Il s'agit de la quatrième partie d'une série en cinq parties qui analyse en profondeur la façon dont les plans parallèles en mode ligne de SQL Server commencent à s'exécuter. La partie 1 a initialisé le contexte d'exécution zéro pour la tâche parente et la partie 2 a créé l'arborescence d'analyse des requêtes. La partie 3 a commencé l'analyse de la requête, effectué une phase préliminaire traitement et a lancé les premières tâches parallèles supplémentaires dans la branche C.
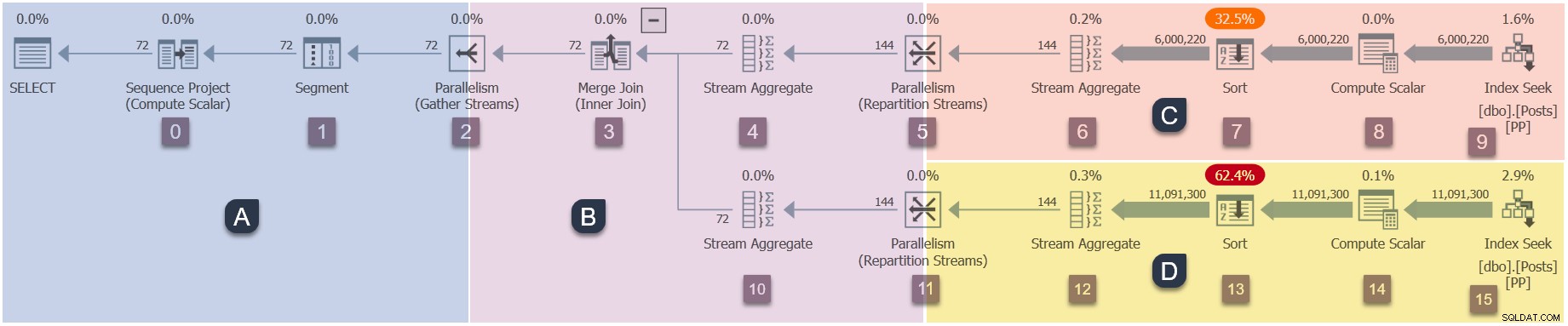
Détails d'exécution de la branche C
Il s'agit de la deuxième étape de la séquence d'exécution :
- Branche A (tâche parente).
- Branche C (tâches parallèles supplémentaires).
- Branche D (tâches parallèles supplémentaires).
- Branche B (tâches parallèles supplémentaires).
Un rappel des branches de notre plan parallèle (cliquez pour agrandir)
Peu de temps après les nouvelles tâches pour la branche C sont en file d'attente, SQL Server attache un worker à chaque tâche et place le travailleur sur un planificateur prêt pour l'exécution. Chaque nouvelle tâche s'exécute dans un nouveau contexte d'exécution. Au DOP 2, il y a deux nouvelles tâches, deux threads de travail et deux contextes d'exécution pour la branche C. Chaque tâche exécute sa propre copie des itérateurs de la branche C sur son propre thread de travail :

Les deux nouvelles tâches parallèles commencent à s'exécuter dans une sous-procédure point d'entrée, qui conduit initialement à un Open appel du côté producteur de l'échange (CQScanXProducerNew::Open ). Les deux tâches ont des piles d'appels identiques au début de leur vie :
Synchronisation d'échange
Pendant ce temps, la tâche parent (s'exécutant sur son propre thread de travail) enregistre les nouveaux sous-processus auprès du gestionnaire de sous-processus, puis attend du côté du consommateur de l'échange des flux de répartition au noeud 5. La tâche parent attend CXPACKET * jusqu'à tous des tâches parallèles de la branche C terminent leur Open appels et retour au côté producteur de l'échange. Les tâches parallèles ouvriront chaque itérateur dans leur sous-arborescence (c'est-à-dire jusqu'à la recherche d'index au nœud 9 et retour) avant de retourner à l'échange de flux de répartition au nœud 5. La tâche parent attendra CXPACKET pendant que cela se produit. N'oubliez pas que la tâche parent exécute les appels des premières phases.
Nous pouvons voir cette attente dans les tâches d'attente DMV :

Le contexte d'exécution zéro (la tâche parente) est bloqué par les deux nouveaux contextes d'exécution. Ces contextes d'exécution sont les premiers supplémentaires à être créés après le contexte zéro, ils reçoivent donc les numéros un et deux. Pour souligner :les deux nouveaux contextes d'exécution doivent ouvrir leurs sous-arborescences et revenir à l'échange pour le CXPACKET de la tâche parent. attendre la fin.
Vous vous attendiez peut-être à voir CXCONSUMER attend ici, mais cette attente est réservée pour attendre les données de ligne arriver. L'attente actuelle n'est pas pour les lignes - c'est au côté producteur d'ouvrir , nous obtenons donc un CXPACKET générique * attendez.
* Azure SQL Database et Managed Instance utilisent le nouveau CXSYNC_PORT attendre au lieu de CXPACKET ici, mais cette amélioration n'a pas encore fait son chemin dans SQL Server (à partir de 2019 CU9).
Inspection des nouvelles tâches parallèles
Nous pouvons voir les nouvelles tâches dans les profils de requête DMV. Les informations de profilage des nouvelles tâches apparaissent dans la DMV car leurs contextes d'exécution ont été dérivés (clonés, puis mis à jour) du parent (contexte d'exécution zéro) :
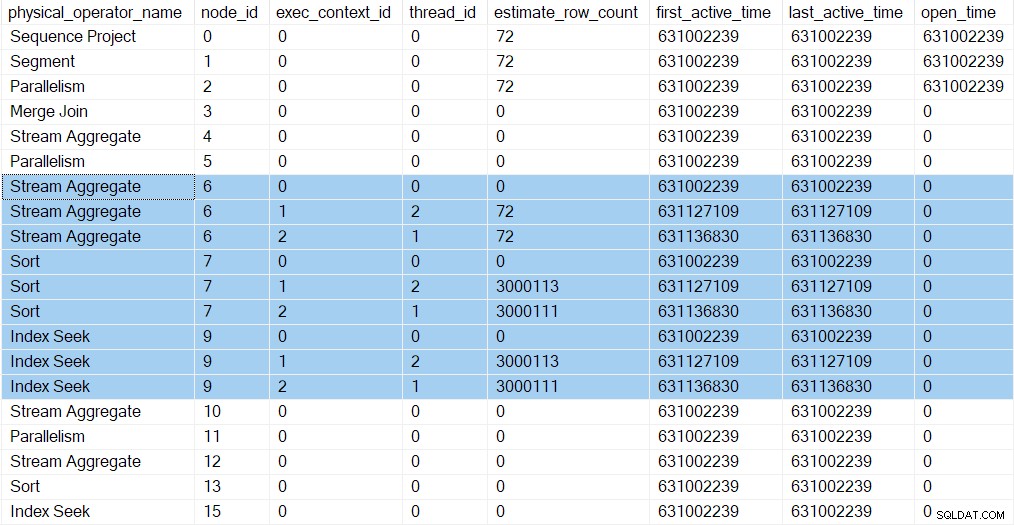
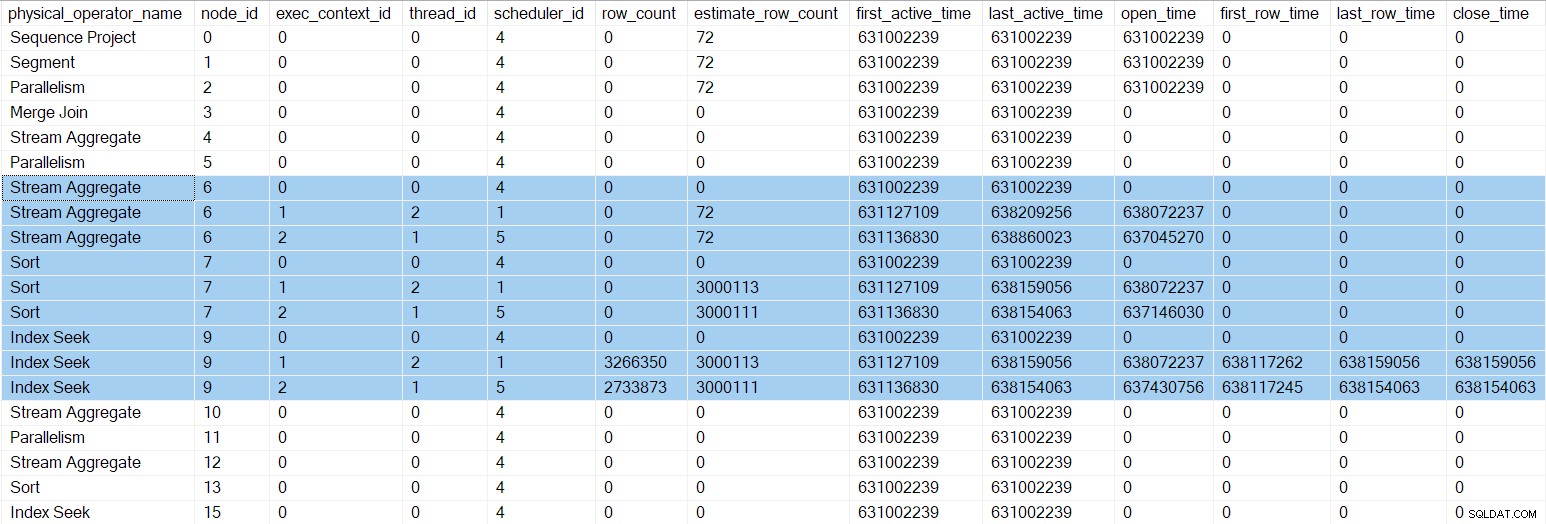
Il y a maintenant trois entrées pour chaque itérateur dans la branche C (en surbrillance). Un pour la tâche parent (contexte d'exécution zéro), et un pour chaque nouvelle tâche parallèle supplémentaire (contextes 1 et 2). Notez que la ligne estimée par thread compte (voir partie 1) sont maintenant arrivés et ne sont affichés que pour les tâches parallèles. La première et la dernière heures d'activité pour les tâches parallèles représentent le moment où leurs contextes d'exécution ont été créés. Aucune des nouvelles tâches n'a ouvert aucun itérateur pour le moment.
Les flux de répartition l'échange au nœud 5 n'a toujours qu'une seule entrée dans la sortie DMV. En effet, le profileur invisible associé surveille le consommateur côté de l'échange. Les tâches parallèles supplémentaires sont sur le producteur côté de l'échange. Le côté consommateur du nœud 5 finira éventuellement ont des tâches parallèles, mais nous n'en sommes pas encore là.
Point de contrôle
Cela semble être un bon point pour faire une pause et résumer où tout se trouve en ce moment. Il y aura plus de ces points d'arrêt au fur et à mesure.
- La tâche parente est du côté du consommateur de l'échange de flux de répartition au nœud 5 , en attente de
CXPACKET. Il est au milieu de l'exécution des appels des premières phases. Il s'est arrêté pour démarrer la branche C car cette branche contient un tri bloquant. L'attente de la tâche parent se poursuivra jusqu'à ce que les deux tâches parallèles terminent l'ouverture de leurs sous-arborescences. - Deux nouvelles tâches parallèles du côté producteur de l'échange du nœud 5 sont prêts à ouvrir les itérateurs dans la branche C.
Rien en dehors de la branche C de ce plan d'exécution parallèle ne peut avancer jusqu'à ce que la tâche parent soit libérée de son CXPACKET Attendez. N'oubliez pas que nous n'avons créé qu'un seul ensemble de travailleurs parallèles supplémentaires jusqu'à présent, pour la branche C. Le seul autre thread est la tâche parente, et elle est bloquée.
Exécution parallèle de la branche C
Les deux tâches parallèles commencent du côté du producteur de l'échange de flux de répartition au nœud 5. Chacun a un plan (série) séparé avec son propre agrégat de flux, tri et recherche d'index. Le scalaire de calcul n'apparaît pas dans le plan d'exécution car ses calculs sont reportés au tri.
Chaque instance de la recherche d'index est consciente du parallèle et opère sur des ensembles disjoints de lignes. Ces ensembles sont générés à la demande à partir de l'ensemble de lignes parent créé précédemment par la tâche parent (traité dans la partie 1). Lorsque l'une ou l'autre des instances de la recherche a besoin d'une nouvelle sous-plage de lignes, elle se synchronise avec les autres threads de travail, de sorte qu'un seul alloue une nouvelle sous-plage en même temps. L'objet de synchronisation utilisé a également été créé précédemment par la tâche parent. Lorsqu'une tâche attend un accès exclusif à l'ensemble de lignes parent pour acquérir une nouvelle sous-plage, elle attend CXROWSET_SYNC .
Tâches de la branche C ouvertes
La séquence de Open appels pour chaque tâche dans la branche C est :
CQScanXProducerNew::Open. Notez qu'il n'y a pas de profileur précédent du côté producteur d'un échange. C'est dommage pour les tuners de requêtes.CXTransLocal::OpenCXPort::RegisterCXTransLocal::ActivateWorkersCQScanProfileNew::Open. Le profileur au-dessus du nœud 6.CQScanStreamAggregateNew::Open(noeud 6)CQScanProfileNew::Open. Le profileur au-dessus du nœud 7.CQScanSortNew::Open(noeud 7)
Le tri est un opérateur entièrement bloquant . Il consomme la totalité de son entrée lors de son Open appel. Il y a un grand nombre de détails internes intéressants à explorer ici, mais l'espace est limité, donc je ne couvrirai que les points saillants :
Le tri construit sa table de tri en ouvrant son sous-arbre et en consommant toutes les lignes que ses enfants peuvent fournir. Une fois le tri terminé, le tri est prêt à passer en mode de sortie et il rend le contrôle à son parent. Le tri répondra plus tard à GetRow() appels, renvoyant la ligne triée suivante à chaque fois. Une pile d'appels illustrative pendant l'entrée de tri est :
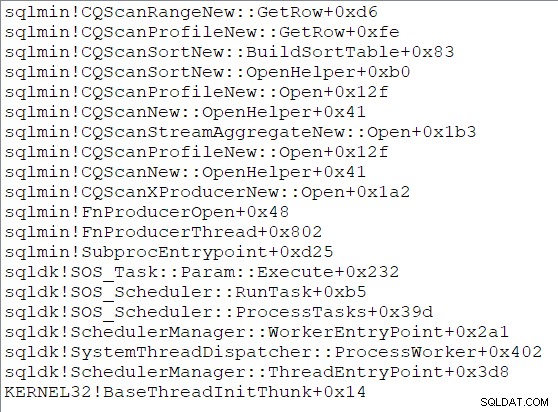
L'exécution continue jusqu'à ce que chaque tri ait consommé toutes les (plages disjointes de) lignes disponibles à partir de son enfant recherche d'index . Les tris appellent alors Close sur l'index cherche et rend le contrôle à son agrégat de flux parent . Les agrégats de flux initialisent leurs compteurs et rendent le contrôle au producteur côté de l'échange de répartition au nœud 5. La séquence de Open les appels sont maintenant terminés dans cette succursale.
Le DMV de profilage à ce stade affiche les numéros de synchronisation mis à jour et les heures de fermeture pour l'index parallèle cherche :
Plus de synchronisation d'échange
Rappeler que la tâche parent attend le consommateur côté du nœud 5 pour que tous les producteurs l'ouvrent. Un processus de synchronisation similaire se produit désormais entre les tâches parallèles sur le producteur côté du même échange :
Chaque tâche producteur se synchronise avec les autres via CXTransLocal::Synchronize . Les producteurs appellent CXPort::Open , puis attendez CXPACKET pour tous les côtés consommateurs tâches parallèles à ouvrir. Lorsque la première tâche parallèle de la branche C revient du côté producteur de l'échange et attend, la DMV des tâches en attente ressemble à ceci :

Nous avons toujours les attentes côté consommateur de la tâche parent. Le nouveau CXPACKET mis en évidence est notre première tâche parallèle côté producteur en attente de toutes les tâches parallèles côté consommateur pour ouvrir le port d'échange.
Les tâches parallèles côté consommateur (dans la branche B) n'existent même pas encore, donc la tâche producteur affiche NULL pour le contexte d'exécution par lequel elle est bloquée. La tâche actuellement en attente du côté consommateur de l'échange de flux de répartition est la tâche parent (pas une tâche parallèle !) exécutant EarlyPhases code, donc ça ne compte pas.
La tâche parent CXPACKET attend se termine
Lorsque la seconde la tâche parallèle dans la branche C revient du côté producteur de l'échange à partir de son Open appels, tous les producteurs ont ouvert le port d'échange, donc la tâche parent du côté du consommateur de l'échange est publié depuis son CXPACKET attendez.
Les travailleurs côté producteur continuent d'attendre que les tâches parallèles côté consommateur soient créées et ouvrent le port d'échange :

Point de contrôle
À ce moment :
- Il y a un total de trois tâches :deux dans la branche C, plus la tâche parente.
- Les deux producteurs au nœud 5, l'échange est ouvert et attend sur
CXPACKETpour que les tâches parallèles côté consommateur s'ouvrent. Une grande partie de la machinerie d'échange (y compris les tampons de lignes) est créée par le côté consommateur, de sorte que les producteurs n'ont encore aucun endroit où placer des lignes. - Les sortes dans la branche C ont consommé toutes leurs entrées et sont prêts à fournir une sortie triée.
- L'index recherche dans la succursale C ont terminé leurs travaux et fermé.
- La tâche parente vient d'être libéré de l'attente sur
CXPACKETdu côté consommateur du nœud 5, l'échange de flux de répartition. C'est toujours exécution deEarlyPhasesimbriqués appels.
Démarrage des tâches parallèles de la branche D
Il s'agit de la troisième étape de la séquence d'exécution :
- Branche A (tâche parente).
- Branche C (tâches parallèles supplémentaires).
- Branche D (tâches parallèles supplémentaires).
- Branche B (tâches parallèles supplémentaires).
Libéré de son CXPACKET attendre du côté consommateur de l'échange de flux de répartition au nœud 5, la tâche parent monte l'arborescence d'analyse des requêtes de la branche B. Il revient de EarlyPhases imbriqué appels aux différents itérateurs et profileurs sur l'entrée externe (supérieure) de la jointure de fusion.
Comme mentionné, ascendant l'arborescence met à jour les temps écoulés et CPU enregistrés par les itérateurs de profilage invisibles. Nous exécutons du code à l'aide de la tâche parente, de sorte que ces nombres sont enregistrés par rapport au contexte d'exécution zéro. Il s'agit de la source ultime des numéros de synchronisation "thread 0" mentionnés dans mon article précédent, Understanding Execution Plan Operator Timings.
Une fois de retour à la jointure de fusion, la tâche parent appelle EarlyPhases pour les itérateurs et les profileurs sur l'entrée interne (inférieure) de la jointure de fusion. Ce sont les nœuds 10 à 15 (hors 14, qui est différé) :
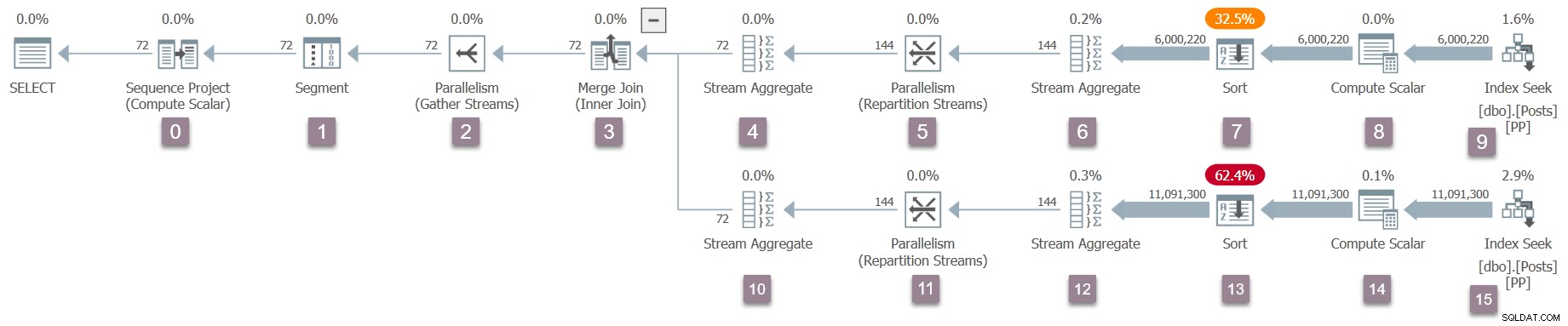
Une fois que les appels des premières phases de la tâche parent atteignent la recherche d'index au nœud 15, elle recommence à remonter l'arborescence (définissant les temps de profilage) jusqu'à ce qu'elle atteigne l'échange de flux de répartition au nœud 11.
Ensuite, tout comme il l'a fait sur l'entrée externe (supérieure) de la jointure de fusion, il démarre le côté producteur de l'échange au nœud 11 , créant deux nouvelles tâches parallèles .
Cela active la branche D (illustrée ci-dessous). La branche D s'exécute exactement comme déjà décrit en détail pour la branche C.
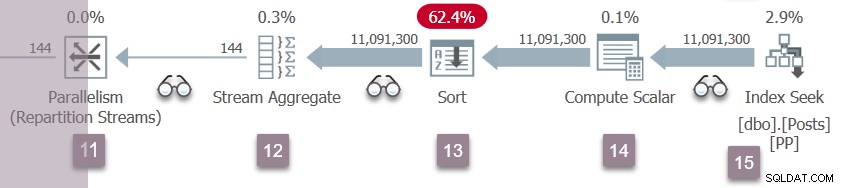
Immédiatement après le démarrage des tâches pour la branche D, la tâche parent attend sur CXPACKET au nœud 11 pour que les nouveaux producteurs ouvrent le port d'échange :

Le nouveau CXPACKET les attentes sont mises en évidence. Notez que l'ID de nœud signalé peut être un peu trompeur. La tâche parent attend réellement du côté consommateur du nœud 11 (flux de répartition), et non du nœud 2 (flux de collecte). C'est une bizarrerie du traitement de phase précoce.
Pendant ce temps, les threads producteurs de la branche C continuent d'attendre CXPACKET pour que le côté consommateur de l'échange de flux de répartition du nœud 5 s'ouvre.
Ouverture de la succursale D
Juste après que la tâche parent démarre les producteurs pour la branche D, le profil de requête DMV montre les nouveaux contextes d'exécution (3 et 4) :
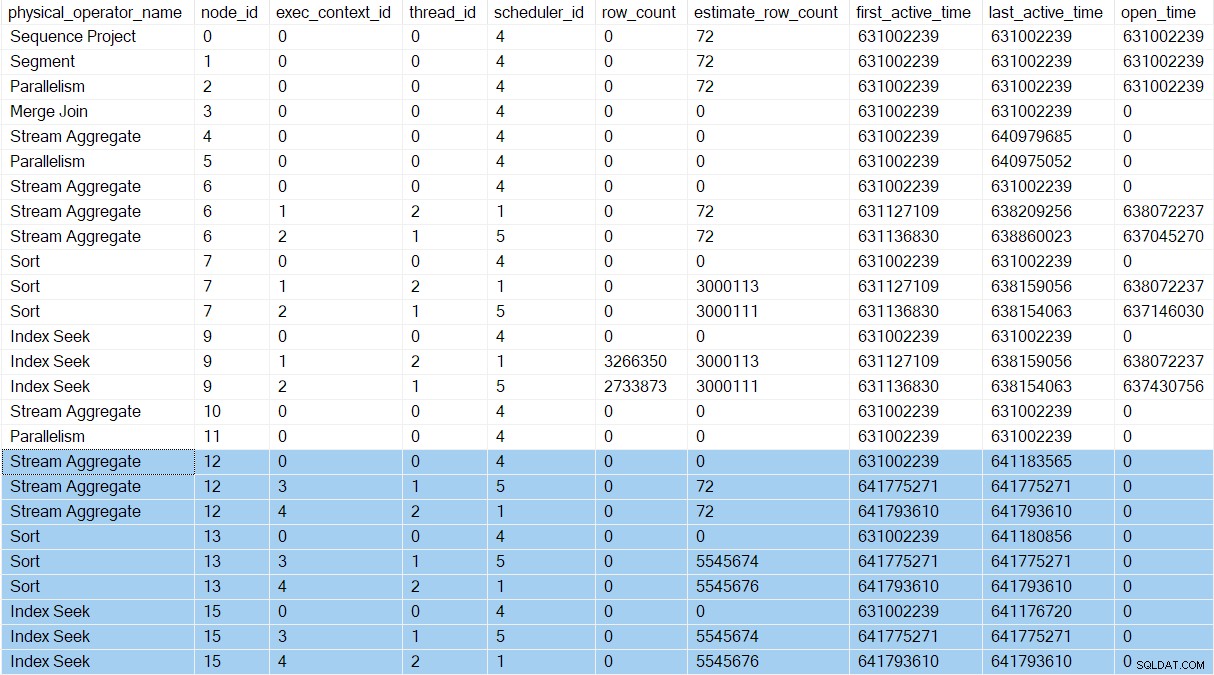
Les deux nouvelles tâches parallèles de la branche D procèdent exactement comme ceux de la branche C. Les tris consomment toutes leurs entrées et les tâches de la branche D retournent à l'échange. Cela libère la tâche parent de son CXPACKET Attendez. Les travailleurs de la branche D attendent alors CXPACKET du côté producteur du nœud 11 pour que les tâches parallèles côté consommateur s'ouvrent. Ces travailleurs parallèles (dans la branche B) n'existent pas encore.
Point de contrôle
Les tâches en attente à ce stade sont indiquées ci-dessous :

Les deux ensembles de tâches parallèles dans les branches C et D attendent CXPACKET pour que leurs consommateurs de tâches parallèles ouvrent, lors de la répartition des flux, les nœuds d'échange 5 et 11 respectivement. La seule tâche exécutable dans toute la requête en ce moment est la tâche parent .
Le profileur de requête DMV à ce stade est illustré ci-dessous, avec les opérateurs des branches C et D en surbrillance :
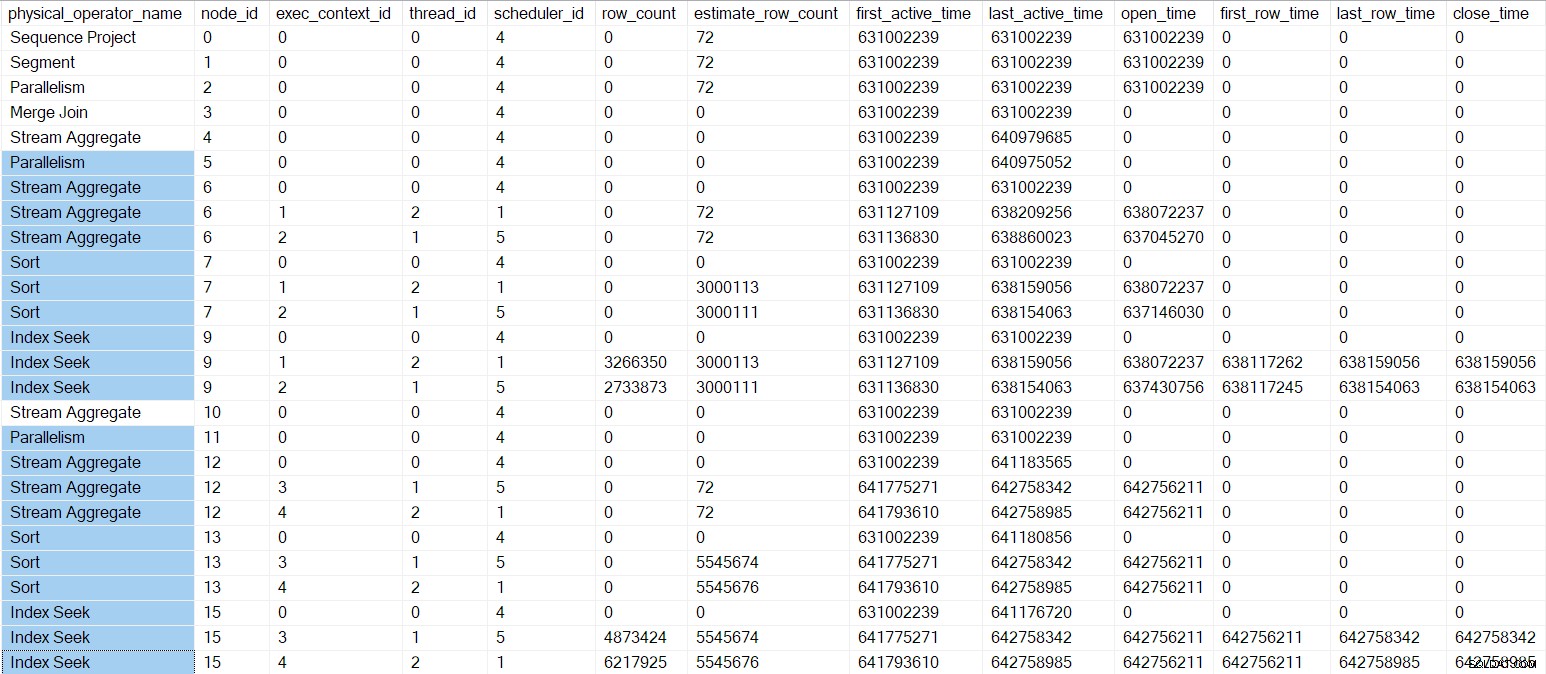
Les seules tâches parallèles que nous n'avons pas encore commencées se trouvent dans la branche B. Tout le travail dans la branche B jusqu'à présent a été des phases préliminaires appels effectués par la tâche parent .
Fin de la partie 4
Dans la dernière partie de cette série, je décrirai comment le reste de ce plan d'exécution parallèle particulier démarre et expliquerai brièvement comment le plan renvoie des résultats. Je terminerai par une description plus générale qui s'applique aux plans parallèles de complexité arbitraire.