Dans les parties 1 et 2 de cette série, j'ai couvert les aspects logiques ou conceptuels des expressions de table nommées en général et des tables dérivées en particulier. Ce mois-ci et le suivant, je vais couvrir les aspects de traitement physique des tables dérivées. Rappel de la partie 1 l'indépendance des données physiques principe de la théorie relationnelle. Le modèle relationnel et le langage d'interrogation standard qui est basé sur celui-ci sont censés ne traiter que les aspects conceptuels des données et laisser les détails de mise en œuvre physique comme le stockage, l'optimisation, l'accès et le traitement des données à la plate-forme de base de données (le mise en œuvre ). Contrairement au traitement conceptuel des données qui est basé sur un modèle mathématique et un langage standard, et donc très similaire dans les différents systèmes de gestion de bases de données relationnelles, le traitement physique des données ne repose sur aucun standard, et tend donc être très spécifique à la plate-forme. Dans ma couverture du traitement physique des expressions de table nommées dans la série, je me concentre sur le traitement dans Microsoft SQL Server et Azure SQL Database. Le traitement physique dans d'autres plates-formes de bases de données peut être assez différent.
Rappelez-vous que ce qui a déclenché cette série est une certaine confusion qui existe dans la communauté SQL Server autour des expressions de table nommées. Tant en termes de terminologie qu'en termes d'optimisation. J'ai abordé certaines considérations terminologiques dans les deux premières parties de la série, et j'en parlerai davantage dans de futurs articles lors de l'examen des CTE, des vues et des TVF en ligne. En ce qui concerne l'optimisation des expressions de table nommées, il existe une confusion autour des éléments suivants (je mentionne ici les tables dérivées puisque c'est l'objet de cet article) :
- Persistance : Une table dérivée est-elle persistante quelque part ? Est-il conservé sur le disque et comment SQL Server gère-t-il la mémoire pour cela ?
- Projection de colonne : Comment fonctionne la correspondance d'index avec les tables dérivées ? Par exemple, si une table dérivée projette un certain sous-ensemble de colonnes à partir d'une table sous-jacente et que la requête la plus externe projette un sous-ensemble des colonnes de la table dérivée, SQL Server est-il suffisamment intelligent pour déterminer une indexation optimale basée sur le sous-ensemble final de colonnes qui est réellement nécessaire? Et qu'en est-il des autorisations ; l'utilisateur a-t-il besoin d'autorisations pour toutes les colonnes référencées dans les requêtes internes, ou uniquement pour les dernières qui sont réellement nécessaires ?
- Références multiples aux alias de colonne : Si la table dérivée a une colonne de résultat basée sur un calcul non déterministe, par exemple, un appel à la fonction SYSDATETIME, et que la requête externe a plusieurs références à cette colonne, le calcul sera-t-il effectué une seule fois, ou séparément pour chaque référence externe ?
- Désimbrication/substitution/inlining : SQL Server désimbrique-t-il ou intègre-t-il la requête de table dérivée ? Autrement dit, SQL Server effectue-t-il un processus de substitution par lequel il convertit le code imbriqué d'origine en une requête qui va directement sur les tables de base ? Et si oui, existe-t-il un moyen de demander à SQL Server d'éviter ce processus de désimbrication ?
Ce sont toutes des questions importantes et les réponses à ces questions ont des implications importantes sur les performances, c'est donc une bonne idée d'avoir une compréhension claire de la façon dont ces éléments sont gérés dans SQL Server. Ce mois-ci, je vais aborder les trois premiers points. Il y a beaucoup à dire sur le quatrième élément, je lui consacrerai donc un article séparé le mois prochain (Partie 4).
Dans mes exemples, j'utiliserai un exemple de base de données appelé TSQLV5. Vous pouvez trouver le script qui crée et remplit TSQLV5 ici, et son diagramme ER ici.
Persistance
Certaines personnes supposent intuitivement que SQL Server conserve le résultat de la partie expression de table de la table dérivée (le résultat de la requête interne) dans une table de travail. À la date de rédaction de cet article, ce n'est pas le cas ; cependant, étant donné que les considérations de persistance sont le choix d'un fournisseur, Microsoft pourrait décider de changer cela à l'avenir. En effet, SQL Server est capable de conserver les résultats de requête intermédiaires dans des tables de travail (généralement dans tempdb) dans le cadre du traitement de la requête. S'il choisit de le faire, vous voyez une forme d'opérateur de spool dans le plan (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Cependant, le choix de SQL Server de spouler ou non quelque chose dans une table de travail n'a actuellement rien à voir avec votre utilisation d'expressions de table nommées dans la requête. SQL Server met parfois en file d'attente les résultats intermédiaires pour des raisons de performances, comme éviter un travail répété (bien qu'actuellement sans rapport avec l'utilisation d'expressions de table nommées), et parfois pour d'autres raisons, comme la protection Halloween.
Comme mentionné, le mois prochain, j'aborderai les détails de la désimbrication des tables dérivées. Pour l'instant, il suffit de dire que SQL Server applique normalement un processus de désimbrication/intégration aux tables dérivées, où il remplace les requêtes imbriquées par une requête sur les tables de base sous-jacentes. Bon, je simplifie un peu. Ce n'est pas comme si SQL Server convertissait littéralement la chaîne de requête T-SQL d'origine avec les tables dérivées en une nouvelle chaîne de requête sans celles-ci; au lieu de cela, SQL Server applique des transformations à une arborescence logique interne d'opérateurs, et le résultat est que les tables dérivées sont généralement non imbriquées. Lorsque vous examinez un plan d'exécution pour une requête impliquant des tables dérivées, vous ne voyez aucune mention de celles-ci car, pour la plupart des objectifs d'optimisation, elles n'existent pas. Vous voyez l'accès aux structures physiques qui contiennent les données des tables de base sous-jacentes (le tas, les index rowstore B-tree et les index columnstore pour les tables sur disque et les index arborescents et de hachage pour les tables optimisées en mémoire).
Il existe des cas qui empêchent SQL Server de désimbriquer une table dérivée, mais même dans ces cas, SQL Server ne conserve pas le résultat de l'expression de table dans une table de travail. Je fournirai les détails ainsi que des exemples le mois prochain.
Étant donné que SQL Server ne conserve pas les tables dérivées, mais interagit directement avec les structures physiques qui contiennent les données des tables de base sous-jacentes, la question de savoir comment la mémoire est gérée pour les tables dérivées est sans objet. Si les tables de base sous-jacentes sont basées sur disque, leurs pages pertinentes doivent être traitées dans le pool de mémoire tampon. Si les tables sous-jacentes sont des tables optimisées en mémoire, leurs lignes en mémoire pertinentes doivent être traitées. Mais ce n'est pas différent que lorsque vous interrogez directement les tables sous-jacentes sans utiliser de tables dérivées. Il n'y a donc rien de spécial ici. Lorsque vous utilisez des tables dérivées, SQL Server n'a pas besoin d'appliquer de considérations de mémoire spéciales pour celles-ci. Pour la plupart des besoins d'optimisation des requêtes, ils n'existent pas.
Si vous avez un cas où vous devez conserver le résultat d'une étape intermédiaire dans une table de travail, vous devez utiliser des tables temporaires ou des variables de table, et non des expressions de table nommées.
Projection de colonne et un mot sur SELECT *
La projection est l'un des opérateurs originaux de l'algèbre relationnelle. Supposons que vous ayez une relation R1 avec les attributs x, y et z. La projection de R1 sur un sous-ensemble de ses attributs, par exemple, x et z, est une nouvelle relation R2, dont l'en-tête est le sous-ensemble des attributs projetés de R1 (x et z dans notre cas), et dont le corps est l'ensemble des tuples formé à partir de la combinaison originale des valeurs d'attribut projetées des tuples de R1.
Rappelez-vous que le corps d'une relation - étant un ensemble de tuples - n'a par définition aucun doublon. Il va donc sans dire que les tuples de la relation de résultat sont la combinaison distincte des valeurs d'attribut projetées à partir de la relation d'origine. Cependant, rappelez-vous que le corps d'une table en SQL est un multi-ensemble de lignes et non un ensemble, et normalement, SQL n'éliminera pas les lignes en double à moins que vous ne le lui demandiez. Étant donné une table R1 avec des colonnes x, y et z, la requête suivante peut potentiellement renvoyer des lignes en double et ne suit donc pas la sémantique de l'opérateur de projection de l'algèbre relationnelle consistant à renvoyer un ensemble :
SELECT x, zFROM R1 ;
En ajoutant une clause DISTINCT, vous éliminez les lignes en double et suivez plus étroitement la sémantique de la projection relationnelle :
SELECT DISTINCT x, zFROM R1 ;
Bien sûr, il y a des cas où vous savez que le résultat de votre requête a des lignes distinctes sans avoir besoin d'une clause DISTINCT, par exemple, lorsqu'un sous-ensemble des colonnes que vous renvoyez inclut une clé de la table interrogée. Par exemple, si x est une clé dans R1, les deux requêtes ci-dessus sont logiquement équivalentes.
Dans tous les cas, rappelez-vous les questions que j'ai mentionnées précédemment concernant l'optimisation des requêtes impliquant des tables dérivées et la projection de colonnes. Comment fonctionne la correspondance d'index ? Si une table dérivée projette un certain sous-ensemble de colonnes à partir d'une table sous-jacente et que la requête la plus externe projette un sous-ensemble de colonnes à partir de la table dérivée, SQL Server est-il suffisamment intelligent pour déterminer l'indexation optimale en fonction du sous-ensemble final de colonnes qui est réellement avait besoin? Et qu'en est-il des autorisations ; l'utilisateur a-t-il besoin d'autorisations pour toutes les colonnes référencées dans les requêtes internes, ou uniquement pour les dernières qui sont réellement nécessaires ? Supposons également que la requête d'expression de table définisse une colonne de résultat basée sur un calcul, mais que la requête externe ne projette pas cette colonne. Le calcul est-il évalué ?
En commençant par la dernière question, essayons. Considérez la requête suivante :
USE TSQLV5;GO SELECT custid, city, 1/0 AS div0errorFROM Sales.Customers;
Comme vous vous en doutez, cette requête échoue avec une erreur de division par zéro :
Msg 8134, Niveau 16, État 1Division par zéro erreur rencontrée.
Ensuite, définissez une table dérivée appelée D basée sur la requête ci-dessus, et dans le projet de requête externe D uniquement sur custid et city, comme ceci :
SELECT custid, cityFROM ( SELECT custid, city, 1/0 AS div0error FROM Sales.Customers ) AS D;
Comme mentionné, SQL Server applique normalement la désimbrication/substitution, et puisque rien dans cette requête n'empêche la désimbrication (plus d'informations le mois prochain), la requête ci-dessus est équivalente à la requête suivante :
SELECT custid, cityFROM Sales.Customers ;
Encore une fois, je simplifie un peu ici. La réalité est un peu plus complexe que ces deux requêtes étant considérées comme vraiment identiques, mais j'aborderai ces complexités le mois prochain. Le fait est que l'expression 1/0 n'apparaît même pas dans le plan d'exécution de la requête et n'est pas du tout évaluée, de sorte que la requête ci-dessus s'exécute correctement sans erreur.
Néanmoins, l'expression de table doit être valide. Par exemple, considérez la requête suivante :
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D ;
Même si la requête externe ne projette qu'une colonne du jeu de regroupement de la requête interne, la requête interne n'est pas valide car elle tente de renvoyer des colonnes qui ne font pas partie du jeu de regroupement ni contenues dans une fonction d'agrégation. Cette requête échoue avec l'erreur suivante :
Msg 8120, Niveau 16, État 1La colonne 'Sales.Customers.custid' n'est pas valide dans la liste de sélection car elle n'est contenue ni dans une fonction d'agrégat ni dans la clause GROUP BY.
Ensuite, abordons la question de la correspondance d'index. Si la requête externe ne projette qu'un sous-ensemble des colonnes de la table dérivée, SQL Server sera-t-il assez intelligent pour effectuer une correspondance d'index basée uniquement sur les colonnes renvoyées (et bien sûr sur toutes les autres colonnes qui jouent un rôle significatif autrement, comme le filtrage, regroupement, etc.) ? Mais avant d'aborder cette question, vous vous demandez peut-être pourquoi nous nous en soucions. Pourquoi auriez-vous des colonnes de retour de requête interne dont la requête externe n'a pas besoin ?
La réponse est simple, pour raccourcir le code en faisant en sorte que la requête interne utilise le fameux SELECT *. Nous savons tous que l'utilisation de SELECT * est une mauvaise pratique, mais c'est principalement le cas lorsqu'il est utilisé dans la requête la plus externe. Que se passe-t-il si vous interrogez une table avec un certain en-tête et que cet en-tête est modifié ultérieurement ? L'application pourrait se retrouver avec des bugs. Même si vous ne vous retrouvez pas avec des bogues, vous pourriez finir par générer un trafic réseau inutile en renvoyant des colonnes dont l'application n'a pas vraiment besoin. De plus, vous utilisez l'indexation de manière moins optimale dans un tel cas, car vous réduisez les chances de faire correspondre les index de couverture basés sur les colonnes réellement nécessaires.
Cela dit, je me sens en fait assez à l'aise avec SELECT * dans une expression de table, sachant que je vais de toute façon projeter uniquement les colonnes vraiment nécessaires dans la requête la plus externe. D'un point de vue logique, c'est assez sûr avec quelques mises en garde mineures que j'aborderai sous peu. Tant que la correspondance d'index est effectuée de manière optimale dans un tel cas, et la bonne nouvelle, c'est le cas.
Pour illustrer cela, supposons que vous deviez interroger la table Sales.Orders, renvoyant les trois commandes les plus récentes pour chaque client. Vous envisagez de définir une table dérivée appelée D basée sur une requête qui calcule les numéros de ligne (résultat colonne rownum) qui sont partitionnés par custid et classés par orderdate DESC, orderid DESC. La requête externe filtrera à partir de D (restriction relationnelle ) uniquement les lignes où rownum est inférieur ou égal à 3, et projeter D sur custid, orderdate, orderid et rownum. Maintenant, Sales.Orders a plus de colonnes que celles que vous devez projeter, mais par souci de brièveté, vous souhaitez que la requête interne utilise SELECT *, plus le calcul du numéro de ligne. C'est sûr et sera géré de manière optimale en termes de correspondance d'index.
Utilisez le code suivant pour créer l'index de couverture optimal pour prendre en charge votre requête :
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Voici la requête qui archive la tâche en cours (nous l'appellerons requête 1) :
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Notez le SELECT * de la requête interne et la liste de colonnes explicite de la requête externe.
Le plan de cette requête, tel que rendu par SentryOne Plan Explorer, est illustré à la figure 1.
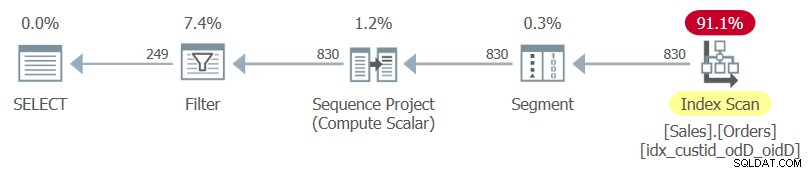 Figure 1 :Plan pour la requête 1
Figure 1 :Plan pour la requête 1
Notez que le seul index utilisé dans ce plan est l'index de couverture optimale que vous venez de créer.
Si vous ne mettez en surbrillance que la requête interne et examinez son plan d'exécution, vous verrez l'index clusterisé de la table utilisé suivi d'une opération de tri.
C'est donc une bonne nouvelle.
Quant aux autorisations, c'est une autre histoire. Contrairement à la correspondance d'index, où vous n'avez pas besoin que l'index inclue les colonnes référencées par les requêtes internes tant qu'elles ne sont finalement pas nécessaires, vous devez disposer d'autorisations sur toutes les colonnes référencées.
Pour le démontrer, utilisez le code suivant pour créer un utilisateur appelé user1 et attribuer certaines autorisations (autorisations SELECT sur toutes les colonnes de Sales.Customers et uniquement sur les trois colonnes de Sales.Orders qui sont finalement pertinentes dans la requête ci-dessus) :
CRÉER UN UTILISATEUR user1 SANS CONNEXION ; ACCORDER LE PLAN D'EXPOSITION À l'utilisateur 1 ; GRANT SELECT ON Sales.Customers TO user1 ; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1 ;
Exécutez le code suivant pour usurper l'identité de l'utilisateur 1 :
EXÉCUTER EN TANT QU'UTILISATEUR ='user1' ;
Essayez de sélectionner toutes les colonnes de Sales.Orders :
SELECT * FROM Ventes.Commandes ;
Comme prévu, vous obtenez les erreurs suivantes en raison du manque d'autorisations sur certaines colonnes :
Msg 230, Niveau 14, État 1La permission SELECT a été refusée sur la colonne 'empid' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230 , Niveau 14, État 1
La permission SELECT a été refusée sur la colonne 'requireddate' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, État 1
La permission SELECT a été refusée sur la colonne 'shippeddate' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Niveau 14, État 1
La permission SELECT a été refusée sur la colonne 'shipperid' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Niveau 14, État 1
La permission SELECT a été refusée sur la colonne 'freight' de l'objet 'Orders', base de données 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
/>La permission SELECT a été refusée sur la colonne 'shipname' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
La permission SELECT a été refusée sur la colonne 'shipaddress' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
La permission SELECT a été refusée sur la colonne 'shipcity' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
Le SELECT l'autorisation a été refusée sur la colonne 'shipregion' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
L'autorisation SELECT a été refusé sur la colonne 'shippostalcode' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
La permission SELECT a été refusée sur la colonne 'shipcountry' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Essayez la requête suivante, en projetant et en interagissant uniquement avec les colonnes pour lesquelles l'utilisateur 1 dispose des autorisations :
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Néanmoins, vous obtenez des erreurs d'autorisation de colonne en raison du manque d'autorisations sur certaines des colonnes référencées par la requête interne via son SELECT * :
Msg 230, Niveau 14, État 1La permission SELECT a été refusée sur la colonne 'empid' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230 , Niveau 14, État 1
La permission SELECT a été refusée sur la colonne 'requireddate' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, État 1
La permission SELECT a été refusée sur la colonne 'shippeddate' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Niveau 14, État 1
La permission SELECT a été refusée sur la colonne 'shipperid' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Niveau 14, État 1
La permission SELECT a été refusée sur la colonne 'freight' de l'objet 'Orders', base de données 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
/>La permission SELECT a été refusée sur la colonne 'shipname' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
La permission SELECT a été refusée sur la colonne 'shipaddress' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
La permission SELECT a été refusée sur la colonne 'shipcity' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
Le SELECT l'autorisation a été refusée sur la colonne 'shipregion' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
L'autorisation SELECT a été refusé sur la colonne 'shippostalcode' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
La permission SELECT a été refusée sur la colonne 'shipcountry' de l'objet 'Orders', base de données 'TSQLV5', schéma 'Sales'.
Si, en effet, dans votre entreprise, il est d'usage d'attribuer aux utilisateurs des autorisations uniquement sur les colonnes pertinentes avec lesquelles ils doivent interagir, il serait logique d'utiliser un code un peu plus long et d'être explicite sur la liste des colonnes dans les requêtes internes et externes, comme ça :
SELECT custid, orderdate, orderid, rownumFROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;Cette fois, la requête s'exécute sans erreur.
Une autre variante qui oblige l'utilisateur à n'avoir des autorisations que sur les colonnes pertinentes consiste à être explicite sur les noms de colonne dans la liste SELECT de la requête interne et à utiliser SELECT * dans la requête externe, comme ceci :
SELECT *FROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;Cette requête s'exécute également sans erreur. Cependant, je considère cette version comme une version sujette aux bogues au cas où plus tard, des modifications seraient apportées à un niveau d'imbrication interne. Comme mentionné précédemment, pour moi, la meilleure pratique consiste à être explicite sur la liste des colonnes dans la requête la plus externe. Donc, tant que vous n'avez aucune inquiétude concernant le manque d'autorisation sur certaines colonnes, je me sens à l'aise avec SELECT * dans les requêtes internes, mais une liste de colonnes explicite dans la requête la plus externe. Si l'application d'autorisations de colonne spécifiques est une pratique courante dans l'entreprise, il est préférable d'être simplement explicite sur les noms de colonne à tous les niveaux d'imbrication. Attention, être explicite sur les noms de colonnes à tous les niveaux d'imbrication est en fait obligatoire si votre requête est utilisée dans un objet lié au schéma, puisque la liaison au schéma interdit l'utilisation de SELECT * n'importe où dans la requête.
À ce stade, exécutez le code suivant pour supprimer l'index que vous avez créé précédemment sur Sales.Orders :
SUPPRIMER L'INDEX SI EXISTE idx_custid_odD_oidD ON Sales.Orders ;Il existe un autre cas avec un dilemme similaire concernant la légitimité de l'utilisation de SELECT * ; dans la requête interne du prédicat EXISTS.
Considérez la requête suivante (nous l'appellerons la requête 2) :
SELECT custidFROM Sales.Customers AS CWHERE EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid =C.custid);Le plan de cette requête est illustré à la figure 2.
Figure 2 :Plan pour la requête 2
Lors de l'application de la correspondance d'index, l'optimiseur a estimé que l'index idx_nc_custid est un index couvrant sur Sales.Orders puisqu'il contient la colonne custid, la seule vraie colonne pertinente dans cette requête. C'est malgré le fait que cet index ne contient aucune autre colonne que custid, et que la requête interne dans le prédicat EXISTS indique SELECT *. Jusqu'à présent, le comportement semble similaire à l'utilisation de SELECT * dans les tables dérivées.
La différence avec cette requête est qu'elle s'exécute sans erreur, malgré le fait que l'utilisateur1 n'a pas d'autorisations sur certaines des colonnes de Sales.Orders. Il y a un argument pour justifier de ne pas exiger d'autorisations sur toutes les colonnes ici. Après tout, le prédicat EXISTS n'a besoin que de vérifier l'existence de lignes correspondantes, de sorte que la liste SELECT de la requête interne n'a vraiment aucun sens. Il aurait probablement été préférable que SQL n'ait pas du tout besoin d'une liste SELECT dans un tel cas, mais ce navire a déjà navigué. La bonne nouvelle est que la liste SELECT est effectivement ignorée, à la fois en termes de correspondance d'index et en termes d'autorisations requises.
Il semblerait également qu'il existe une autre différence entre les tables dérivées et EXISTS lors de l'utilisation de SELECT * dans la requête interne. Rappelez-vous cette requête du début de l'article :
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D ;Si vous vous en souvenez, ce code a généré une erreur car la requête interne n'est pas valide.
Essayez la même requête interne, mais cette fois dans le prédicat EXISTS (nous appellerons cet énoncé 3) :
IF EXISTS ( SELECT * FROM Sales.Customers GROUP BY country ) PRINT 'Ça marche ! Merci Dmitri Korotkevitch pour le tuyau !';Curieusement, SQL Server considère ce code comme valide et il s'exécute avec succès. Le plan de ce code est illustré à la figure 3.
Figure 3 :Plan pour l'énoncé 3
Ce plan est identique au plan que vous obtiendriez si la requête interne était simplement SELECT * FROM Sales.Customers (sans le GROUP BY). Après tout, vous vérifiez l'existence de groupes, et s'il y a des lignes, il y a naturellement des groupes. Quoi qu'il en soit, je pense que le fait que SQL Server considère cette requête comme valide est un bogue. Certes, le code SQL doit être valide ! Mais je peux voir pourquoi certains pourraient prétendre que la liste SELECT dans la requête EXISTS est censée être ignorée. Quoi qu'il en soit, le plan utilise une semi-jointure gauche sondée, qui n'a pas besoin de renvoyer de colonnes, mais plutôt de sonder une table pour vérifier l'existence de lignes. L'index sur les clients peut être n'importe quel index.
À ce stade, vous pouvez exécuter le code suivant pour arrêter d'emprunter l'identité de l'utilisateur 1 et le supprimer :
REVERT ; SUPPRIMER L'UTILISATEUR SI EXISTE user1 ;Revenons au fait que je trouve pratique d'utiliser SELECT * dans les niveaux d'imbrication internes, plus vous avez de niveaux, plus cette pratique raccourcit et simplifie votre code. Voici un exemple avec deux niveaux d'imbrication :
SELECT orderid, orderyear, custid, empid, shipperidFROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear FROM ( SELECT *, YEAR(orderdate) AS orderyear FROM Sales.Orders ) AS D1 ) AS D2WHERE orderdate =fin d'année ;Il y a des cas où cette pratique ne peut pas être utilisée. Par exemple, lorsque la requête interne joint des tables avec des noms de colonne communs, comme dans l'exemple suivant :
SELECT custid, companyname, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Sales.Customers et Sales.Orders ont une colonne appelée custid. Vous utilisez une expression de table basée sur une jointure entre les deux tables pour définir la table dérivée D. N'oubliez pas que l'en-tête d'une table est un ensemble de colonnes et qu'en tant qu'ensemble, vous ne pouvez pas avoir de noms de colonne en double. Par conséquent, cette requête échoue avec l'erreur suivante :
Msg 8156, Niveau 16, État 1
La colonne 'custid' a été spécifiée plusieurs fois pour 'D'.Ici, vous devez être explicite sur les noms de colonne dans la requête interne et vous assurer que vous renvoyez custid d'une seule des tables ou attribuez des noms de colonne uniques aux colonnes de résultat au cas où vous voudriez renvoyer les deux. Plus souvent, vous utiliseriez la première approche, comme ceci :
SELECT custid, companyname, orderdate, orderid, rownumFROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O. orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Encore une fois, vous pouvez être explicite avec les noms de colonne dans la requête interne et utiliser SELECT * dans la requête externe, comme ceci :
SELECT *FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales .Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Mais comme je l'ai mentionné plus tôt, je considère que c'est une mauvaise pratique de ne pas être explicite sur les noms de colonne dans la requête la plus externe.
Références multiples aux alias de colonne
Passons à l'élément suivant :références multiples aux colonnes de la table dérivée. Si la table dérivée a une colonne de résultats basée sur un calcul non déterministe et que la requête externe a plusieurs références à cette colonne, le calcul sera-t-il évalué une seule fois ou séparément pour chaque référence ?
Commençons par le fait que plusieurs références à la même fonction non déterministe dans une requête sont supposées être évaluées indépendamment. Considérez la requête suivante comme exemple :
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2 ;Ce code génère la sortie suivante montrant deux GUID différents :
monnouvelid1 monnouvelid2------------------------------------ --------- ---------------------------7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406Inversement, si vous avez une table dérivée avec une colonne basée sur un calcul non déterministe et que la requête externe a plusieurs références à cette colonne, le calcul est censé être évalué une seule fois. Considérez la requête suivante (nous l'appellerons la requête 4) :
SELECT mynewid AS mynewid1, mynewid AS mynewid2FROM ( SELECT NEWID() AS mynewid ) AS D ;Le plan de cette requête est illustré à la figure 4.
Figure 4 :Plan pour la requête 4
Observez qu'il n'y a qu'une seule invocation de la fonction NEWID dans le plan. En conséquence, la sortie affiche deux fois le même GUID :
monnouvelid1 monnouvelid2------------------------------------ --------- ---------------------------296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74AAinsi, les deux requêtes ci-dessus ne sont pas logiquement équivalentes, et il y a des cas où l'inlining/substitution n'a pas lieu.
Avec certaines fonctions non déterministes, il est un peu plus difficile de démontrer que plusieurs invocations dans une requête sont gérées séparément. Prenez la fonction SYSDATETIME comme exemple. Il a une précision de 100 nanosecondes. Quelles sont les chances qu'une requête telle que la suivante affiche en fait deux valeurs différentes ?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ;Si vous vous ennuyez, vous pouvez appuyer sur F5 à plusieurs reprises jusqu'à ce que cela se produise. Si vous avez des choses plus importantes à faire de votre temps, vous préférerez peut-être exécuter une boucle, comme ceci :
DECLARER @i COMME INT =1 ; WHILE EXISTS( SELECT * FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;Par exemple, lorsque j'ai exécuté ce code, j'ai obtenu 1971.
Si vous voulez vous assurer que la fonction non déterministe n'est invoquée qu'une seule fois et s'appuyer sur la même valeur dans plusieurs références de requête, assurez-vous de définir une expression de table avec une colonne basée sur l'invocation de la fonction et d'avoir plusieurs références à cette colonne. à partir de la requête externe, comme ceci (nous appellerons cette requête 5) :
SELECT mydt AS mydt1, mydt AS mydt1FROM ( SELECT SYSDATETIME() AS mydt ) AS D ;Le plan de cette requête est illustré à la figure 5.
Figure 5 :Plan pour la requête 5
Notez dans le plan que la fonction n'est invoquée qu'une seule fois.
Maintenant, cela pourrait être un exercice vraiment intéressant pour les patients d'appuyer sur F5 à plusieurs reprises jusqu'à ce que vous obteniez deux valeurs différentes. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT =1; WHILE EXISTS ( SELECT * FROM (SELECT mydt AS mydt1, mydt AS mydt2 FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2 WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT CASE WHEN RAND() <0.5 THEN STR(RAND(), 5, 3) + ' is less than half.' ELSE STR(RAND(), 5, 3) + ' is at least half.' END;Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT CASE WHEN rnd <0.5 THEN STR(rnd, 5, 3) + ' is less than half.' ELSE STR(rnd, 5, 3) + ' is at least half.' ENDFROM ( SELECT RAND() AS rnd ) AS D;Résumé
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.



