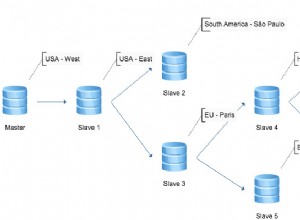
Pendant des années, la réplication MySQL était basée sur des événements de journalisation binaires - tout ce qu'un esclave savait était l'événement exact et la position exacte qu'il venait de lire du maître. Toute transaction unique d'un maître peut s'être terminée dans différents journaux binaires et à différentes positions dans ces journaux. C'était une solution simple qui comportait des limitations - des changements de topologie plus complexes pouvaient nécessiter qu'un administrateur arrête la réplication sur les hôtes concernés. Ou ces changements pourraient causer d'autres problèmes, par exemple, un esclave ne pouvait pas être déplacé vers le bas de la chaîne de réplication sans processus de reconstruction fastidieux (nous ne pouvions pas facilement changer la réplication de A -> B -> C à A -> C -> B sans arrêter la réplication sur B et C). Nous avons tous dû contourner ces limitations tout en rêvant d'un identifiant de transaction global.
GTID a été introduit avec MySQL 5.6 et a apporté des changements majeurs dans le fonctionnement de MySQL. Tout d'abord, chaque transaction possède un identifiant unique qui l'identifie de la même manière sur chaque serveur. Il n'est plus important de savoir dans quelle position de journal binaire une transaction a été enregistrée, tout ce que vous devez savoir est le GTID :'966073f3-b6a4-11e4-af2c-080027880ca6:4'. GTID est construit à partir de deux parties - l'identifiant unique d'un serveur sur lequel une transaction a été exécutée pour la première fois et un numéro de séquence. Dans l'exemple ci-dessus, nous pouvons voir que la transaction a été exécutée par le serveur avec server_uuid de '966073f3-b6a4-11e4-af2c-080027880ca6' et c'est la 4ème transaction exécutée ici. Ces informations sont suffisantes pour effectuer des changements de topologie complexes - MySQL sait quelles transactions ont été exécutées et donc il sait quelles transactions doivent être exécutées ensuite. Oubliez les logs binaires, tout est dans le GTID.
Alors, où pouvez-vous trouver des GTID ? Vous les trouverez à deux endroits. Sur un esclave, dans ‘show slave status;’ vous trouverez deux colonnes :Retrieved_Gtid_Set et Executed_Gtid_Set. Le premier couvre les GTID qui ont été récupérés du maître via la réplication, le second informe sur toutes les transactions qui ont été exécutées sur un hôte donné - à la fois via la réplication ou exécutées localement.
Configurer un cluster de réplication en toute simplicité
Le déploiement du cluster de réplication MySQL est très simple dans ClusterControl (vous pouvez l'essayer gratuitement). La seule condition préalable est que tous les hôtes, que vous utiliserez pour déployer des nœuds MySQL, soient accessibles depuis l'instance ClusterControl à l'aide d'une connexion SSH sans mot de passe.
Lorsque la connectivité est en place, vous pouvez déployer un cluster en utilisant l'option "Déployer". Lorsque la fenêtre de l'assistant est ouverte, vous devez prendre quelques décisions :que voulez-vous faire ? Déployer un nouveau cluster ? Déployez un nœud Postgresql ou importez un cluster existant.
Nous voulons déployer un nouveau cluster. Nous serons alors présentés avec l'écran suivant dans lequel nous devons décider quel type de cluster nous voulons déployer. Choisissons la réplication, puis transmettons les détails requis sur la connectivité ssh.
Lorsque vous êtes prêt, cliquez sur Continuer. Cette fois, nous devons décider quel fournisseur MySQL nous aimerions utiliser, quelle version et quelques paramètres de configuration, y compris, entre autres, le mot de passe pour le compte root dans MySQL.
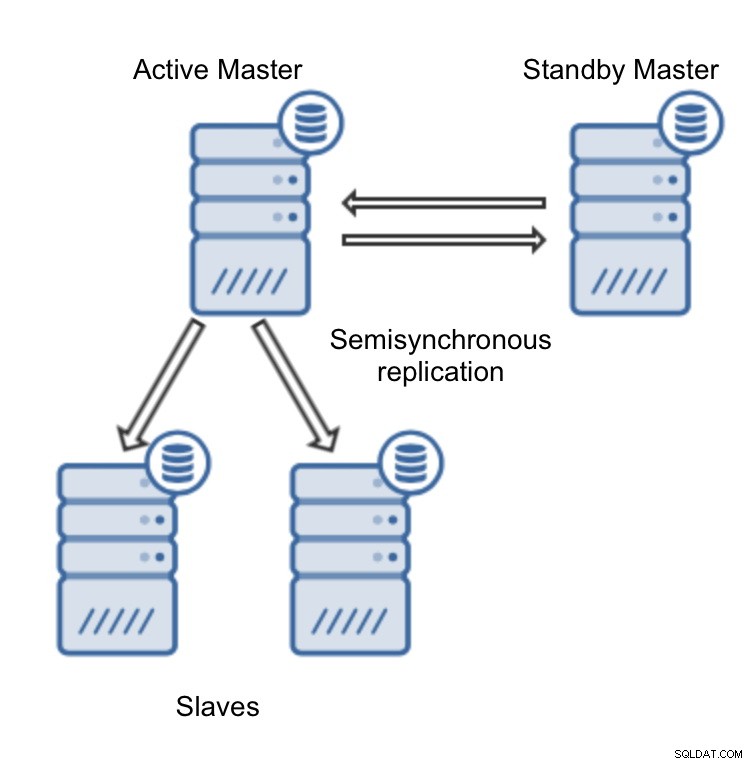
Enfin, nous devons décider de la topologie de réplication - vous pouvez soit utiliser une configuration maître - esclave typique, soit créer une paire plus complexe, active - maître de réserve - maître (+ esclaves si vous souhaitez les ajouter). Une fois prêt, cliquez simplement sur "Déployer" et en quelques minutes, votre cluster devrait être déployé.
Une fois cela fait, vous verrez votre cluster dans la liste des clusters de l'interface utilisateur de ClusterControl.
Une fois la réplication opérationnelle, nous pouvons examiner de plus près le fonctionnement de GTID.
Transactions erronées :quel est le problème ?
Comme nous l'avons mentionné au début de cet article, les GTID ont apporté un changement significatif dans la façon dont les gens devraient penser à la réplication MySQL. Tout est question d'habitudes. Disons, pour une raison quelconque, qu'une application a effectué une écriture sur l'un des esclaves. Cela n'aurait pas dû arriver, mais étonnamment, cela arrive tout le temps. Par conséquent, la réplication s'arrête avec une erreur de clé en double. Il existe deux façons de traiter un tel problème. L'un d'eux consisterait à supprimer la ligne incriminée et à redémarrer la réplication. L'autre consisterait à ignorer l'événement de journalisation binaire, puis à redémarrer la réplication.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Les deux méthodes devraient ramener la réplication au travail, mais elles peuvent introduire une dérive des données, il est donc nécessaire de se rappeler que la cohérence de l'esclave doit être vérifiée après un tel événement (pt-table-checksum et pt-table-sync fonctionnent bien ici).
Si un problème similaire se produit lors de l'utilisation de GTID, vous remarquerez quelques différences. La suppression de la ligne incriminée peut sembler résoudre le problème, la réplication devrait pouvoir commencer. L'autre méthode, utilisant sql_slave_skip_counter ne fonctionnera pas du tout - elle renverra une erreur. N'oubliez pas qu'il ne s'agit plus d'événements binlog, mais de GTID exécuté ou non.
Pourquoi la suppression de la ligne "semble" seulement résoudre le problème ? L'une des choses les plus importantes à garder à l'esprit concernant GTID est qu'un esclave, lors de la connexion au maître, vérifie s'il manque des transactions qui ont été exécutées sur le maître. C'est ce qu'on appelle les transactions errantes. Si un esclave trouve de telles transactions, il les exécutera. Supposons que nous ayons exécuté le code SQL suivant pour effacer une ligne incriminée :
DELETE FROM mytable WHERE id=100;Vérifions afficher le statut de l'esclave :
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,Et voyez d'où vient le 84d15910-b6a4-11e4-af2c-080027880ca6:1 :
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Comme vous pouvez le voir, nous avons 29 transactions provenant du maître, UUID de 966073f3-b6a4-11e4-af2c-080027880ca6 et une qui a été exécutée localement. Disons qu'à un moment donné, nous basculons et que le maître (966073f3-b6a4-11e4-af2c-080027880ca6) devient un esclave. Il vérifiera sa liste de GTID exécutés et ne trouvera pas celui-ci :84d15910-b6a4-11e4-af2c-080027880ca6:1. En conséquence, le SQL associé sera exécuté :
DELETE FROM mytable WHERE id=100;Ce n'est pas quelque chose que nous attendions… Si, entre-temps, le binlog contenant cette transaction était purgé sur l'ancien esclave, alors le nouvel esclave se plaindra après le basculement :
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Comment détecter les transactions erronées ?
MySQL fournit deux fonctions très pratiques lorsque vous souhaitez comparer des ensembles GTID sur différents hôtes.
GTID_SUBSET() prend deux ensembles GTID et vérifie si le premier ensemble est un sous-ensemble du second.
Disons que nous avons l'état suivant.
Maître :
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Esclave :
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Nous pouvons vérifier si l'esclave a des transactions errantes en exécutant le SQL suivant :
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)On dirait qu'il y a des transactions erronées. Comment les identifie-t-on ? Nous pouvons utiliser une autre fonction, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Nos GTID manquants sont ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - ces transactions ont été exécutées sur l'esclave mais pas sur le maître.
Comment résoudre les problèmes causés par des transactions erronées ?
Il existe deux façons :injecter des transactions vides ou exclure des transactions de l'historique GTID.
Pour injecter des transactions vides, nous pouvons utiliser le SQL suivant :
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Cela doit être exécuté sur chaque hôte de la topologie de réplication qui n'a pas ces GTID exécutés. Si le maître est disponible, vous pouvez y injecter ces transactions et les laisser se répliquer dans la chaîne. Si le maître n'est pas disponible (par exemple, il a planté), ces transactions vides doivent être exécutées sur chaque esclave. Oracle a développé un outil appelé mysqlslavetrx qui est conçu pour automatiser ce processus.
Une autre approche consiste à supprimer les GTID de l'historique :
Arrêter l'esclave :
mysql> STOP SLAVE;Imprimer Executed_Gtid_Set sur l'esclave :
mysql> SHOW MASTER STATUS\GRéinitialiser les informations GTID :
RESET MASTER;Définissez GTID_PURGED sur un ensemble GTID correct. basé sur les données de SHOW MASTER STATUS. Vous devez exclure les transactions erronées de l'ensemble.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Démarrer l'esclave.
mysql> START SLAVE\GDans tous les cas, vous devez vérifier la cohérence de vos esclaves à l'aide de pt-table-checksum et pt-table-sync (si nécessaire) - une transaction errante peut entraîner une dérive des données.
Basculement dans ClusterControl
À partir de la version 1.4, ClusterControl a amélioré ses processus de gestion du basculement pour la réplication MySQL. Vous pouvez toujours effectuer une commutation principale manuelle en promouvant l'un des esclaves en maître. Le reste des esclaves basculera alors vers le nouveau maître. À partir de la version 1.4, ClusterControl a également la possibilité d'effectuer un basculement entièrement automatisé en cas de défaillance du maître. Nous l'avons couvert en profondeur dans un article de blog décrivant ClusterControl et le basculement automatisé. Nous aimerions tout de même mentionner une fonctionnalité, directement liée au sujet de cet article.
Par défaut, ClusterControl effectue le basculement de manière "sûre" - au moment du basculement (ou du basculement, si c'est l'utilisateur qui a exécuté un commutateur principal), ClusterControl sélectionne un candidat principal, puis vérifie que ce nœud n'a pas de transactions errantes ce qui aurait un impact sur la réplication une fois promu maître. Si une transaction errante est détectée, ClusterControl arrêtera le processus de basculement et le candidat maître ne sera pas promu pour devenir un nouveau maître.
Si vous voulez être sûr à 100 % que ClusterControl promouvra un nouveau maître même si certains problèmes (comme des transactions errantes) sont détectés, vous pouvez le faire en utilisant le paramètre replication_stop_on_error=0 dans cmon configuration. Bien sûr, comme nous en avons discuté, cela peut entraîner des problèmes de réplication - les esclaves peuvent commencer à demander un événement de journal binaire qui n'est plus disponible.
Pour gérer de tels cas, nous avons ajouté un support expérimental pour la reconstruction des esclaves. Si vous définissez replication_auto_rebuild_slave=1 dans la configuration cmon et que votre esclave est marqué comme arrêté avec l'erreur suivante dans MySQL, ClusterControl tentera de reconstruire l'esclave en utilisant les données du maître :
A obtenu l'erreur fatale 1236 du maître lors de la lecture des données du journal binaire :"L'esclave se connecte en utilisant CHANGE MASTER TO MASTER_AUTO_POSITION =1, mais le maître a purgé les journaux binaires contenant les GTID dont l'esclave a besoin."
Un tel paramètre peut ne pas toujours être approprié car le processus de reconstruction induira une charge accrue sur le maître. Il se peut également que votre ensemble de données soit très volumineux et qu'une reconstruction régulière ne soit pas une option - c'est pourquoi ce comportement est désactivé par défaut.