Dans le post précédent, nous avons expliqué comment vérifier que la réplication MySQL est en bon état. Nous avons également examiné certains des problèmes typiques. Dans cet article, nous examinerons d'autres problèmes que vous pourriez rencontrer lors de la réplication MySQL.
Entrée manquante ou en double
C'est quelque chose qui ne devrait pas arriver, mais cela arrive très souvent - une situation dans laquelle une instruction SQL exécutée sur le maître réussit mais la même instruction exécutée sur l'un des esclaves échoue. La raison principale est la dérive de l'esclave - quelque chose (généralement des transactions errantes mais aussi d'autres problèmes ou bogues dans la réplication) fait que l'esclave diffère de son maître. Par exemple, une ligne qui existait sur le maître n'existe pas sur un esclave et elle ne peut pas être supprimée ou mise à jour. La fréquence d'apparition de ce problème dépend principalement de vos paramètres de réplication. En bref, MySQL stocke les événements de journal binaire de trois manières. Premièrement, "instruction", signifie que SQL est écrit en texte brut, tout comme il a été exécuté sur un maître. Ce paramètre a la tolérance la plus élevée sur la dérive de l'esclave mais c'est aussi celui qui ne peut pas garantir la cohérence de l'esclave - il est difficile de recommander de l'utiliser en production. Le deuxième format, "ligne", stocke le résultat de la requête au lieu de l'instruction de la requête. Par exemple, un événement peut ressembler à ceci :
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Cela signifie que nous mettons à jour une ligne dans la table 'tab' dans le schéma 'test' où la première colonne a une valeur de 2 et la deuxième colonne a une valeur de 5. Nous définissons la première colonne sur 2 (la valeur ne change pas) et la seconde colonne à 4. Comme vous pouvez le voir, il n'y a pas beaucoup de place pour l'interprétation - il est précisément défini quelle ligne est utilisée et comment elle est modifiée. Par conséquent, ce format est idéal pour la cohérence des esclaves mais, comme vous pouvez l'imaginer, il est très vulnérable en matière de dérive des données. C'est toujours la méthode recommandée pour exécuter la réplication MySQL.
Enfin, le troisième, "mixte", fonctionne de manière à ce que les événements qui peuvent être écrits en toute sécurité sous forme d'instructions utilisent le format "instruction". Ceux qui pourraient entraîner une dérive des données utiliseront le format "ligne".
Comment les détectez-vous ?
Comme d'habitude, SHOW SLAVE STATUS nous aidera à identifier le problème.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Comme vous pouvez le voir, les erreurs sont claires et explicites (et elles sont fondamentalement identiques entre MySQL et MariaDB.
Comment résolvez-vous le problème ?
C'est malheureusement la partie complexe. Tout d'abord, vous devez identifier une source de vérité. Quel hôte contient les données correctes ? Maître ou esclave ? Habituellement, vous supposeriez que c'est le maître, mais ne le supposez pas par défaut - enquêtez ! Il se peut qu'après le basculement, une partie de l'application émette encore des écritures sur l'ancien maître, qui agit désormais comme un esclave. Il se peut que read_only n'ait pas été défini correctement sur cet hôte ou que l'application utilise un superutilisateur pour se connecter à la base de données (oui, nous l'avons vu dans des environnements de production). Dans ce cas, l'esclave pourrait être la source de la vérité - au moins dans une certaine mesure.
En fonction des données qui doivent rester et de celles qui doivent disparaître, la meilleure chose à faire serait d'identifier ce qui est nécessaire pour synchroniser la réplication. Tout d'abord, la réplication est interrompue, vous devez donc vous en occuper. Connectez-vous au maître et vérifiez le journal binaire, même celui qui a provoqué l'interruption de la réplication.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Comme vous pouvez le voir, nous manquons un événement :5d1e2227-07c6-11e7-8123-080027495a77:1106672. Vérifions-le dans les journaux binaires du maître :
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Nous pouvons voir qu'il s'agit d'un insert qui définit la première colonne sur 3 et la seconde sur 7. Voyons maintenant à quoi ressemble notre tableau :
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Nous avons maintenant deux options, selon les données qui doivent prévaloir. Si les données correctes sont sur le maître, nous pouvons simplement supprimer la ligne avec id=3 sur l'esclave. Assurez-vous simplement de désactiver la journalisation binaire pour éviter d'introduire des transactions erronées. D'autre part, si nous avons décidé que les données correctes se trouvent sur l'esclave, nous devons exécuter la commande REPLACE sur le maître pour définir la ligne avec id=3 pour corriger le contenu de (3, 10) à partir du courant (3, 7). Sur l'esclave, cependant, nous devrons ignorer le GTID actuel (ou, pour être plus précis, nous devrons créer un événement GTID vide) pour pouvoir redémarrer la réplication.
Supprimer une ligne sur un esclave est simple :
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;L'insertion d'un GTID vide est presque aussi simple :
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Une autre méthode pour résoudre ce problème particulier (tant que nous acceptons le maître comme source de vérité) consiste à utiliser des outils tels que pt-table-checksum et pt-table-sync pour identifier où l'esclave n'est pas cohérent avec son maître et ce qui SQL doit être exécuté sur le maître pour ramener l'esclave en synchronisation. Malheureusement, cette méthode est plutôt lourde - beaucoup de charge est ajoutée au maître et un tas de requêtes sont écrites dans le flux de réplication, ce qui peut affecter le décalage sur les esclaves et les performances générales de la configuration de la réplication. Cela est particulièrement vrai s'il y a un nombre important de lignes qui doivent être synchronisées.
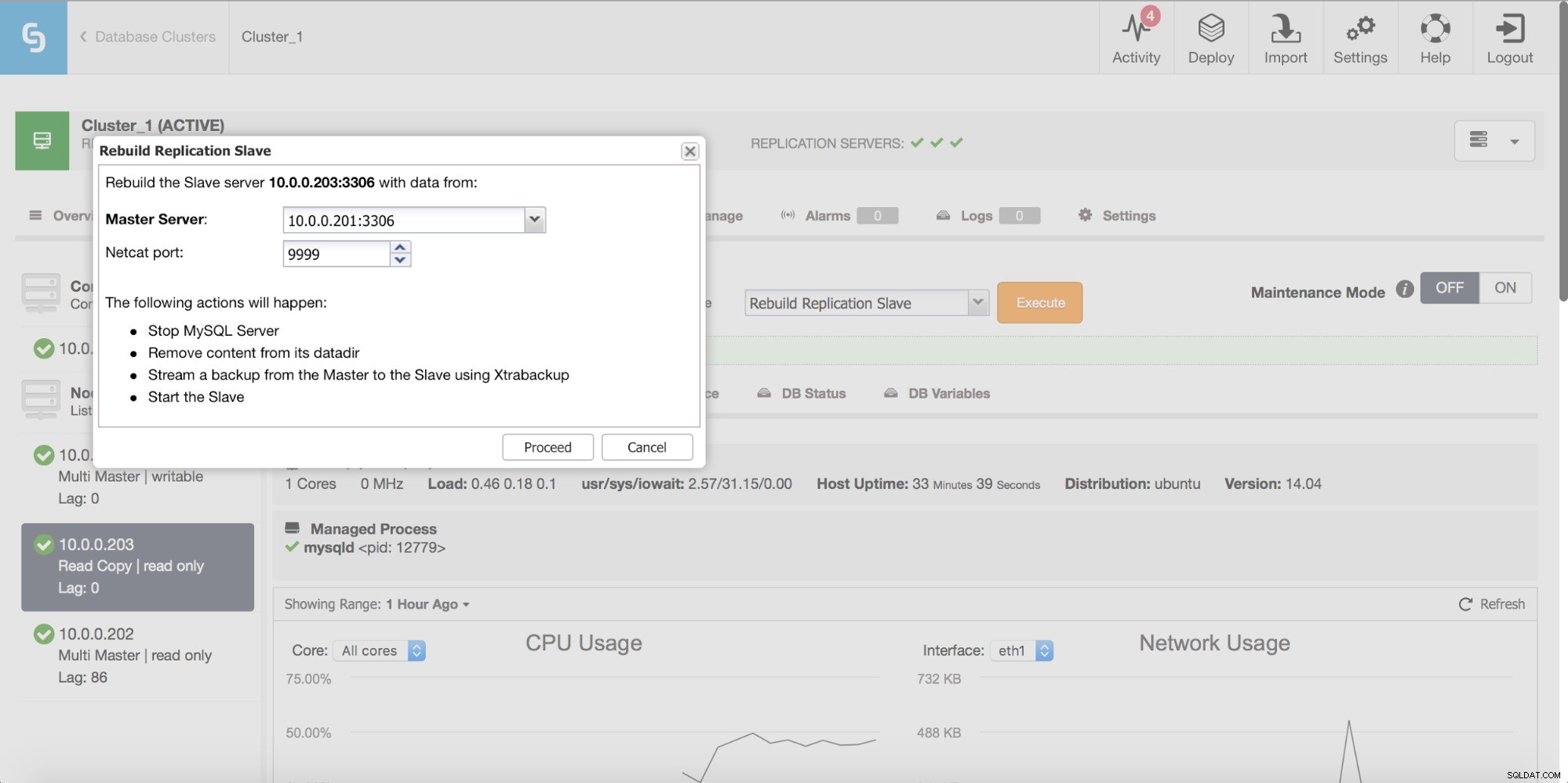
Enfin, comme toujours, vous pouvez reconstruire votre esclave en utilisant les données du maître - de cette façon, vous pouvez être sûr que l'esclave sera rafraîchi avec les données les plus récentes et les plus à jour. Ce n'est en fait pas nécessairement une mauvaise idée - lorsque nous parlons d'un grand nombre de lignes à synchroniser à l'aide de pt-table-checksum/pt-table-sync, cela entraîne une surcharge importante en termes de performances de réplication, de processeur global et d'E/S charge et heures de travail requises.
ClusterControl vous permet de reconstruire un esclave, en utilisant une nouvelle copie des données maître.
Vérifications de cohérence
Comme nous l'avons mentionné dans le chapitre précédent, la cohérence peut devenir un problème sérieux et peut causer beaucoup de maux de tête aux utilisateurs exécutant des configurations de réplication MySQL. Voyons comment vous pouvez vérifier que vos esclaves MySQL sont synchronisés avec le maître et ce que vous pouvez faire à ce sujet.
Comment détecter un esclave incohérent
Malheureusement, la façon typique dont un utilisateur apprend qu'un esclave est incohérent est de se heurter à l'un des problèmes que nous avons mentionnés dans le chapitre précédent. Pour éviter qu'une surveillance proactive de la cohérence des esclaves soit nécessaire. Voyons comment cela peut être fait.
Nous allons utiliser un outil de Percona Toolkit :pt-table-checksum. Il est conçu pour analyser le cluster de réplication et identifier toute anomalie.
Nous avons construit un scénario personnalisé à l'aide de sysbench et nous avons introduit un peu d'incohérence sur l'un des esclaves. Ce qui est important (si vous souhaitez le tester comme nous l'avons fait), vous devez appliquer un correctif ci-dessous pour forcer pt-table-checksum à reconnaître le schéma "sbtest" comme schéma non système :
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Dans un premier temps, nous allons exécuter pt-table-checksum de la manière suivante :
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Quelques notes importantes sur la façon dont nous avons invoqué l'outil. Tout d'abord, l'utilisateur que nous avons défini doit exister sur tous les esclaves. Si vous le souhaitez, vous pouvez également utiliser '--slave-user' pour définir un autre utilisateur moins privilégié pour accéder aux esclaves. Une autre chose mérite d'être expliquée - nous utilisons une réplication basée sur les lignes qui n'est pas entièrement compatible avec pt-table-checksum. Si vous avez une réplication basée sur les lignes, ce qui se passe, c'est que pt-table-checksum changera le format de journal binaire au niveau de la session en "instruction", car c'est le seul format pris en charge. Le problème est qu'un tel changement ne fonctionnera que sur un premier niveau d'esclaves qui sont directement connectés à un maître. Si vous avez des maîtres intermédiaires (donc, plus d'un niveau d'esclaves), l'utilisation de pt-table-checksum peut interrompre la réplication. C'est pourquoi, par défaut, si l'outil détecte une réplication basée sur les lignes, il se ferme et affiche une erreur :
"La réplique slave1 a binlog_format ROW, ce qui pourrait entraîner l'interruption de la réplication par pt-table-checksum. Veuillez lire "Réplicas utilisant la réplication basée sur les lignes" dans la section LIMITATIONS de la documentation de l'outil. Si vous comprenez les risques, spécifiez --no-check-binlog-format pour désactiver cette vérification."
Nous n'avons utilisé qu'un seul niveau d'esclaves, il était donc sûr de spécifier "--no-check-binlog-format" et d'aller de l'avant.
Enfin, nous fixons le décalage maximum à 5 secondes. Si ce seuil est atteint, pt-table-checksum s'arrêtera pendant le temps nécessaire pour ramener le décalage sous le seuil.
Comme vous pouvez le voir sur la sortie,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2une incohérence a été détectée sur la table sbtest.sbtest2.
Par défaut, pt-table-checksum stocke les sommes de contrôle dans la table percona.checksums. Ces données peuvent être utilisées pour un autre outil de Percona Toolkit, pt-table-sync, pour identifier les parties de la table qui doivent être vérifiées en détail pour trouver la différence exacte dans les données.
Comment réparer un esclave incohérent
Comme mentionné ci-dessus, nous utiliserons pt-table-sync pour ce faire. Dans notre cas, nous allons utiliser les données collectées par pt-table-checksum bien qu'il soit également possible de pointer pt-table-sync vers deux hôtes (le maître et un esclave) et il comparera toutes les données sur les deux hôtes. C'est certainement un processus qui prend plus de temps et de ressources. Par conséquent, tant que vous avez déjà des données de pt-table-checksum, il est préférable de l'utiliser. Voici comment nous l'avons exécuté pour tester la sortie :
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Comme vous pouvez le voir, du SQL a été généré. Il est important de noter que la variable --replicate . Ce qui se passe ici, c'est que nous pointons pt-table-sync vers la table générée par pt-table-checksum. Nous le pointons également vers master.
Pour vérifier si SQL a du sens, nous avons utilisé l'option --print. Veuillez noter que le SQL généré n'est valide qu'au moment où il est généré - vous ne pouvez pas vraiment le stocker quelque part, le réviser puis l'exécuter. Tout ce que vous pouvez faire est de vérifier si le SQL a un sens et, immédiatement après, réexécutez l'outil avec l'indicateur --execute :
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeCela devrait remettre l'esclave en synchronisation avec le maître. Nous pouvons le vérifier avec pt-table-checksum :
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Comme vous pouvez le voir, il n'y a plus de différences dans la table sbtest.sbtest2.
Nous espérons que vous avez trouvé cet article de blog informatif et utile. Cliquez ici pour en savoir plus sur la réplication MySQL. Si vous avez des questions ou des suggestions, n'hésitez pas à nous contacter via les commentaires ci-dessous.