Dans la première partie de cette série, j'ai introduit la terminologie de base autour de la journalisation, je vous recommande donc de la lire avant de continuer avec cet article. Tout le reste que je couvrirai dans la série nécessite de connaître une partie de l'architecture du journal des transactions, c'est donc ce dont je vais discuter cette fois. Même si vous n'allez pas suivre la série, certains des concepts que je vais expliquer ci-dessous valent la peine d'être connus pour les tâches quotidiennes que les DBA gèrent en production.
Hiérarchie structurelle
Le journal des transactions est organisé en interne à l'aide d'une hiérarchie à trois niveaux, comme illustré dans la figure 1 ci-dessous.
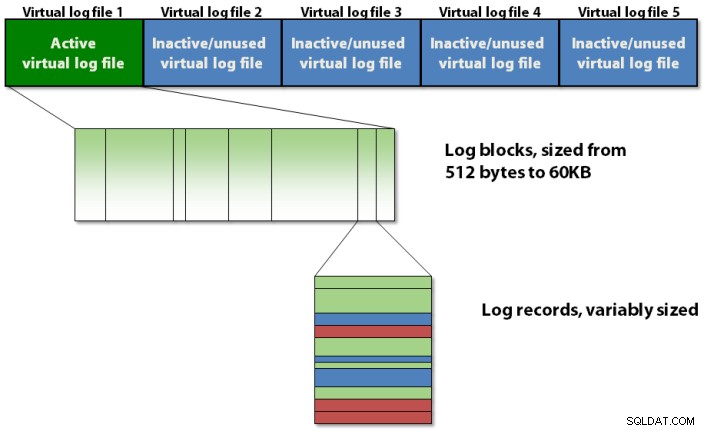 Figure 1 :La hiérarchie structurelle à trois niveaux du journal des transactions
Figure 1 :La hiérarchie structurelle à trois niveaux du journal des transactions
Le journal des transactions contient des fichiers journaux virtuels, qui contiennent des blocs de journal, qui stockent les enregistrements de journal réels.
Fichiers journaux virtuels
Le journal des transactions est divisé en sections appelées fichiers journaux virtuels , communément appelés VLF . Ceci est fait pour faciliter la gestion des opérations dans le journal des transactions pour le gestionnaire de journaux dans SQL Server. Vous ne pouvez pas spécifier le nombre de VLF créés par SQL Server lorsque la base de données est créée pour la première fois ou que le fichier journal s'agrandit automatiquement, mais vous pouvez l'influencer. L'algorithme du nombre de VLF créés est le suivant :
- Taille du fichier journal inférieure à 64 Mo :créez 4 fichiers VLF d'environ 16 Mo chacun
- Taille du fichier journal de 64 Mo à 1 Go :créez 8 fichiers VLF, chacun représentant environ 1/8 de la taille totale
- Taille du fichier journal supérieure à 1 Go :créez 16 fichiers VLF, chacun représentant environ 1/16 de la taille totale
Avant SQL Server 2014, lorsque le fichier journal se développe automatiquement, le nombre de nouvelles VLF ajoutées à la fin du fichier journal est déterminé par l'algorithme ci-dessus, en fonction de la taille de croissance automatique. Cependant, en utilisant cet algorithme, si la taille de la croissance automatique est petite et que le fichier journal subit de nombreuses croissances automatiques, cela peut conduire à un très grand nombre de petites VLF (appelées fragmentation VLF ) qui peut être un gros problème de performances pour certaines opérations (voir ici).
En raison de ce problème, dans SQL Server 2014, l'algorithme a changé pour la croissance automatique du fichier journal. Si la taille de croissance automatique est inférieure à 1/8 de la taille totale du fichier journal, un seul nouveau VLF est créé, sinon l'ancien algorithme est utilisé. Cela réduit considérablement le nombre de VLF pour un fichier journal qui a subi une grande quantité de croissance automatique. J'ai expliqué un exemple de la différence dans cet article de blog.
Chaque VLF a un numéro de séquence qui l'identifie de manière unique et est utilisé dans une variété d'endroits, ce que j'expliquerai ci-dessous et dans les prochains articles. On pourrait penser que les numéros de séquence commenceraient à 1 pour une toute nouvelle base de données, mais ce n'est pas le cas.
Sur une instance SQL Server 2019, j'ai créé une nouvelle base de données, sans spécifier de taille de fichier, puis j'ai vérifié les VLF à l'aide du code ci-dessous :
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Notez le sys.dm_db_log_info DMV a été ajouté dans SQL Server 2016 SP2. Avant cela (et aujourd'hui, car il existe toujours), vous pouvez utiliser le DBCC LOGINFO non documenté commande, mais vous ne pouvez pas lui donner une liste de sélection - faites simplement DBCC LOGINFO(N'NewDB'); et les numéros de séquence VLF sont dans le FSeqNo colonne du jeu de résultats.
Quoi qu'il en soit, les résultats de l'interrogation de sys.dm_db_log_info étaient :
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Notez que le premier VLF commence au décalage de 8 192 octets dans le fichier journal. En effet, tous les fichiers de base de données, y compris le journal des transactions, ont une page d'en-tête de fichier qui occupe les 8 premiers Ko et stocke diverses métadonnées sur le fichier.
Alors pourquoi SQL Server choisit-il 37 et non 1 pour le premier numéro de séquence VLF ? Il trouve le numéro de séquence VLF le plus élevé dans le model base de données, puis, pour toute nouvelle base de données, le premier VLF du journal des transactions utilise ce numéro plus 1 pour son numéro de séquence. Je ne sais pas pourquoi cet algorithme a été choisi dans la nuit des temps, mais c'est ainsi depuis au moins SQL Server 7.0.
Pour le prouver, j'ai exécuté ce code :
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Et les résultats étaient :
Max_VLF_SeqNo -------------------- 36
Alors voilà.
Il y a plus à discuter des VLF et de leur utilisation, mais pour l'instant, il suffit de savoir que chaque VLF a un numéro de séquence, qui augmente de un pour chaque VLF.
Blocs de journal
Chaque VLF contient un petit en-tête de métadonnées et le reste de l'espace est rempli de blocs de journal. Chaque bloc de journal commence à 512 octets et grandit par incréments de 512 octets jusqu'à une taille maximale de 60 Ko, auquel cas il doit être écrit sur le disque. Un bloc de journal peut être écrit sur le disque avant d'avoir atteint sa taille maximale si l'un des événements suivants se produit :
- Une transaction est validée et la durabilité différée n'est pas utilisée pour cette transaction, donc le bloc de journal doit être écrit sur le disque pour rendre la transaction durable
- La durabilité retardée est utilisée et l'arrière-plan "vider le bloc de journal actuel sur le disque" se déclenche pendant 1 ms
- Une page de fichier de données est en cours d'écriture sur le disque par un point de contrôle ou l'écrivain paresseux, et il y a un ou plusieurs enregistrements de journal dans le bloc de journal actuel qui affectent la page qui est sur le point d'être écrite (rappelez-vous que la journalisation en écriture anticipée doit être garanti)
Vous pouvez considérer un bloc de journal comme quelque chose comme une page de taille variable qui stocke les enregistrements de journal dans l'ordre dans lequel ils sont créés par les transactions modifiant la base de données. Il n'y a pas de bloc de journal pour chaque transaction ; les enregistrements de journal pour plusieurs transactions simultanées peuvent être entremêlés dans un bloc de journal. Vous pourriez penser que cela présenterait des difficultés pour les opérations qui ont besoin de trouver tous les enregistrements de journal pour une seule transaction, mais ce n'est pas le cas, comme je l'expliquerai lorsque je couvrirai le fonctionnement des annulations de transactions dans un article ultérieur.
De plus, lorsqu'un bloc de journal est écrit sur le disque, il est tout à fait possible qu'il contienne des enregistrements de journal de transactions non validées. Ce n'est pas non plus un problème en raison de la façon dont fonctionne la récupération sur incident, ce qui représente quelques bons articles dans la série à venir.
Numéros de séquence de journal
Les blocs de journal ont un ID dans un VLF, commençant à 1 et augmentant de 1 pour chaque nouveau bloc de journal dans le VLF. Les enregistrements de journal ont également un ID dans un bloc de journal, commençant à 1 et augmentant de 1 pour chaque nouvel enregistrement de journal dans le bloc de journal. Ainsi, les trois éléments de la hiérarchie structurelle du journal des transactions ont un identifiant, et ils sont rassemblés dans un identifiant tripartite appelé numéro de séquence du journal , plus communément appelé simplement LSN .
Un LSN est défini comme <VLF sequence number>:<log block ID>:<log record ID> (4 octets :4 octets :2 octets) et identifie de manière unique un seul enregistrement de journal. C'est un identifiant en constante augmentation, car les numéros de séquence VLF augmentent indéfiniment.
Travail préparatoire terminé !
Bien qu'il soit important de connaître les VLF, à mon avis, le LSN est le concept le plus important à comprendre autour de l'implémentation de la journalisation de SQL Server, car les LSN sont la pierre angulaire sur laquelle l'annulation des transactions et la récupération sur incident sont construites, et les LSN apparaîtront encore et encore comme Je progresse dans la série. Dans le prochain article, j'aborderai la troncature du journal et la nature circulaire du journal des transactions, qui concerne uniquement les VLF et la manière dont elles sont réutilisées.