De manière générale, le meilleur type de tri est celui qui est complètement évité. Avec une indexation soignée et parfois une écriture de requête créative, nous pouvons souvent supprimer le besoin d'un opérateur de tri des plans d'exécution. Lorsque les données à trier sont volumineuses, éviter ce type de tri peut produire des améliorations de performances très significatives.
Le deuxième meilleur type de tri est celui que nous ne pouvons pas éviter, mais qui réserve une quantité appropriée de mémoire et en utilise la totalité ou la majeure partie pour faire quelque chose de valable. Être utile peut prendre plusieurs formes. Parfois, un tri peut être plus que rentable en permettant une opération ultérieure qui fonctionne beaucoup plus efficacement sur une entrée triée. D'autres fois, le tri est tout simplement nécessaire, et nous devons simplement le rendre aussi efficace que possible.
Viennent ensuite les types que nous voulons généralement éviter :ceux qui réservent beaucoup plus de mémoire qu'ils n'en ont besoin et ceux qui en réservent trop peu. Ce dernier cas est celui sur lequel la plupart des gens se concentrent. Avec une mémoire réservée (ou disponible) insuffisante pour terminer l'opération de tri requise en mémoire, un opérateur de tri va, à quelques exceptions près, renverser les lignes de données vers tempdb . En réalité, cela signifie presque toujours écrire des pages de tri dans un stockage physique (et les relire plus tard bien sûr).
Dans les versions modernes de SQL Server, un tri renversé entraîne une icône d'avertissement dans les plans de post-exécution, qui peut inclure des détails concernant la quantité de données renversées, le nombre de threads impliqués et le niveau de déversement.
Contexte :Niveaux de déversement
Considérez la tâche de trier 4000 Mo de données, alors que nous n'avons que 500 Mo de mémoire disponible. Évidemment, nous ne pouvons pas trier tout l'ensemble en mémoire en une seule fois, mais nous pouvons décomposer la tâche :
Nous lisons d'abord 500 Mo de données, trions cet ensemble en mémoire, puis écrivons le résultat sur le disque. Effectuer cela 8 fois au total consomme la totalité de l'entrée de 4 000 Mo, ce qui donne 8 ensembles de données triées d'une taille de 500 Mo. La deuxième étape consiste à effectuer une fusion à 8 voies des ensembles de données triés. Notez qu'une fusion est nécessaire, et non une simple concaténation des ensembles puisque les données ne sont garanties d'être triées que comme requis dans un ensemble particulier de 500 Mo à l'étape intermédiaire.
En principe, nous pourrions lire et fusionner une ligne à la fois à partir de chacun des huit tris, mais cela ne serait pas très efficace. Au lieu de cela, nous lisons la première partie de chaque tri exécuté en mémoire, disons 60 Mo. Cela consomme 8 x 60 Mo =480 Mo sur les 500 Mo dont nous disposons. Nous pouvons ensuite effectuer efficacement la fusion à 8 voies en mémoire pendant un certain temps, en mettant en mémoire tampon la sortie triée finale avec la mémoire de 20 Mo encore disponible. Au fur et à mesure que chacun des tampons de mémoire d'exécution de tri se vide, nous lisons une nouvelle section de cette exécution de tri dans la mémoire. Une fois que toutes les exécutions de tri ont été consommées, le tri est terminé.
Il y a quelques détails et optimisations supplémentaires que nous pouvons inclure, mais c'est le schéma de base d'un déversement de niveau 1, également connu sous le nom de déversement à passage unique. Un seul passage supplémentaire sur les données est nécessaire pour produire la sortie triée finale.
Maintenant, une fusion à n voies pourrait théoriquement accueillir une sorte de n'importe quelle taille, dans n'importe quelle quantité de mémoire, simplement en augmentant le nombre d'ensembles intermédiaires triés localement. Le problème est qu'à mesure que 'n' augmente, nous finissons par lire et écrire de plus petits morceaux de données. Par exemple, trier 400 Go de données dans 500 Mo de mémoire signifierait quelque chose comme une fusion à 800 voies, avec seulement environ 0,6 Mo de chaque ensemble trié intermédiaire en mémoire à tout moment (800 x 0,6 Mo =480 Mo, laissant un peu d'espace pour un tampon de sortie).
Plusieurs passes de fusion peuvent être utilisées pour contourner ce problème. L'idée générale est de fusionner progressivement de petits morceaux en plus grands, jusqu'à ce que nous puissions produire efficacement le flux de sortie trié final. Dans l'exemple, cela peut signifier fusionner 40 des 800 ensembles triés de premier passage à la fois, ce qui donne 20 morceaux plus grands, qui peuvent ensuite être fusionnés à nouveau pour former la sortie. Avec un total de deux passages supplémentaires sur les données, il s'agirait d'un déversement de niveau 2, et ainsi de suite. Heureusement, une augmentation linéaire du niveau de déversement permet une augmentation exponentielle de la taille du tri, de sorte que des niveaux de déversement de tri en profondeur sont rarement nécessaires.
Le déversement "Niveau 15 000"
À ce stade, vous vous demandez peut-être quelle combinaison de petite allocation de mémoire et d'énorme taille de données pourrait éventuellement entraîner un débordement de tri de niveau 15 000. Vous essayez de trier tout Internet dans 1 Mo de mémoire ? Peut-être, mais c'est beaucoup trop difficile à démontrer. Pour être honnête, je n'ai aucune idée si un niveau de déversement aussi élevé est même possible dans SQL Server. Le but ici (une triche, bien sûr) est d'amener SQL Server à signaler un déversement de niveau 15 000.
L'ingrédient clé est le partitionnement. Depuis SQL Server 2012, nous avons été autorisés à un maximum (pratique) de 15 000 partitions par objet (la prise en charge de 15 000 partitions est également disponible sur 2008 SP2 et 2008 R2 SP1, mais vous devez l'activer manuellement par base de données et être conscient de tous les mises en garde).
La première chose dont nous aurons besoin est une fonction de partition de 15 000 éléments et un schéma de partition associé. Pour éviter un bloc de code en ligne vraiment énorme, le script suivant utilise SQL dynamique pour générer les instructions requises :
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Le script est assez facile à modifier en un nombre inférieur au cas où votre configuration se débattrait avec 15 000 partitions (en particulier du point de vue de la mémoire, comme nous le verrons bientôt). Les étapes suivantes consistent à créer une table de tas normale (non partitionnée) avec une seule colonne d'entiers, puis à la remplir avec les entiers de 1 à 15 000 inclus :
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Cela devrait se terminer en 100 ms environ. Si vous disposez d'un tableau de nombres, n'hésitez pas à l'utiliser à la place pour une expérience plus basée sur les ensembles. La manière dont la table de base est remplie n'a pas d'importance. Pour obtenir notre déversement de niveau 15 000, il nous suffit maintenant de créer un index clusterisé partitionné sur la table :
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Le temps d'exécution dépend beaucoup du système de stockage utilisé. Sur mon ordinateur portable, en utilisant un SSD grand public assez typique d'il y a quelques années, cela prend environ 20 secondes, ce qui est assez important étant donné que nous n'avons affaire qu'à 15 000 lignes au total. Sur une machine virtuelle Azure aux spécifications assez basses avec des performances d'E/S assez terribles, le même test a duré près de 20 minutes.
Analyse
Le plan d'exécution pour la construction de l'index est :
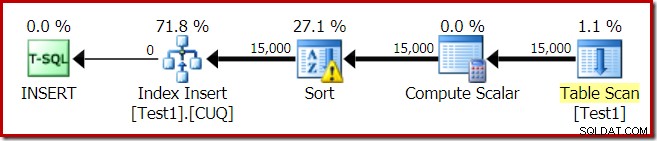
Le balayage de table lit les 15 000 lignes de notre table de tas. Le Compute Scalar calcule le numéro de partition d'index de destination pour chaque ligne à l'aide de la fonction interne RangePartitionNew() . Le tri est la partie la plus intéressante du plan, nous allons donc l'examiner plus en détail.
Tout d'abord, l'avertissement de tri, tel qu'affiché dans Plan Explorer :

Un avertissement similaire de SSMS (tiré d'une exécution différente du script) :
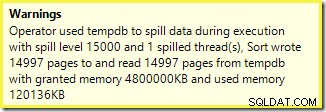
La première chose à noter est le rapport d'un niveau de déversement de 15 000 sortes, comme promis. Ce n'est pas tout à fait exact, mais les détails sont assez intéressants. Le tri dans ce plan a un Partition ID propriété, qui n'est normalement pas présente :
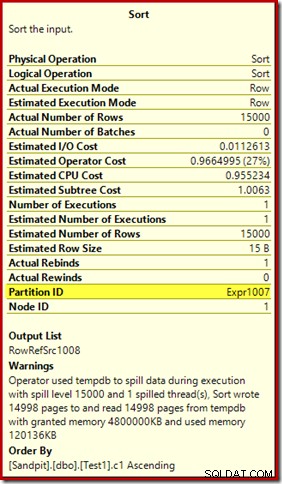
Cette propriété est égale à la définition de la fonction de partitionnement interne dans le Compute Scalar.
Il s'agit d'une construction d'index non aligné , car la source et la destination ont des arrangements de partitionnement différents. Dans ce cas, cette différence se produit car la table de tas source n'est pas partitionnée, mais l'index de destination l'est. En conséquence, 15 000 tris distincts sont créés au moment de l'exécution :un par partition cible non vide. Chacun de ces tris déborde au niveau 1, et SQL Server additionne tous ces débordements pour donner le niveau de débordement de tri final de 15 000.
Les 15 000 tris distincts expliquent l'importante allocation de mémoire. Chaque instance de tri a une taille minimale de 40 pages, soit 40 x 8 Ko =320 Ko. Les 15 000 tris nécessitent donc au minimum 15 000 x 320 Ko =4 800 000 Ko de mémoire. C'est un peu moins de 4,6 Go de RAM réservés exclusivement à une requête qui trie 15 000 lignes contenant une seule colonne entière. Et chaque tri se répand sur le disque, bien qu'il ne reçoive qu'une seule ligne ! Si le parallélisme était utilisé pour la construction de l'index, l'allocation de mémoire pourrait être encore gonflée par le nombre de threads. Notez également que la ligne unique est écrite dans une page, ce qui explique le nombre de pages écrites et lues à partir de tempdb. Il semble y avoir une condition de concurrence qui signifie que le nombre de pages signalé est souvent inférieur à 15 000.
Cet exemple reflète un cas limite, bien sûr, mais il est toujours difficile de comprendre pourquoi chaque tri renverse sa seule ligne au lieu de trier dans la mémoire qui lui a été donnée. Peut-être que c'est par conception pour une raison quelconque, ou peut-être que c'est simplement un bogue. Quoi qu'il en soit, il est toujours assez amusant de voir une sorte de quelques centaines de Ko de données prendre si longtemps avec une allocation de mémoire de 4,6 Go et un déversement de 15 000 niveaux. À moins que vous ne le rencontriez dans un environnement de production, peut-être. Quoi qu'il en soit, c'est quelque chose dont il faut être conscient.
Le rapport trompeur de déversement de niveau 15 000 se résume en grande partie aux limitations de représentation dans la sortie du plan de spectacle. Le problème fondamental est quelque chose qui se pose dans de nombreux endroits où des actions répétées se produisent, par exemple sur le côté intérieur de la jointure des boucles imbriquées. Il serait certainement utile de pouvoir voir une ventilation plus précise au lieu d'un total global dans ces cas. Au fil du temps, ce domaine s'est un peu amélioré, nous avons donc maintenant plus d'informations de plan par thread ou par partition pour certaines opérations. Il reste encore un long chemin à parcourir.
Il n'est toujours pas utile que 15 000 déversements distincts de niveau 1 soient signalés ici comme un seul déversement de niveau 15 000.
Variantes de test
Cet article vise davantage à mettre en évidence les limitations des informations de plan et le potentiel de performances médiocres lorsqu'un nombre extrême de partitions est utilisé, qu'à rendre l'opération d'exemple particulière plus efficace, mais il y a quelques variations intéressantes que je souhaite également examiner. .
En ligne, Trier dans tempdb
Effectuer la même opération de création d'index partitionné avec ONLINE = ON, SORT_IN_TEMPDB = ON ne souffre pas de la même allocation de mémoire énorme et du même débordement :
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Notez que l'utilisation de ONLINE à lui seul n'est pas suffisant. En fait, cela se traduit par le même plan qu'avant avec tous les mêmes problèmes, plus une surcharge supplémentaire pour la création de chaque partition d'index en ligne. Pour moi, cela se traduit par un temps d'exécution de plus d'une minute. Dieu sait combien de temps cela prendrait sur une instance Azure à faible spécification avec des performances d'E/S épouvantables.
Quoi qu'il en soit, le plan d'exécution avec ONLINE = ON, SORT_IN_TEMPDB = ON est :

Le tri est effectué avant le calcul du numéro de partition de destination. Il n'a pas la propriété Partition ID, il s'agit donc simplement d'un tri normal. L'ensemble de l'opération dure une dizaine de secondes (il reste encore beaucoup de partitions à créer). Il réserve moins de 3 Mo de mémoire et utilise un maximum de 816 Ko. Une nette amélioration par rapport à 4,6 Go et 15 000 déversements.
Indexez d'abord, puis les données
Des résultats similaires peuvent être obtenus en écrivant d'abord les données dans une table de tas :
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Ensuite, créez une table en cluster partitionnée vide et insérez les données du tas :
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Cela prend environ dix secondes, avec une allocation de mémoire de 2 Mo et sans débordement :
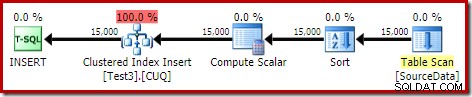
Bien sûr, le tri pourrait également être complètement évité en indexant la table source (non partitionnée) et en insérant les données dans l'ordre de l'index (le meilleur tri est de ne pas trier du tout, rappelez-vous).
Tas partitionné, puis données, puis index
Pour cette dernière variante, nous créons d'abord un tas partitionné et chargeons les 15 000 lignes de test :
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Ce script s'exécute pendant une seconde ou deux, ce qui est plutôt bien. La dernière étape consiste à créer l'index clusterisé partitionné :
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
C'est un désastre complet, à la fois du point de vue des performances et du point de vue des informations sur le plan du spectacle. L'opération elle-même dure un peu moins d'une minute, avec le plan d'exécution suivant :

Il s'agit d'un plan d'insertion colocalisé. L'analyse constante contient une ligne pour chaque ID de partition. Le côté intérieur de la boucle recherche la partition actuelle du tas (oui, une recherche sur un tas). Le tri a une propriété d'identifiant de partition (bien que celle-ci soit constante par itération de boucle), il y a donc un tri par partition et le comportement de débordement indésirable. L'avertissement de statistiques sur la table de tas est fallacieux.
La racine du plan d'insertion indique qu'une allocation de mémoire de 1 Mo a été réservée, avec un maximum de 144 Ko utilisés :
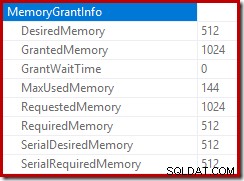
L'opérateur de tri ne signale pas un débordement de niveau 15 000, mais autrement, il fait un gâchis complet des calculs d'itération par boucle impliqués :

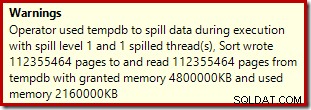
La surveillance des allocations de mémoire DMV pendant l'exécution montre que cette requête ne réserve en fait que 1 Mo, avec un maximum de 144 Ko utilisés à chaque itération de la boucle. (En revanche, la réservation de mémoire de 4,6 Go lors du premier test est absolument authentique.) C'est déroutant, bien sûr.
Le problème (comme mentionné précédemment) est que SQL Server est confus quant à la meilleure façon de signaler ce qui s'est passé au cours de nombreuses itérations. Il n'est probablement pas pratique d'inclure des informations sur les performances du plan par partition et par itération, mais il est indéniable que l'arrangement actuel produit parfois des résultats déroutants. Nous ne pouvons qu'espérer trouver un jour une meilleure façon de rapporter ce type d'informations, dans un format plus cohérent.



