version_cleanup; USE master GO EXECUTE master.sys.sp_persistent_version_cleanup 'TSQLV4_ADR';
La récupération accélérée de la base de données est désactivée par défaut
Le fait que l'ADR soit désactivé par défaut dans SQL Server 2019 peut sembler surprenant pour certains administrateurs de base de données étant donné qu'il semble être une fonctionnalité si intéressante. ADR utilise la gestion des versions dans la base de données utilisateur dans laquelle il est activé. Cela peut avoir un impact significatif sur la taille de la base de données. En outre, vous devrez peut-être planifier la croissance de la base de données ainsi que l'emplacement possible du PVS afin d'assurer de bonnes performances si ADR est activé. Il est donc logique d'activer délibérément cette fonctionnalité.
L'expérience :phase préparatoire
Nous avons mis en place une expérience pour explorer la nouvelle fonctionnalité et voir l'impact de l'ADR sur la taille du journal des transactions ainsi que sur la vitesse de ROLLBACK. Dans notre expérience, nous créons deux bases de données identiques à l'aide d'un seul jeu de sauvegarde, puis nous n'activons l'ADR que sur l'une de ces bases de données. Le Listing 2 montre les étapes préparatoires de la tâche.
[expand title =”Code”]
-- LISTING 2: PREPARE THE DATABASES AND CONFIGURE ADR
-- 2a. Backup a sample database and restore as two identical databases
BACKUP DATABASE TSQLV4 TO DISK='TSQLV4.BAK' WITH COMPRESSION;
-- Restore Database TSQLV4_NOADR (ADR will not be enabled)
RESTORE DATABASE TSQLV4_NOADR FROM DISK='TSQLV4.BAK' WITH
MOVE 'TSQLV4' TO 'C:\MSSQL\DATA\TSQLV4_NOADR.MDF',
MOVE 'TSQLV4_log' TO 'E:\MSSQL\LOG\TSQLV4_NOADR_LOG.LDF';
-- Restore Database TSQLV4_ADR (ADR will be enabled)
RESTORE DATABASE TSQLV4_ADR FROM DISK='TSQLV4.BAK' WITH
MOVE 'TSQLV4' TO 'C:\MSSQL\DATA\TSQLV4_ADR.MDF',
MOVE 'TSQLV4_log' TO 'E:\MSSQL\LOG\TSQLV4_ADR_LOG.LDF';
-- 2b. Enable ADR in TSQLV4_ADR
USE [master]
GO
-- First create a separate filegroup and add a file to the filegroup
ALTER DATABASE [TSQLV4_ADR] ADD FILEGROUP [ADR_FG];
ALTER DATABASE [TSQLV4_ADR] ADD FILE ( NAME = N'TSQLV4_ADR01', FILENAME = N'C:\MSSQL\Data\TSQLV4_ADR01.ndf' ,
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [ADR_FG]
GO
-- Enable ADR
ALTER DATABASE TSQLV4_ADR SET ACCELERATED_DATABASE_RECOVERY = ON (PERSISTENT_VERSION_STORE_FILEGROUP = ADR_FG);
GO
-- 2c. Check if all ADR is enabled as planned
SELECT name
, compatibility_level
, snapshot_isolation_state_desc
, recovery_model_desc
, target_recovery_time_in_seconds
, is_accelerated_database_recovery_on FROM SYS.DATABASES
WHERE name LIKE 'TSQLV4_%';
-- 2d. Check sizes of all files in the databases
SELECT DB_NAME(database_id) AS database_name
, name AS file_name
, physical_name
, (size * 8)/1024 AS [size (MB)]
, type_desc
FROM SYS.master_files
WHERE DB_NAME(database_id) LIKE 'TSQLV4_%';
-- 2e. Check size of log used
CREATE TABLE ##LogSpaceUsage (database_name VARCHAR(50)
, database_id INT, total_log_size_in_bytes BIGINT
, used_log_space_in_bytes BIGINT
, used_log_space_in_percent BIGINT
, log_space_in_bytes_since_last_backup BIGINT)
INSERT INTO ##LogSpaceUsage
EXEC sp_MSforeachdb @command1='
IF ''?'' LIKE ("TSQLV4_%")
SELECT DB_NAME(database_id), * FROM ?.SYS.dm_db_log_space_usage;'
SELECT * FROM ##LogSpaceUsage;
DROP TABLE ##LogSpaceUsage; [/expand]
La figure 1 montre la sortie de l'instruction SQL dans le Listing 2 section 2c. Nous avons également capturé la taille des fichiers de base de données et l'utilisation du fichier journal des transactions. (voir figure 3).
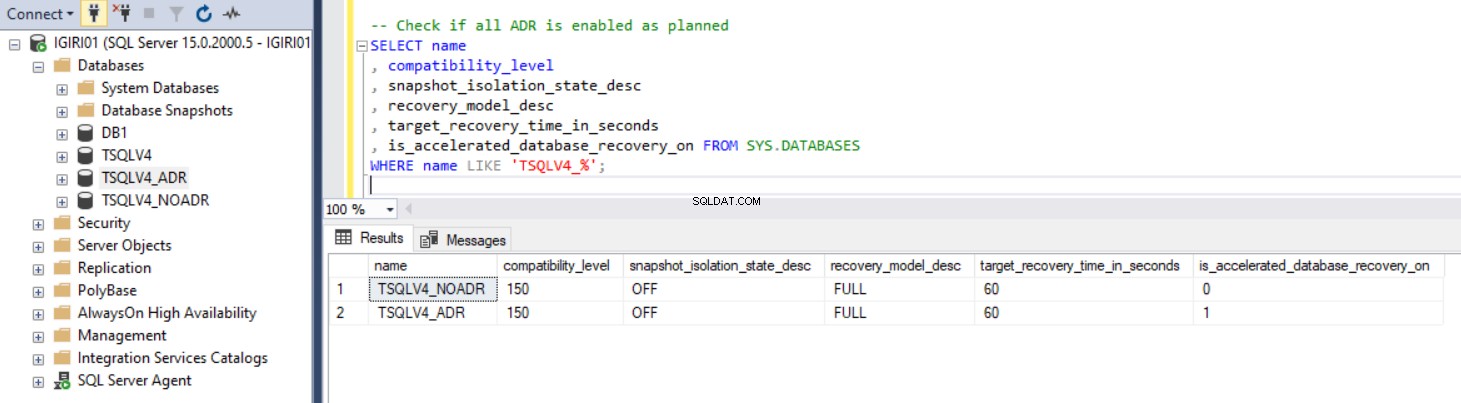
Fig. 1 Confirmer que l'ADR est configuré
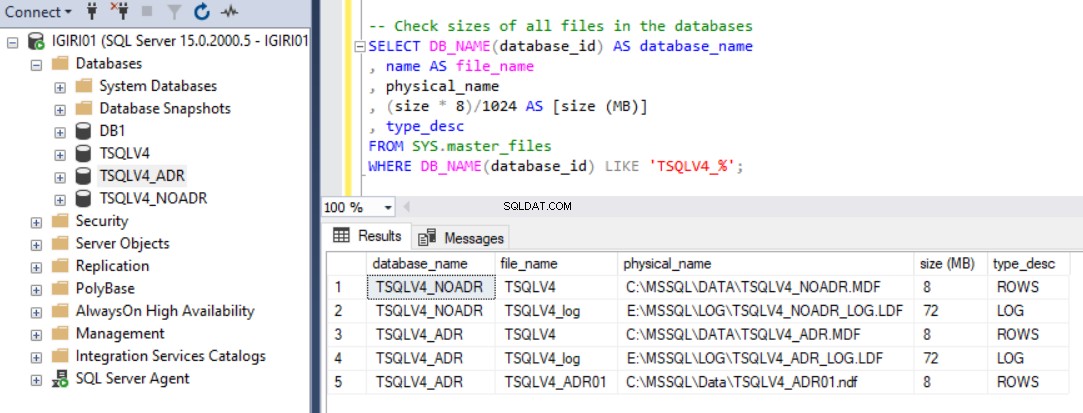
Fig. 2 Examiner la taille des fichiers de données de la base de données
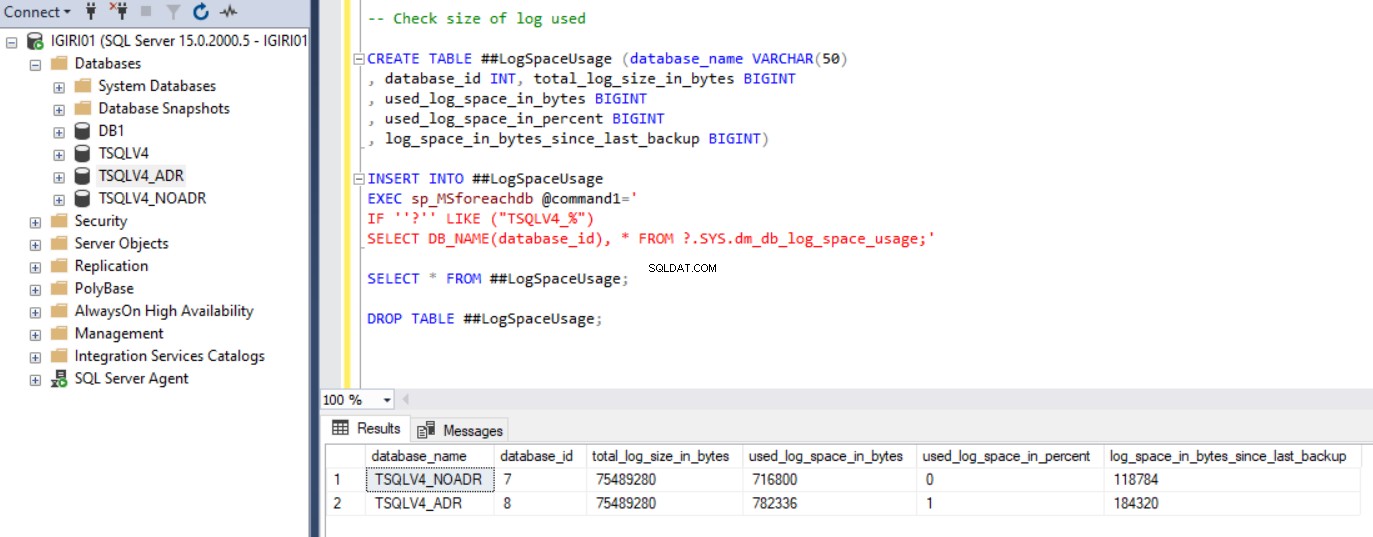
Fig. 3 Vérifiez la taille du journal utilisé pour les deux bases de données
L'expérience :phase d'exécution
Une fois que nous avons capturé les détails dont nous avons besoin pour continuer, nous exécutons ensuite le code SQL des listes 3 et 4 par étapes. Les deux listes sont équivalentes, mais nous les exécutons séparément sur deux bases de données identiques. Tout d'abord, nous faisons un INSERT (Listing 3, 3a), puis nous effectuons un DELETE (Listing 3, 3b) que nous allons ensuite annuler. Notez que dans INSERT et DELETE, nous avons encapsulé les opérations dans des transactions. Notez également que l'INSERT est exécuté 50 fois. À chaque étape de l'exécution, c'est-à-dire entre 3a, 3b et 3c, nous capturons l'utilisation du journal des transactions à l'aide du code du Listing 2,2e. Il en va de même pour les sections 4a, 4b et 4c.
-- LISTING 3: EXECUTE DML IN TSQLV4_NOADR DATABASE -- 3a. Execute INSERT Statement in TSQLV4_NOADR Database USE TSQLV4_NOADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT * INTO [Sales].[OrderDetails_noadr] FROM [Sales].[OrderDetails]; GO INSERT INTO [Sales].[OrderDetails_noadr] SELECT * FROM [Sales].[OrderDetails]; GO 50 COMMIT; -- 3b. Execute DELETE in TSQLV4_NOADR Database USE TSQLV4_NOADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; DELETE FROM [Sales].[OrderDetails_noadr] GO -- 3c. Perform Rollback and Capture Time ROLLBACK;
Fig. 4 et 5 nous montrent que l'opération SELECT INTO a pris 6 millisecondes de plus dans la base de données TSQLV4_ADR où nous avons activé la récupération accélérée de la base de données. Nous voyons également dans la Fig. 6 que nous avons une plus grande utilisation du journal des transactions dans la base de données TSQLV4_ADR. J'ai été particulièrement surpris de cela, alors j'ai répété l'expérience plusieurs fois pour m'assurer que j'obtenais ce résultat de manière cohérente.
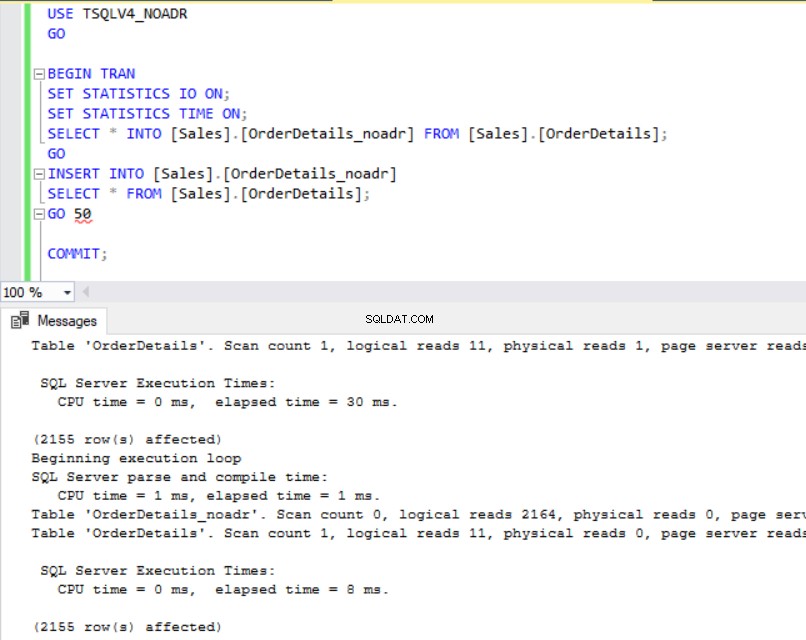
Fig. 4 Insérer le temps d'exécution pour TSQLV4_NOADR
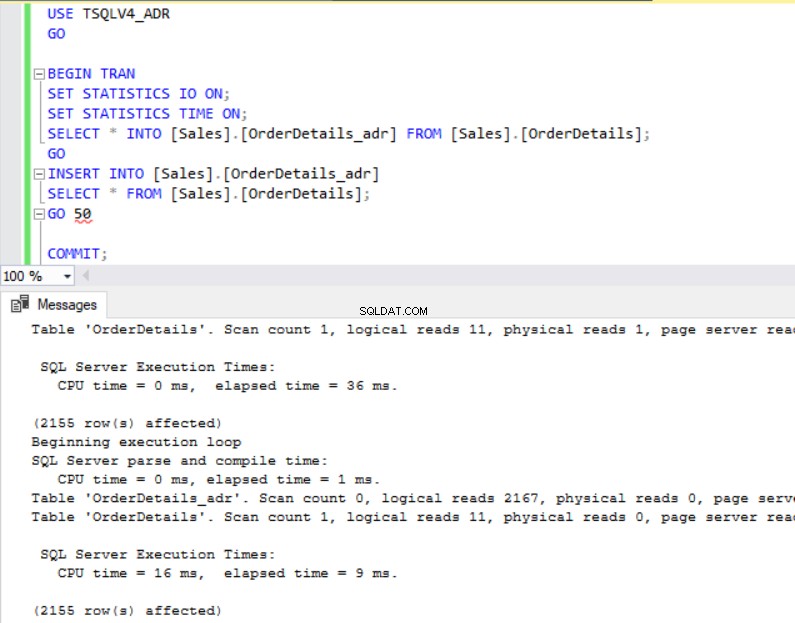
Fig. 5 Insérer le temps d'exécution pour TSQLV4_ADR
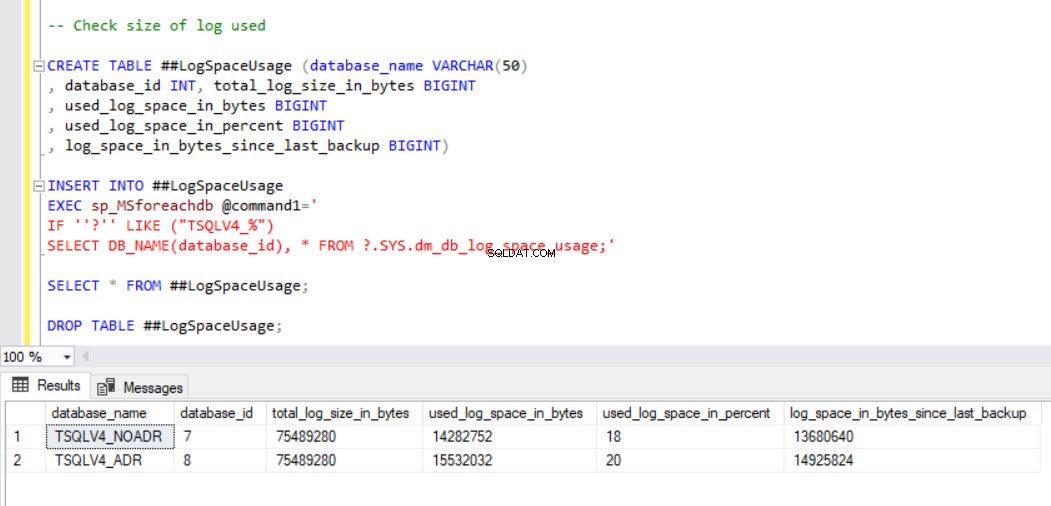
Fig. 6 Utilisation du journal des transactions après les insertions
-- LISTING 4: EXECUTE DML IN TSQLV4_ADR DATABASE -- 4a. Execute INSERT Statement in TSQLV4_ADR Database USE TSQLV4_ADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT * INTO [Sales].[OrderDetails_adr] FROM [Sales].[OrderDetails]; GO INSERT INTO [Sales].[OrderDetails_adr] SELECT * FROM [Sales].[OrderDetails]; GO 50 COMMIT; -- 4b. Execute DELETE in TSQLV4_ADR Database USE TSQLV4_ADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; DELETE FROM [Sales].[OrderDetails_adr] GO -- 4c. Perform Rollback and Capture Time ROLLBACK;
Fig. 7 et 8 nous montrent que l'opération DELETE a mis beaucoup plus de temps à se terminer dans la base de données TSQLV4_ADR où nous avons activé la récupération accélérée de la base de données même si le même nombre de lignes a été supprimé dans les deux bases de données. Cette fois-ci, cependant, nous avons une plus grande utilisation du journal des transactions dans la base de données TSQLV4_NOADR.
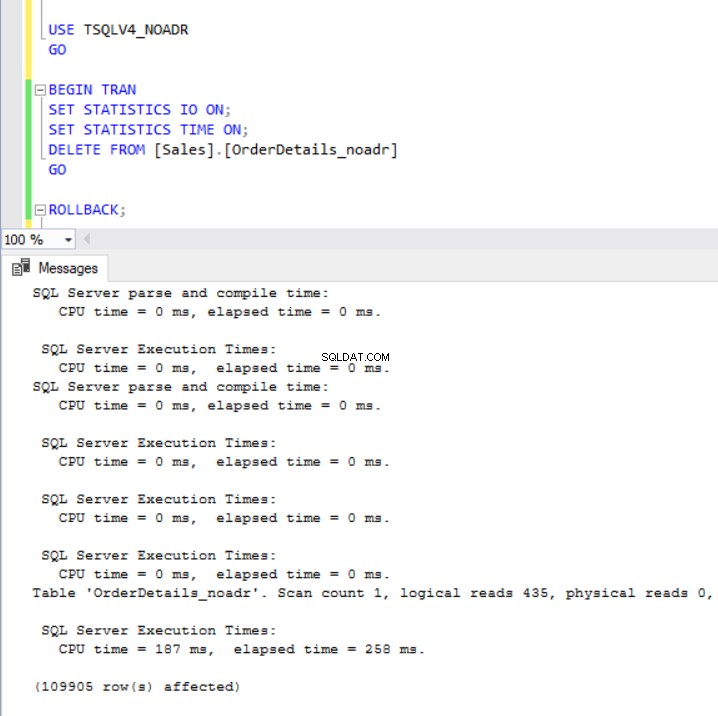
Fig. 7 Supprimer le temps d'exécution pour TSQLV4_NOADR
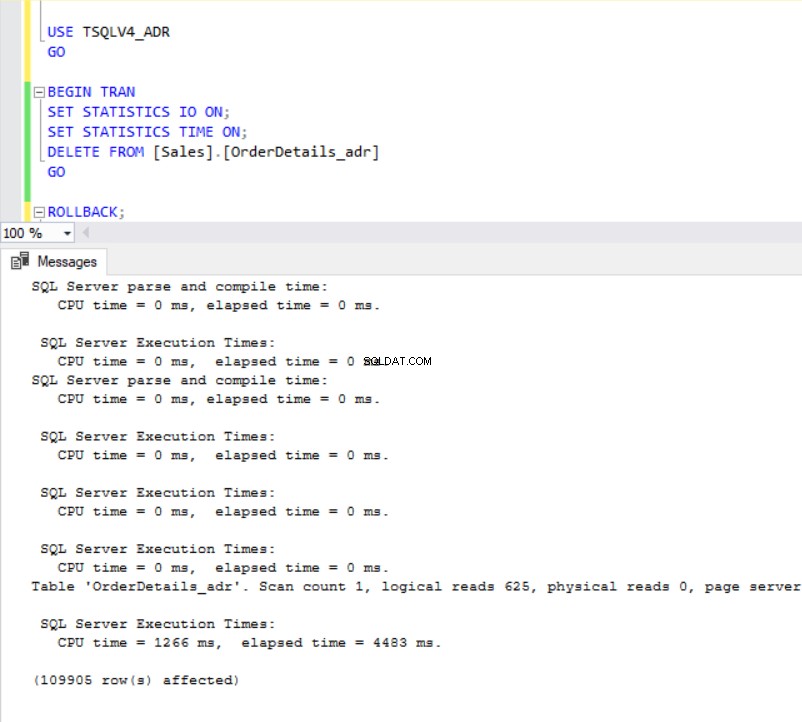
Fig. 8 Supprimer le temps d'exécution pour TSQLV4_ADR
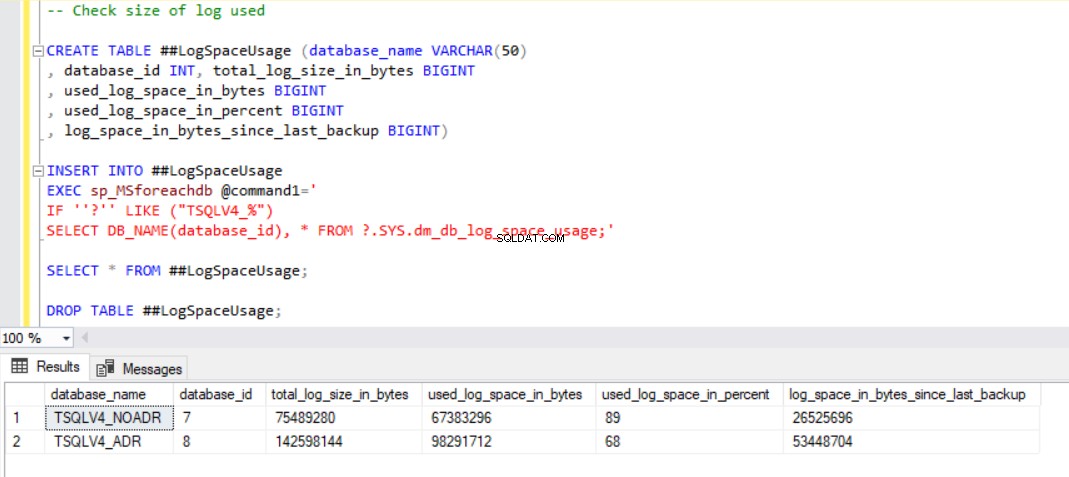
Fig. 9 Utilisation du journal des transactions après les suppressions
À présent, il devenait évident que les opérations DML prennent plus de temps dans les bases de données avec ADR activé. Cela explique en partie pourquoi la fonctionnalité est désactivée en premier lieu. En y réfléchissant bien, cela a du sens puisque SQL Server doit stocker les versions de ligne dans le PVS pendant qu'une opération d'insertion, de mise à jour ou de suppression est en cours d'exécution. Quel que soit le temps que prend le DML, nous constatons que l'émission d'un ROLLBACK avec ADR activé prend moins de 1 milliseconde (voir Figs. 10 à 13). Dans certains cas, la restauration rapide peut compenser la surcharge du DML lui-même, mais pas dans tous les cas !
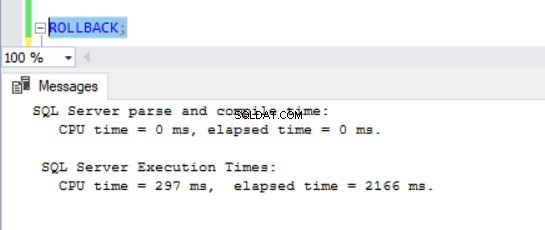
Fig. 10 Temps d'exécution pour ROLLBACK (Après DELETE) sur TSQLV4_NOADR
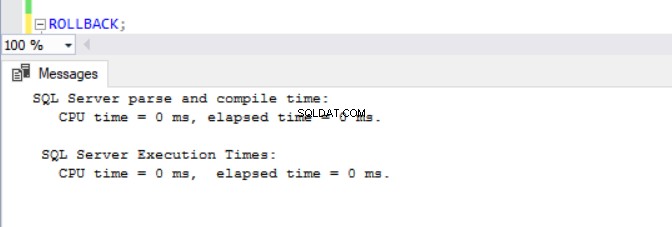
Fig. 11 Temps d'exécution pour ROLLBACK (Après DELETE) sur TSQLV4_ADR
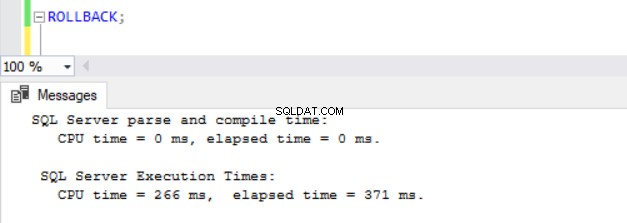
Fig. 12 Temps d'exécution pour ROLLBACK (Après INSERT) sur TSQLV4_NOADR
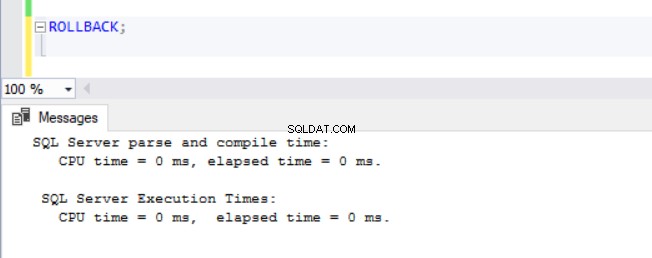
Fig. 13 Temps d'exécution pour ROLLBACK (Après DELETE) sur TSQLV4_ADR
Conclusion
Accelerated Database Recovery est l'une des grandes fonctionnalités publiées dans SQL Server 2019. Cependant, comme pour toutes les choses extrêmement agréables dans la vie, quelqu'un doit payer pour cela. L'ADR peut avoir un impact négatif sur les performances dans certains scénarios. Il est donc important d'évaluer attentivement votre scénario avant d'implémenter l'ADR dans votre base de données de production. Microsoft recommande spécifiquement la récupération de base de données accélérée pour les bases de données prenant en charge des charges de travail avec des transactions de très longue durée, une croissance excessive du journal des transactions ou des pannes fréquentes liées à une récupération de longue durée.
Références
Récupération accélérée de la base de données
Comment fonctionne la récupération de base de données accélérée ?
Récupération accélérée de la base de données