Il s'agit de la troisième d'une série en cinq parties qui explore en profondeur la façon dont les plans parallèles en mode ligne de SQL Server commencent à s'exécuter. La partie 1 a initialisé le contexte d'exécution zéro pour la tâche parente et la partie 2 a créé l'arborescence d'analyse des requêtes. Nous sommes maintenant prêts à démarrer l'analyse des requêtes, à effectuer une phase préliminaire traitement et démarrer les premières tâches parallèles supplémentaires.
Démarrage de l'analyse des requêtes
Rappelez-vous que seule la tâche parent existe actuellement, et les échanges (opérateurs de parallélisme) n'ont qu'un côté consommateur. Néanmoins, cela suffit pour que l'exécution de la requête commence, sur le thread de travail de la tâche parent. Le processeur de requêtes commence l'exécution en démarrant le processus d'analyse de la requête via un appel à CQueryScan::StartupQuery . Un rappel du plan (cliquez pour agrandir) :
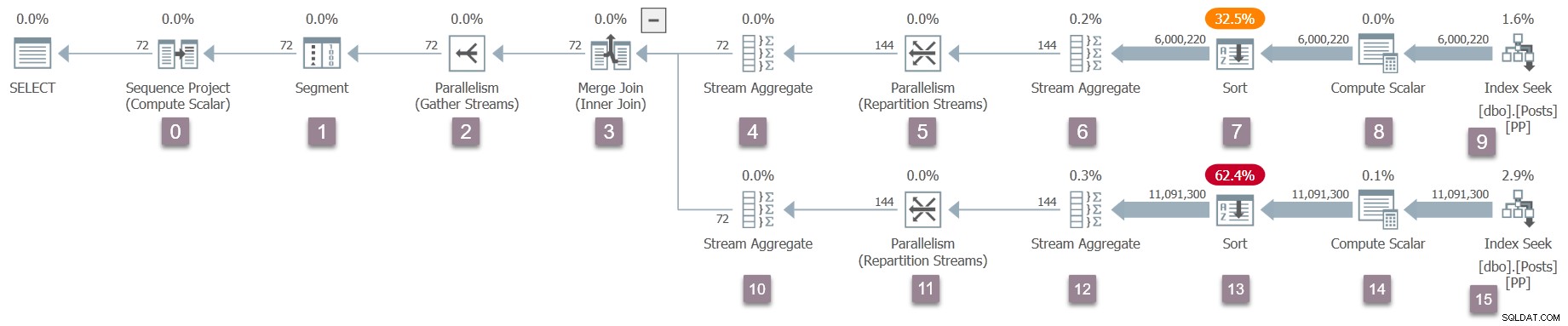
C'est le premier point du processus jusqu'à présent qu'un plan d'exécution en cours est disponible (à partir de SQL Server 2016 SP1) dans sys.dm_exec_query_statistics_xml . Il n'y a rien de particulièrement intéressant à voir dans un tel plan à ce stade, car tous les compteurs de transitoires sont à zéro, mais le plan est au moins disponible . Rien n'indique que des tâches parallèles n'ont pas encore été créées ou que les échanges manquent d'un côté producteur. Le plan semble "normal" à tous égards.
Succursales du plan parallèle
Comme il s'agit d'un plan parallèle, il sera utile de le montrer divisé en branches. Celles-ci sont ombrées ci-dessous et étiquetées comme les branches A à D :
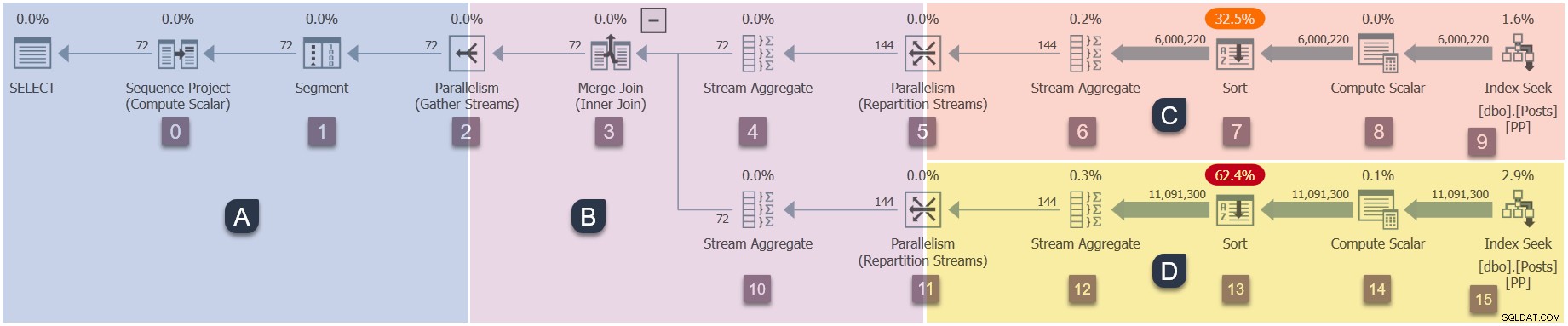
La branche A est associée à la tâche parent, s'exécutant sur le thread de travail fourni par la session. Des travailleurs parallèles supplémentaires seront lancés pour exécuter les tâches parallèles supplémentaires contenus dans les branches B, C et D. Ces branches sont parallèles, il y aura donc des tâches DOP supplémentaires et des travailleurs dans chacune d'elles.
Notre exemple de requête s'exécute à DOP 2, donc la branche B recevra deux tâches supplémentaires. Il en va de même pour la branche C et la branche D, ce qui donne un total de six des tâches supplémentaires. Chaque tâche s'exécutera sur son propre thread de travail dans son propre contexte d'exécution.
Deux planificateurs (S1 et S2 ) sont affectés à cette requête pour exécuter des nœuds de calcul parallèles supplémentaires. Chaque travailleur supplémentaire s'exécutera sur l'un de ces deux planificateurs. Le travailleur parent peut s'exécuter sur un planificateur différent, donc notre requête DOP 2 peut utiliser un maximum de trois cœurs de processeur à tout moment.
Pour résumer, notre plan aura éventuellement :
- Branche A (parent)
- Tâche parent.
- Fil de discussion parent.
- Contexte d'exécution zéro.
- Tout planificateur unique disponible pour la requête.
- Branche B (supplémentaire)
- Deux tâches supplémentaires.
- Un thread de travail supplémentaire lié à chaque nouvelle tâche.
- Deux nouveaux contextes d'exécution, un pour chaque nouvelle tâche.
- Un thread de travail s'exécute sur le planificateur S1 . L'autre s'exécute sur le planificateur S2 .
- Branche C (supplémentaire)
- Deux tâches supplémentaires.
- Un thread de travail supplémentaire lié à chaque nouvelle tâche.
- Deux nouveaux contextes d'exécution, un pour chaque nouvelle tâche.
- Un thread de travail s'exécute sur le planificateur S1 . L'autre s'exécute sur le planificateur S2 .
- Branche D (supplémentaire)
- Deux tâches supplémentaires.
- Un thread de travail supplémentaire lié à chaque nouvelle tâche.
- Deux nouveaux contextes d'exécution, un pour chaque nouvelle tâche.
- Un thread de travail s'exécute sur le planificateur S1 . L'autre s'exécute sur le planificateur S2 .
La question est de savoir comment toutes ces tâches, travailleurs et contextes d'exécution supplémentaires sont créés, et quand ils commencent à s'exécuter.
Séquence de démarrage
L'ordre dans lequel les tâches supplémentaires commencer à exécuter pour ce plan particulier est :
- Branche A (tâche parente).
- Branche C (tâches parallèles supplémentaires).
- Branche D (tâches parallèles supplémentaires).
- Branche B (tâches parallèles supplémentaires).
Ce n'est peut-être pas la commande initiale que vous attendiez.
Il peut y avoir un retard important entre chacune de ces étapes, pour des raisons que nous allons explorer prochainement. Le point clé à ce stade est que les tâches supplémentaires, les travailleurs et les contextes d'exécution ne sont pas tous créés en même temps, et ils ne le font pas commencent tous à s'exécuter en même temps.
SQL Server aurait pu être conçu pour démarrer tous les bits parallèles supplémentaires en même temps. Cela pourrait être facile à comprendre, mais ce ne serait pas très efficace en général. Cela maximiserait le nombre de threads supplémentaires et d'autres ressources utilisées par la requête, et entraînerait un grand nombre d'attentes parallèles inutiles.
Avec la conception employée par SQL Server, les plans parallèles utiliseront souvent moins de threads de travail totaux que (DOP multiplié par le nombre total de branches). Ceci est réalisé en reconnaissant que certaines branches peuvent s'exécuter jusqu'à la fin avant qu'une autre branche ne doive démarrer. Cela peut permettre la réutilisation de threads dans la même requête et réduit généralement la consommation globale de ressources.
Passons maintenant aux détails du démarrage de notre plan parallèle.
Ouverture de la succursale A
L'analyse de la requête commence à s'exécuter avec la tâche parent appelant Open() sur l'itérateur à la racine de l'arbre. C'est le début de la séquence d'exécution :
- Branche A (tâche parente).
- Branche C (tâches parallèles supplémentaires).
- Branche D (tâches parallèles supplémentaires).
- Branche B (tâches parallèles supplémentaires).
Nous exécutons cette requête avec un plan "réel" demandé, donc l'itérateur racine n'est pas l'opérateur de projet de séquence au nœud 0. Il s'agit plutôt de l'itérateur de profilage invisible qui enregistre les métriques d'exécution dans les plans en mode ligne.
L'illustration ci-dessous montre les itérateurs d'analyse de requête dans la branche A du plan, avec la position des itérateurs de profilage invisibles représentés par les icônes "spectacles".
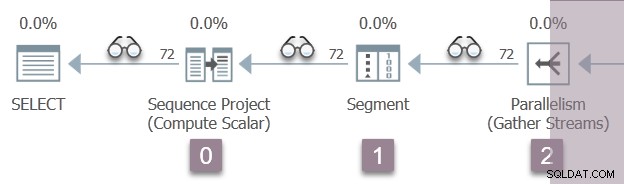
L'exécution commence par un appel pour ouvrir le premier profileur, CQScanProfileNew::Open . Cela définit le temps d'ouverture pour l'opérateur de projet de séquence enfant via l'API Query Performance Counter du système d'exploitation.
Nous pouvons voir ce numéro dans sys.dm_exec_query_profiles :
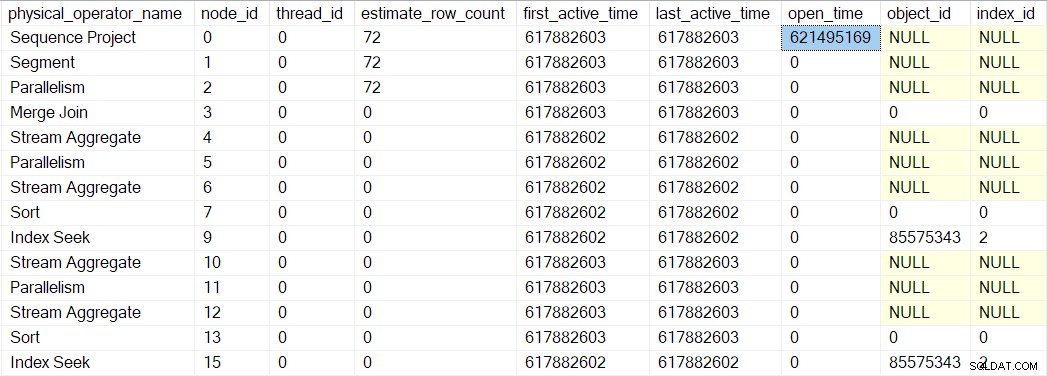
Les entrées peuvent contenir les noms d'opérateurs, mais les données proviennent du profileur au-dessus de l'opérateur, pas l'opérateur lui-même.
En l'occurrence, un projet de séquence (CQScanSeqProjectNew ) n'a pas besoin de faire de travail lorsqu'il est ouvert , donc il n'a pas réellement de Open() méthode. Le profileur au-dessus du projet de séquence est appelé, donc un temps d'ouverture pour le projet de séquence est enregistré dans le DMV.
L'Open du profileur la méthode n'appelle pas Open sur le projet de séquence (puisqu'il n'en a pas). Au lieu de cela, il appelle Open sur le profileur pour le prochain itérateur dans la séquence. Il s'agit du segment itérateur au nœud 1. Cela définit le temps d'ouverture pour le segment, tout comme le profileur précédent l'a fait pour le projet de séquence :
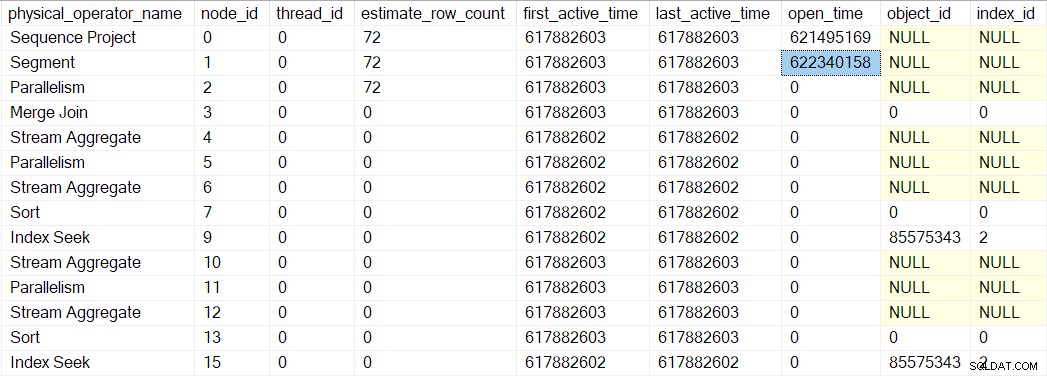
Un itérateur de segment fait avoir des choses à faire lors de l'ouverture, donc le prochain appel est à CQScanSegmentNew::Open . Une fois que le segment a fait ce qu'il doit faire, il appelle le profileur pour l'itérateur suivant dans la séquence - le consommateur côté de la échange de flux de collecte au noeud 2 :
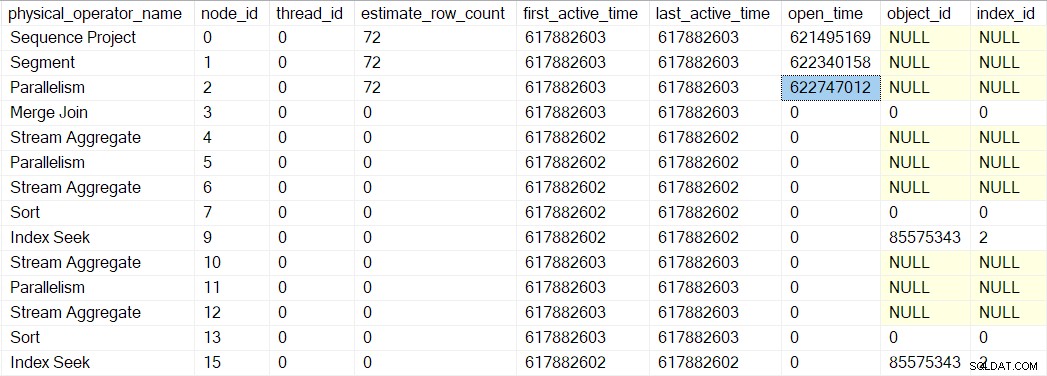
Le prochain appel vers le bas de l'arborescence d'analyse des requêtes dans le processus d'ouverture est CQScanExchangeNew::Open , c'est là que les choses commencent à devenir plus intéressantes.
Ouverture de l'échange de flux de collecte
Demander au côté consommateur de l'échange d'ouvrir :
- Ouvre une transaction locale (parallèle imbriquée) (
CXTransLocal::Open). Chaque processus a besoin d'une transaction contenante, et les tâches parallèles supplémentaires ne font pas exception. Ils ne peuvent pas partager directement la transaction parente (de base), donc des transactions imbriquées sont utilisées. Lorsqu'une tâche parallèle doit accéder à la transaction de base, elle se synchronise sur un verrou et peut rencontrerNESTING_TRANSACTION_READONLYouNESTING_TRANSACTION_FULLattend. - Enregistre le thread de travail actuel avec le port d'échange (
CXPort::Register). - Se synchronise avec d'autres threads du côté consommateur de l'échange (
sqlmin!CXTransLocal::Synchronize). Il n'y a pas d'autres threads du côté consommateur d'un flux de collecte, il s'agit donc essentiellement d'une opération interdite à cette occasion.
Traitement des "premières phases"
La tâche parent a maintenant atteint le bord de la branche A. La prochaine étape est particulière aux plans parallèles en mode ligne :la tâche parent continue son exécution en appelant CQScanExchangeNew::EarlyPhases sur l'itérateur d'échange de flux de collecte au nœud 2. Il s'agit d'une méthode d'itération supplémentaire au-delà de l'habituel Open , GetRow , et Close méthodes que beaucoup d'entre vous connaissent. EarlyPhases n'est appelé que dans les plans parallèles en mode ligne.
Je veux être clair sur quelque chose à ce stade :le côté producteur de l'échange de flux de collecte au nœud 2 n'a pas n'a pas encore été créé, et non des tâches parallèles supplémentaires ont été créées. Nous exécutons toujours du code pour la tâche parent, en utilisant le seul thread en cours d'exécution en ce moment.
Tous les itérateurs n'implémentent pas EarlyPhases , car ils n'ont pas tous quelque chose de spécial à faire à ce stade dans les plans parallèles en mode ligne. Ceci est analogue au projet de séquence n'implémentant pas le Open méthode parce qu'elle n'a rien à faire à ce moment-là. Les principaux itérateurs avec EarlyPhases méthodes sont :
CQScanConcatNew(concaténation).CQScanMergeJoinNew(jointure par fusion).CQScanSwitchNew(commutateur).CQScanExchangeNew(parallélisme).CQScanNew(accès à l'ensemble de lignes, par exemple scans et recherches).CQScanProfileNew(profileurs invisibles).CQScanLightProfileNew(profileurs légers invisibles).
Phases précoces de la branche B
La tâche parente continue en appelant EarlyPhases sur les opérateurs enfants au-delà de l'échange de flux de collecte au nœud 2. Une tâche se déplaçant au-delà d'une limite de branche peut sembler inhabituelle, mais rappelez-vous que le contexte d'exécution zéro contient l'ensemble du plan série, avec les échanges inclus. Le traitement de la phase précoce consiste à initialiser le parallélisme, donc cela ne compte pas comme exécution en soi .
Pour vous aider à garder une trace, l'image ci-dessous montre les itérateurs dans la branche B du plan :
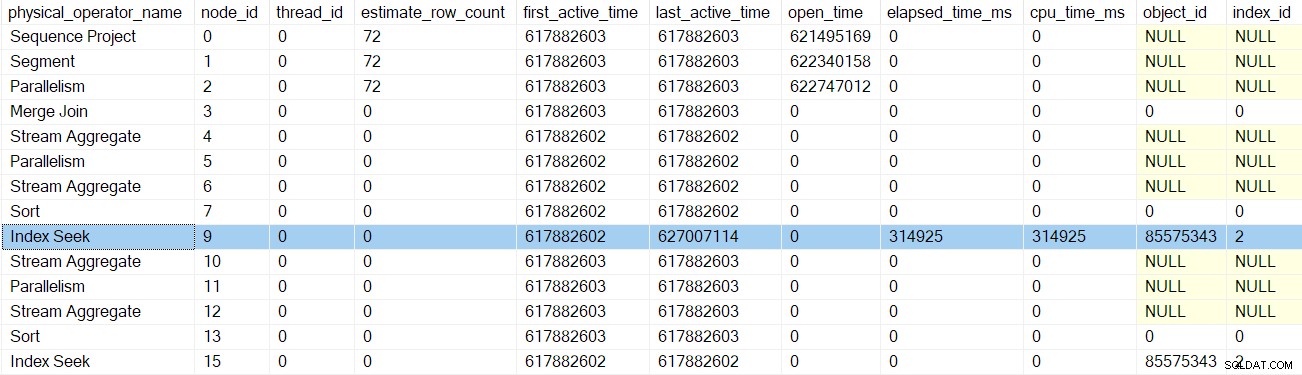
N'oubliez pas que nous sommes toujours dans le contexte d'exécution zéro, donc je ne fais référence à cela que sous le nom de branche B pour plus de commodité. Nous n'avons pas commencé aucune exécution parallèle pour le moment.
La séquence d'invocations de code de phase précoce dans la branche B est :
CQScanProfileNew::EarlyPhasespour le profileur au-dessus du nœud 3.CQScanMergeJoinNew::EarlyPhasesau nœud 3 jointure de fusion .CQScanProfileNew::EarlyPhasespour le profileur au-dessus du nœud 4. Le nœud 4 agrégat de flux lui-même n'a pas de méthode de phases précoces.CQScanProfileNew::EarlyPhasessur le profileur au-dessus du nœud 5.CQScanExchangeNew::EarlyPhasespour les flux de répartition échange au nœud 5.
Notez que nous ne traitons que l'entrée externe (supérieure) de la jointure de fusion à ce stade. Il s'agit simplement de la séquence itérative d'exécution en mode ligne normale. Ce n'est pas particulier aux plans parallèles.
Phases précoces de la branche C
Le traitement de la première phase se poursuit avec les itérateurs dans la branche C :

La séquence d'appels ici est :
CQScanProfileNew::EarlyPhasespour le profileur au-dessus du nœud 6.CQScanProfileNew::EarlyPhasespour le profileur au-dessus du nœud 7.CQScanProfileNew::EarlyPhasessur le profileur au-dessus du nœud 9.CQScanNew::EarlyPhasespour la recherche d'index au nœud 9.
Il n'y a pas de EarlyPhases méthode sur l'agrégat ou le tri du flux. Le travail effectué par le calculateur scalaire au nœud 8 est différé (au tri), il n'apparaît donc pas dans l'arborescence d'analyse des requêtes et n'a pas de profileur associé.
À propos des délais du profileur
Tâche parente traitement de la phase précoce a commencé à l'échange de flux de collecte au nœud 2. Il est descendu dans l'arborescence d'analyse de requête, en suivant l'entrée externe (supérieure) de la jointure de fusion, jusqu'à la recherche d'index au nœud 9. En cours de route, la tâche parent a appelé les EarlyPhases méthode sur chaque itérateur qui la prend en charge.
Jusqu'à présent, aucune des activités des premières phases n'a été mise à jour à tout moment dans la DMV de profilage. Plus précisément, aucun des itérateurs touchés par le traitement des premières phases n'a son "temps d'ouverture" défini. Cela a du sens, car le traitement de la phase précoce consiste simplement à configurer une exécution parallèle - ces opérateurs seront ouverts pour une exécution ultérieure.
La recherche d'index au nœud 9 est un nœud feuille - il n'a pas d'enfant. La tâche parent commence maintenant à revenir des EarlyPhases imbriqués appels, croissant l'arborescence d'analyse des requêtes vers l'échange de flux de collecte.
Chacun des profileurs appelle le Query Performance Counter API à l'entrée de leurs EarlyPhases méthode, et ils l'appellent à nouveau en sortant. La différence entre les deux nombres représente le temps écoulé pour l'itérateur et tous ses enfants (puisque les appels de méthode sont imbriqués).
Après le retour du profileur pour la recherche d'index, le profileur DMV affiche le temps écoulé et le temps CPU pour la recherche d'index uniquement, ainsi qu'un dernier actif mis à jour temps. Notez également que ces informations sont enregistrées par rapport à la tâche parent (la seule option pour le moment):
Aucun des itérateurs antérieurs touchés par les appels de phases précoces n'a de temps écoulé ou n'a mis à jour les derniers temps actifs. Ces chiffres ne sont mis à jour que lorsque nous montons dans l'arbre.
Après le prochain retour d'appel des premières phases du profileur, le sort les horaires sont mis à jour :
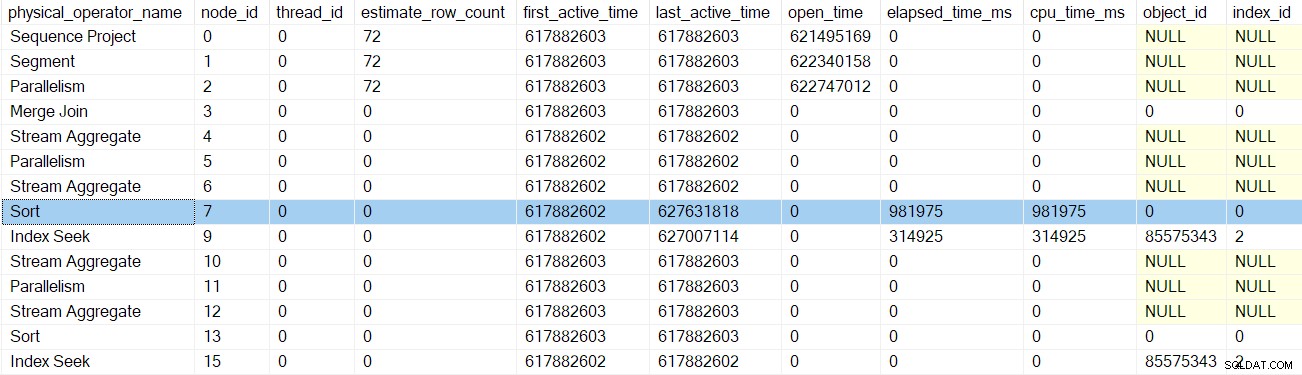
Le retour suivant nous emmène au-delà du profileur pour l'agrégat de flux au nœud 6 :
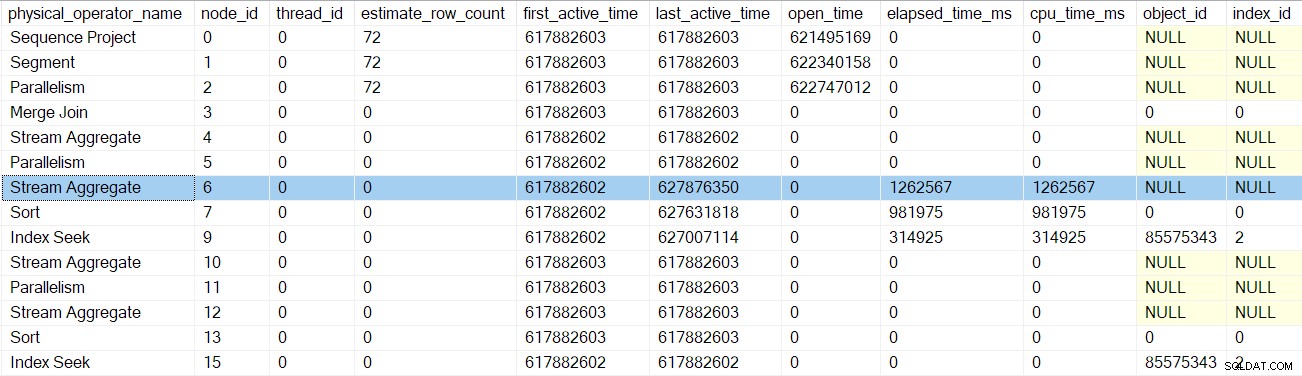
Revenir de ce profileur nous ramène aux EarlyPhases appel aux flux de répartition échange au nœud 5 . N'oubliez pas que ce n'est pas là que la séquence d'appels des premières phases a commencé - c'était l'échange de flux de collecte au nœud 2.
Tâches parallèles de la branche C mises en file d'attente
Mis à part la mise à jour des données de profilage, les appels des premières phases précédentes ne semblaient pas faire grand-chose. Tout change avec les flux de répartition échange au nœud 5.
Je vais décrire la branche C assez en détail pour introduire un certain nombre de concepts importants, qui s'appliqueront également aux autres branches parallèles. Couvrir ce terrain une fois maintenant signifie que la discussion ultérieure de la branche peut être plus succincte.
Après avoir terminé le traitement de phase précoce imbriqué pour son sous-arbre (jusqu'à la recherche d'index au nœud 9), l'échange peut commencer son propre travail de phase précoce. Cela commence de la même manière que l'ouverture l'échange de flux de collecte au nœud 2 :
CXTransLocal::Open(ouverture de la sous-transaction parallèle locale).CXPort::Register(enregistrement auprès du port d'échange).
Les étapes suivantes sont différentes car la branche C contient un élément entièrement bloquant itérateur (le tri au nœud 7). Le traitement de la phase précoce au niveau des flux de répartition du nœud 5 effectue les opérations suivantes :
- Appelle
CQScanExchangeNew::StartAllProducers. C'est la première fois que nous rencontrons quoi que ce soit faisant référence au côté producteur de l'échange. Le nœud 5 est le premier échange de ce plan à créer son côté producteur. - Acquiert un mutex afin qu'aucun autre thread ne puisse mettre des tâches en file d'attente en même temps.
- Démarre des transactions imbriquées parallèles pour les tâches du producteur (
CXPort::StartNestedTransactionsetReadOnlyXactImp::BeginParallelNestedXact). - Enregistre les sous-transactions avec l'objet d'analyse de requête parent (
CQueryScan::AddSubXact). - Crée des descripteurs de producteurs (
CQScanExchangeNew::PxproddescCreate). - Crée de nouveaux contextes d'exécution de producteur (
CExecContext) dérivé du contexte d'exécution zéro. - Met à jour la carte liée des itérateurs de plan.
- Définit DOP pour le nouveau contexte (
CQueryExecContext::SetDop) afin que toutes les tâches sachent quel est le paramètre DOP global. - Initialise le cache des paramètres (
CQueryExecContext::InitParamCache). - Lie les transactions parallèles imbriquées à la transaction de base (
CExecContext::SetBaseXact). - Mette en file d'attente les nouveaux sous-processus pour exécution (
SubprocessMgr::EnqueueMultipleSubprocesses). - Crée de nouvelles tâches parallèles tâches via
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
La pile d'appels de la tâche parent (pour ceux d'entre vous qui aiment ces choses) à ce moment précis est :
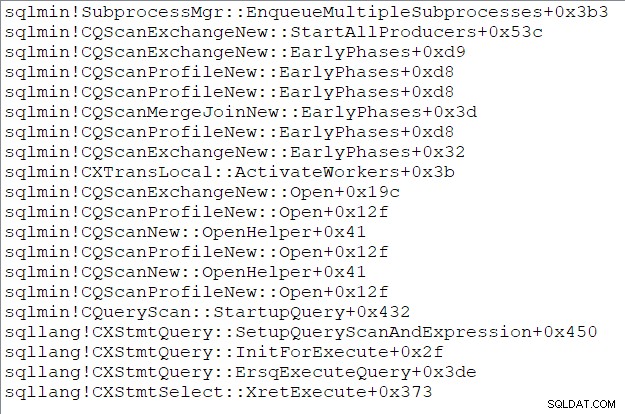
Fin de la troisième partie
Nous avons maintenant créé le côté producteur de l'échange de flux de répartition au nœud 5, a créé des tâches parallèles supplémentaires pour exécuter la branche C, et tout lié au parent structures selon les besoins. La branche C est la première branche pour démarrer toutes les tâches parallèles. La dernière partie de cette série examinera en détail l'ouverture de la branche C et commencera les tâches parallèles restantes.