Mon ami Peter Larsson m'a envoyé un défi T-SQL impliquant l'adéquation entre l'offre et la demande. En ce qui concerne les défis, c'est formidable. C'est un besoin assez courant dans la vraie vie; c'est simple à décrire, et c'est assez facile à résoudre avec des performances raisonnables en utilisant une solution basée sur le curseur. La partie la plus délicate consiste à le résoudre à l'aide d'une solution efficace basée sur des ensembles.
Lorsque Peter m'envoie un puzzle, je réponds généralement avec une solution suggérée, et il propose généralement une solution brillante et plus performante. Je soupçonne parfois qu'il m'envoie des énigmes pour se motiver à trouver une excellente solution.
Étant donné que la tâche représente un besoin commun et qu'elle est si intéressante, j'ai demandé à Peter s'il accepterait que je la partage ainsi que ses solutions avec les lecteurs de sqlperformance.com, et il a été ravi de me laisser faire.
Ce mois-ci, je présenterai le défi et la solution classique basée sur le curseur. Dans les articles suivants, je présenterai des solutions basées sur des ensembles, y compris celles sur lesquelles Peter et moi avons travaillé.
Le défi
Le défi consiste à interroger une table appelée Auctions, que vous créez à l'aide du code suivant :
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Cette table contient les entrées de demande et d'approvisionnement. Les entrées de demande sont marquées par le code D et les entrées d'approvisionnement par S. Votre tâche consiste à faire correspondre les quantités d'approvisionnement et de demande en fonction de la commande d'ID, en écrivant le résultat dans une table temporaire. Les entrées peuvent représenter des ordres d'achat et de vente de crypto-monnaie tels que BTC/USD, des ordres d'achat et de vente d'actions tels que MSFT/USD, ou tout autre article ou bien pour lequel vous devez faire correspondre l'offre à la demande. Notez qu'il manque un attribut de prix aux entrées d'enchères. Comme mentionné, vous devez faire correspondre les quantités d'approvisionnement et de demande en fonction de la commande d'ID. Cet ordre peut avoir été dérivé du prix (croissant pour les entrées d'approvisionnement et décroissant pour les entrées de demande) ou de tout autre critère pertinent. Dans ce défi, l'idée était de garder les choses simples et de supposer que l'ID représente déjà l'ordre pertinent pour la correspondance.
Par exemple, utilisez le code suivant pour remplir la table Auctions avec un petit ensemble d'exemples de données :
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Vous êtes censé faire correspondre les quantités de l'offre et de la demande comme suit :
- Une quantité de 5,0 correspond à la demande 1 et à l'approvisionnement 1 000, ce qui épuise la demande 1 et laisse 3,0 de l'approvisionnement 1 000
- Une quantité de 3,0 correspond à la demande 2 et à l'offre 1 000, ce qui épuise à la fois la demande 2 et l'offre 1 000
- Une quantité de 6,0 correspond à la demande 3 et à l'offre 2 000, ce qui laisse 2,0 de la demande 3 et épuise l'offre 2 000
- Une quantité de 2,0 correspond à la demande 3 et à l'approvisionnement 3 000, ce qui épuise à la fois la demande 3 et l'approvisionnement 3 000
- Une quantité de 2,0 correspond à la demande 5 et à l'offre 4 000, ce qui épuise à la fois la demande 5 et l'offre 4 000
- Une quantité de 4,0 correspond à la demande 6 et à l'offre 5 000, ce qui laisse 4,0 de la demande 6 et épuise l'offre 5 000
- Une quantité de 3,0 correspond à la demande 6 et à l'offre 6 000, ce qui laisse 1,0 de la demande 6 et épuise l'offre 6 000
- Une quantité de 1,0 correspond à la demande 6 et à l'offre 7 000, ce qui épuise la demande 6 et laisse 1,0 de l'offre 7 000
- Une quantité de 1,0 correspond à la demande 7 et à l'offre 7 000, ce qui laisse 3,0 de la demande 7 et épuise l'offre 7 000 ; La demande 8 ne correspond à aucune entrée d'approvisionnement et se retrouve donc avec la quantité totale 2.0
Votre solution est censée écrire les données suivantes dans la table temporaire résultante :
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Vaste ensemble d'échantillons de données
Pour tester les performances des solutions, vous aurez besoin d'un plus grand ensemble d'exemples de données. Pour vous aider, vous pouvez utiliser la fonction GetNums, que vous créez en exécutant le code suivant :
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Cette fonction renvoie une séquence d'entiers dans la plage demandée.
Une fois cette fonction en place, vous pouvez utiliser le code suivant fourni par Peter pour remplir la table Auctions avec des exemples de données, en personnalisant les entrées selon vos besoins :
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Comme vous pouvez le constater, vous pouvez personnaliser le nombre d'acheteurs et de vendeurs ainsi que les quantités minimales et maximales d'acheteurs et de vendeurs. Le code ci-dessus spécifie 200 000 acheteurs et 200 000 vendeurs, ce qui donne un total de 400 000 lignes dans la table Auctions. La dernière requête vous indique combien d'entrées de demande (D) et d'offre (S) ont été écrites dans la table. Il renvoie la sortie suivante pour les entrées susmentionnées :
Code Items ---- ----------- D 200000 S 200000
Je vais tester les performances de différentes solutions à l'aide du code ci-dessus, en définissant le nombre d'acheteurs et de vendeurs sur les valeurs suivantes :50 000, 100 000, 150 000 et 200 000. Cela signifie que j'obtiendrai le nombre total de lignes suivant dans le tableau :100 000, 200 000, 300 000 et 400 000. Bien entendu, vous pouvez personnaliser les entrées à votre guise pour tester les performances de vos solutions.
Solution basée sur le curseur
Peter a fourni la solution basée sur le curseur. C'est assez basique, ce qui est l'un de ses avantages importants. Il servira de référence.
La solution utilise deux curseurs :un pour les entrées de demande classées par ID et l'autre pour les entrées d'approvisionnement classées par ID. Pour éviter un parcours complet et un tri par curseur, créez l'index suivant :
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Voici le code complet de la solution :
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Comme vous pouvez le voir, le code commence par créer une table temporaire. Il déclare ensuite les deux curseurs et extrait une ligne de chacun, en écrivant la quantité de demande actuelle dans la variable @DemandQuantity et la quantité d'approvisionnement actuelle dans @SupplyQuantity. Il traite ensuite les entrées dans une boucle tant que la dernière récupération a réussi. Le code applique la logique suivante dans le corps de la boucle :
Si la quantité demandée actuelle est inférieure ou égale à la quantité d'approvisionnement actuelle, le code effectue les actions suivantes :
- Écrit une ligne dans la table temporaire avec la paire actuelle, avec la quantité demandée (@DemandQuantity) comme quantité correspondante
- Soustrait la quantité demandée actuelle de la quantité d'approvisionnement actuelle (@SupplyQuantity)
- Récupère la ligne suivante à partir du curseur de demande
Sinon, le code fait ce qui suit :
- Vérifie si la quantité d'approvisionnement actuelle est supérieure à zéro, et si c'est le cas, il fait ce qui suit :
- Écrit une ligne dans la table temporaire avec l'association actuelle, avec la quantité d'approvisionnement comme quantité correspondante
- Soustrait la quantité d'approvisionnement actuelle de la quantité de demande actuelle
- Récupère la ligne suivante à partir du curseur d'approvisionnement
Une fois la boucle terminée, il n'y a plus de paires à faire correspondre, donc le code nettoie simplement les ressources du curseur.
Du point de vue des performances, vous obtenez la surcharge typique de la récupération du curseur et de la boucle. Là encore, cette solution effectue une seule passe ordonnée sur les données de demande et une seule passe ordonnée sur les données d'offre, chacune utilisant une recherche et une analyse de plage dans l'index que vous avez créé précédemment. Les plans pour les requêtes de curseur sont illustrés à la figure 1.

Figure 1 :Plans pour les requêtes de curseur
Étant donné que le plan effectue une recherche et une analyse de plage ordonnée de chacune des parties (demande et offre) sans aucun tri, il a une mise à l'échelle linéaire. Cela a été confirmé par les chiffres de performance que j'ai obtenus lors du test, comme le montre la figure 2.
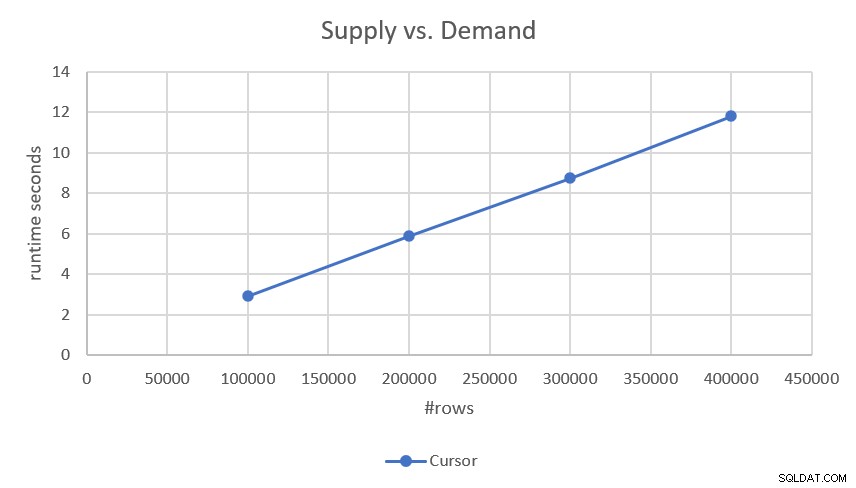
Figure 2 :performances de la solution basée sur les curseurs
Si vous êtes intéressé par les durées d'exécution plus précises, les voici :
- 100 000 lignes (50 000 demandes et 50 000 fournitures) :2,93 secondes
- 200 000 lignes :5,89 secondes
- 300 000 lignes :8,75 secondes
- 400 000 lignes :11,81 secondes
Étant donné que la solution a une mise à l'échelle linéaire, vous pouvez facilement prédire le temps d'exécution avec d'autres échelles. Par exemple, avec un million de lignes (par exemple, 500 000 demandes et 500 000 fournitures), l'exécution devrait prendre environ 29,5 secondes.
Le défi est lancé
La solution basée sur le curseur a une mise à l'échelle linéaire et, en tant que telle, elle n'est pas mauvaise. Mais cela entraîne la surcharge typique de récupération et de bouclage du curseur. Évidemment, vous pouvez réduire cette surcharge en implémentant le même algorithme à l'aide d'une solution basée sur CLR. La question est la suivante :pouvez-vous proposer une solution basée sur des ensembles performante pour cette tâche ?
Comme mentionné, j'explorerai des solutions basées sur des ensembles, à la fois peu performantes et performantes, à partir du mois prochain. En attendant, si vous êtes prêt à relever le défi, voyez si vous pouvez proposer vos propres solutions basées sur des ensembles.
Pour vérifier l'exactitude de votre solution, comparez d'abord son résultat avec celui indiqué ici pour le petit ensemble de données d'échantillon. Vous pouvez également vérifier la validité du résultat de votre solution avec un grand ensemble d'exemples de données en vérifiant que la différence symétrique entre le résultat de la solution du curseur et le vôtre est vide. En supposant que le résultat du curseur est stocké dans une table temporaire appelée #PairingsCursor et le vôtre dans une table temporaire appelée #MyPairings, vous pouvez utiliser le code suivant pour y parvenir :
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Le résultat doit être vide.
Bonne chance !
[ Aller aux solutions :Partie 1 | Partie 2 | Partie 3 ]