SQLAlchemy vous aide à travailler avec des bases de données en Python. Dans cet article, nous vous disons tout ce que vous devez savoir pour démarrer avec ce module.
Dans l'article précédent, nous avons expliqué comment utiliser Python dans le processus ETL. Nous nous sommes concentrés sur l'exécution du travail en exécutant des procédures stockées et des requêtes SQL. Dans cet article et le suivant, nous utiliserons une approche différente. Au lieu d'écrire du code SQL, nous utiliserons la boîte à outils SQLAlchemy. Vous pouvez également utiliser cet article séparément, comme introduction rapide à l'installation et à l'utilisation de SQLAlchemy.
Prêt? Commençons.
Qu'est-ce que SQLAlchemy ?
Python est bien connu pour son nombre et sa variété de modules. Ces modules réduisent considérablement notre temps de codage car ils implémentent des routines nécessaires pour accomplir une tâche spécifique. Un certain nombre de modules qui fonctionnent avec des données sont disponibles, y compris SQLAlchemy.
Pour décrire SQLAlchemy, j'utiliserai une citation de SQLAlchemy.org :
SQLAlchemy est la boîte à outils Python SQL et Object Relational Mapper qui offre aux développeurs d'applications toute la puissance et la flexibilité de SQL.
Il fournit une suite complète d'outils bien connus de persistance au niveau de l'entreprise modèles, conçus pour un accès efficace et performant aux bases de données, adaptés dans un langage de domaine simple et Pythonic.
La partie la plus importante ici concerne l'ORM (object-relational mapper), qui nous aide à traiter les objets de base de données comme des objets Python plutôt que comme des listes.
Avant d'aller plus loin avec SQLAlchemy, faisons une pause et parlons des ORM.
Les avantages et les inconvénients de l'utilisation des ORM
Par rapport au SQL brut, les ORM ont leurs avantages et leurs inconvénients, et la plupart s'appliquent également à SQLAlchemy.
Les bonnes choses :
- Portabilité du code. L'ORM prend en charge les différences syntaxiques entre les bases de données.
- Une seule langue est nécessaire pour gérer votre base de données. Bien que, pour être honnête, cela ne devrait pas être la principale motivation pour utiliser un ORM.
- Les ORM simplifient votre code , par exemple. ils s'occupent des relations et les traitent comme des objets, ce qui est très bien si vous êtes habitué à la POO.
- Vous pouvez manipuler vos données dans le programme .
Malheureusement, tout a un prix. Les moins bonnes choses sur les ORM :
- Dans certains cas, un ORM peut être lent .
- Rédaction de requêtes complexes pourrait devenir encore plus compliqué ou entraîner des requêtes lentes. Mais ce n'est pas le cas lors de l'utilisation de SQLAlchemy.
- Si vous connaissez bien votre SGBD, apprendre à écrire la même chose dans un ORM est une perte de temps.
Maintenant que nous avons traité ce sujet, revenons à SQLAlchemy.
Avant de commencer...
… rappelons-nous le but de cet article. Si vous êtes simplement intéressé par l'installation de SQLAlchemy et avez besoin d'un tutoriel rapide sur la façon d'exécuter des commandes simples, cet article le fera. Cependant, les commandes présentées dans cet article seront utilisées dans le prochain article pour effectuer le processus ETL et remplacer le code SQL (procédures stockées) et Python que nous avons présenté dans les articles précédents.
Bon, maintenant commençons par le début :avec l'installation de SQLAlchemy.
Installer SQLAlchemy
1. Vérifiez si le module est déjà installé
Pour utiliser un module Python, vous devez l'installer (c'est-à-dire s'il n'a pas été installé auparavant). Une façon de vérifier quels modules ont été installés consiste à utiliser cette commande dans Python Shell :
help('modules')
Pour vérifier si un module spécifique est installé, essayez simplement de l'importer. Utilisez ces commandes :
import sqlalchemy sqlalchemy.__version__
Si SQLAlchemy est déjà installé, la première ligne s'exécutera avec succès. import est une commande Python standard utilisée pour importer des modules. Si le module n'est pas installé, Python lancera une erreur - en fait une liste d'erreurs, en texte rouge - que vous ne pouvez pas manquer :)
La deuxième commande renvoie la version actuelle de SQLAlchemy. Le résultat renvoyé est illustré ci-dessous :

Nous aurons également besoin d'un autre module, et c'est PyMySQL . Il s'agit d'une bibliothèque client MySQL légère en Python pur. Ce module prend en charge tout ce dont nous avons besoin pour travailler avec une base de données MySQL, de l'exécution de requêtes simples à des actions de base de données plus complexes. Nous pouvons vérifier s'il existe en utilisant help('modules') , comme décrit précédemment, ou en utilisant les deux instructions suivantes :
import pymysql pymysql.__version__
Bien sûr, ce sont les mêmes commandes que nous avons utilisées pour tester si SQLAlchemy était installé.
Et si SQLAlchemy ou PyMySQL n'est pas déjà installé ?
L'importation de modules précédemment installés n'est pas difficile. Mais que se passe-t-il si les modules dont vous avez besoin ne sont pas déjà installés ?
Certains modules ont un package d'installation, mais la plupart du temps, vous utiliserez la commande pip pour les installer. PIP est un outil Python utilisé pour installer et désinstaller des modules. Le moyen le plus simple d'installer un module (sous Windows) est :
- Utilisez Invite de commandes -> Exécuter -> cmd .
- Positionnez-vous au répertoire Python cd C:\...\Python\Python37\Scripts .
- Exécutez la commande pip
install(dans notre cas, nous exécuteronspip install pyMySQLetpip install sqlAlchemy.
PIP peut également être utilisé pour désinstaller le module existant. Pour ce faire, vous devez utiliser pip uninstall .
2. Connexion à la base de données
Bien qu'il soit essentiel d'installer tout le nécessaire pour utiliser SQLAlchemy, ce n'est pas très intéressant. Cela ne fait pas non plus vraiment partie de ce qui nous intéresse. Nous ne nous sommes même pas connectés aux bases de données que nous souhaitons utiliser. Nous allons résoudre ce problème maintenant :
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
À l'aide du script ci-dessus, nous établirons une connexion à la base de données située sur notre serveur local, le subscription_live base de données.
(Remarque : Remplacez
Passons en revue le script, commande par commande.
import sqlalchemy from sqlalchemy.engine import create_engine
Ces deux lignes importent notre module et le create_engine fonction.
Ensuite, nous établirons une connexion à la base de données située sur notre serveur.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
La fonction create_engine crée le moteur et utilise .connect() , se connecte à la base de données. Le create_engine la fonction utilise ces paramètres :
dialect+driver://username:password@host:port/database
Dans notre cas, le dialecte est mysql , le pilote est pymysql (précédemment installé) et les variables restantes sont spécifiques au serveur et aux bases de données auxquelles nous voulons nous connecter.
(Remarque : Si vous vous connectez localement, utilisez localhost au lieu de votre adresse IP "locale", 127.0.0.1 et le port approprié :3306 .)

Le résultat de la commande print(engine_live.table_names()) est montré dans l'image ci-dessus. Comme prévu, nous avons obtenu la liste de toutes les tables de notre base de données opérationnelle/en direct.
3. Exécution de commandes SQL à l'aide de SQLAlchemy
Dans cette section, nous analyserons les commandes SQL les plus importantes, examinerons la structure des tables et exécuterons les quatre commandes DML :SELECT, INSERT, UPDATE et DELETE.
Nous discuterons séparément des instructions utilisées dans ce script. Veuillez noter que nous avons déjà parcouru la partie connexion de ce script et que nous avons déjà répertorié les noms de table. Il y a des changements mineurs dans cette ligne :
from sqlalchemy import create_engine, select, MetaData, Table, asc
Nous venons d'importer tout ce que nous utiliserons depuis SQLAlchemy.
Tableaux et structure
Nous allons exécuter le script en tapant la commande suivante dans Python Shell :
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Le résultat est le script exécuté. Analysons maintenant le reste du script.
SQLAlchemy importe les informations relatives aux tables, à la structure et aux relations. Pour travailler avec ces informations, il peut être utile de vérifier la liste des tables (et leurs colonnes) dans la base de données :
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Cela renvoie simplement une liste de toutes les tables de la base de données connectée.
Remarque : Le table_names() La méthode renvoie une liste de noms de table pour le moteur donné. Vous pouvez imprimer la liste entière ou la parcourir à l'aide d'une boucle (comme vous pourriez le faire avec n'importe quelle autre liste).
Ensuite, nous renverrons une liste de tous les attributs de la table sélectionnée. La partie pertinente du script et le résultat sont présentés ci-dessous :
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
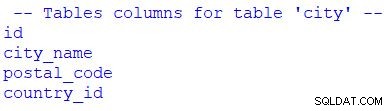
Vous pouvez voir que j'ai utilisé for pour parcourir le jeu de résultats. Nous pourrions remplacer table_city.c avec table_city.columns .
Remarque : Le processus de chargement de la description de la base de données et de création de métadonnées dans SQLAlchemy est appelé réflexion.
Remarque : MetaData est l'objet qui conserve les informations sur les objets de la base de données, de sorte que les tables de la base de données sont également liées à cet objet. En général, cet objet stocke des informations sur l'apparence du schéma de la base de données. Vous l'utiliserez comme point de contact unique lorsque vous souhaitez apporter des modifications ou obtenir des informations sur le schéma de base de données.
Remarque : Les attributs autoload = True et autoload_with = engine_live doit être utilisé pour s'assurer que les attributs de table seront téléchargés (s'ils ne l'ont pas déjà été).
SÉLECTIONNER
Je ne pense pas avoir besoin d'expliquer à quel point l'instruction SELECT est importante :) Alors, disons simplement que vous pouvez utiliser SQLAlchemy pour écrire des instructions SELECT. Si vous êtes habitué à la syntaxe MySQL, il vous faudra un certain temps pour vous adapter; encore, tout est assez logique. Pour le dire aussi simplement que possible, je dirais que l'instruction SELECT est découpée en tranches et que certaines parties sont omises, mais tout est toujours dans le même ordre.
Essayons maintenant quelques instructions SELECT.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Le premier est une instruction SELECT simple renvoyant toutes les valeurs de la table donnée. La syntaxe de cette instruction est très simple :j'ai placé le nom de la table dans le select() . Veuillez noter que j'ai :
- Préparé la déclaration -
stmt = select([table_city]. - Impression de la déclaration en utilisant
print(stmt), ce qui nous donne une bonne idée de l'instruction qui vient d'être exécutée. Cela pourrait également être utilisé pour le débogage. - Impression du résultat avec
print(connection_live.execute(stmt).fetchall()). - Parcourir le résultat en boucle et imprimer chaque enregistrement.
Remarque : Étant donné que nous avons également chargé des contraintes de clé primaire et étrangère dans SQLAlchemy, l'instruction SELECT prend une liste d'objets de table comme arguments et établit automatiquement des relations si nécessaire.
Le résultat est montré dans l'image ci-dessous :

Python récupérera tous les attributs de la table et les stockera dans l'objet. Comme indiqué, nous pouvons utiliser cet objet pour effectuer des opérations supplémentaires. Le résultat final de notre déclaration est une liste de toutes les villes de la city tableau.
Maintenant, nous sommes prêts pour une requête plus complexe. Je viens d'ajouter une clause ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Remarque : Le asc() La méthode effectue un tri croissant par rapport à l'objet parent, en utilisant des colonnes définies comme paramètres.
La liste renvoyée est la même, mais elle est désormais triée par la valeur de l'identifiant, dans l'ordre croissant. Il est important de noter que nous avons simplement ajouté .order_by( à la requête SELECT précédente. Le .order_by(...) La méthode nous permet de modifier l'ordre du jeu de résultats renvoyé, de la même manière que nous l'utiliserions dans une requête SQL. Par conséquent, les paramètres doivent suivre la logique SQL, en utilisant les noms de colonne ou l'ordre des colonnes et ASC ou DESC.
Ensuite, nous allons ajouter WHERE à notre instruction SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Remarque : Le .where() La méthode est utilisée pour tester une condition que nous avons utilisée comme argument. Nous pourrions également utiliser le .filter() méthode, qui filtre mieux les conditions plus complexes.
Une fois de plus, le .where part est simplement concaténée à notre instruction SELECT. Notez que nous avons mis la condition entre parenthèses. Quelle que soit la condition entre parenthèses, elle est testée de la même manière qu'elle le serait dans la partie WHERE d'une instruction SELECT. La condition d'égalité est testée en utilisant ==au lieu de =.
La dernière chose que nous essaierons avec SELECT est de joindre deux tables. Examinons d'abord le code et son résultat.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Il y a deux parties importantes dans la déclaration ci-dessus :
select([table_city.columns.city_name, table_country.columns.country_name])définit les colonnes qui seront renvoyées dans notre résultat..select_from(table_city.join(table_country))définit la condition/table de jointure. Notez que nous n'avons pas eu à écrire la condition de jointure complète, y compris les clés. En effet, SQLAlchemy "sait" comment ces deux tables sont jointes, car les clés primaires et les règles de clés étrangères sont importées en arrière-plan.
INSÉRER / METTRE À JOUR / SUPPRIMER
Ce sont les trois commandes DML restantes que nous aborderons dans cet article. Bien que leur structure puisse devenir très complexe, ces commandes sont généralement beaucoup plus simples. Le code utilisé est présenté ci-dessous.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Le même modèle est utilisé pour les trois instructions :préparer l'instruction, l'imprimer et l'exécuter, et imprimer le résultat après chaque instruction afin que nous puissions voir ce qui s'est réellement passé dans la base de données. Notez une fois de plus que certaines parties de l'instruction ont été traitées comme des objets (.values(), .where()).

Nous utiliserons ces connaissances dans le prochain article pour créer un script ETL complet à l'aide de SQLAlchemy.
Prochaine étape :SQLAlchemy dans le processus ETL
Aujourd'hui, nous avons analysé comment configurer SQLAlchemy et comment exécuter des commandes DML simples. Dans le prochain article, nous utiliserons ces connaissances pour écrire le processus ETL complet à l'aide de SQLAlchemy.
Vous pouvez télécharger le script complet, utilisé dans cet article ici.