Deux graves vulnérabilités de sécurité (nom de code Meltdown et Spectre) ont été révélées il y a quelques semaines. Les premiers tests ont suggéré que l'impact sur les performances des atténuations (ajoutées dans le noyau) pourrait atteindre environ 30 % pour certaines charges de travail, en fonction du taux d'appel système.
Ces premières estimations devaient être faites rapidement et étaient donc basées sur un nombre limité de tests. De plus, les correctifs intégrés au noyau ont évolué et se sont améliorés au fil du temps, et nous avons maintenant également retpoline qui devrait traiter Spectre v2. Cet article présente des données provenant de tests plus approfondis, en espérant fournir des estimations plus fiables pour les charges de travail PostgreSQL typiques.
Par rapport à la première évaluation des correctifs de Meltdown que Simon a publiée le 10 janvier, les données présentées dans cet article sont plus détaillées, mais correspondent en général aux résultats présentés dans cet article.
Cet article est axé sur les charges de travail PostgreSQL, et bien qu'il puisse être utile pour d'autres systèmes avec des taux de commutation syscall/contexte élevés, il n'est certainement pas universellement applicable. Si vous êtes intéressé par une explication plus générale des vulnérabilités et de l'évaluation de l'impact, Brendan Gregg a publié il y a quelques jours un excellent article KPTI/KAISER Meltdown Initial Performance Regressions. En fait, il pourrait être utile de le lire d'abord, puis de continuer avec cet article.
Remarque : Cet article n'a pas pour but de vous décourager d'installer les correctifs, mais de vous donner une idée de l'impact potentiel sur les performances. Vous devez installer tous les correctifs afin que votre environnement soit sécurisé et utiliser ce message pour décider si vous devez mettre à niveau le matériel, etc.
Quels tests ferons-nous ?
Nous examinerons deux types de charge de travail de base habituels :OLTP (petites transactions simples) et OLAP (requêtes complexes traitant de grandes quantités de données). La plupart des systèmes PostgreSQL peuvent être modélisés comme un mélange de ces deux types de charge de travail.
Pour OLTP, nous avons utilisé pgbench, un outil d'analyse comparative bien connu fourni avec PostgreSQL. Nous avons testé les deux en lecture seule (-S ) et lecture-écriture (-N ) modes, avec trois échelles différentes - s'adaptant aux tampons_partagés, à la RAM et plus grande que la RAM.
Pour le cas OLAP, nous avons utilisé le benchmark dbt-3, qui est assez proche de TPC-H, avec deux tailles de données différentes :10 Go qui tiennent dans la RAM et 50 Go qui est plus grand que la RAM (compte tenu des index, etc.).
Tous les chiffres présentés proviennent d'un serveur avec 2x Xeon E5-2620v4, 64 Go de RAM et Intel SSD 750 (400 Go). Le système exécutait Gentoo avec le noyau 4.15.3, compilé avec GCC 7.3 (nécessaire pour activer le retpoline complet réparer). Les mêmes tests ont également été effectués sur un système plus ancien/plus petit avec un processeur i5-2500k, 8 Go de RAM et 6x Intel S3700 SSD (en RAID-0). Mais le comportement et les conclusions sont à peu près les mêmes, nous n'allons donc pas présenter les données ici.
Comme d'habitude, les scripts/résultats complets pour les deux systèmes sont disponibles sur github.
Cet article traite de l'impact de l'atténuation sur les performances. Ne nous concentrons donc pas sur les chiffres absolus et examinons plutôt les performances par rapport au système non corrigé (sans les atténuations du noyau). Tous les graphiques de la section OLTP affichent
(throughput with patches) / (throughput without patches)
Nous attendons des chiffres compris entre 0 % et 100 %, les valeurs les plus élevées étant meilleures (impact moindre des mesures d'atténuation), 100 % signifiant "aucun impact".
Remarque : L'axe des ordonnées commence à 75 %, pour rendre les différences plus visibles.
OLTP / lecture seule
Voyons d'abord les résultats pour pgbench en lecture seule, exécuté par cette commande
pgbench -n -c 16 -j 16 -S -T 1800 test
et illustré par le tableau suivant :
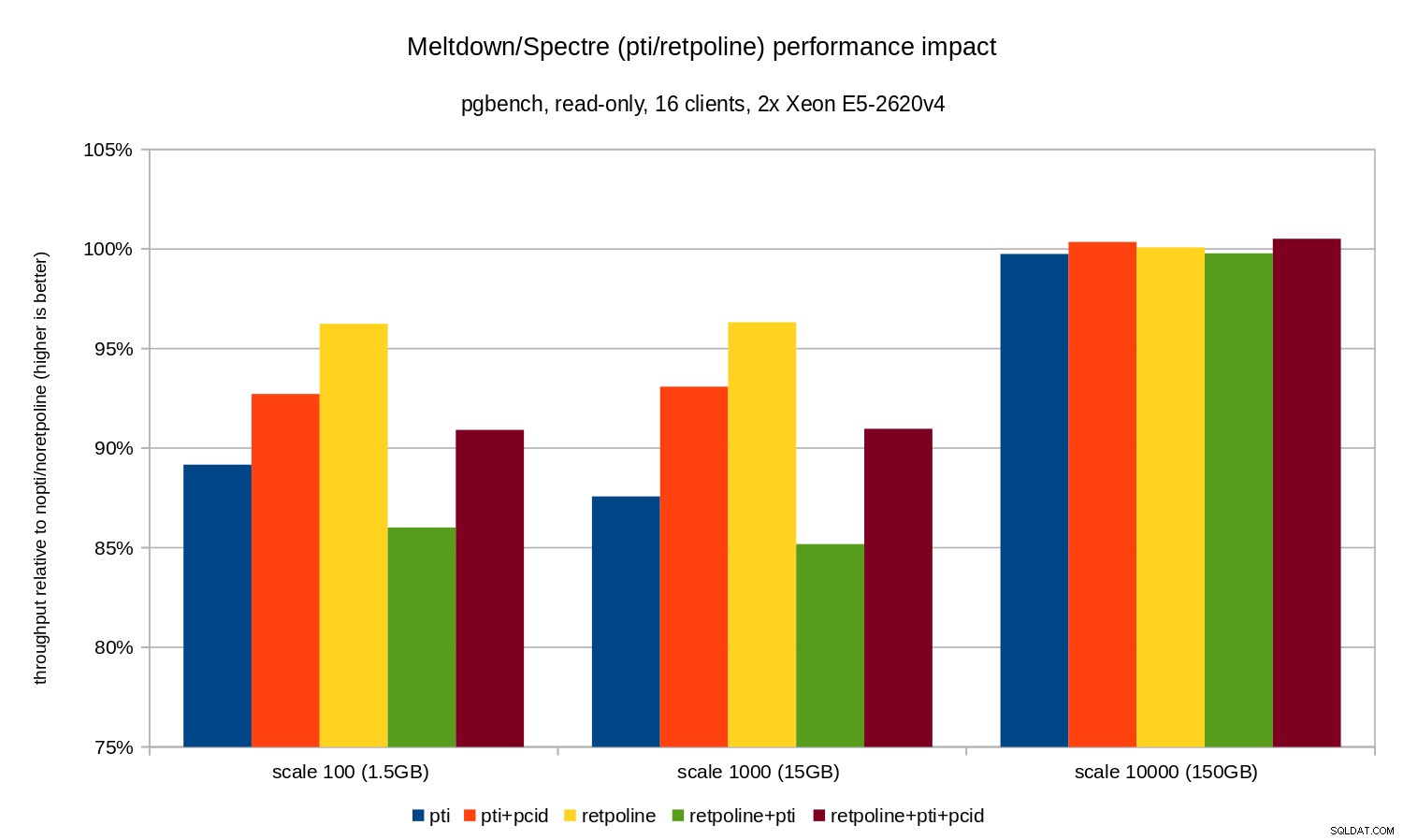
Comme vous pouvez le constater, l'impact sur les performances de pti pour les échelles qui tiennent dans la mémoire est d'environ 10 à 12 % et presque non mesurable lorsque la charge de travail devient liée aux E/S. De plus, la régression est considérablement réduite (ou disparaît entièrement) lorsque pcid est autorisé. Ceci est cohérent avec l'affirmation selon laquelle le PCID est désormais une fonctionnalité critique de performance/sécurité sur x86. L'impact de retpoline est beaucoup plus petit - moins de 4 % dans le pire des cas, ce qui peut facilement être dû au bruit.
OLTP / lecture-écriture
Les tests de lecture-écriture ont été effectués par un pgbench commande similaire à celle-ci :
pgbench -n -c 16 -j 16 -N -T 3600 test
La durée était suffisamment longue pour couvrir plusieurs points de contrôle, et -N a été utilisé pour éliminer les conflits de verrouillage sur les lignes de la (petite) table de branches. La performance relative est illustrée par ce graphique :
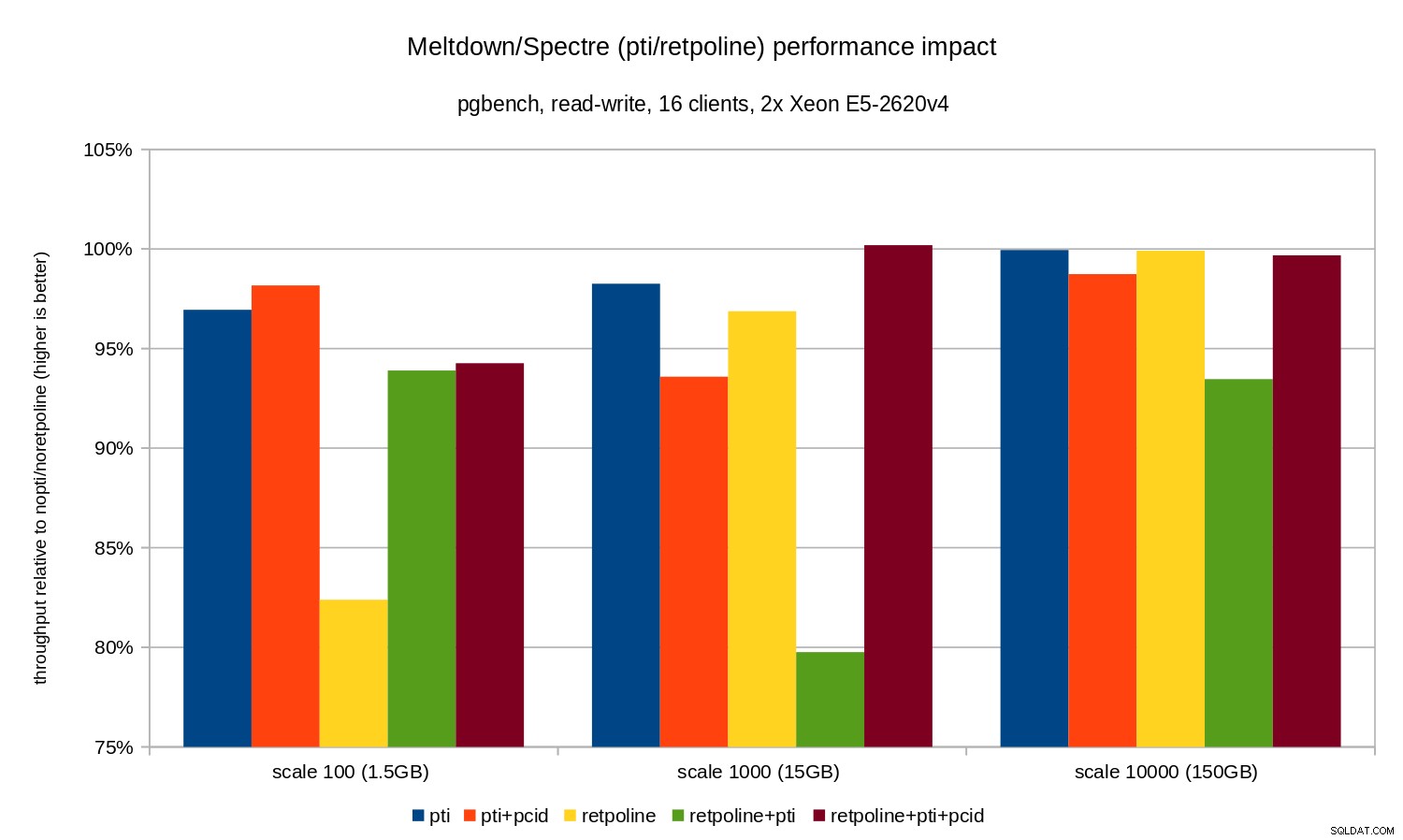
Les régressions sont un peu plus petites que dans le cas en lecture seule - moins de 8 % sans pcid et moins de 3 % avec pcid activé. C'est une conséquence naturelle de passer plus de temps à effectuer des E/S tout en écrivant des données dans WAL, en vidant les tampons modifiés pendant le point de contrôle, etc.
Il y a cependant deux éléments étranges. Tout d'abord, l'impact de retpoline est étonnamment grand (près de 20 %) pour l'échelle 100, et la même chose s'est produite pour retpoline+pti à l'échelle 1000. Les raisons ne sont pas tout à fait claires et nécessiteront une enquête supplémentaire.
OLAP
La charge de travail analytique a été modélisée par le benchmark dbt-3. Tout d'abord, regardons les résultats à l'échelle 10 Go, qui s'intègrent entièrement dans la RAM (y compris tous les index, etc.). Comme pour OLTP, nous ne sommes pas vraiment intéressés par les nombres absolus, qui dans ce cas seraient la durée des requêtes individuelles. Au lieu de cela, nous examinerons le ralentissement par rapport au nopti/noretpoline , c'est-à-dire :
(duration without patches) / (duration with patches)
En supposant que les atténuations entraînent un ralentissement, nous obtiendrons des valeurs comprises entre 0 % et 100 %, où 100 % signifie "aucun impact". Les résultats ressemblent à ceci :
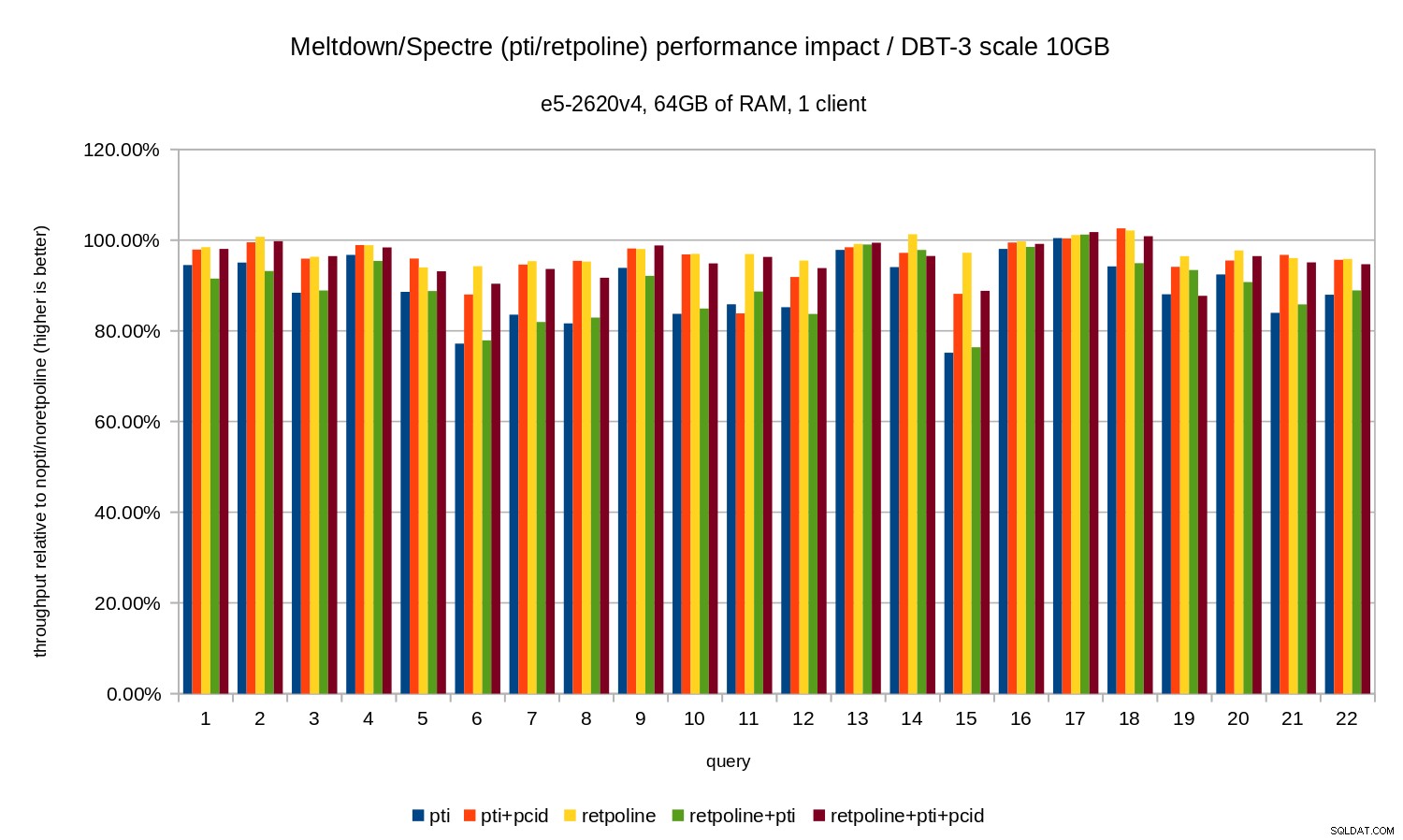
Autrement dit, sans le pcid la régression est généralement comprise entre 10 et 20 %, selon la requête. Et avec pcid la régression tombe à moins de 5 % (et généralement proche de 0 %). Une fois de plus, cela confirme l'importance de pcid fonctionnalité.
Pour l'ensemble de données de 50 Go (soit environ 120 Go avec tous les index, etc.), l'impact ressemble à ceci :
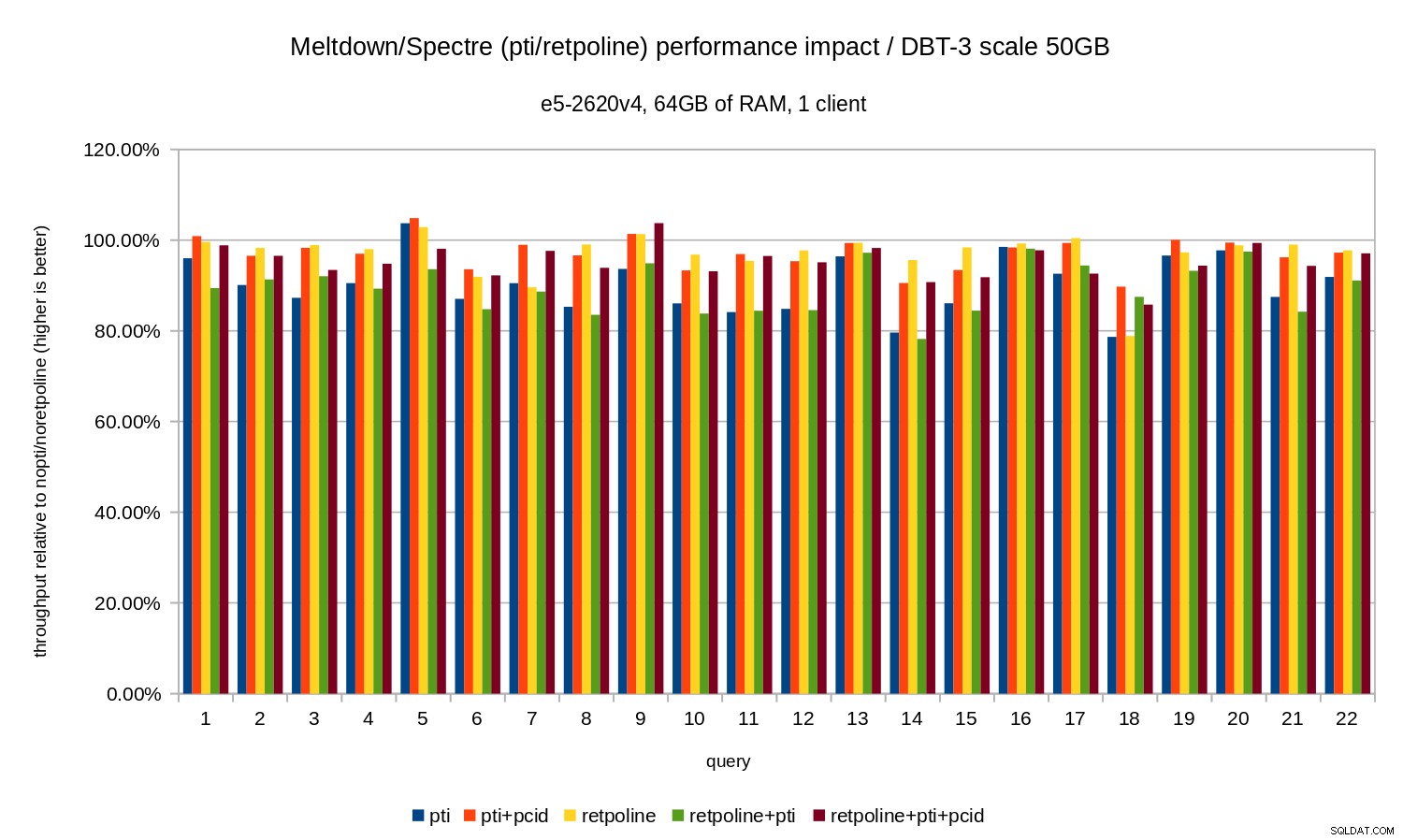
Donc, tout comme dans le cas de 10 Go, les régressions sont inférieures à 20 % et pcid les réduit considérablement - près de 0 % dans la plupart des cas.
Les graphiques précédents sont un peu encombrés - il y a 22 requêtes et 5 séries de données, ce qui est un peu trop pour un seul graphique. Voici donc un graphique montrant l'impact uniquement pour les trois fonctionnalités (pti , pcid et retpoline ), pour les deux tailles d'ensemble de données.
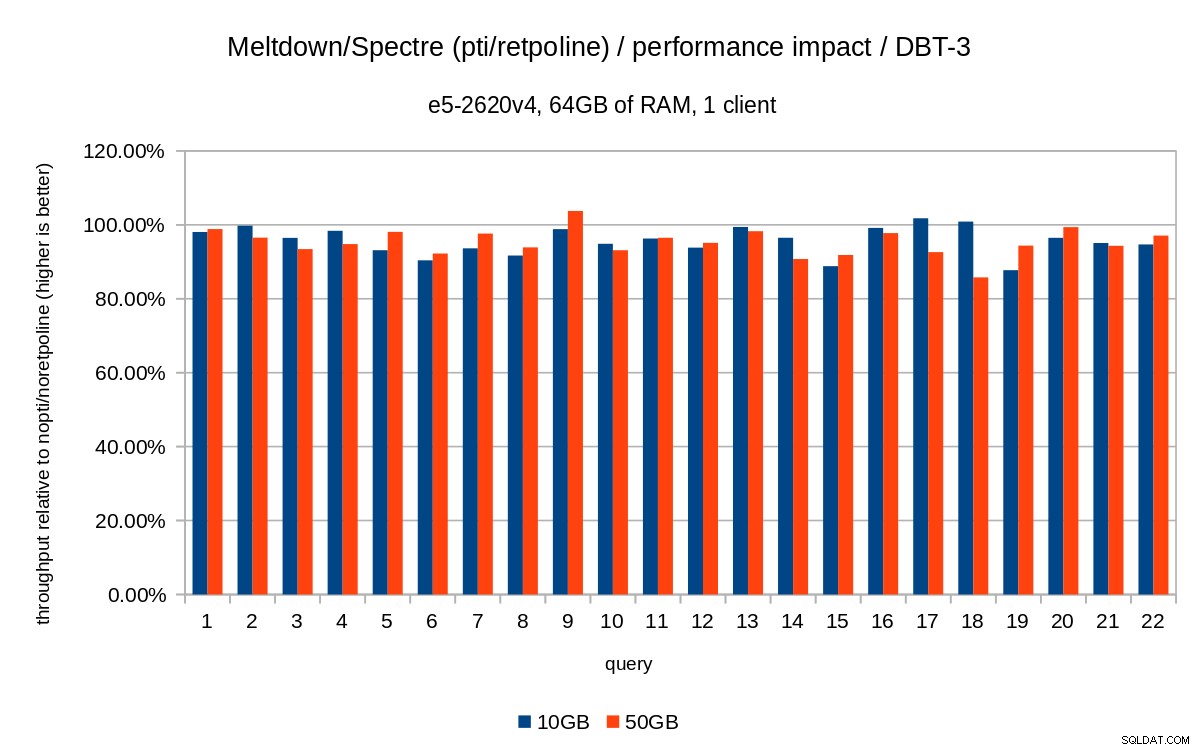
Conclusion
Pour résumer brièvement les résultats :
retpolinea très peu d'impact sur les performances- OLTP :la régression est d'environ 10 à 15 % sans le
pcid, et environ 1 à 5 % avecpcid. - OLAP :la régression peut atteindre 20 % sans le
pcid, et environ 1 à 5 % avecpcid. - Pour les charges de travail liées aux E/S (par exemple, OLTP avec le plus grand ensemble de données), Meltdown a un impact négligeable.
L'impact semble bien inférieur aux estimations initiales (30 %), du moins pour les charges de travail testées. De nombreux systèmes fonctionnent à 70-80 % du processeur pendant les périodes de pointe, et les 30 % satureraient complètement la capacité du processeur. Mais en pratique l'impact semble être inférieur à 5 %, du moins lorsque le pcid option est utilisée.
Ne vous méprenez pas, une baisse de 5% est toujours une grave régression. C'est certainement quelque chose dont nous nous soucierions pendant le développement de PostgreSQL, par ex. lors de l'évaluation de l'impact des correctifs proposés. Mais c'est quelque chose que les systèmes existants devraient très bien gérer - si une augmentation de 5 % de l'utilisation du processeur fait passer votre système à la limite, vous avez des problèmes même sans Meltdown/Spectre.
De toute évidence, ce n'est pas la fin des correctifs Meltdown/Spectre. Les développeurs du noyau travaillent toujours à l'amélioration des protections et à l'ajout de nouvelles, et Intel et d'autres fabricants de processeurs travaillent sur les mises à jour du microcode. Et ce n'est pas comme si nous connaissions toutes les variantes possibles des vulnérabilités, car les chercheurs ont réussi à trouver de nouvelles variantes des attaques.
Il y a donc plus à venir et il sera intéressant de voir quel sera l'impact sur les performances.