J'ai déjà écrit sur les avantages de l'utilisation de NOEXPAND conseils, même dans Enterprise Edition. Les détails sont tous dans l'article lié, mais pour résumer brièvement :
- SQL Server ne fera que créer automatiquement statistiques sur une vue indexée lorsqu'un
NOEXPANDl'indice de table est utilisé. L'omission de cet indice peut entraîner des avertissements de plan d'exécution concernant des statistiques manquantes qui ne peuvent pas être résolus en créant des statistiques manuellement. - SQL Server n'utilisera que statistiques de vue créées automatiquement ou manuellement dans les calculs d'estimation de cardinalité lorsque la requête référence directement la vue et un
NOEXPANDl'indice est utilisé. Pour toutes les définitions de vue, sauf les plus triviales, cela signifie que la qualité des estimations de cardinalité est susceptible d'être inférieure lorsque cet indice n'est pas utilisé, ce qui entraîne souvent des plans d'exécution moins optimaux. - L'absence ou l'impossibilité d'utiliser des statistiques d'affichage peut amener l'optimiseur à deviner les estimations de cardinalité, même lorsque des statistiques de table de base sont disponibles. Cela peut se produire lorsqu'une partie du plan de requête est remplacée par une référence de vue indexée par la fonction de mise en correspondance automatique des vues, mais que les statistiques de vue ne sont pas disponibles, comme décrit ci-dessus.
Il y a une autre conséquence de ne pas utiliser le NOEXPAND indice, que j'ai mentionné en passant il y a quelques années dans mon article, Optimizer Limitations with Filtered Indexes :
Le
NOEXPANDdes conseils sont nécessaires même dans Enterprise Edition pour s'assurer que la garantie d'unicité fournie par les index de vue est utilisée par l'optimiseur.
Cet article examine cette déclaration et ses implications plus en détail.
Configuration de la démo
Le script suivant crée une table simple et une vue indexée :
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Cela crée une table de tas de colonne unique et une vue illimitée de la même table avec un index clusterisé unique. Ceci n'est pas destiné à être un cas d'utilisation réaliste pour une vue indexée ; mais cela aidera à illustrer les points clés avec le minimum de distractions. Le point important est que la table de base ici n'a aucun index (pas même un index clusterisé) mais la vue en a un, et cet index est unique.
L'exemple de requête
Considérez la requête simple suivante sur la table de base :
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Le plan d'exécution que vous verrez pour cette requête dépend de l'édition de SQL Server utilisée. Si ce n'est pas Enterprise Edition (ou équivalent), vous verrez un plan comme celui-ci :

L'optimiseur de requête SQL Server a choisi d'analyser la table de base et d'appliquer la distinction spécifiée à l'aide d'un opérateur Distinct Sort. Cette forme de plan est parfaitement attendue, car la correspondance automatique des vues indexées n'est pas disponible en dehors de Enterprise Edition. Je vais arrêter de dire "Enterprise Edition ou équivalent" à partir de maintenant, mais continuez à déduire que je veux dire toute édition qui prend en charge la correspondance automatique des vues lorsque je dis "Enterprise Edition" à partir de maintenant.
L'astuce EXPAND VIEWS
C'est un peu un aparté, mais pour obtenir le même plan sur Enterprise Edition, nous devons utiliser un EXPAND VIEWS indice de requête :
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Il peut sembler un peu étrange d'utiliser cet indice lorsqu'il n'y a aucune référence de vue dans la requête, mais c'est ainsi que cela fonctionne. Les EXPAND VIEWS hint spécifie effectivement que la correspondance de vue indexée doit être désactivée lors de la compilation et de l'optimisation de la requête. Pour être clair :sans cet indice, Enterprise Edition peut faire correspondre (des parties de) la requête à une ou plusieurs vues indexées.
Avec la correspondance automatique des vues activée
Sans EXPAND VIEWS indice, compiler la même requête sur Developer Edition (par exemple) produit un plan différent :
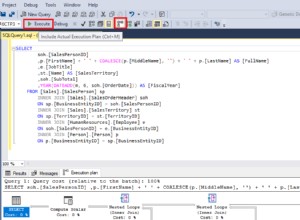
L'application de la correspondance des vues indexées signifie que le plan d'exécution comporte une analyse de l'index clusterisé de la vue au lieu d'une analyse de la table de base.
Le même plan est produit dans ce cas si la requête référence directement la vue (au lieu de la table de base) :
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; Dans toutes les éditions, la référence de la vue est développée avant le début de l'optimisation des requêtes. Dans les éditions équivalentes à Enterprise, le formulaire développé peut être associé ultérieurement à la vue. Il s'agit d'un concept clé à comprendre lorsque l'on réfléchit à la manière dont le compilateur et l'optimiseur de requêtes utilisent les vues indexées dans SQL Server.
L'agrégat de flux
La différence la plus intéressante entre les deux plans que nous avons vus jusqu'à présent est le Stream Aggregate dans le plan correspondant à la vue. Si vous regardez les coûts estimés des opérateurs Table Scan et View Scan, vous verrez qu'ils sont exactement les mêmes. L'optimiseur n'a pas décidé d'utiliser la vue indexée car cela rendait l'accès aux données moins cher. Au lieu de cela, la numérisation de l'index de vue permet le DISTINCT exigence d'être implémenté en tant que Stream Aggregate, plutôt qu'un Hash Aggregate ou Distinct Sort (comme dans le premier plan).
Un Stream Aggregate nécessite une entrée triée par colonne(s) de regroupement. Dans ce cas, le distinct équivaut à un regroupement par colonne unique, et l'index clusterisé unique de la vue fournit la garantie de classement nécessaire. Le modèle de coût de l'optimiseur identifie le Stream Aggregate comme une option moins chère qu'un Distinct Sort ou Hash Aggregate pour cette requête. C'est sur cette base que l'optimiseur choisit d'accéder à la vue indexée lorsque la correspondance automatique des vues est disponible.
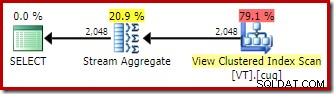
Avec tout cela dit et compris, le Stream Aggregate est encore inattendu :étant donné la garantie d'unicité fournie par l'index de vue, il n'est pas du tout nécessaire d'effectuer cette opération de regroupement. L'unique l'index clusterisé garantit déjà que la colonne ne contient pas de doublons.
Voilà, en un mot, le problème. Lorsque la correspondance automatique des vues est utilisée, l'optimiseur reconnaît la garantie de classement fournie par l'index de vue, mais pas la garantie d'unicité.
Utilisation d'un indice NOEXPAND
Pour obtenir le plan d'exécution idéal pour cette requête, nous devons référencer directement la vue et utiliser un NOEXPAND indice de tableau :
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Cela nous donne le plan auquel s'attendrait une personne expérimentée en matière de bases de données ; une qui reconnaît correctement que l'opération distincte est redondante et peut être supprimée :
Un deuxième exemple
Ne pas profiter de la garantie d'unicité fournie par un index de vue peut avoir d'autres effets sur le plan d'exécution final. Considérons maintenant une auto-jointure de la vue indexée (encore une fois, juste pour illustrer un concept - ceci n'est pas destiné à être une requête réaliste) :
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
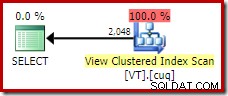
ON V2.col1 = V1.col1; Avec Developer Edition, le plan d'exécution choisi n'accède pas du tout à la vue indexée et comporte une jointure par hachage (parfois une indication qu'un index utile est manquant) :
Essayons maintenant exactement la même requête, mais avec un NOEXPAND indice sur chaque référence de vue :
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
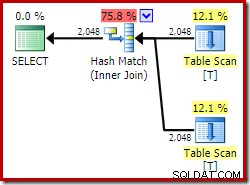
ON V2.col1 = V1.col1; Le plan d'exécution comporte désormais deux accès aux vues indexées et une jointure par fusion :
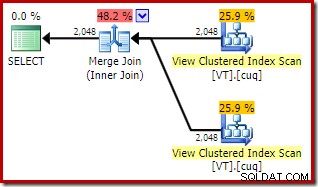
Ce nouveau plan a un coût estimé beaucoup plus bas que le plan de jointure par hachage, alors pourquoi l'optimiseur n'a-t-il pas choisi cette option auparavant ? Nous pouvons comprendre pourquoi en ajoutant un indice de jointure de fusion à la requête d'origine :
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Cela donne un aspect similaire plan qui choisit d'accéder à la vue même si NOEXPAND n'a pas été spécifié :
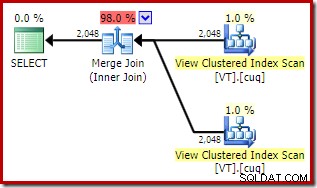
Le coût global estimé de ce plan est supérieur aux deux exemples précédents. La jointure de fusion dans ce plan représente également une proportion plus élevée du coût total estimé qu'auparavant (98 % contre 48,2 %).
La raison en est visible en examinant les propriétés de la jointure de fusion. Dans le NOEXPAND plan, c'était une jointure de fusion un-à-plusieurs. Dans le plan ci-dessus, il s'agit d'une jointure de fusion plusieurs-à-plusieurs. Le modèle de coût de l'optimiseur attribue un coût plus élevé aux jointures de fusion plusieurs-à-plusieurs, car une table de travail tempdb est nécessaire pour gérer les doublons.
Conclusion
Les garanties apportées par un index unique peuvent être un puissant outil d'optimisation, il est donc dommage que la mise en correspondance automatique des index ne puisse actuellement pas en tirer profit. Les avantages potentiels vont au-delà de l'élimination des agrégations inutiles ou de l'activation d'une jointure de fusion un-à-plusieurs, comme le montrent les exemples simples précédents. En général, il peut être difficile de repérer qu'un plan d'exécution est sous-optimal parce que l'optimiseur n'a pas profité d'une garantie d'unicité.
Cette limitation de l'optimiseur ne s'applique pas uniquement à l'index cluster unique qu'une vue doit avoir pour être matérialisée. Dans des scénarios plus complexes, des index non cluster supplémentaires peuvent également être présents sur la vue; peut-être pour refléter des relations entre tables difficiles à appliquer ou à représenter autrement. Si ces index non clusterisés sont définis comme étant uniques, l'optimiseur négligera également ces garanties si la correspondance automatique d'index est utilisée.
En ajoutant cela aux limitations concernant la création et l'utilisation d'informations statistiques, il semble que s'appuyer sur la correspondance automatique des vues peut entraîner des plans d'exécution inférieurs. L'option la plus sûre est probablement de référencer explicitement les vues indexées et d'utiliser un NOEXPAND indice à chaque fois - au moins jusqu'à ce que ces problèmes soient résolus dans le produit.
Facteurs atténuants
Je dois souligner que le problème décrit dans cet article ne s'applique qu'à la garantie d'unicité fournie par un index de vue unique. Si l'optimiseur peut obtenir les informations d'unicité requises d'une autre manière , il y a de bonnes chances que les problèmes d'optimisation soient évités.
Par exemple, il peut y avoir un index unique approprié sur une table de base référencée par la vue. Ou, dans le cas d'une vue contenant une agrégation, l'optimiseur peut déjà déduire une garantie d'unicité utile à partir du GROUP BY de la vue. clause. La pratique courante consistant à ajouter un index clusterisé de vue aux clés de regroupement n'ajoute aucune information d'unicité supplémentaire dans ce cas.
Néanmoins, il y a des moments où cette "surveillance de l'unicité" peut signifier que vous obtiendrez des plans d'exécution de meilleure qualité en utilisant une référence de vue explicite et NOEXPAND conseils, même dans Enterprise Edition.