[ Partie 1 | Partie 2 | Partie 3 ]
Dans la partie 1 de cette série, j'ai essayé plusieurs façons de compresser une table de 1 To. Bien que j'ai obtenu des résultats décents lors de ma première tentative, je voulais voir si je pouvais améliorer les performances dans la partie 2. Là, j'ai décrit quelques-unes des choses que je pensais être des problèmes de performances et expliqué comment je ferais mieux de partitionner la table de destination pour une compression optimale du columnstore. J'ai déjà :
- partitionné la table en 8 partitions (une par cœur) ;
- placez le fichier de données de chaque partition sur son propre groupe de fichiers ; et,
- définit la compression des archives sur toutes les partitions sauf la partition "active".
Je dois encore faire en sorte que chaque planificateur écrive exclusivement sur sa propre partition.
Tout d'abord, je dois apporter des modifications à la table de lots que j'ai créée. J'ai besoin d'une colonne pour stocker le nombre de lignes ajoutées par lot (une sorte de vérification d'intégrité par auto-audit) et les heures de début/fin pour mesurer les progrès.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Ensuite, je dois créer une table pour fournir une affinité - nous ne voulons jamais plus d'un processus en cours d'exécution sur un planificateur, même si cela signifie perdre du temps pour réessayer la logique. Nous avons donc besoin d'une table qui gardera une trace de toute session sur un planificateur spécifique et empêchera l'empilement :
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
L'idée est que j'aurais huit instances d'une application (SQLQueryStress) qui s'exécuteraient chacune sur un planificateur dédié, ne traitant que les données destinées à une partition / groupe de fichiers / fichier de données spécifique, ~ 100 millions de lignes à la fois (cliquez pour agrandir) :
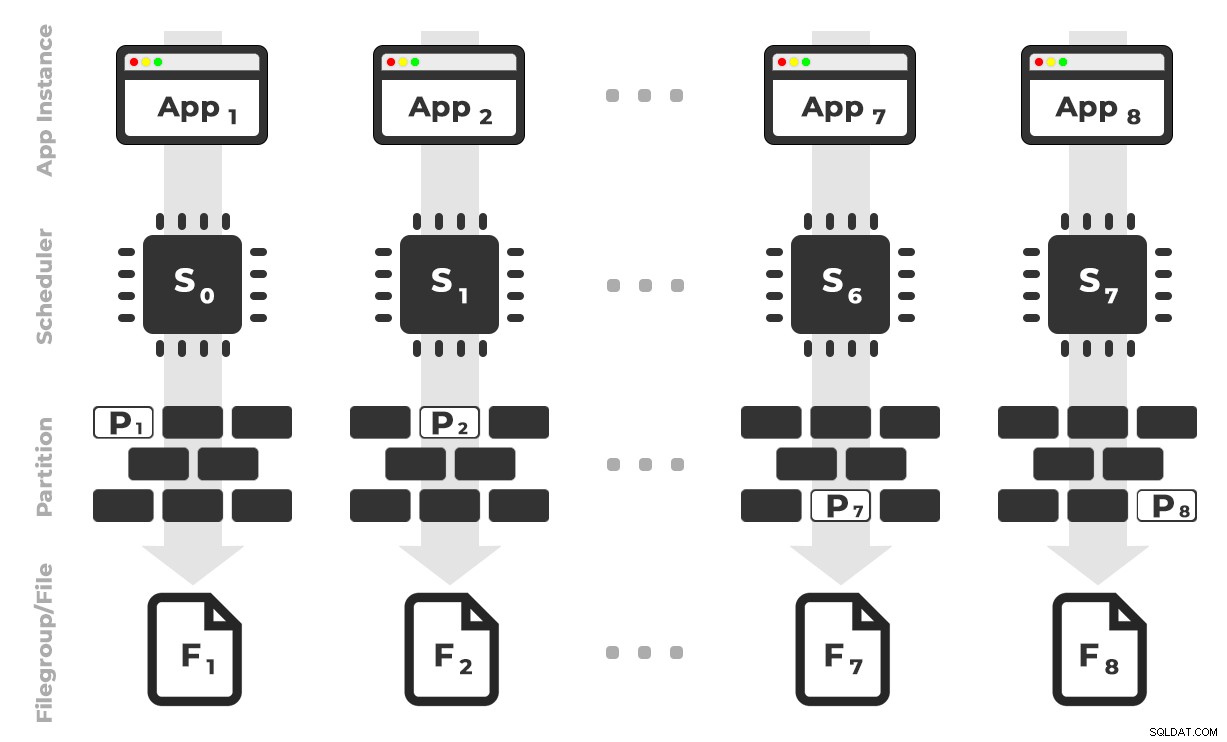 L'application 1 obtient le planificateur 0 et écrit dans la partition 1 sur le groupe de fichiers 1, et ainsi de suite …
L'application 1 obtient le planificateur 0 et écrit dans la partition 1 sur le groupe de fichiers 1, et ainsi de suite …
Ensuite, nous avons besoin d'une procédure stockée qui permettra à chaque instance de l'application de réserver du temps sur un seul planificateur. Comme je l'ai mentionné dans un article précédent, ce n'est pas mon idée originale (et je ne l'aurais jamais trouvée dans ce guide sans Joe Obbish). Voici la procédure que j'ai créée dans Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Simple, non ? Lancez 8 instances de SQLQueryStress et placez ce lot dans chacune :
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
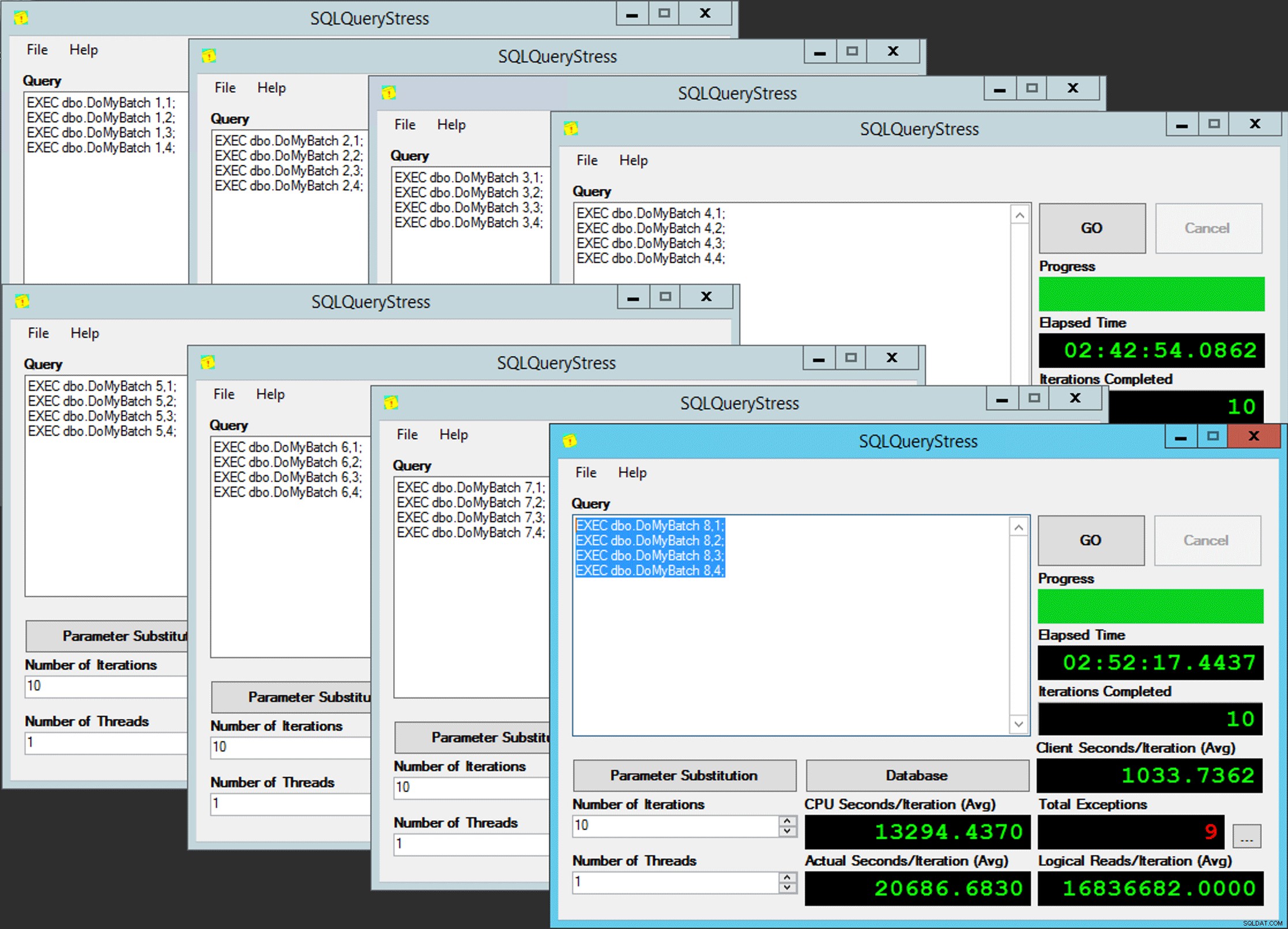 Le parallélisme du pauvre
Le parallélisme du pauvre
Sauf que ce n'est pas si simple, car l'affectation d'un ordonnanceur est un peu comme une boîte de chocolats. Il a fallu de nombreux essais pour obtenir chaque instance de l'application sur le planificateur attendu ; J'inspecterais les exceptions sur n'importe quelle instance donnée de l'application et changerais le PartitionID correspondre. C'est pourquoi j'ai utilisé plus d'une itération (mais je ne voulais toujours qu'un seul thread par instance). Par exemple, cette instance de l'application s'attendait à être sur le planificateur 3, mais elle a reçu le planificateur 4 :
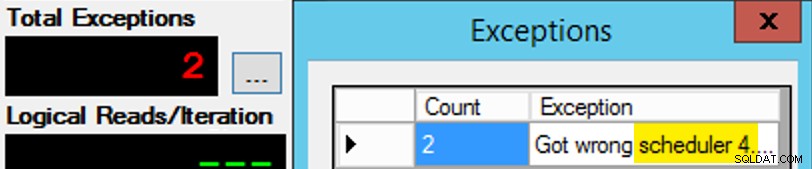 Si au début vous ne réussissez pas…
Si au début vous ne réussissez pas…
J'ai changé les 3 dans la fenêtre de requête en 4 et j'ai réessayé. Si j'étais rapide, l'affectation du planificateur était suffisamment "collante" pour qu'elle la récupère immédiatement et commence à s'en aller. Mais je n'étais pas toujours assez rapide, donc c'était un peu comme un coup de taupe pour y aller. J'aurais probablement pu concevoir une meilleure routine de réessai/boucle pour rendre le travail moins manuel ici, et raccourcir le délai afin que je sache immédiatement si cela fonctionnait ou non, mais c'était assez bon pour mes besoins. Cela a également entraîné un échelonnement involontaire des heures de démarrage de chaque processus, un autre conseil de M. Obbish.
Surveillance
Pendant que la copie affinitaire est en cours d'exécution, je peux obtenir un indice sur l'état actuel avec les deux requêtes suivantes :
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Si je faisais tout correctement, les deux requêtes renverraient 8 lignes et afficheraient des lectures logiques et une durée incrémentielles. Les types d'attente basculeront entre PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , et occasionnellement RESERVED_MEMORY_ALLOCATION_EXT. Lorsqu'un lot était terminé (je pouvais les revoir en décommentant -- AND EndTime IS NULL , je confirme que RowsAdded = RowsInRange .
Une fois les 8 instances de SQLQueryStress terminées, je pouvais simplement effectuer un SELECT INTO <newtable> FROM dbo.BatchQueue pour enregistrer les résultats finaux pour une analyse ultérieure.
Autres tests
En plus de copier les données dans l'index clustered columnstore partitionné qui existait déjà, en utilisant l'affinité, je voulais aussi essayer quelques autres choses :
- Copier les données dans la nouvelle table sans essayer de contrôler l'affinité. J'ai retiré la logique d'affinité de la procédure et j'ai laissé au hasard tout le truc "j'espère que vous obtenez le bon planificateur". Cela a pris plus de temps car, bien sûr, l'empilement du planificateur l'a fait se produire. Par exemple, à ce stade précis, le planificateur 3 exécutait deux processus, tandis que le planificateur 0 était en pause déjeuner :
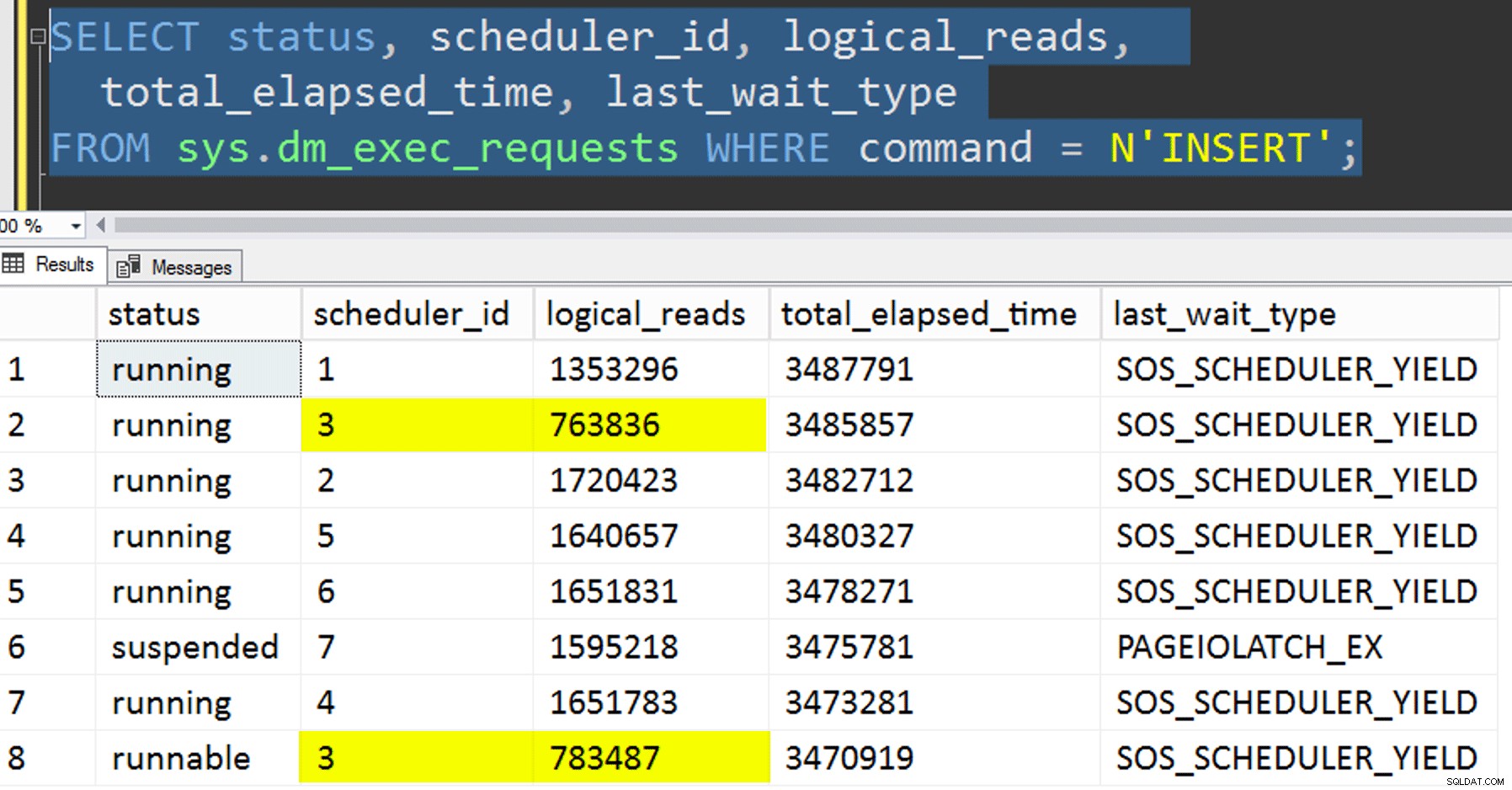 Où es-tu, planificateur numéro 0 ?
Où es-tu, planificateur numéro 0 ? - Application de la page ou ligne compression (en ligne/hors ligne) vers la source avant la copie affinitaire (hors ligne), pour voir si la compression préalable des données pourrait accélérer la destination. Notez que la copie peut également être effectuée en ligne mais, comme le
intd'Andy Mallon enbigintconversion, cela demande un peu de gymnastique. Notez que dans ce cas, nous ne pouvons pas tirer parti de l'affinité CPU (bien que nous le puissions si la table source était déjà partitionnée). J'étais intelligent et j'ai fait une sauvegarde de la source d'origine et j'ai créé une procédure pour rétablir la base de données à son état initial. Beaucoup plus rapide et facile que d'essayer de revenir manuellement à un état spécifique.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Et enfin, reconstruisez d'abord l'index clusterisé sur le schéma de partition, puis construisez l'index clustered columnstore par-dessus. L'inconvénient de ce dernier est que, dans SQL Server 2017, vous ne pouvez pas l'exécuter en ligne… mais vous pourrez le faire en 2019.
Ici, nous devons d'abord supprimer la contrainte PK ; vous ne pouvez pas utiliser
Msg 1907, Niveau 16, État 1DROP_EXISTING, car la contrainte d'unicité d'origine ne peut pas être appliquée par l'index cluster columnstore et vous ne pouvez pas remplacer un index cluster unique par un index cluster non unique.
Impossible de recréer l'index 'pk_tblOriginal'. La nouvelle définition d'index ne correspond pas à la contrainte appliquée par l'index existant.Tous ces détails en font un processus en trois étapes, seule la deuxième étape en ligne. La première étape, j'ai seulement testé explicitement
OFFLINE; qui a duré trois minutes, tandis queONLINEJ'ai arrêté au bout de 15 minutes. Une de ces choses qui ne devrait peut-être pas être une opération de taille de données dans les deux cas, mais je vais laisser ça pour un autre jour.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Résultats
Timings et taux de compression :
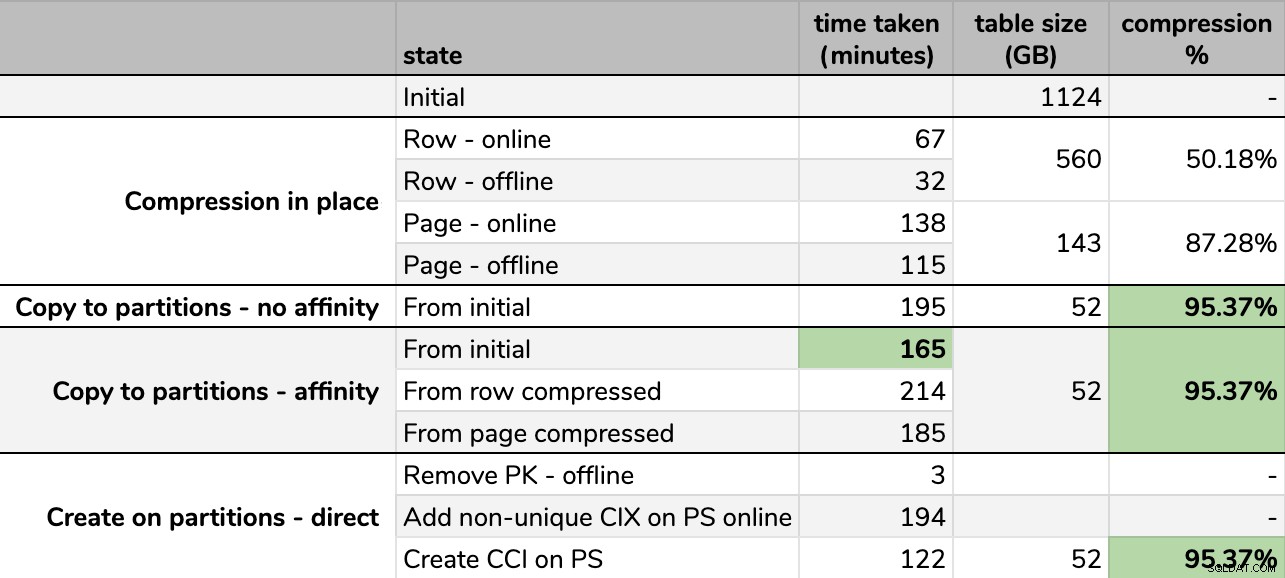 Certaines options sont meilleures que d'autres
Certaines options sont meilleures que d'autres
Notez que j'ai arrondi au Go car il y aurait des différences mineures dans la taille finale après chaque exécution, même en utilisant la même technique. De plus, les délais des méthodes d'affinité étaient basés sur la moyenne planificateur individuel/exécution par lots, car certains planificateurs se sont terminés plus rapidement que d'autres.
Il est difficile d'imaginer une image exacte à partir de la feuille de calcul comme indiqué, car certaines tâches ont des dépendances, je vais donc essayer d'afficher les informations sous forme de chronologie et de montrer la compression que vous obtenez par rapport au temps passé :
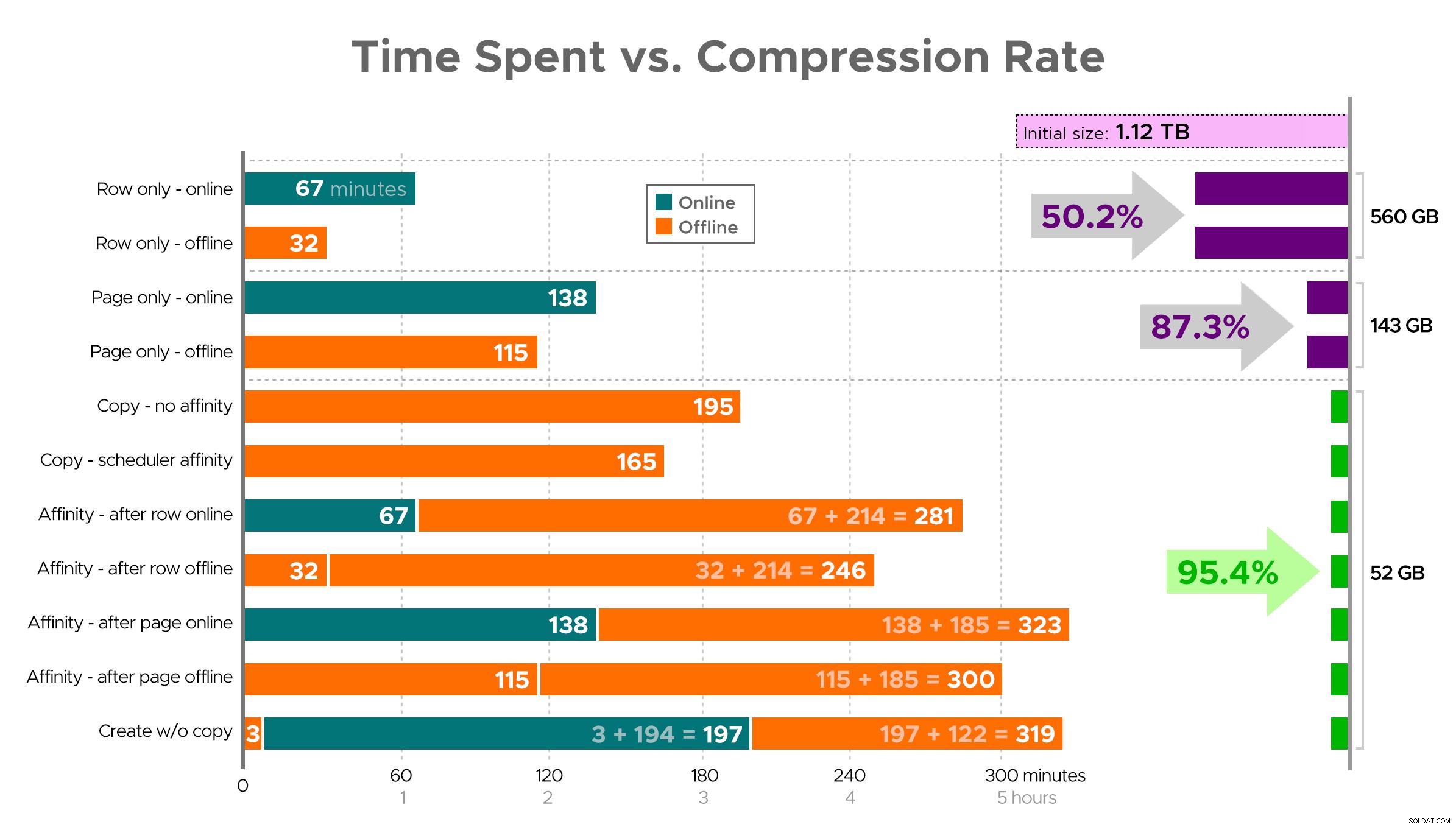 Temps passé (minutes) par rapport au taux de compression
Temps passé (minutes) par rapport au taux de compression
Quelques observations à partir des résultats, avec la mise en garde que vos données peuvent être compressées différemment (et que les opérations en ligne ne s'appliquent qu'à vous si vous utilisez Enterprise Edition) :
- Si votre priorité est de économiser de l'espace le plus rapidement possible , le mieux est d'appliquer la compression de ligne en place. Si vous souhaitez minimiser les perturbations, utilisez en ligne ; si vous souhaitez optimiser la vitesse, utilisez hors ligne.
- Si vous souhaitez maximiser la compression sans interruption , vous pouvez approcher une réduction de stockage de 90 % sans aucune interruption, en utilisant la compression de page en ligne.
- Si vous voulez maximiser la compression et les perturbations, c'est bien , copiez les données dans une nouvelle version partitionnée de la table, avec un index cluster columnstore, et utilisez le processus d'affinité décrit ci-dessus pour migrer les données. (Et encore une fois, vous pouvez éliminer cette perturbation si vous êtes un meilleur planificateur que moi.)
La dernière option a fonctionné le mieux pour mon scénario, même si nous devrons encore écraser les charges de travail (oui, au pluriel). Notez également que dans SQL Server 2019, cette technique peut ne pas fonctionner aussi bien, mais vous pouvez y créer des index clustered columnstore en ligne, donc cela peut ne pas avoir autant d'importance.
Certaines de ces approches peuvent être plus ou moins acceptables pour vous, car vous pouvez préférer « rester disponible » plutôt que « finir le plus rapidement possible », ou « minimiser l'utilisation du disque » plutôt que « rester disponible », ou simplement équilibrer les performances de lecture et la surcharge d'écriture. .
Si vous voulez plus de détails sur n'importe quel aspect de cela, il suffit de demander. J'ai coupé une partie de la graisse pour équilibrer les détails avec la digestibilité, et je me suis trompé sur cet équilibre auparavant. Une pensée d'adieu est que je suis curieux de savoir à quel point cela est linéaire - nous avons une autre table avec une structure similaire qui dépasse 25 To, et je suis curieux de savoir si nous pouvons avoir un impact similaire là-bas. En attendant, bonne compression !
[ Partie 1 | Partie 2 | Partie 3 ]