Il est facile de commencer à bricoler avec les engrenages de l'optimisation des requêtes SQL. Vous ouvrez SQL Server Management Studio (SSMS), surveillez le temps d'attente, examinez le plan d'exécution, collectez des informations sur les objets et commencez à optimiser SQL jusqu'à ce que vous exécutiez une machine parfaitement réglée.
Si vous êtes assez bon dans ce domaine, vous remportez une victoire rapide et revenez à votre chaos régulièrement programmé. Mais si vous ajustez la mauvaise chose, ou ajustez la bonne chose dans la mauvaise direction, eh bien, votre mercredi est passé.
Optimisation des requêtes SQL ? Qu'est-ce qui vous fait penser que vous en avez besoin ?
La plupart du temps, il s'agit d'un pic de tickets d'incident ou de plaintes d'utilisateurs. « Pourquoi le système est-il si lent ? » vos utilisateurs se plaignent. "Il nous faut une éternité pour exécuter nos rapports habituels cette semaine."
C'est une description assez vague, bien sûr. Ce serait bien s'ils pouvaient vous dire :« Les choses sont lentes parce que vous avez une conversion implicite à la ligne 62 de CurrentOrderQuery5.sql. La colonne est varchar et vous transmettez un entier. Mais il est peu probable que vos utilisateurs puissent voir ce niveau de détail.
Au moins, les tickets d'incident et les appels téléphoniques constituent une mesure active :facile à repérer, facile à mesurer. Lorsqu'ils commencent à arriver, vous pouvez être raisonnablement sûr qu'il est temps de régler SQL.
Mais il existe d'autres mesures passives qui rendent le besoin moins clair. Des choses comme la chute des ventes, qui pourrait être due à un certain nombre de facteurs. Est-ce parce que les requêtes douloureusement lentes dans votre boutique en ligne font que vos clients abandonnent leurs paniers ? Est-ce parce que l'économie va mal ?
Ou cela pourrait être des choses comme des performances lentes de SQL Server. Est-ce parce qu'une requête mal écrite envoie des lectures logiques à travers le toit ? Est-ce parce que le serveur manque de ressources physiques comme la mémoire et le stockage ?
Dans les deux scénarios, l'optimisation des requêtes SQL peut aider avec la première option, mais pas avec la seconde.
Pourquoi appliquer la bonne solution au mauvais problème ?
Avant de vous engager sur la voie de l'optimisation, assurez-vous que le réglage est la bonne solution au bon problème.
Le réglage de SQL est un processus technique, mais chaque étape technique a ses racines dans le bon sens commercial. Vous pourriez passer des jours à essayer de raccourcir le temps d'exécution de quelques millisecondes ou de réduire le nombre de lectures logiques de 5 %, mais cette réduction en vaut-elle la peine ? Il est vrai qu'il est important de répondre aux exigences des utilisateurs, mais chaque effort finit par décroître.
Tenez compte de ces problèmes de performances des requêtes SQL et du contexte commercial qui les entoure :
- Performances acceptables — Une requête prend 10 minutes à s'exécuter et l'utilisateur souhaite qu'elle s'exécute en une minute; cela semble être une disparité raisonnable et un objectif réalisable pour l'optimisation. Cependant, si la requête prend une nuit et que l'utilisateur pense qu'elle devrait s'exécuter en une minute, il peut s'agir de plus qu'un problème de réglage. D'une part, vous devrez peut-être informer l'utilisateur de la quantité de travail que la requête effectue réellement. D'autre part, il peut s'agir d'un problème lié à la conception de la base de données ou à la manière dont l'application cliente a été écrite.
- Utilitaire — Supposons que vous soyez responsable de l'administration de la base de données financière dans une entreprise manufacturière. À la fin de chaque mois, les utilisateurs se plaignent de mauvaises performances. Vous attribuez le problème à une série de rapports de fin de mois gérés par la comptabilité qui prennent des heures chacun et vont directement dans un classeur sans être examinés par personne. Au lieu de régler, vous expliquez le problème aux chefs d'entreprise et obtenez l'autorisation de supprimer les rapports.
- Décalage horaire — Ou, supposons que ces mêmes rapports soient importants pour la gouvernance mais pas urgents pour l'entreprise. S'ils sont exécutés une fois par semaine ou par mois, ils peuvent être programmés pendant les heures creuses en pré-mettant en cache l'ensemble de données et en envoyant les résultats dans un fichier. Cela supprime le goulot d'étranglement pour les autres utilisateurs professionnels et évite à l'utilisateur Comptabilité d'avoir à attendre les rapports.
Lorsque vous tenez compte du contexte commercial dans votre décision d'optimiser, vous pouvez définir des priorités et gagner du temps.
Lorsque vous optimisez les requêtes SQL, essayez la création de diagrammes SQL
SSMS et les outils intégrés à SQL Server offrent l'essentiel de ce dont vous avez besoin pour une optimisation efficace des requêtes SQL. Combinez les outils avec une approche méthodique autour des étapes suivantes, comme décrit dans l'e-book "Le guide fondamental de l'optimisation des requêtes SQL" :
- Surveiller le temps d'attente
- Examiner le plan d'exécution
- Recueillir des informations sur l'objet
- Trouvez la table de conduite
- Identifier les inhibiteurs de performances
À l'étape 4, votre objectif est de piloter la requête avec la table qui renvoie le moins de données. Lorsque vous étudiez les jointures et les prédicats et que vous filtrez plus tôt dans la requête plutôt que plus tard, vous réduisez le nombre de lectures logiques. C'est un grand pas en avant dans l'optimisation des requêtes SQL.
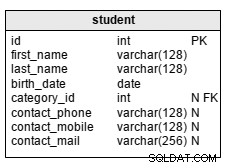
La création de diagrammes SQL est une technique graphique permettant de cartographier la quantité de données dans les tables et de trouver le filtre qui renverra le moins d'enregistrements. Tout d'abord, vous déterminez quelles tables contiennent les informations détaillées et quelles tables sont les tables principales ou de recherche. Prenons l'exemple simple de cette requête sur une base de données d'inscription universitaire :

Le tableau de détail est l'enregistrement. Il a deux tables de recherche, étudiant et classe. Pour schématiser ces tables, dessinez une arborescence inversée reliant la table détaillée (en haut) avec des flèches (ou des liens) aux tables de recherche, comme ceci :

Maintenant, calculez le nombre relatif d'enregistrements requis pour les critères de jointure (c'est-à-dire le rapport moyen des lignes liées entre la table de détails et les tables de recherche). Écrivez les nombres à chaque extrémité de la flèche. Dans cet exemple, pour chaque élève, il y a environ 5 enregistrements dans la table d'inscription, et pour chaque classe, il y a environ 30 enregistrements dans l'inscription. Cela signifie qu'il ne devrait jamais être nécessaire de JOINDRE plus de 150 (5×30) enregistrements pour obtenir un résultat pour un seul élève ou une seule classe.
Cet exercice est utile si vos colonnes de jointure ne sont pas indexées ou si vous n'êtes pas sûr qu'elles le soient.
Ensuite, examinez les prédicats de filtrage pour trouver la table avec laquelle piloter la requête. Cette requête avait deux filtres :un sur l'inscription annulée = 'N' et l'autre sur signup_date entre deux dates. Pour voir à quel point le filtre est sélectif, exécutez cette requête lors de l'inscription :
select count(1) from registration where cancelled ='N'
ET r.signup_date ENTRE :beg_date ET :beg_date +1
Il renvoie 4 344 enregistrements sur les 79 800 enregistrements au total dans l'enregistrement. Autrement dit, 5,43 % des enregistrements seront lus avec ce filtre.
L'autre filtre est sur la classe :
select count(1) from class where name ='ANGLAIS 101'
Il renvoie deux enregistrements sur 1 000, soit 0,2 %, ce qui représente un filtre beaucoup plus sélectif. Ainsi, la classe est la table de pilotage, et celle sur laquelle concentrer votre réglage SQL en premier.
La voix de l'utilisateur
Si vous êtes sûr d'avoir besoin d'un réglage SQL, "Le guide fondamental de l'optimisation des requêtes SQL" offre plus d'informations. Il vous guide à travers cinq conseils d'optimisation des performances avec des requêtes copier-coller et des études de cas, y compris celui décrit ci-dessus.
Vous constaterez probablement que l'outil d'optimisation des requêtes SQL le plus important est la voix de l'utilisateur. Pourquoi? Parce que cette voix vous permet de savoir quand commencer à optimiser et vous indique quand vous avez suffisamment optimisé. Cela peut vous permettre de commencer à bricoler les engrenages lorsque vous en avez besoin et de vous arrêter pendant que vous êtes encore devant.