Dans cet article, je continue d'explorer des solutions au défi de l'adéquation entre l'offre et la demande. Merci à Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian et Peter Larsson, pour l'envoi de vos solutions.
Le mois dernier, j'ai couvert des solutions basées sur une approche révisée des intersections d'intervalles par rapport à l'approche classique. La plus rapide de ces solutions combinait les idées de Kamil, Luca et Daniel. Il a unifié deux requêtes avec des prédicats sargables disjoints. Il a fallu 1,34 seconde à la solution pour se terminer par rapport à une entrée de 400 000 lignes. Ce n'est pas trop minable étant donné que la solution basée sur l'approche classique des intersections d'intervalle a pris 931 secondes pour se terminer avec la même entrée. Rappelez-vous également que Joe a proposé une solution brillante qui s'appuie sur l'approche classique d'intersection d'intervalles mais optimise la logique de correspondance en regroupant les intervalles en fonction de la plus grande longueur d'intervalle. Avec la même entrée de 400 000 lignes, il a fallu 0,9 seconde à la solution de Joe. La partie délicate de cette solution est que ses performances se dégradent à mesure que la longueur de l'intervalle le plus grand augmente.
Ce mois-ci, j'explore des solutions fascinantes qui sont plus rapides que la solution Kamil/Luca/Daniel Revised Intersections et qui sont neutres par rapport à la longueur de l'intervalle. Les solutions de cet article ont été créées par Brian Walker, Ian, Peter Larsson, Paul White et moi.
J'ai testé toutes les solutions de cet article par rapport à la table d'entrée Auctions avec des lignes de 100 Ko, 200 Ko, 300 Ko et 400 Ko, et avec les index suivants :
-- Index pour prendre en charge la solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Activer l'agrégation de fenêtres en mode batch CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID =-1 AND ID =-2 ;
Lors de la description de la logique derrière les solutions, je supposerai que la table des enchères est remplie avec le petit ensemble d'exemples de données suivant :
Numéro de code ID----------- ---------1 D 5.0000002 D 3.0000003 D 8.0000005 D 2.0000006 D 8.0000007 D 4.0000008 D 2.0000001000 S 8.0000002000 S 6.0000003000 S 2.0000004000 S 2.0000005000 S 4.0000006000 S 3.0000007000 S 2.000000
Voici le résultat souhaité pour cet exemple de données :
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
La solution de Brian Walker
Les jointures externes sont assez couramment utilisées dans les solutions d'interrogation SQL, mais de loin, lorsque vous les utilisez, vous utilisez des jointures unilatérales. Lorsque j'enseigne les jointures externes, je reçois souvent des questions demandant des exemples de cas d'utilisation pratiques de jointures externes complètes, et il n'y en a pas beaucoup. La solution de Brian est un bel exemple de cas d'utilisation pratique de jointures externes complètes.
Voici le code de solution complet de Brian :
DOP TABLE SI EXISTE #MyPairings ; CREATE TABLE #MyPairings( DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); WITH D AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running FROM dbo.Auctions AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running FROM dbo.Auctions AS A WHERE A.Code ='S'),W AS( SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running FROM D FULL JOIN S ON D.Running =S.Running),Z AS( SELECT CASE WHEN W.DemandID IS NOT NULL THEN W.DemandID ELSE MIN(W.DemandID) OVER (ORDER BY W.Running ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) END AS DemandID, CASE WHEN SupplyID IS NOT NULL THEN W.SupplyID ELSE MIN(W.SupplyID ) OVER (ORDER BY W.Running ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) END AS SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity ) SELECT Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity FROM Z WHERE Z.DemandID N'EST PAS NULL AND Z.SupplyID N'EST PAS NULL ;
J'ai révisé l'utilisation originale par Brian des tables dérivées avec les CTE pour plus de clarté.
Le CTE D calcule les quantités cumulées de la demande totale dans une colonne de résultat appelée D.Running, et le CTE S calcule les quantités cumulées de l'offre totale dans une colonne de résultat appelée S.Running. Le CTE W effectue ensuite une jointure externe complète entre D et S, faisant correspondre D.Running avec S.Running, et renvoie le premier non-NULL parmi D.Running et S.Running comme W.Running. Voici le résultat que vous obtenez si vous interrogez toutes les lignes de W triées par Running :
DemandID SupplyID Running----------- ----------- ----------1 NULL 5.0000002 1000 8.000000NULL 2000 14.0000003 3000 16.0000005 4000 18.000000 NULL 5000 22.000000NULL 6000 25.0000006 NULL 26.000000NULL 7000 27.0000007 NULL 30.0000008 NULL 32.000000
L'idée d'utiliser une jointure externe complète basée sur un prédicat qui compare les totaux cumulés de la demande et de l'offre est un coup de génie ! La plupart des lignes de ce résultat (les 9 premières dans notre cas) représentent des paires de résultats avec un peu de calculs supplémentaires manquants. Les lignes avec des ID NULL à la fin de l'un des types représentent des entrées qui ne peuvent pas être mises en correspondance. Dans notre cas, les deux dernières lignes représentent des entrées de demande qui ne peuvent pas être mises en correspondance avec des entrées d'offre. Il ne reste donc plus qu'à calculer le DemandID, le SupplyID et le TradeQuantity des appariements de résultats, et à filtrer les entrées qui ne peuvent pas être mises en correspondance.
La logique qui calcule le résultat DemandID et SupplyID est effectuée dans le CTE Z comme suit (en supposant que la commande dans W par Running) :
- DemandID :si DemandID n'est pas NULL alors DemandID, sinon le DemandID minimum commençant par la ligne courante
- SupplyID :si SupplyID n'est pas NULL, alors SupplyID, sinon le SupplyID minimum commençant par la ligne actuelle
Voici le résultat que vous obtenez si vous interrogez Z et ordonnez les lignes par Running :
DemandID SupplyID Running----------- ----------- ----------1 1000 5.0000002 1000 8.0000003 2000 14.0000003 3000 16.0000005 4000 18.0000006 5000 22.0000006 6000 25.0000006 7000 26.0000007 7000 27.0000007 NUL 30.0000008 NUL 32.000000
La requête externe filtre les lignes de Z représentant les entrées d'un type qui ne peuvent pas être mises en correspondance avec les entrées de l'autre type en s'assurant que DemandID et SupplyID ne sont pas NULL. La quantité d'échanges des paires de résultats est calculée comme la valeur courante actuelle moins la valeur courante précédente à l'aide d'une fonction LAG.
Voici ce qui est écrit dans la table #MyPairings, qui est le résultat souhaité :
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
Le plan de cette solution est illustré à la figure 1.
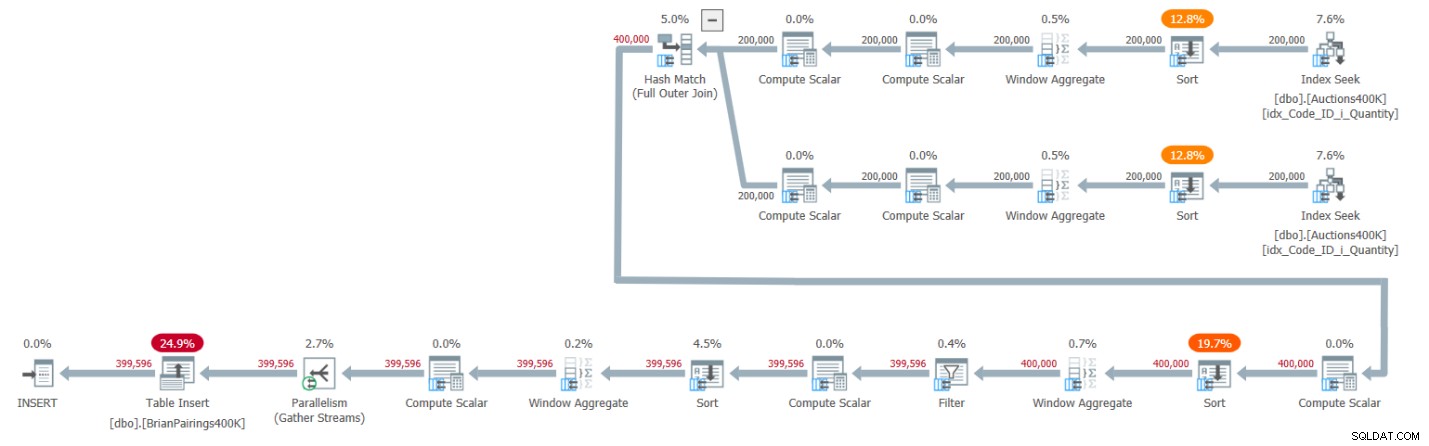 Figure 1 :Plan de requête pour la solution de Brian
Figure 1 :Plan de requête pour la solution de Brian
Les deux branches supérieures du plan calculent les totaux cumulés de la demande et de l'offre à l'aide d'un opérateur Window Aggregate en mode batch, chacune après avoir récupéré les entrées respectives de l'index de prise en charge. Comme je l'ai expliqué dans les articles précédents de la série, puisque l'index a déjà les lignes ordonnées comme les opérateurs Window Aggregate en ont besoin, vous penseriez que les opérateurs de tri explicites ne devraient pas être nécessaires. Mais SQL Server ne prend actuellement pas en charge une combinaison efficace d'opérations d'index parallèles préservant l'ordre avant un opérateur d'agrégation de fenêtre parallèle en mode batch. Par conséquent, un opérateur de tri parallèle explicite précède chacun des opérateurs d'agrégation de fenêtre parallèles.
Le plan utilise une jointure de hachage en mode batch pour gérer la jointure externe complète. Le plan utilise également deux opérateurs d'agrégation de fenêtre en mode batch supplémentaires précédés d'opérateurs de tri explicites pour calculer les fonctions de fenêtre MIN et LAG.
C'est un plan plutôt efficace !
Voici les temps d'exécution que j'ai obtenus pour cette solution avec des tailles d'entrée allant de 100 000 à 400 000 lignes, en secondes :
100K :0,368200K :0,845300K :1,255400K :1,315
La solution d'Itzik
La solution suivante pour le défi est l'une de mes tentatives pour le résoudre. Voici le code complet de la solution :
DOP TABLE SI EXISTE #MyPairings ; WITH C1 AS( SELECT *, SUM(Quantity) OVER(PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS SumQty FROM dbo.Auctions),C2 AS( SELECT *, SUM(Quantity * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS StockLevel, LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevSupplyID, MIN(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextDemandID, MIN(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURRENT ROW ET SANS LIMITE SUIVANT) AS NextSupplyID FROM C1),C3 AS( SELECT *, CASE Code WHEN 'D ' THEN ID WHEN 'S' THEN CASE WHEN StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID ELSE PrevSupplyID END END AS SupplyID, SumQty - PrevSumQty AS TradeQuantity FROM C2)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0.0 AND DemandID IS NOT NULL AND SupplyID IS NOT NULL;
Le CTE C1 interroge la table Auctions et utilise une fonction de fenêtrage pour calculer la demande totale en cours et les quantités d'approvisionnement, en appelant la colonne de résultat SumQty.
Le CTE C2 interroge C1 et calcule un certain nombre d'attributs à l'aide de fonctions de fenêtre basées sur l'ordre SumQty et Code :
- StockLevel :le niveau de stock actuel après le traitement de chaque entrée. Ceci est calculé en attribuant un signe négatif aux quantités demandées et un signe positif aux quantités fournies et en additionnant ces quantités jusqu'à et y compris l'entrée actuelle.
- PrevSumQty :valeur SumQty de la ligne précédente.
- PrevDemandID :dernier ID de demande non NULL.
- PrevSupplyID :dernier ID de fourniture non NULL.
- NextDemandID :ID de demande suivant non NULL.
- NextSupplyID :ID d'approvisionnement suivant non NULL.
Voici le contenu de C2 classé par SumQty et Code :
ID Code Quantité SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- --------- ---------- --------- -- ----------- ------------ ------------ ------------ - ----------- 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 10002 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 10001000 S 8.000000 8.000000.000000 8.0000002 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.000000-20000000000008 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 60006 D 8.000000 26.000000 -1.000000000000000000 6 6000 6 70007000 S 2.000000700000000000000006 32.000000 -5.000000 30.000000 8 7000 8 NUL
Le CTE C3 interroge C2 et calcule les paires de résultats DemandID, SupplyID et TradeQuantity, avant de supprimer certaines lignes superflues.
La colonne de résultat C3.DemandID est calculée comme suit :
- Si l'entrée actuelle est une entrée de demande, renvoie DemandID.
- Si l'entrée actuelle est une entrée d'approvisionnement et que le niveau de stock actuel est positif, renvoie NextDemandID.
- Si l'entrée actuelle est une entrée d'approvisionnement et que le niveau de stock actuel n'est pas positif, renvoie PrevDemandID.
La colonne de résultat C3.SupplyID est calculée comme suit :
- Si l'entrée actuelle est une entrée de fourniture, renvoie SupplyID.
- Si l'entrée actuelle est une entrée de demande et que le niveau de stock actuel n'est pas positif, renvoie NextSupplyID.
- Si l'entrée actuelle est une entrée de demande et que le niveau de stock actuel est positif, renvoie PrevSupplyID.
Le résultat TradeQuantity est calculé comme SumQty de la ligne actuelle moins PrevSumQty.
Voici le contenu des colonnes pertinentes pour le résultat de C3 :
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000002 1000 0.0000003 2000 6.0000003 3000 2.0000003 3000 0.0000005 4000 2.0000005 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000007 NULL 3.0000008 NULL 2.000000
Ce qui reste à faire pour la requête externe est de filtrer les lignes superflues de C3. Ceux-ci incluent deux cas :
- Lorsque les totaux cumulés des deux types sont identiques, l'entrée d'approvisionnement a une quantité commerciale nulle. N'oubliez pas que la commande est basée sur SumQty et Code, donc lorsque les totaux cumulés sont identiques, l'entrée de demande apparaît avant l'entrée d'approvisionnement.
- Entrées de fin d'un type qui ne peuvent pas être mises en correspondance avec des entrées de l'autre type. Ces entrées sont représentées par des lignes dans C3 où DemandID est NULL ou SupplyID est NULL.
Le plan de cette solution est illustré à la figure 2.
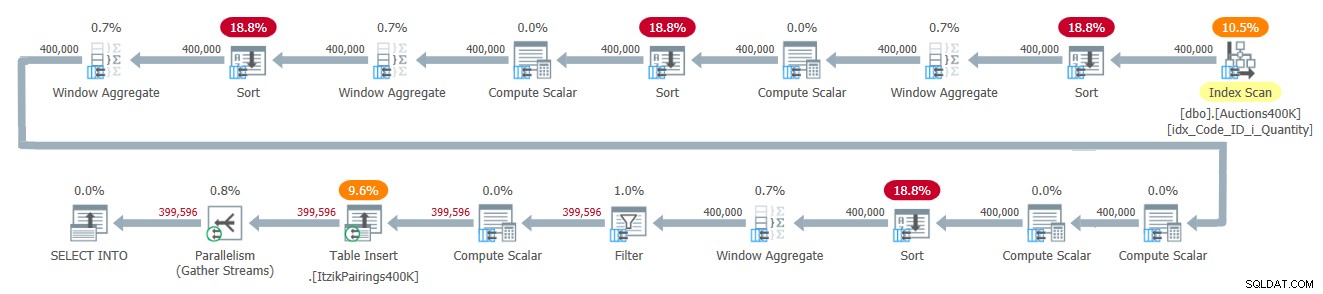 Figure 2 :Plan de requête pour la solution d'Itzik
Figure 2 :Plan de requête pour la solution d'Itzik
Le plan applique une passe sur les données d'entrée et utilise quatre opérateurs Window Aggregate en mode batch pour gérer les différents calculs fenêtrés. Tous les opérateurs Window Aggregate sont précédés d'opérateurs de tri explicites, bien que seuls deux d'entre eux soient inévitables ici. Les deux autres ont à voir avec l'implémentation actuelle de l'opérateur Window Aggregate en mode batch parallèle, qui ne peut pas s'appuyer sur une entrée parallèle préservant l'ordre. Un moyen simple de voir quels opérateurs de tri sont dus à cette raison est de forcer un plan en série et de voir quels opérateurs de tri disparaissent. Lorsque je force un plan en série avec cette solution, les premier et troisième opérateurs de tri disparaissent.
Voici les temps d'exécution en secondes que j'ai obtenus pour cette solution :
100K :0,246200K :0,427300K :0,616400K :0,841>
La solution d'Ian
La solution de Ian est courte et efficace. Voici le code complet de la solution :
DOP TABLE SI EXISTE #MyPairings ; WITH A AS ( SELECT *, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity FROM dbo.Auctions), B AS ( SELECT CumulativeQuantity, CumulativeQuantity - LAG(CumulativeQuantity, 1, 0) OVER (ORDER BY CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Code ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID FROM A GROUP BY CumulativeQuantity, ID/ID -- regroupement erroné pour améliorer l'estimation des lignes -- (nombre de lignes des enchères au lieu de 2 lignes)), C AS ( -- remplir NULLs avec la prochaine offre/demande -- FIRST_VALUE(ID) IGNORE NULLS OVER ... -- serait mieux, mais cela fonctionnera car les ID sont dans l'ordre CumulativeQuantity SELECT MIN(DemandID) OVER (ORDER BY CumulativeQuantity ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID, MIN(SupplyID) OVER (ORDER BY CumulativeQ uantity LIGNES ENTRE LA LIGNE ACTUELLE ET SANS LIMITE SUIVANT) AS SupplyID, TradeQuantity FROM B)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID N'EST PAS NULL - supprimer les demandes non satisfaites ET DemandID N'EST PAS NULL ; -- couper les fournitures inutilisées
Le code dans le CTE A interroge la table Auctions et calcule les quantités totales de demande et d'approvisionnement en cours à l'aide d'une fonction de fenêtre, en nommant la colonne de résultat CumulativeQuantity.
Le code dans le CTE B interroge CTE A et regroupe les lignes par CumulativeQuantity. Ce regroupement produit un effet similaire à la jointure externe de Brian basée sur les totaux cumulés de la demande et de l'offre. Ian a également ajouté l'expression fictive ID/ID à l'ensemble de regroupement pour améliorer la cardinalité d'origine du regroupement sous estimation. Sur ma machine, cela a également entraîné l'utilisation d'un plan parallèle au lieu d'un plan série.
Dans la liste SELECT, le code calcule DemandID et SupplyID en récupérant l'ID du type d'entrée respectif dans le groupe à l'aide de l'agrégat MAX et d'une expression CASE. Si l'ID n'est pas présent dans le groupe, le résultat est NULL. Le code calcule également une colonne de résultats appelée TradeQuantity comme la quantité cumulée actuelle moins la précédente, récupérée à l'aide de la fonction de fenêtre LAG.
Voici le contenu de B :
CumulativeQuantity TradeQuantity DemandId SupplyId------------------- -------------- --------- - -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.000000 4.000000 NULL 500025.000000 3.000000 NULL 600026.000000 1.000000 6 NULL27.000000 1.000000 NULL 700030.000000 3.000000 7 NULL32.000000 2.000000 8 NULL
Le code dans le CTE C interroge ensuite le CTE B et remplit les ID de demande et d'approvisionnement NULL avec les prochains ID de demande et d'approvisionnement non NULL, en utilisant la fonction de fenêtre MIN avec le cadre ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Voici le contenu de C :
DemandID SupplyID TradeQuantity --------- --------- --------------1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
La dernière étape gérée par la requête externe contre C consiste à supprimer les entrées d'un type qui ne peuvent pas être mises en correspondance avec les entrées de l'autre type. Cela se fait en filtrant les lignes où SupplyID est NULL ou DemandID est NULL.
Le plan de cette solution est illustré à la figure 3.
 Figure 3 :Plan de requête pour la solution de Ian
Figure 3 :Plan de requête pour la solution de Ian
Ce plan effectue une analyse des données d'entrée et utilise trois opérateurs d'agrégation de fenêtres en mode batch parallèles pour calculer les différentes fonctions de fenêtre, tous précédés d'opérateurs de tri parallèles. Deux d'entre eux sont inévitables, comme vous pouvez le vérifier en forçant un plan en série. Le plan utilise également un opérateur Hash Aggregate pour gérer le regroupement et l'agrégation dans le CTE B.
Voici les temps d'exécution en secondes que j'ai obtenus pour cette solution :
100 K :0,214200 K :0,363300 K :0,546400 K :0,701
La solution de Peter Larsson
La solution de Peter Larsson est incroyablement courte, douce et très efficace. Voici le code de solution complet de Peter :
DOP TABLE SI EXISTE #MyPairings ; WITH cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM ( SELECT MIN(CASE WHEN Code ='D' THEN ID ELSE 2147483648 END) SUR (ORDER BY RunningQuantity, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID, MIN(CASE WHEN Code ='S' THEN ID ELSE 2147483648 END) SUR (ORDER BY RunningQuantity, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0) AS TradeQuantity FROM cteSource ) AS dWHERE DemandID <2147483648 AND SupplyID <2147483648 AND TradeQuantity> 0.0;
Le CTE cteSource interroge la table Auctions et utilise une fonction de fenêtrage pour calculer la demande totale en cours et les quantités d'approvisionnement, en appelant la colonne de résultat RunningQuantity.
Le code définissant la table dérivée d interroge cteSource et calcule les paires de résultats DemandID, SupplyID et TradeQuantity, avant de supprimer certaines lignes superflues. Toutes les fonctions de fenêtre utilisées dans ces calculs sont basées sur la commande RunningQuantity et Code.
La colonne de résultat d.DemandID est calculée comme l'ID de demande minimum commençant par le courant ou 2147483648 si aucun n'est trouvé.
La colonne de résultat d.SupplyID est calculée comme l'ID d'approvisionnement minimum commençant par le courant ou 2147483648 si aucun n'est trouvé.
Le résultat TradeQuantity est calculé comme la valeur RunningQuantity de la ligne actuelle moins la valeur RunningQuantity de la ligne précédente.
Voici le contenu de d :
DemandID SupplyID TradeQuantity--------- ----------- --------------1 1000 5.0000002 1000 3.0000003 1000 0.0000003 2000 6.0000003 3000 2.0000005 3000 0.0000005 4000 2.0000006 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.000000
Ce qui reste à faire pour la requête externe est de filtrer les lignes superflues de d. Ce sont des cas où la quantité échangée est nulle, ou des entrées d'un type qui ne peuvent pas être mises en correspondance avec des entrées de l'autre type (avec l'ID 2147483648).
Le plan de cette solution est illustré à la figure 4.
 Figure 4 :Plan de requête pour la solution de Peter
Figure 4 :Plan de requête pour la solution de Peter
Comme le plan de Ian, le plan de Peter repose sur une analyse des données d'entrée et utilise trois opérateurs d'agrégation de fenêtres en mode batch parallèles pour calculer les différentes fonctions de fenêtre, tous précédés d'opérateurs de tri parallèles. Deux d'entre eux sont inévitables, comme vous pouvez le vérifier en forçant un plan en série. Dans le plan de Peter, il n'y a pas besoin d'un opérateur d'agrégat groupé comme dans le plan de Ian.
La perspicacité critique de Peter qui a permis une solution aussi courte était la réalisation que pour une entrée pertinente de l'un des types, l'ID correspondant de l'autre type apparaîtra toujours plus tard (basé sur RunningQuantity et l'ordre des codes). Après avoir vu la solution de Peter, j'ai vraiment eu l'impression de trop compliquer les choses dans la mienne !
Voici les temps d'exécution en secondes que j'ai obtenus pour cette solution :
100K :0,197200K :0,412300K :0,558400K :0,696
La solution de Paul White
Notre dernière solution a été créée par Paul White. Voici le code complet de la solution :
DOP TABLE SI EXISTE #MyPairings ; CREATE TABLE #MyPairings( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.SupplyID, Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Chevauchement d'intervalle CASE WHEN Q2.Code ='S' THEN CASE WHEN Q2.CumDemand>=Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumDemand> Q2. IntStart ALORS Q2.CumDemand - Q2.IntStart ELSE 0.0 FIN QUAND Q2.Code ='D' ALORS CAS QUAND Q2.CumSupply>=Q2.IntEnd ALORS Q2.IntLength QUAND Q2.CumSupply> Q2.IntStart ALORS Q2.CumSupply - Q2. IntDébut SINON 0.0 FIN FIN DE ( CHOISIR Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER (ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) SUR ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) SUR ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING) FROM ( -- Intervalles de demande SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A. Quantité, IntEnd =SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Intervalles d'approvisionnement SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A.Quantity, IntEnd =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;
Le code définissant la table dérivée Q1 utilise deux requêtes distinctes pour calculer les intervalles de demande et d'approvisionnement en fonction des totaux cumulés et unifie les deux. Pour chaque intervalle, le code calcule son début (IntStart), sa fin (IntEnd) et sa longueur (IntLength). Voici le contenu de Q1 trié par IntStart et ID :
ID Code IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0.000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30.000000 32.000000 2.000000
Le code définissant la table dérivée Q2 interroge Q1 et calcule les colonnes de résultats appelées DemandID, SupplyID, CumSupply et CumDemand. Toutes les fonctions de fenêtre utilisées par ce code sont basées sur l'ordre IntStart et ID et le cadre ROWS UNBOUNDED PRECEDING (toutes les lignes jusqu'au courant).
DemandID est l'ID de demande maximum jusqu'à la ligne actuelle, ou 0 s'il n'en existe pas.
SupplyID est l'ID d'approvisionnement maximal jusqu'à la ligne actuelle, ou 0 s'il n'en existe pas.
CumSupply correspond aux quantités d'approvisionnement cumulées (longueurs des intervalles d'approvisionnement) jusqu'à la ligne actuelle.
CumDemand correspond aux quantités de demande cumulées (longueurs d'intervalle de demande) jusqu'à la ligne actuelle.
Voici le contenu de Q2 :
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- --------- ---------- ----------D 0,000000 5,000000 5,000000 1 0 0,000000 5,000000S 0,000000 8,000000 8,000000 1 1000 8,000000 5,000000D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000S 22.000000 25.000000 3.000000 6 600000 25.000000 26.000000S 25.000000 27.000000 2.000000 6 7000 27.00000026Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
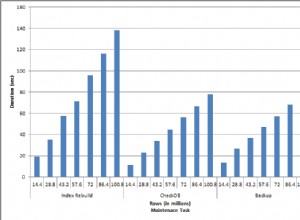
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Conclusion
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]