Chez Stack Overflow, nous avons des tables utilisant des index clustered columnstore, et ceux-ci fonctionnent très bien pour la majorité de notre charge de travail. Mais nous avons récemment rencontré une situation où des "tempêtes parfaites" - plusieurs processus essayant tous de supprimer du même CCI - submergeraient le processeur car ils allaient tous largement en parallèle et se battaient pour terminer leur opération. Voici à quoi cela ressemblait dans SolarWinds SQL Sentry :
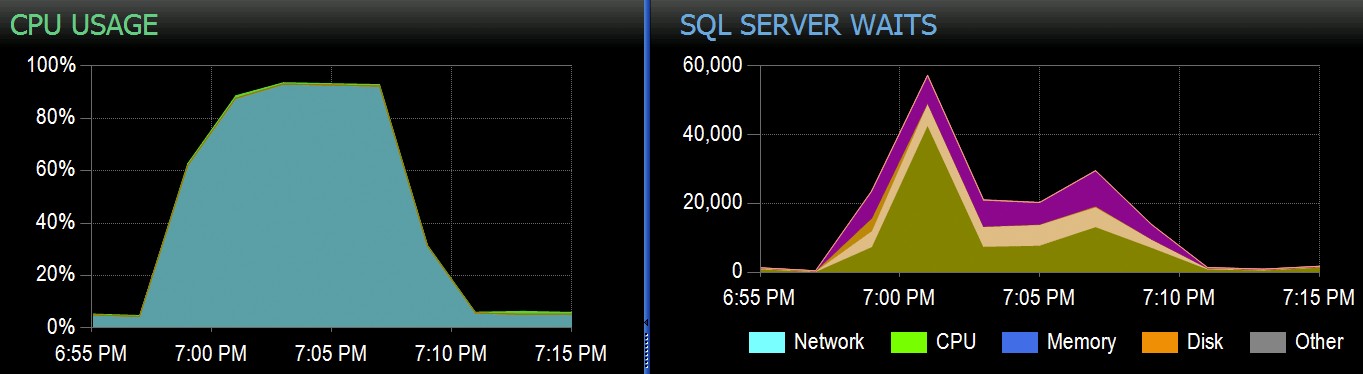
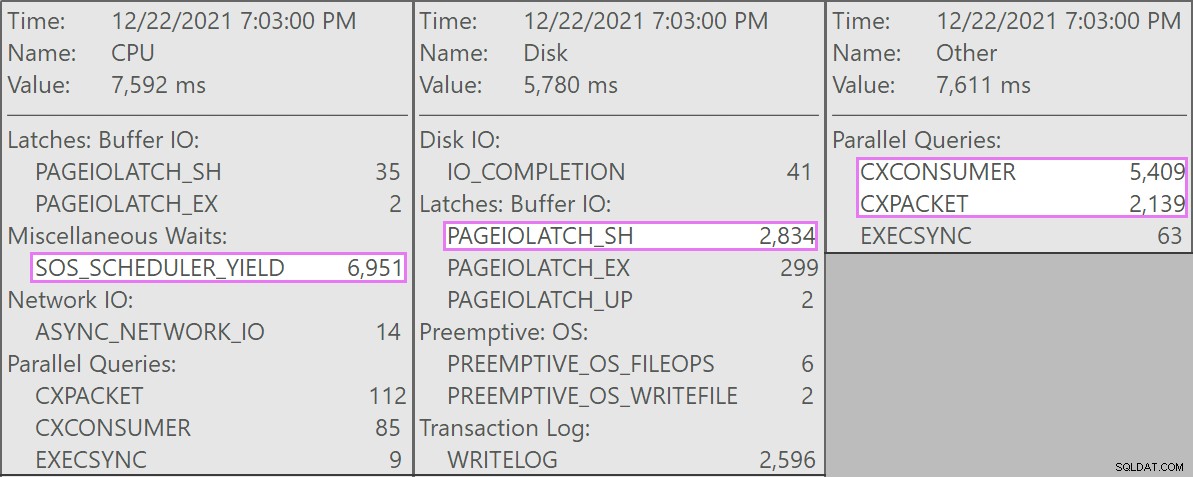
Et voici les temps d'attente intéressants associés à ces requêtes :
Les requêtes en compétition étaient toutes de cette forme :
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Le plan ressemblait à ceci :

Et l'avertissement sur l'analyse nous a informés de certaines E/S résiduelles assez extrêmes :

La table a 1,9 milliard de lignes mais ne fait que 32 Go (merci, stockage en colonnes !). Pourtant, ces suppressions d'une seule ligne prendraient 10 à 15 secondes chacune, la majeure partie de ce temps étant consacrée à SOS_SCHEDULER_YIELD .
Heureusement, étant donné que dans ce scénario, l'opération de suppression pourrait être asynchrone, nous avons pu résoudre le problème avec deux modifications (bien que je simplifie grossièrement ici) :
- Nous avons limité
MAXDOPau niveau de la base de données afin que ces suppressions ne puissent pas être aussi parallèles - Nous avons amélioré la sérialisation des processus provenant de l'application (essentiellement, nous avons mis en file d'attente les suppressions via un seul répartiteur)
En tant que DBA, nous pouvons facilement contrôler MAXDOP , à moins qu'il ne soit remplacé au niveau de la requête (un autre terrier de lapin pour un autre jour). Nous ne pouvons pas nécessairement contrôler l'application dans cette mesure, surtout si elle est distribuée ou non la nôtre. Comment pouvons-nous sérialiser les écritures dans ce cas sans changer radicalement la logique de l'application ?
Une configuration fictive
Je ne vais pas essayer de créer localement une table de deux milliards de lignes - sans parler de la table exacte - mais nous pouvons approximer quelque chose à plus petite échelle et essayer de reproduire le même problème.
Supposons qu'il s'agisse des SuggestedEdits table (en réalité, ce n'est pas le cas). Mais c'est un exemple facile à utiliser car nous pouvons extraire le schéma de l'explorateur de données Stack Exchange. En utilisant cela comme base, nous pouvons créer une table équivalente (avec quelques modifications mineures pour la rendre plus facile à remplir) et lui lancer un index clustered columnstore :
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Pour le remplir avec 100 millions de lignes, nous pouvons croiser la jointure sys.all_objects et sys.all_columns cinq fois (sur mon système, cela produira 2,68 millions de lignes à chaque fois, mais YMMV) :
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Ensuite, nous pouvons vérifier l'espace :
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
C'est seulement 1,3 Go, mais cela devrait suffire :

Imitation de notre suppression clustered Columnstore
Voici une requête simple correspondant à peu près à ce que notre application faisait à la table :
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Le plan n'est pas tout à fait parfait, cependant :
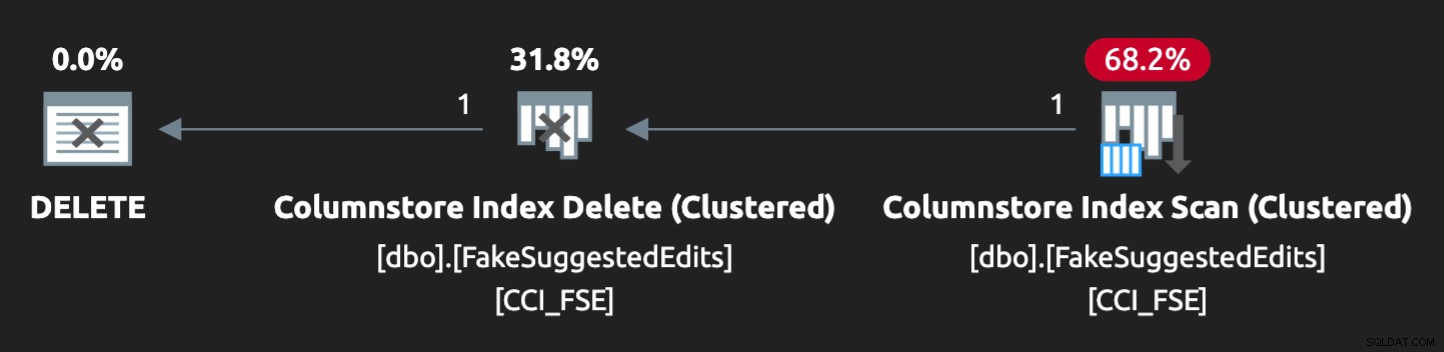
Pour qu'il soit parallèle et produise un conflit similaire sur mon maigre ordinateur portable, j'ai dû forcer un peu l'optimiseur avec cet indice :
OPTION (QUERYTRACEON 8649);
Maintenant, ça a l'air correct :

Reproduire le problème
Ensuite, nous pouvons créer une vague d'activités de suppression simultanées à l'aide de SqlStressCmd pour supprimer 1 000 lignes aléatoires à l'aide de 16 et 32 threads :
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Nous pouvons observer la pression que cela met sur le CPU :
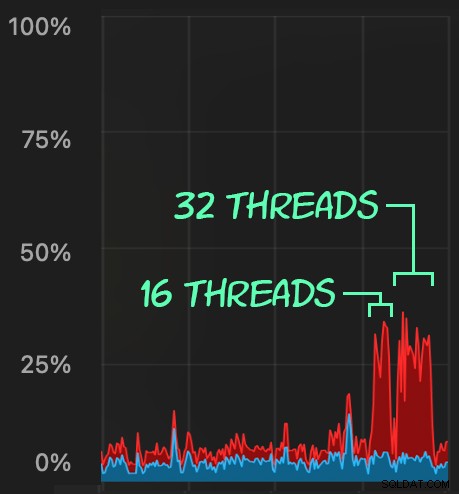
La pression sur le processeur dure tout au long des lots d'environ 64 et 130 secondes, respectivement :
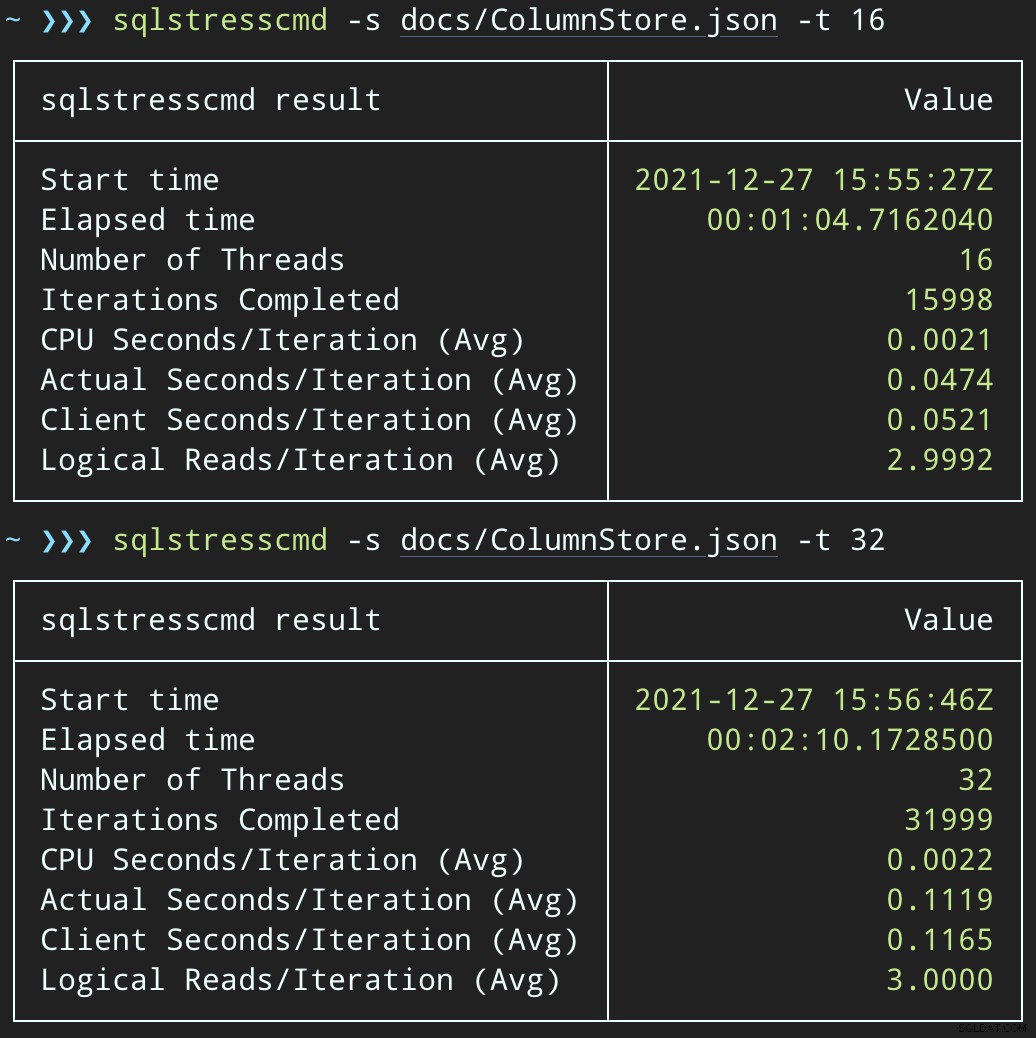
Remarque :La sortie de SQLQueryStress est parfois un peu décalée sur les itérations, mais j'ai confirmé que le travail que vous lui demandez est fait avec précision.
Une solution de contournement potentielle :une file d'attente de suppression
Au départ, j'ai pensé à introduire une table de file d'attente dans la base de données, que nous pourrions utiliser pour décharger l'activité de suppression :
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Tout ce dont nous avons besoin est un déclencheur INSTEAD OF pour intercepter ces suppressions malveillantes provenant de l'application et les placer dans la file d'attente pour un traitement en arrière-plan. Malheureusement, vous ne pouvez pas créer de déclencheur sur une table avec un index columnstore cluster :
Msg 35358, niveau 16, état 1 Envisagez d'appliquer la logique du déclencheur d'une autre manière, ou si vous devez utiliser un déclencheur, utilisez plutôt un tas ou un index B-tree.Nous aurons besoin d'une modification minimale du code de l'application, afin qu'il appelle une procédure stockée pour gérer la suppression :
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Ce n'est pas un état permanent; c'est juste pour garder le même comportement tout en ne changeant qu'une seule chose dans l'application. Une fois que l'application est modifiée et appelle avec succès cette procédure stockée au lieu de soumettre des requêtes de suppression ad hoc, la procédure stockée peut changer :
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Tester l'impact de la file d'attente
Maintenant, si nous modifions SqlQueryStress pour appeler la procédure stockée à la place :
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
Et soumettez des lots similaires (en plaçant 16 000 ou 32 000 lignes dans la file d'attente) :
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
L'impact CPU est légèrement plus élevé :
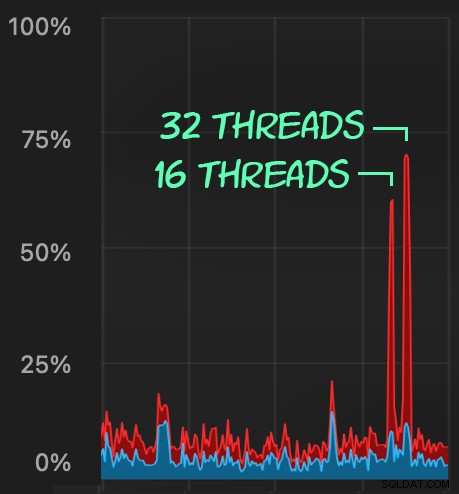
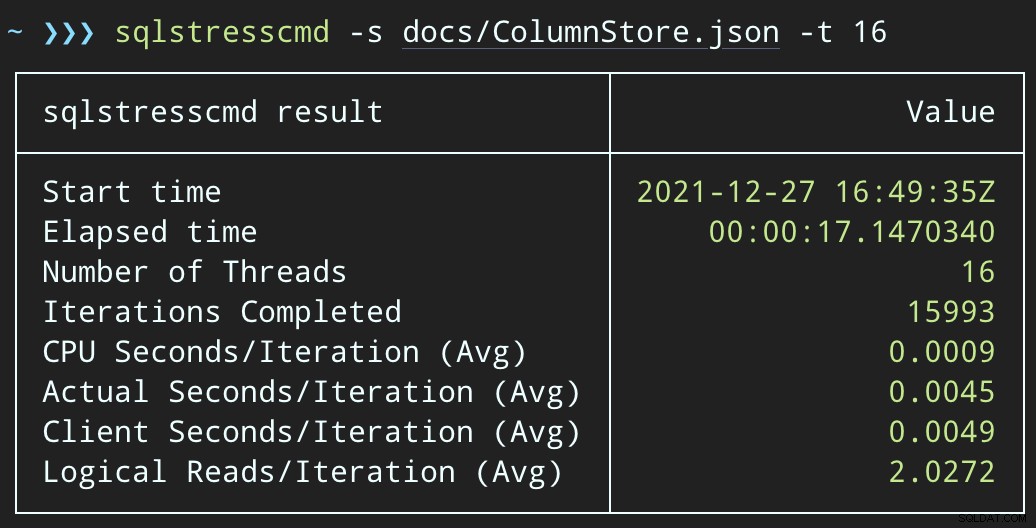
Mais les charges de travail se terminent beaucoup plus rapidement :16 et 23 secondes, respectivement :
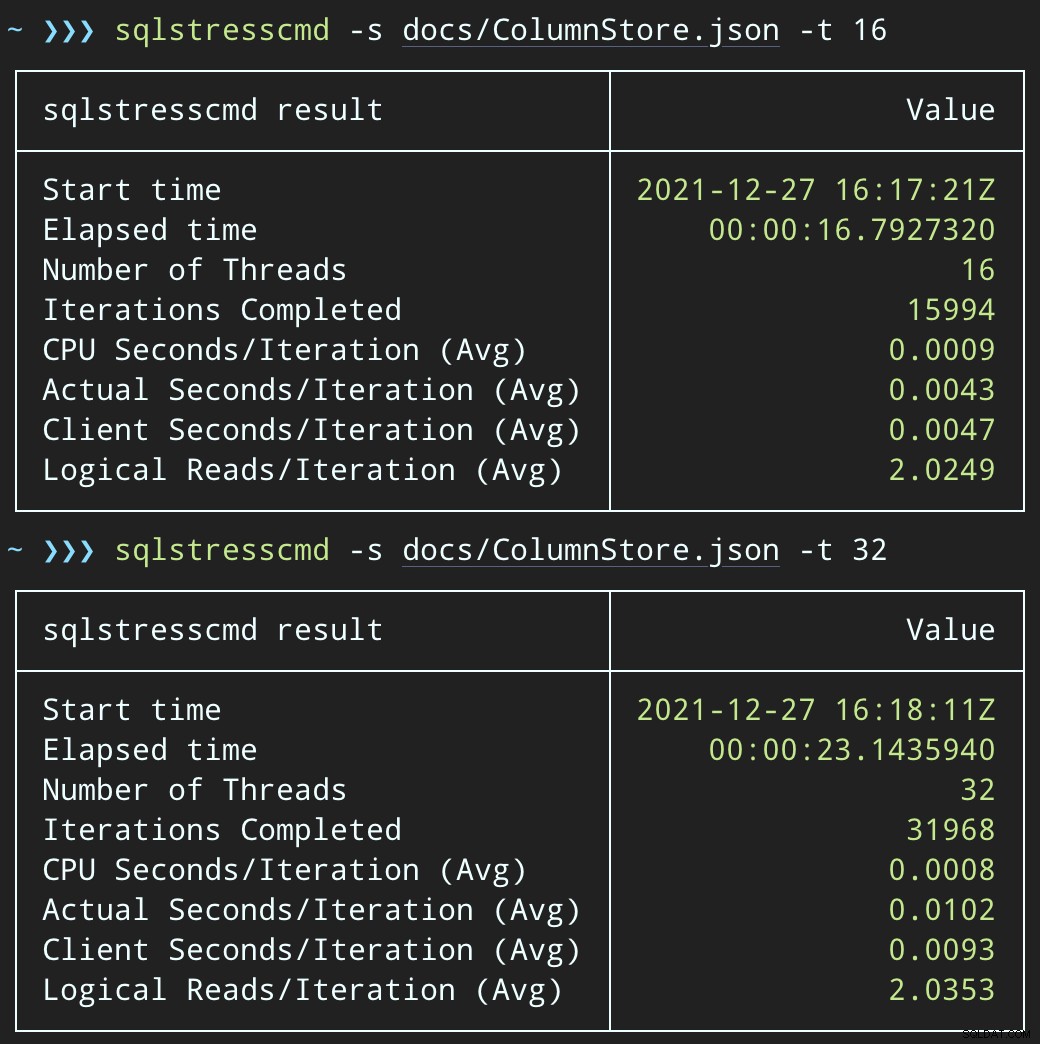
Il s'agit d'une réduction significative de la douleur ressentie par les applications lorsqu'elles entrent dans des périodes de forte simultanéité.
Nous devons encore effectuer la suppression, cependant
Nous devons encore traiter ces suppressions en arrière-plan, mais nous pouvons désormais introduire le traitement par lots et avoir un contrôle total sur le taux et les retards que nous voulons injecter entre les opérations. Voici la structure de base d'une procédure stockée pour traiter la file d'attente (certes sans contrôle transactionnel entièrement acquis, gestion des erreurs ou nettoyage de la table de file d'attente) :
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Maintenant, la suppression de lignes prendra plus de temps - la moyenne pour 10 000 lignes est de 223 secondes, dont environ 100 sont un retard intentionnel. Mais aucun utilisateur n'attend, alors qui s'en soucie ? Le profil CPU est presque nul et l'application peut continuer à ajouter des éléments dans la file d'attente aussi hautement simultanés qu'elle le souhaite, avec presque aucun conflit avec la tâche d'arrière-plan. Lors du traitement de 10 000 lignes, j'ai ajouté 16 000 lignes supplémentaires à la file d'attente, qui utilisait le même processeur qu'auparavant, ce qui ne prenait qu'une seconde de plus que lorsque la tâche n'était pas en cours d'exécution :
Et le plan ressemble maintenant à ceci, avec de bien meilleures lignes estimées/réelles :
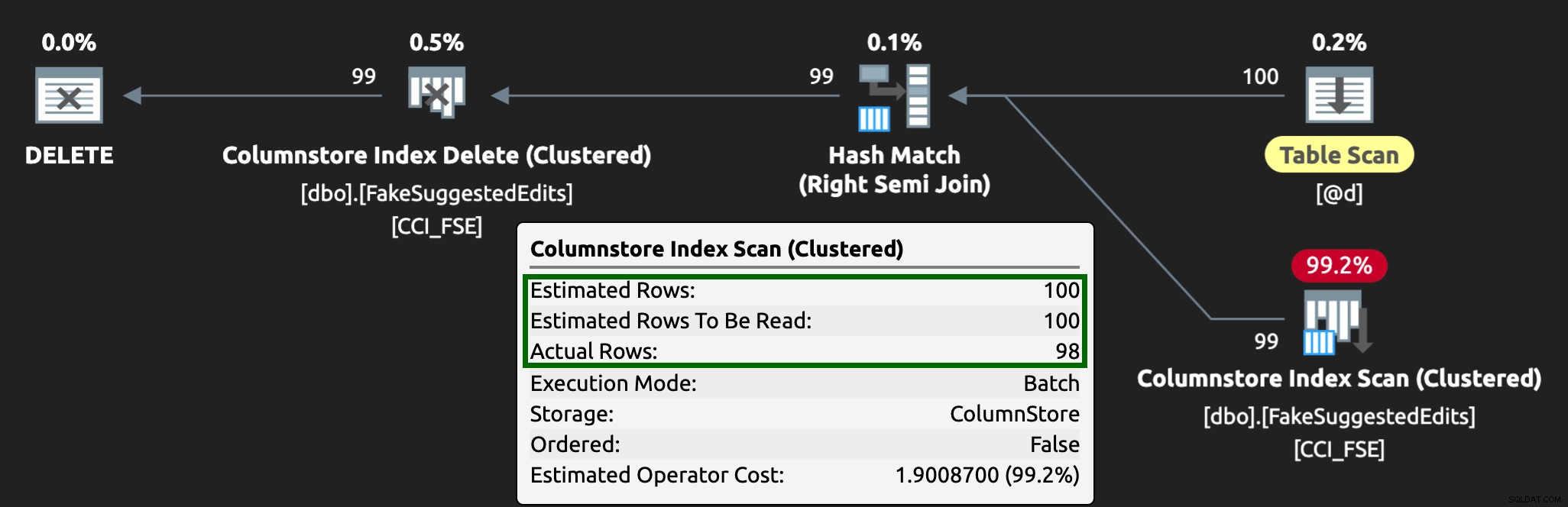
Je peux voir que cette approche de table de file d'attente est un moyen efficace de gérer une concurrence DML élevée, mais elle nécessite au moins un peu de flexibilité avec les applications soumettant DML - c'est l'une des raisons pour lesquelles j'aime vraiment que les applications appellent des procédures stockées, car elles nous donne beaucoup plus de contrôle au plus près des données.
Autres options
Si vous n'avez pas la possibilité de modifier les requêtes de suppression provenant de l'application, ou si vous ne pouvez pas reporter les suppressions à un processus d'arrière-plan, vous pouvez envisager d'autres options pour réduire l'impact des suppressions :
- Un index non clusterisé sur les colonnes de prédicat pour prendre en charge les recherches de points (nous pouvons le faire de manière isolée sans modifier l'application)
- Utilisation des suppressions réversibles uniquement (nécessite toujours des modifications de l'application)
Il sera intéressant de voir si ces options offrent des avantages similaires, mais je les garderai pour un prochain article.