Les vues indexées peuvent être créées dans n'importe quelle édition de SQL Server, mais il existe un certain nombre de comportements à prendre en compte si vous souhaitez en tirer le meilleur parti.
Les statistiques automatiques nécessitent un indice NOEXPAND
SQL Server peut créer automatiquement des statistiques pour faciliter l'estimation de la cardinalité et la prise de décision basée sur les coûts lors de l'optimisation des requêtes. Cette fonctionnalité fonctionne avec les vues indexées ainsi que les tables de base, mais uniquement si la vue est explicitement nommée dans la requête et le NOEXPAND indice est spécifié. (Il y a toujours un objet statistique associé à chaque index sur une vue, c'est la génération et la maintenance automatique des statistiques non associées à un index dont nous parlons ici.)
Si vous avez l'habitude de travailler avec des éditions non Enterprise de SQL Server, vous n'avez peut-être jamais remarqué ce comportement auparavant. Les éditions inférieures de SQL Server nécessitent le NOEXPAND indice pour produire un plan de requête qui accède à une vue indexée. Lorsque NOEXPAND est spécifié, des statistiques automatiques sont créées sur les vues indexées exactement comme cela se produit avec les tables ordinaires.
Exemple – Édition Standard avec NOEXPAND
À l'aide de SQL Server 2012 Standard Edition et de l'exemple de base de données Adventure Works, nous créons d'abord une vue qui joint deux tables de ventes et calcule la quantité totale de commande par client et produit :
CREATE VIEW dbo.CustomerOrders
WITH SCHEMABINDING AS
SELECT
SOH.CustomerID,
SOD.ProductID,
OrderQty = SUM(SOD.OrderQty),
NumRows = COUNT_BIG(*)
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY
SOH.CustomerID,
SOD.ProductID; Pour que cette vue prenne en charge les statistiques, nous devons la matérialiser en ajoutant un index clusterisé unique. La combinaison de l'ID client et de l'ID produit est garantie d'être unique dans la vue (par définition), nous l'utiliserons donc comme clé. Nous pourrions spécifier les deux colonnes dans les deux sens dans l'index, mais en supposant que nous nous attendions à ce que davantage de requêtes soient filtrées par produit, nous faisons de Product ID la colonne principale. Cette action crée également des statistiques d'index, avec un histogramme construit à partir des valeurs d'ID de produit.
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.CustomerOrders (ProductID, CustomerID);
On nous demande maintenant d'écrire une requête qui montre la quantité totale de commandes par client, pour une gamme particulière de produits. Nous nous attendons à ce qu'un plan d'exécution utilisant la vue indexée soit une stratégie efficace, car il évitera une jointure et fonctionnera sur des données déjà partiellement agrégées. Puisque nous utilisons SQL Server Standard Edition, nous devons spécifier explicitement la vue et utiliser un NOEXPAND indice pour produire un plan de requête qui accède à la vue indexée :
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
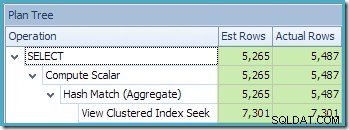
CO.CustomerID; Le plan d'exécution produit montre une recherche sur la vue indexée pour trouver des lignes pour les produits d'intérêt suivi d'une agrégation pour calculer la quantité totale par client :
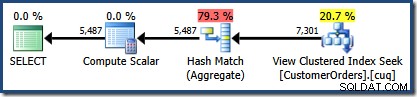
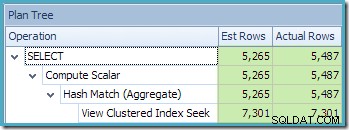
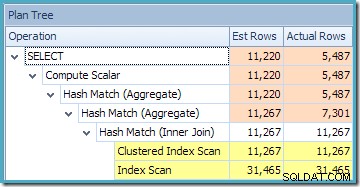
La vue Arborescence du plan de SQL Sentry Plan Explorer montre que l'estimation de la cardinalité est tout à fait correcte pour la recherche de vue indexée et très bonne pour le résultat de l'agrégat :
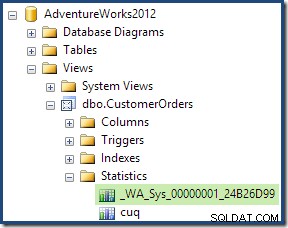
Dans le cadre du processus de compilation et d'optimisation de cette requête, SQL Server a créé un objet de statistiques supplémentaire dans la colonne ID client de la vue indexée. Cette statistique est créée car le nombre et la distribution attendus d'ID client peuvent être importants, par exemple lors du choix d'une stratégie d'agrégation. Nous pouvons voir la nouvelle statistique à l'aide de l'Explorateur d'objets de Management Studio :
Un double-clic sur l'objet de statistiques confirme qu'il a été créé à partir de la colonne Customer ID de la vue (et non d'une table de base) :
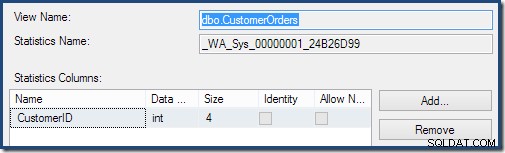
Les vues indexées peuvent améliorer l'estimation de la cardinalité
Toujours en utilisant l'édition Standard, nous supprimons et recréons maintenant la vue indexée (qui supprime également les statistiques de la vue) et exécutons à nouveau la requête, cette fois avec le NOEXPAND indice commenté :
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
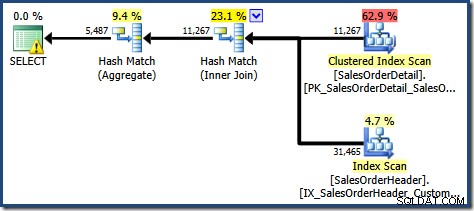
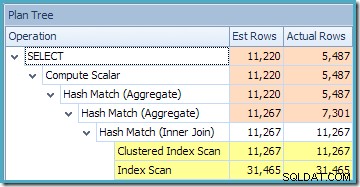
Comme prévu lors de l'utilisation de l'édition Standard sans NOEXPAND , le plan de requête résultant opère sur les tables de base plutôt que sur la vue directement :

Le triangle d'avertissement sur l'opérateur racine dans le plan ci-dessus nous alerte sur un index potentiellement utile sur la table Sales Order Detail, qui n'est pas important pour nos besoins actuels. Cette compilation ne crée aucune statistique sur la vue indexée. La seule statistique sur la vue après compilation de la requête est celle associée à l'index cluster :
La vue Arborescence du plan pour la requête montre que l'estimation de la cardinalité est correcte pour les deux parcours de table et la jointure, mais un peu moins bonne pour les autres opérateurs de plan :
Utilisation de la vue indexée avec un NOEXPAND indice a permis d'obtenir des estimations plus précises pour notre requête de test, car des informations de meilleure qualité étaient disponibles à partir des statistiques sur la vue, en particulier les statistiques associées à l'index de vue.
En règle générale, la précision des informations statistiques se dégrade assez rapidement au fur et à mesure de leur passage et est modifiée par les opérateurs du plan de requête. Les jointures simples ne sont souvent pas trop mauvaises à cet égard, mais les informations sur le résultat d'une agrégation ne valent souvent pas mieux qu'une supposition éclairée. Fournir à l'optimiseur de requête des informations plus précises à l'aide de statistiques sur les vues indexées peut être une technique utile pour améliorer la qualité et la robustesse du plan.
Une vue sans NOEXPAND peut produire un plan inférieur
Le plan de requête illustré ci-dessus (édition standard, sans NOEXPAND ) est en fait moins optimal que si nous avions écrit nous-mêmes la requête sur les tables de base, plutôt que de permettre à l'optimiseur de requête d'étendre la vue. La requête ci-dessous exprime la même exigence logique, mais ne fait pas référence à la vue :
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID; Cette requête produit le plan d'exécution suivant :
Ce plan comporte une opération d'agrégation de moins qu'auparavant. Lors de l'utilisation de l'expansion de la vue, l'optimiseur de requête n'a malheureusement pas pu supprimer une opération d'agrégation redondante, ce qui a entraîné un plan d'exécution moins efficace. L'estimation finale de cardinalité pour la nouvelle requête est également légèrement meilleure que lorsque la vue indexée était référencée sans NOEXPAND :
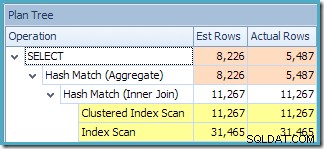
Néanmoins, les meilleures estimations restent celles produites en référençant la vue indexée avec NOEXPAND (répété ci-dessous pour plus de commodité) :
Édition Entreprise et correspondance des vues
Sur une instance Enterprise Edition, l'optimiseur de requête peut être en mesure d'utiliser une vue indexée même si la requête ne mentionne pas explicitement la vue. Si l'optimiseur est capable de faire correspondre une partie de l'arborescence de requête à une vue indexée, il peut choisir de le faire, en fonction de son estimation des coûts d'utilisation de la vue ou non. La logique de correspondance des vues est raisonnablement intelligente, mais elle a des limites assez faciles à atteindre dans la pratique. Même lorsque la correspondance des vues réussit, l'optimiseur peut toujours être induit en erreur par des estimations de coûts inexactes.
L'indice de requête EXPAND VIEWS
En commençant par la plus rare des possibilités, il peut y avoir des occasions où une requête fait référence à une vue indexée, mais un meilleur plan serait obtenu en accédant aux tables de base à la place. Dans ces circonstances, l'indicateur de requête EXPAND VIEWS peut être utilisé :
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID
OPTION (EXPAND VIEWS);
Sur Enterprise Edition, cette requête produit le même plan que celui vu sur Standard Edition lorsque le NOEXPAND indice a été omis (y compris l'opération d'agrégation redondante) :

En aparté, les EXPAND VIEWS l'indice est mal nommé, à mon avis. SQL Server développe toujours les définitions de vue dans une requête à moins que le NOEXPAND indice est spécifié. Les EXPAND VIEWS hint désactive les règles de l'optimiseur qui peuvent faire correspondre des parties de l'arborescence développée aux vues indexées. En l'absence de l'un ou l'autre indice, SQL Server étend d'abord une vue à sa définition de table de base, puis envisage ultérieurement de faire correspondre les vues indexées. Un meilleur nom pour les EXPAND VIEWS l'indice aurait pu être DISABLE INDEXED VIEW MATCHING , car c'est ce qu'il fait.
Les EXPAND VIEWS indice est probablement le plus souvent utilisé pour empêcher une requête sur des tables de base d'être mise en correspondance avec une vue indexée :
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID
OPTION (EXPAND VIEWS); L'indicateur de requête donne le même plan d'exécution et les mêmes estimations que lorsque nous utilisions l'édition Standard et la même requête de table de base uniquement :
Correspondance des vues d'entreprise et statistiques
Même dans Enterprise Edition, les statistiques de vue sans index ne sont toujours créées que si le NOEXPAND l'indice est utilisé. Pour être tout à fait clair à ce sujet, la fonctionnalité de correspondance des vues réservée aux entreprises n'entraîne jamais la création ou la mise à jour de statistiques de vues. Ce comportement non intuitif mérite d'être exploré un peu, car il peut avoir des effets secondaires surprenants.
Nous exécutons maintenant notre requête de base sur la vue d'une instance Enterprise Edition, sans aucun indice :
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
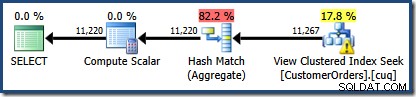
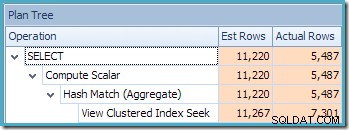
Une nouveauté est le triangle d'avertissement sur la recherche d'index clusterisée. L'info-bulle affiche les détails :
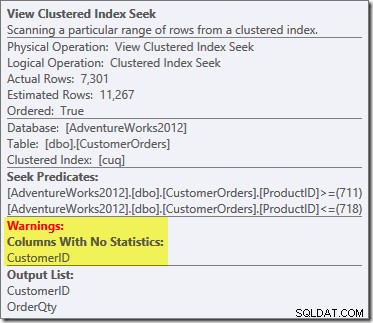
Nous n'avons pas utilisé de NOEXPAND indice, de sorte que les statistiques sur la colonne Customer ID de la vue indexée n'étaient pas automatiquement créées. Les statistiques sur l'ID client ne sont pas vraiment très importantes dans cet exemple simplifié, mais ce ne sera pas toujours le cas.
Estimations de cardinalité curieuses
La deuxième chose intéressante est que les estimations de cardinalité semblent être pires que tous les cas que nous avons rencontrés jusqu'à présent, y compris les exemples de l'édition standard.
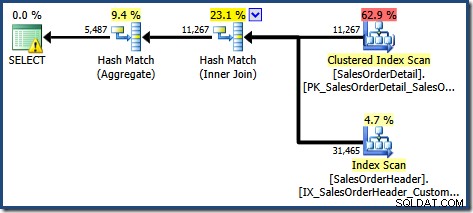
Il est initialement difficile de voir d'où vient l'estimation de la cardinalité pour la recherche d'index clusterisée de vue (11 267). Nous nous attendrions à ce que l'estimation soit basée sur les informations de l'histogramme d'ID de produit à partir des statistiques associées à l'index clusterisé de la vue. La partie pertinente de cet histogramme est illustrée ci-dessous :
DBCC SHOW_STATISTICS
('dbo.CustomerOrders', 'cuq')
WITH HISTOGRAM;
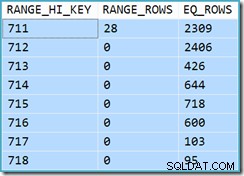
Étant donné que le tableau n'a pas été modifié depuis la création des statistiques, nous nous attendrions à ce que l'estimation soit une simple somme de RANGE_ROWS et EQ_ROWS pour les valeurs d'ID de produit entre 711 et 718 (notez que l'estimation doit exclure les 28 RANGE_ROWS indiqués par rapport à l'entrée 711 puisque ces lignes existent sous la valeur de clé 711). La somme des EQ_ROWS affichées est de 7 301. C'est exactement le nombre de lignes réellement renvoyées par la vue. D'où vient donc l'estimation de 11 267 ?
La réponse réside dans la façon dont la correspondance des vues fonctionne actuellement. Notre requête n'a pas spécifié le NOEXPAND indice, de sorte que les estimations de cardinalité initiales sont basées sur l'arbre de requête étendu. Ceci est plus facile à voir en examinant à nouveau le plan estimé pour la même requête avec EXPAND VIEWS spécifié :
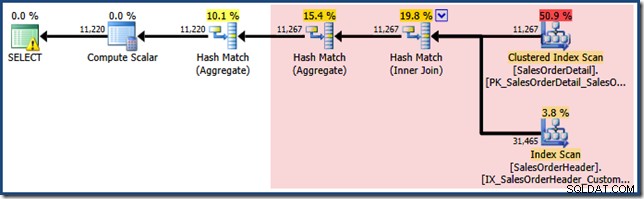
La zone ombrée en rouge représente la partie de l'arborescence qui est remplacée par l'activité de correspondance des vues. La cardinalité de sortie de cette zone est de 11 267. La partie non ombrée avec l'estimation de 11 220 n'est pas affectée par la correspondance des vues. Ce sont exactement les estimations que nous cherchions à expliquer :
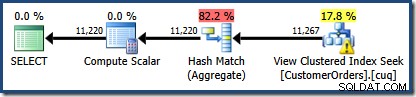
La correspondance de vue a simplement remplacé la zone ombrée rouge par une recherche logiquement équivalente sur la vue indexée. Il n'a pas utilisé les informations statistiques de la vue pour recalculer l'estimation de la cardinalité.
Dans une certaine mesure, vous pouvez probablement comprendre pourquoi cela pourrait fonctionner de cette façon :en général, il y a peu de raisons de s'attendre à ce qu'une estimation calculée à partir d'un ensemble d'informations statistiques soit meilleure qu'une autre. On pourrait faire valoir que les statistiques de vues indexées sont plus susceptibles d'être précises ici, par rapport aux statistiques dérivées post-jointure dans la zone ombrée rouge, mais il peut être difficile de généraliser cela, ou de tenir compte correctement de la rapidité avec laquelle diverses sources de les informations statistiques peuvent devenir obsolètes à mesure que les données sous-jacentes changent.
On pourrait également dire que si nous étions si sûrs que les informations de vue indexées étaient meilleures, nous aurions utilisé un NOEXPAND indice.
Estimations de cardinalité encore plus curieuses
Une situation encore plus intéressante se présente avec Enterprise Edition si nous écrivons la requête par rapport aux tables de base et comptons sur la correspondance automatique des vues :
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID;
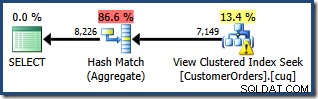
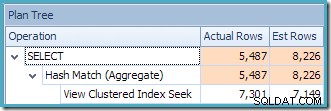
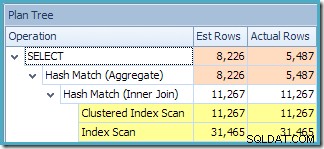
L'avertissement de statistiques manquantes est le même qu'avant et a la même explication. La caractéristique la plus intéressante est que nous avons maintenant une estimation inférieure du nombre de lignes produites par View Clustered Index Seek (7 149) et une estimation accrue du nombre de lignes renvoyées par l'agrégation (8 226).
Pour souligner ce point, ce plan de requête semble être basé sur l'idée que 7 149 lignes source peuvent être agrégées pour produire 8 226 lignes !
Une partie de l'explication est la même que précédemment. Les EXPAND VIEWS plan de requête, montrant la région rouge qui sera remplacée par la correspondance de vue est illustré ci-dessous :
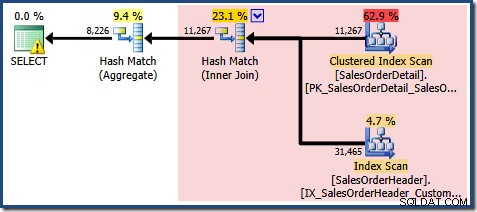
Cela explique d'où vient l'estimation finale de 8 226, mais qu'en est-il de l'estimation de 7 149 lignes ? En suivant la logique vue précédemment, il semble que la vue devrait afficher une estimation de 11 267 lignes ?
La réponse est que l'estimation de 7 149 est une supposition. Oui vraiment. La vue indexée contient 79 433 lignes au total. Le pourcentage de conjecture magique pour le prédicat Product ID BETWEEN est de 9 %, ce qui donne 0,09 * 79433 =7148,97 lignes. Le plan de requête SSMS montre que ce calcul est exactement correct, même avant l'arrondi :
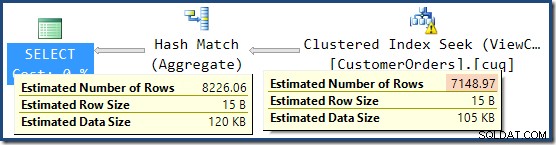
Dans cette situation, l'optimiseur SQL Server semble avoir préféré une estimation basée sur la cardinalité de la vue indexée plutôt que l'estimation de la cardinalité post-jointure à partir du sous-arbre remplacé. Curieux.
Résumé
Utiliser le NOEXPAND hint garantit qu'une vue indexée sera utilisée dans le plan de requête final et permet la création, la maintenance et l'utilisation automatiques de statistiques non indexées par l'optimiseur de requête. Utilisation de NOEXPAND garantit également que les estimations de cardinalité initiales sont basées sur des informations de vue indexées plutôt que d'être dérivées de tables de base.
Si NOEXPAND n'est pas spécifié, les références de vue sont toujours remplacées par leurs définitions de table de base avant le début de la compilation de la requête (et donc avant l'estimation initiale de la cardinalité). Dans les SKU d'entreprise uniquement, les vues indexées peuvent être remplacées dans l'arborescence de requête ultérieurement dans le processus d'optimisation.
Les EXPAND VIEWS L'indicateur de requête empêche l'optimiseur d'effectuer la mise en correspondance des vues indexées Enterprise Edition. Cela s'applique que la requête ait initialement fait référence à une vue indexée ou non. Lorsque la correspondance des vues est effectuée, une estimation de cardinalité existante peut être remplacée par une supposition dans certaines circonstances.
Les statistiques affichées comme manquantes sur une vue indexée peuvent être créées manuellement, mais l'optimiseur ne les utilisera généralement pas pour les requêtes qui n'utilisent pas de NOEXPAND indice.
L'utilisation de vues indexées peut améliorer l'estimation de la cardinalité, en particulier si la vue contient des jointures ou des agrégations. Les requêtes ont les meilleures chances de bénéficier de statistiques d'affichage plus précises si NOEXPAND est spécifié.