Percona XtraDB Cluster est une solution de haute disponibilité très connue dans le monde MySQL. Il est basé sur Galera Cluster et fournit une réplication virtuellement synchrone sur plusieurs nœuds. Comme pour toute base de données, il est crucial de garder une trace de ce qui se passe dans le système, si les performances sont aux niveaux attendus et, si ce n'est pas le cas, quel est le goulot d'étranglement. Ceci est de la plus haute importance pour pouvoir réagir correctement dans la situation où les performances sont affectées. Bien sûr, Percona XtraDB Cluster est livré avec plusieurs métriques et il n'est pas toujours clair lesquelles sont les plus importantes pour suivre l'état de la base de données. Dans ce blog, nous discuterons de quelques mesures clés que vous souhaitez surveiller lorsque vous travaillez avec PXC.
Pour être clair, nous nous concentrerons sur les métriques propres à PXC et Galera, nous ne couvrirons pas les métriques pour MySQL ou InnoDB. Ces statistiques ont été abordées dans nos blogs précédents.
Regardons quelques-unes des informations les plus importantes que PXC nous présente.
Contrôle de flux
Le contrôle de flux est à peu près la métrique la plus importante que vous puissiez surveiller dans n'importe quel cluster Galera. Parlons donc un peu en arrière-plan. Galera est un cluster multimaître virtuellement synchrone. Il est possible d'exécuter des écritures sur n'importe lequel des nœuds de base de données qui le composent. Chaque écriture doit être envoyée à tous les nœuds du cluster pour s'assurer qu'elle peut être appliquée - ce processus s'appelle la certification. Aucune transaction ne peut être appliquée tant que tous les nœuds n'ont pas convenu qu'elle peut être validée. Si l'un des nœuds a des problèmes de performances qui le rendent incapable de faire face au trafic, il commencera à émettre des messages de contrôle de flux destinés à informer le reste du cluster des problèmes de performances et à leur demander de réduire la charge de travail et d'aider les retardataires. nœud pour rattraper le reste du cluster.
Vous pouvez suivre le moment où les nœuds ont dû introduire une pause artificielle pour permettre à leurs homologues en retard de rattraper leur retard à l'aide de la métrique de mise en pause du contrôle de flux (wsrep_flow_control_paused) :

Vous pouvez également suivre si le nœud envoie ou reçoit les messages de contrôle de flux (wsrep_flow_control_recv et wsrep_flow_control_sent).
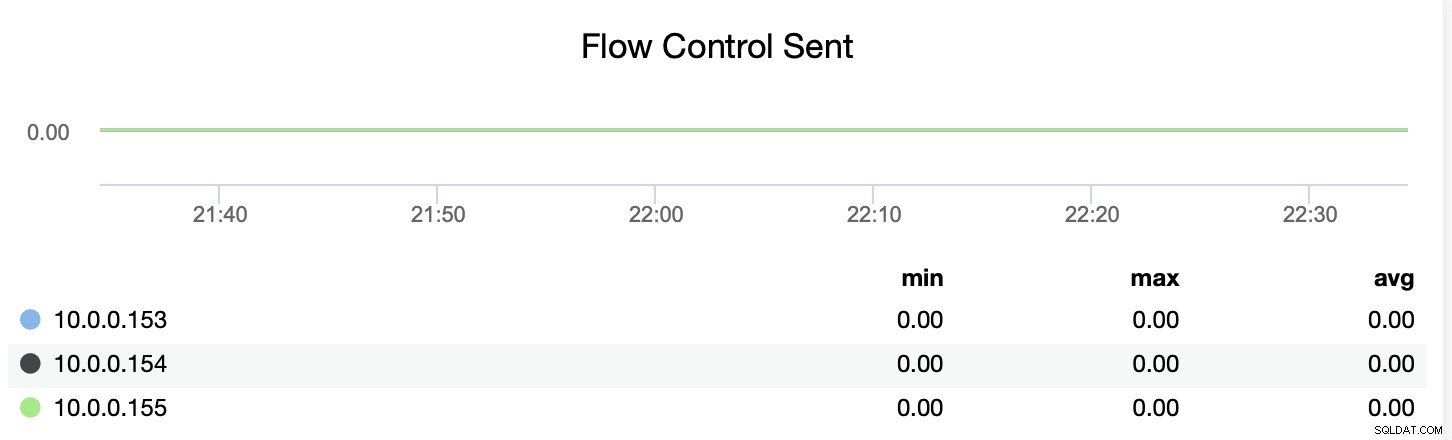
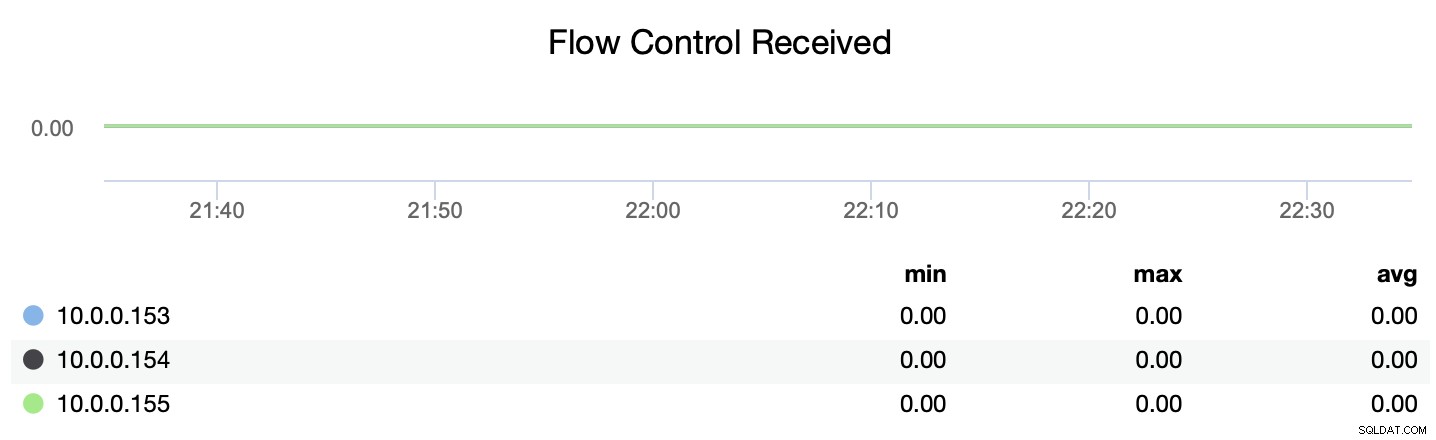
Ces informations vous aideront à mieux comprendre quel nœud ne fonctionne pas sur le même niveau que ses pairs. Vous pouvez ensuite vous concentrer sur ce nœud et essayer de comprendre quel est le problème et comment supprimer le goulot d'étranglement.
Envoyer et recevoir des files d'attente
Ces métriques sont en quelque sorte liées au contrôle de flux. Comme nous l'avons vu, un nœud peut être en retard par rapport aux autres nœuds du cluster. Cela peut être dû à une répartition inégale de la charge de travail ou à d'autres raisons (certains processus s'exécutant en arrière-plan, une sauvegarde ou certaines requêtes lourdes personnalisées). Avant que le contrôle de flux ne démarre, les nœuds en retard tenteront de stocker les ensembles d'écritures entrants dans la file d'attente de réception (wsrep_local_recv_queue) en espérant que l'impact sur les performances est transitoire et qu'il pourra rattraper son retard très bientôt. Ce n'est que si la file d'attente devient trop grande (elle est régie par le paramètre gcs.fc_limit) que les messages de contrôle de flux commencent à être envoyés à travers le cluster.

Vous pouvez considérer une file d'attente de réception comme le premier marqueur qui montre qu'il il y a des problèmes de performances et le contrôle de flux peut se déclencher.

D'autre part, la file d'attente d'envoi (wsrep_local_send_queue) vous indiquera que le nœud n'est pas en mesure d'envoyer les jeux d'écriture aux autres membres du cluster, ce qui peut indiquer des problèmes de connectivité réseau (poussant les jeux d'écriture vers le réseau n'est pas vraiment gourmand en ressources).
Métriques de parallélisation
Le cluster Percona XtraDB peut être configuré pour utiliser plusieurs threads pour appliquer les jeux d'écriture entrants - cela lui permet de mieux gérer plusieurs threads se connectant au cluster et émettant des écritures en même temps. Il y a deux métriques principales sur lesquelles vous voudrez peut-être garder un œil.
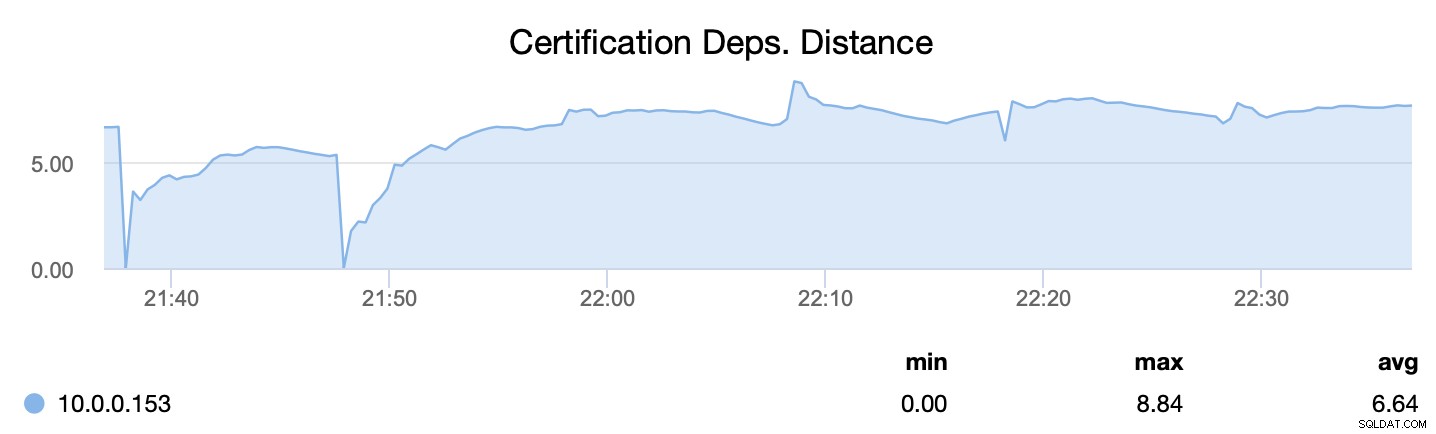
Tout d'abord, wsrep_cert_deps_distance, nous indique quel est le potentiel de parallélisation - combien de jeux d'écriture peuvent, potentiellement, être appliqués en même temps. En fonction de cette valeur, vous pouvez configurer le nombre de threads esclaves parallèles (wsrep_slave_threads) qui fonctionneront sur l'application des jeux d'écriture entrants. La règle générale est qu'il est inutile de configurer plus de threads que la valeur de wsrep_cert_deps_distance.
Deuxième métrique, d'autre part, nous indique avec quelle efficacité nous avons pu paralléliser le processus d'application des jeux d'écriture - wsrep_apply_oooe nous indique à quelle fréquence l'applicateur a commencé à appliquer des jeux d'écriture dans le désordre (ce qui indique une meilleure parallélisation ).
Conclusion
Comme vous pouvez le voir, il y a quelques métriques qui valent la peine d'être examinées dans Percona XtraDB Cluster. Bien sûr, comme nous l'avons indiqué au début de ce blog, ce sont des métriques strictement liées à PXC et Galera Cluster en général.
Vous devez également garder un œil sur les métriques MySQL et InnoDB régulières pour mieux comprendre l'état de votre base de données. Et n'oubliez pas que vous pouvez surveiller cette technologie gratuitement à l'aide de ClusterControl Community Edition.